







智能agent
开篇前言
这段时间找工作,发现自己太菜了,一直刷题也刷不动,索性总结一下以前学习的课程。在外留学的这两年学了好多东西,无奈总不用都忘记了。所以我决定开始写博客,整理一下以前的学习资料,感觉好多东西不看都忘记了,学费挺贵的,我不能把知识还给老师。本系列博文覆盖内容为search,KRR和planning,教材为人工智能:一种现代的方法(第三版)。笔记中也会记录老师引申出的一些内容,原书中是没有的。作者水平有限,希望大家多多指点。这篇文章的内容在书上第二章。(PS:去年年中出了第四版,不过是英文的,1800一本好贵呀,买不起ค(TㅅT)ค)
agent的分类
1、简单反射agent
简单反射agent是最简单的agent,这类agent仅仅基于当前的感知来做决定。
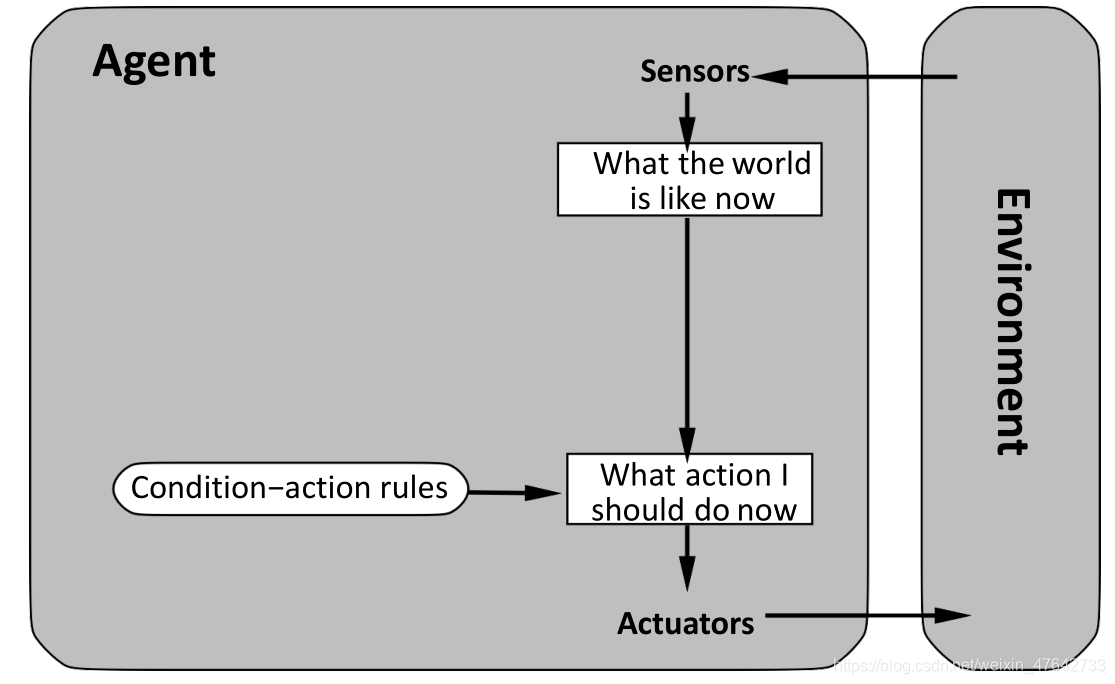
2、基于状态的反射agent
这种agent的内部状态可以跟踪环境中不可见的相关方面,环境模型描述环境如何工作(环境状态如何受到动作的影响。

3、基于目标的agent
目标用于描述理想的情况。此时,agent结合目标和环境模型来选择行动。planning 和 search是人工智能子领域中致力于建立基于目标的agent。(PS:planning挺难的,当时我就没学会)
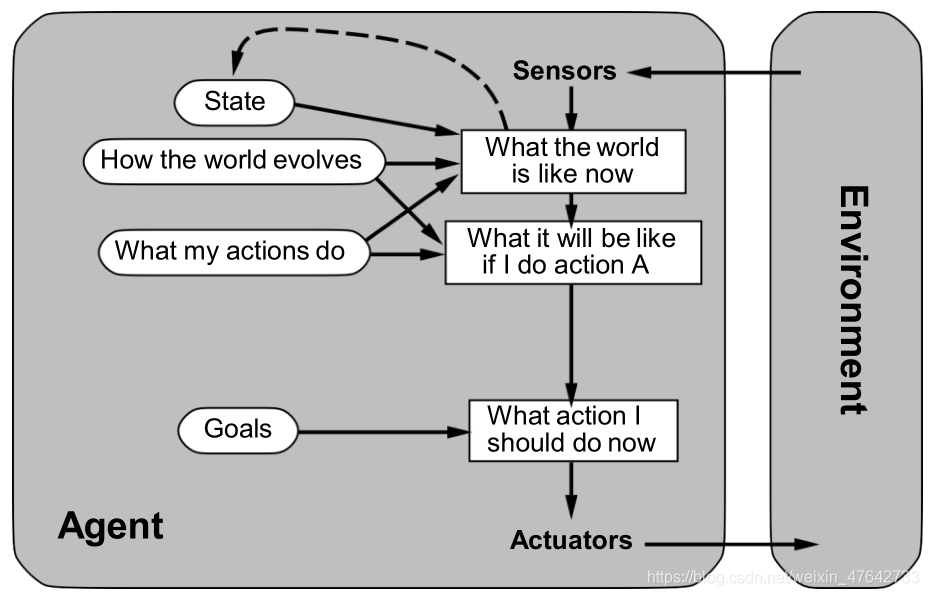
4、基于效用的agent
效用函数的出现使得agent将性能度量内部化。在一些不确定的情况下,agent会选择那些能让期望效用最大化的动作。
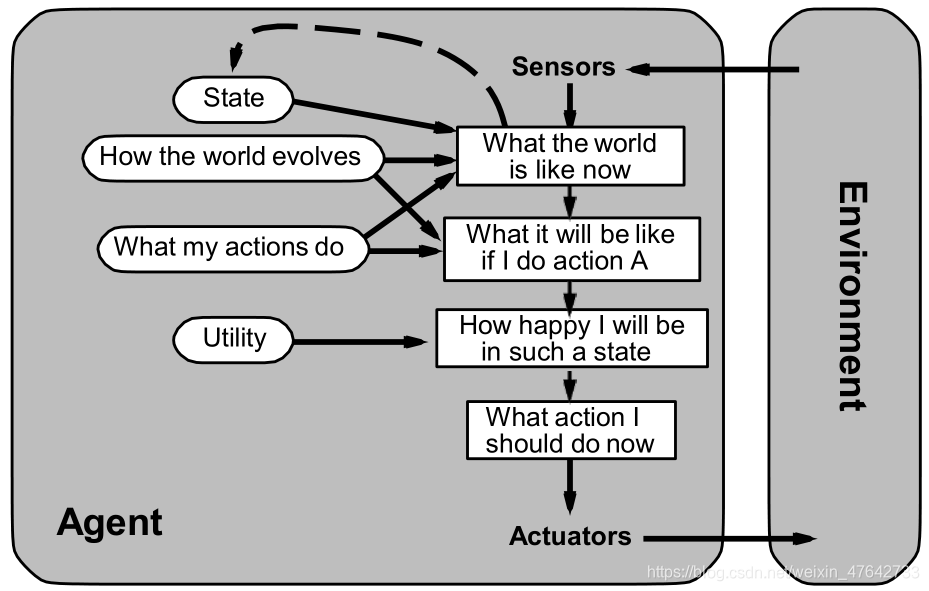
(PS:最近朋友圈里火了的那个自杀狼就是因为效用问题导致的狼的自杀。狼吃羊加10分,狼撞到障碍物扣1分。为了鼓励狼吃羊,每过1秒减0.1分。这导致了狼抓到羊也可能会是负分,可能不如直接撞死的好。我们可以把羊的分数按照时间递减,这样应该不会出现狼自杀的情况)
5、学习agent
动作选择元件跟上面讲的agent一样,跟前面的agent不一样的是学习agent多了学习元件。学习元件使用评判元件的反馈来修改动作的选择。学习agent中的问题生成器负责得到新的和有信息的经验的行动提议。

Exploration vs Exploitation
为什么我要写这一段东西那?这是因为学习agent其实是有一个基本原则困境的。那就是探索和利用(这个是我自己翻译的,第三版书上还没有这部分)。首先我们来看一下这两个词的定义。
- Exploration: 采取其他(可能是随机的)行动来了解更多内容,希望找到比目前已知的内容更好的内容。
- Exploitation: 为了有最好的结果,agent根据当前的知识,贪婪的使用已经学会的东西去做选择。
这就是学习agent面临的困境。如果我们只为了最好的结果,一味的在每一步追求最优解,最终agent可能会被困在次优解。(比如贪心算法,总是选当前的最优解,可能最终得不到最优解,不过大部分时候贪心算法得到的结果都不错)所以agent必须进行探索以避免卡在次优行为。但是探索是有成本的,如何平衡exploration和exploitation是一个问题。通常情况下,我们建议agent在早期阶段的探索多余后期。(大家可以看看模拟退火算法).。














 2192
2192











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









