







目录
CPU
一、CPU是什么
CPU 的全称是 Central Processing Unit,CPU 是计算机的核心组件,它是一种小型的计算机芯片,它嵌入在台式机、笔记本电脑或者平板电脑的主板上。通过在单个计算机芯片上放置数十亿个微型晶体管来构建 CPU。 这些晶体管使它能够执行运行存储在系统内存中的程序所需的计算,也就是说 CPU 决定了你电脑的计算能力。

二、CPU 实际做什么
CPU 的核心是从程序或应用程序获取指令并执行计算。此过程可以分为三个关键阶段:提取,解码和执行。CPU从系统的 RAM 中提取指令,然后解码该指令的实际内容,然后再由 CPU 的相关部分执行该指令。
RAM : 随机存取存储器(英语:Random Access Memory,缩写:RAM),也叫主存,是与 CPU 直接交换数据的内部存储器。它可以随时读写(刷新时除外),而且速度很快,通常作为操作系统或其他正在运行中的程序的临时数据存储介质
三、CPU 的内部结构
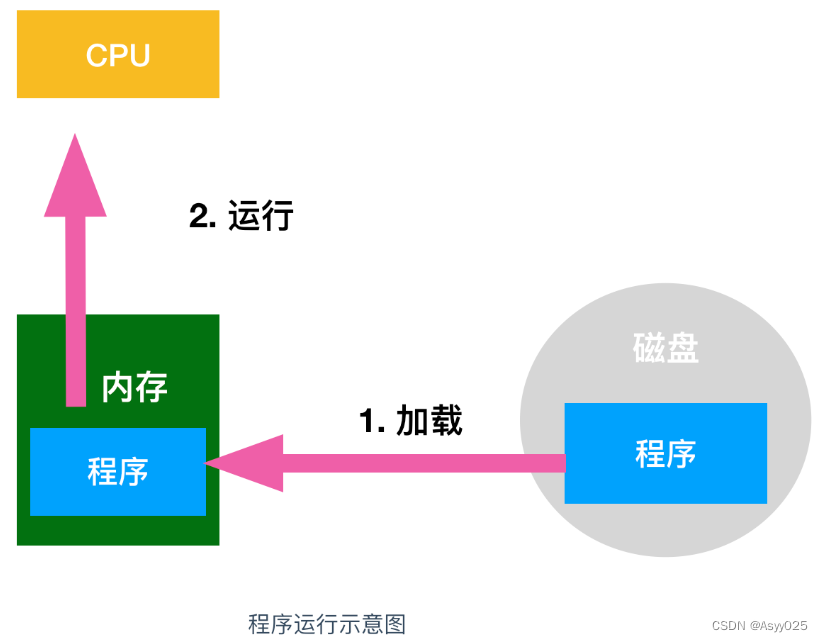
说了这么多 CPU 的重要性,那么 CPU 的内部结构是什么呢?又是由什么组成的呢?下图展示了一般程序的运行流程(以 C 语言为例),可以说了解程序的运行流程是掌握程序运行机制的基础和前提。
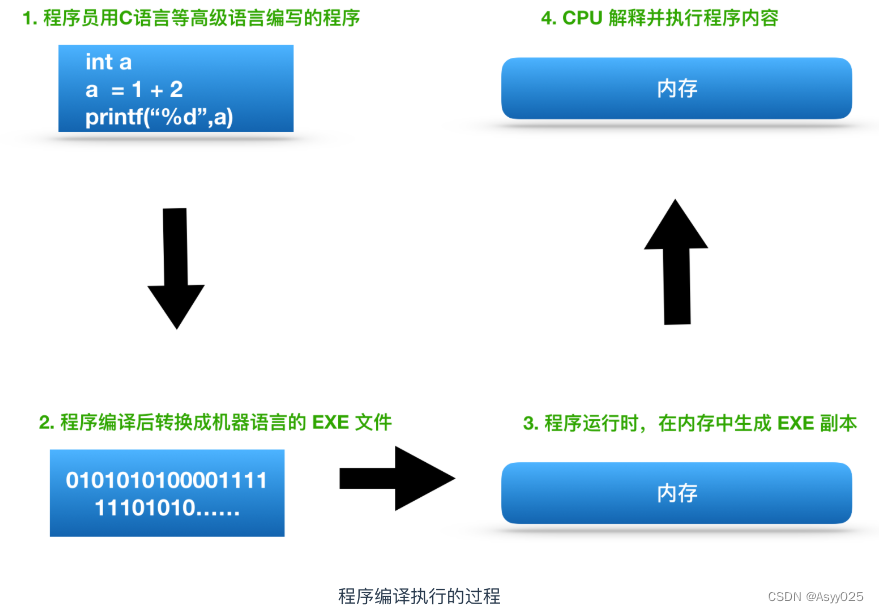
在这个流程中,CPU 负责的就是解释和运行最终转换成机器语言的内容。
CPU 主要由两部分构成:控制单元 和 算术逻辑单元(ALU)
- 控制单元:从内存中提取指令并解码执行
- 算数逻辑单元(ALU):处理算数和逻辑运算
CPU 是计算机的心脏和大脑,它和内存都是由许多晶体管组成的电子部件。它接收数据输入,执行指令并处理信息。它与输入/输出(I / O)设备进行通信,这些设备向 CPU 发送数据和从 CPU 接收数据。
从功能来看,CPU 的内部由寄存器、控制器、运算器和时钟四部分组成,各部分之间通过电信号连通。
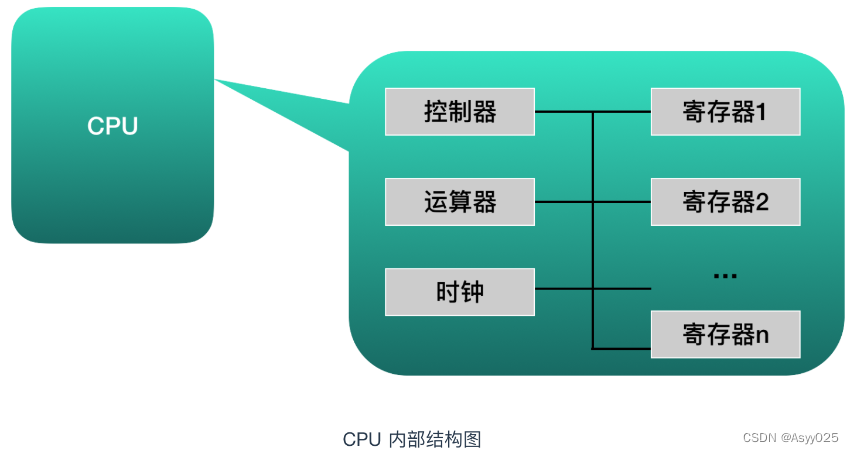
寄存器是中央处理器内的组成部分。它们可以用来暂存指令、数据和地址。可以将其看作是内存的一种。根据种类的不同,一个 CPU 内部会有 20 - 100个寄存器。控制器负责把内存上的指令、数据读入寄存器,并根据指令的结果控制计算机运算器负责运算从内存中读入寄存器的数据时钟负责发出 CPU 开始计时的时钟信号
内存是与 CPU 进行沟通的桥梁。计算机所有程序的运行都是在内存中运行的,内存又被称为主存,其作用是存放 CPU 中的运算数据,以及与硬盘等外部存储设备交换的数据。只要计算机在运行中,CPU 就会把需要运算的数据调到主存中进行运算,当运算完成后CPU再将结果传送出来,主存的运行也决定了计算机的稳定运行。
主存通过控制芯片与 CPU 进行相连,由可读写的元素构成,每个字节(1 byte = 8 bits)都带有一个地址编号,注意是一个字节,而不是一个位。CPU 通过地址从主存中读取数据和指令,也可以根据地址写入数据。注意一点:当计算机关机时,内存中的指令和数据也会被清除。
CPU 是寄存器的集合体
计算机语言
计算机听不懂你说的话,你要想和他交流必须按照计算机指令来交换,计算机是由二进制构成的,它只能听的懂二进制也就是 机器语言,但是普通人是无法看懂机器语言的,这个时候就需要一种电脑既能识别,人又能理解的语言,最先出现的就是汇编语言。但是汇编语言晦涩难懂,所以又出现了像是 C,C++,Java 的这种高级语言。
所以计算机语言一般分为两种:低级语言(机器语言,汇编语言)和高级语言。使用高级语言编写的程序,经过编译转换成机器语言后才能运行,而汇编语言经过汇编器才能转换为机器语言。
汇编语言
首先来看一段用汇编语言表示的代码清单
mov eax, dword ptr [ebp-8] /* 把数值从内存复制到 eax */ add eax, dword ptr [ebp-0Ch] /* 把 eax 的数值和内存的数值相加 */ mov dword ptr [ebp-4], eax /* 把 eax 的数值(上一步的结果)存储在内存中*/
这是采用汇编语言(assembly)编写程序的一部分。汇编语言采用 助记符(memonic) 来编写程序,每一个原本是电信号的机器语言指令会有一个与其对应的助记符,例如 mov,add 分别是数据的存储(move)和相加(addition)的简写。汇编语言和机器语言是一一对应的。这一点和高级语言有很大的不同,通常我们将汇编语言编写的程序转换为机器语言的过程称为 汇编;反之,机器语言转化为汇编语言的过程称为 反汇编。
汇编语言能够帮助你理解计算机做了什么工作,机器语言级别的程序是通过寄存器来处理的,上面代码中的 eax,ebp 都是表示的寄存器,是 CPU 内部寄存器的名称,所以可以说 CPU 是一系列寄存器的集合体。在内存中的存储通过地址编号来表示,而寄存器的种类则通过名字来区分。
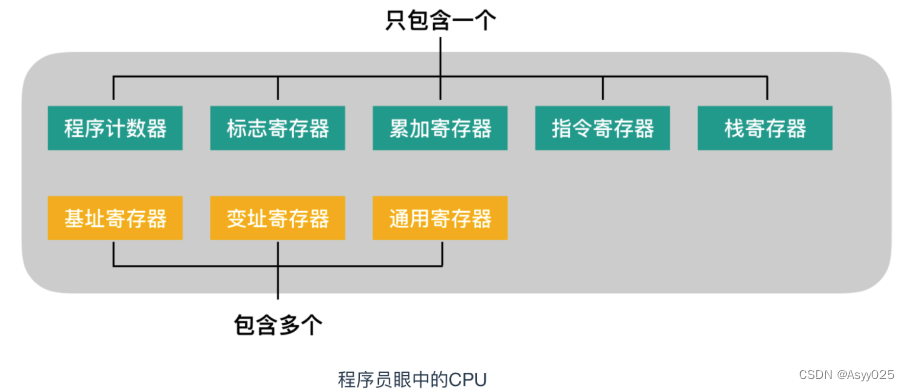
不同类型的 CPU ,其内部寄存器的种类,数量以及寄存器存储的数值范围都是不同的。不过,根据功能的不同,可以将寄存器划分为下面这几类
| 种类 | 功能 |
|---|---|
| 累加寄存器 | 存储运行的数据和运算后的数据。 |
| 标志寄存器 | 用于反应处理器的状态和运算结果的某些特征以及控制指令的执行。 |
| 程序计数器 | 程序计数器是用于存放下一条指令所在单元的地址的地方。 |
| 基址寄存器 | 存储数据内存的起始位置 |
| 变址寄存器 | 存储基址寄存器的相对地址 |
| 通用寄存器 | 存储任意数据 |
| 指令寄存器 | 储存正在被运行的指令,CPU内部使用,程序员无法对该寄存器进行读写 |
| 栈寄存器 | 存储栈区域的起始位置 |
其中程序计数器、累加寄存器、标志寄存器、指令寄存器和栈寄存器都只有一个,其他寄存器一般有多个
四、CPU 指令执行过程
几乎所有的冯·诺伊曼型计算机的CPU,其工作都可以分为5个阶段:取指令、指令译码、执行指令、访存取数、结果写回。
取指令阶段是将内存中的指令读取到 CPU 中寄存器的过程,程序寄存器用于存储下一条指令所在的地址指令译码阶段,在取指令完成后,立马进入指令译码阶段,在指令译码阶段,指令译码器按照预定的指令格式,对取回的指令进行拆分和解释,识别区分出不同的指令类别以及各种获取操作数的方法。执行指令阶段,译码完成后,就需要执行这一条指令了,此阶段的任务是完成指令所规定的各种操作,具体实现指令的功能。访问取数阶段,根据指令的需要,有可能需要从内存中提取数据,此阶段的任务是:根据指令地址码,得到操作数在主存中的地址,并从主存中读取该操作数用于运算。结果写回阶段,作为最后一个阶段,结果写回(Write Back,WB)阶段把执行指令阶段的运行结果数据“写回”到某种存储形式:结果数据经常被写到CPU的内部寄存器中,以便被后续的指令快速地存取;
内存
一、什么是内存
内存(Memory)是计算机中最重要的部件之一,它是程序与CPU进行沟通的桥梁。计算机中所有程序的运行都是在内存中进行的,因此内存对计算机的影响非常大,内存又被称为主存,其作用是存放 CPU 中的运算数据,以及与硬盘等外部存储设备交换的数据。只要计算机在运行中,CPU 就会把需要运算的数据调到主存中进行运算,当运算完成后CPU再将结果传送出来,主存的运行也决定了计算机的稳定运行。
二、内存的物理结构

内存的内部是由各种IC电路组成的,它的种类很庞大,但是其主要分为三种存储器
- 随机存储器(RAM): 内存中最重要的一种,表示既可以从中读取数据,也可以写入数据。当机器关闭时,内存中的信息会
丢失。 - 只读存储器(ROM):ROM 一般只能用于数据的读取,不能写入数据,但是当机器停电时,这些数据不会丢失。
- 高速缓存(Cache):Cache 也是我们经常见到的,它分为一级缓存(L1 Cache)、二级缓存(L2 Cache)、三级缓存(L3 Cache)这些数据,它位于内存和 CPU 之间,是一个读写速度比内存
更快的存储器。当 CPU 向内存写入数据时,这些数据也会被写入高速缓存中。当 CPU 需要读取数据时,会直接从高速缓存中直接读取,当然,如需要的数据在Cache中没有,CPU会再去读取内存中的数据。
内存 IC 是一个完整的结构,它内部也有电源、地址信号、数据信号、控制信号和用于寻址的 IC 引脚来进行数据的读写。下面是一个虚拟的 IC 引脚示意图
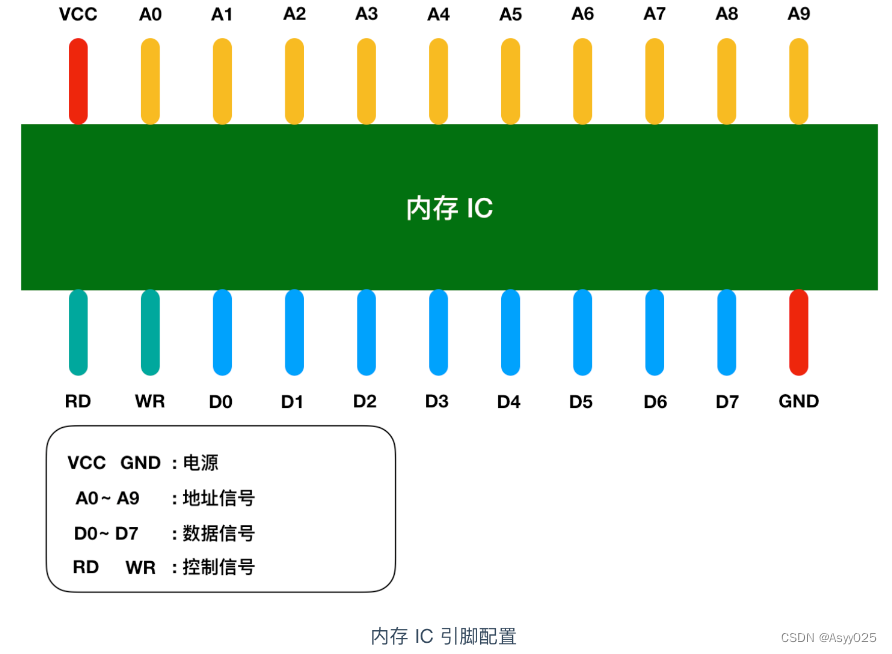
图中 VCC 和 GND 表示电源,A0 - A9 是地址信号的引脚,D0 - D7 表示的是数据信号、RD 和 WR 都是控制信号,我用不同的颜色进行了区分,将电源连接到 VCC 和 GND 后,就可以对其他引脚传递 0 和 1 的信号,大多数情况下,+5V 表示1,0V 表示 0。
我们都知道内存是用来存储数据,那么这个内存 IC 中能存储多少数据呢?D0 - D7 表示的是数据信号,也就是说,一次可以输入输出 8 bit = 1 byte 的数据。A0 - A9 是地址信号共十个,表示可以指定 00000 00000 - 11111 11111 共 2 的 10次方 = 1024个地址。每个地址都会存放 1 byte 的数据,因此我们可以得出内存 IC 的容量就是 1 KB。
如果我们使用的是 512 MB 的内存,这就相当于是 512000(512 * 1000) 个内存 IC。当然,一台计算机不太可能有这么多个内存 IC ,然而,通常情况下,一个内存 IC 会有更多的引脚,也就能存储更多数据。
内存的读写过程
让我们把关注点放在内存 IC 对数据的读写过程上来吧!我们来看一个对内存IC 进行数据写入和读取的模型
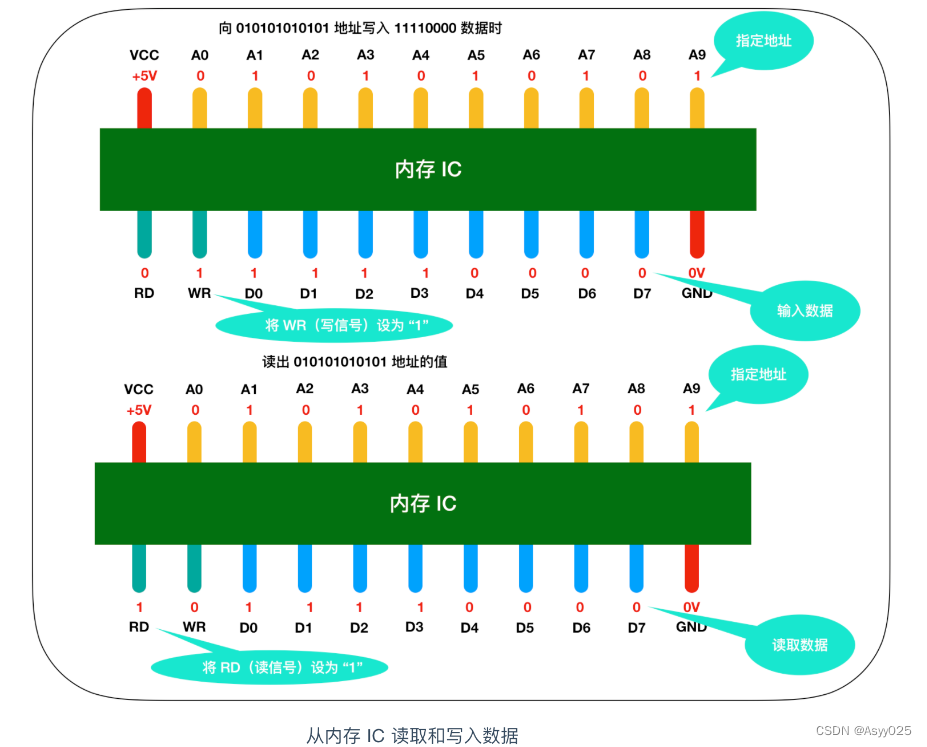
假设要向内存 IC 中写入 1byte 的数据的话,它的过程是这样的:
- 首先给 VCC 接通 +5V 的电源,给 GND 接通 0V 的电源,使用
A0 - A9来指定数据的存储场所,然后再把数据的值输入给D0 - D7的数据信号,并把WR(write)的值置为 1,执行完这些操作后,即可以向内存 IC 写入数据- 读出数据时,只需要通过 A0 - A9 的地址信号指定数据的存储场所,然后再将 RD 的值置为 1 即可。
- 图中的 RD 和 WR 又被称为控制信号。其中当WR 和 RD 都为 0 时,无法进行写入和读取操作。
内存的现实模型
为了便于记忆,我们把内存模型映射成为我们现实世界的模型,在现实世界中,内存的模型很想我们生活的楼房。在这个楼房中,1层可以存储一个字节的数据,楼层号就是地址,下面是内存和楼层整合的模型图

程序中的数据不仅只有数值,还有数据类型的概念,从内存上来看,就是占用内存大小(占用楼层数)的意思。即使物理上强制以 1 个字节为单位来逐一读写数据的内存,在程序中,通过指定其数据类型,也能实现以特定字节数为单位来进行读写。
下面是一个以特定字节数为例来读写指令字节的程序的示例
// 定义变量
char a;
short b;
long c;
// 变量赋值
a = 123;
b = 123;
c = 123;分别声明了三个变量 a,b,c ,并给每个变量赋上了相同的 123,这三个变量表示内存的特定区域。通过变量,即使不指定物理地址,也可以直接完成读写操作,操作系统会自动为变量分配内存地址。
这三个变量分别表示 1 个字节长度的 char,2 个字节长度的 short,表示4 个字节的 long。因此,虽然数据都表示的是 123,但是其存储时所占的内存大小是不一样的。如下所示
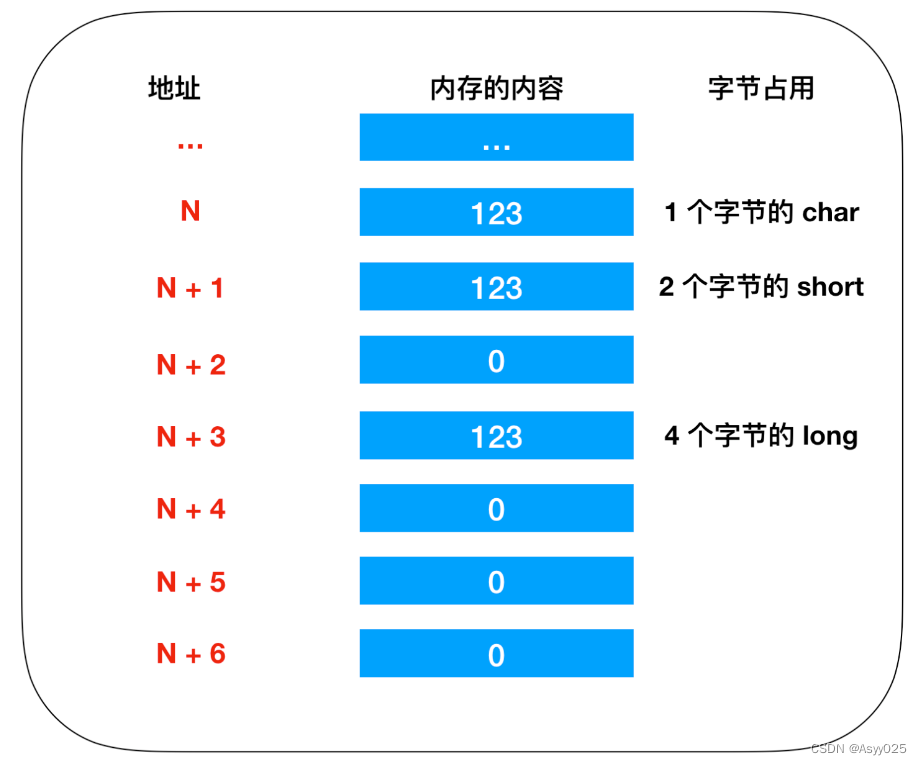
这里的 123 都没有超过每个类型的最大长度,所以 short 和 long 类型为所占用的其他内存空间分配的数值是0,这里我们采用的是低字节序列的方式存储
低字节序列:将数据低位存储在内存低位地址。
高字节序列:将数据的高位存储在内存地位的方式称为高字节序列。
三、内存的使用
指针
指针是 C 语言非常重要的特征,指针也是一种变量,只不过它所表示的不是数据的值,而是内存的地址。通过使用指针,可以对任意内存地址的数据进行读写。
在了解指针读写的过程前,我们先需要了解如何定义一个指针,和普通的变量不同,在定义指针时,我们通常会在变量名前加一个 * 号。例如我们可以用指针定义如下的变量
char *d; // char类型的指针 d 定义
short *e; // short类型的指针 e 定义
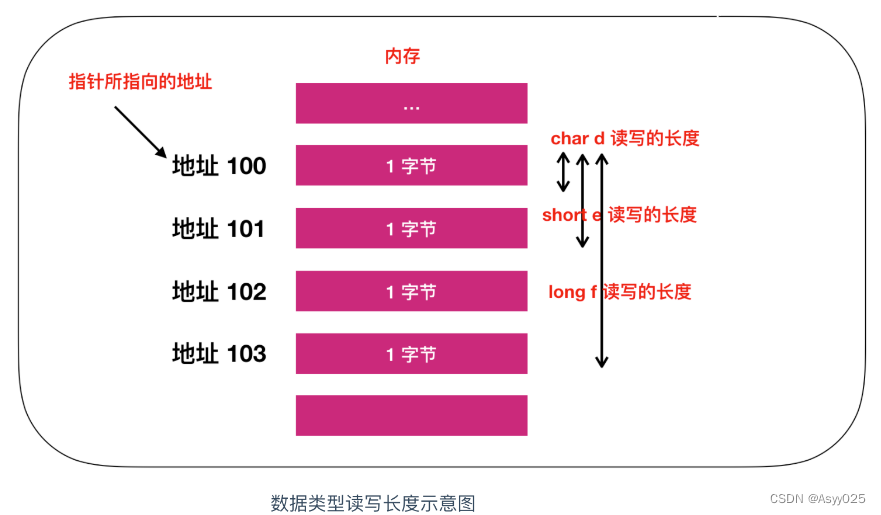
long *f; // long类型的指针 f 定义我们以32位计算机为例,32位计算机的内存地址是 4 字节,在这种情况下,指针的长度也是 32 位。然而,变量 d e f 却代表了不同的字节长度,这是为什么呢?
实际上,这些数据表示的是从内存中一次读取的字节数,比如 d e f 的值都为 100,那么使用 char 类型时就能够从内存中读写 1 byte 的数据,使用 short 类型就能够从内存读写 2 字节的数据, 使用 long 就能够读写 4 字节的数据,下面是一个完整的类型字节表
| 类型 | 32位 | 64位 |
|---|---|---|
| char | 1 | 1 |
| short int | 2 | 2 |
| int | 4 | 4 |
| unsigned int | 4 | 4 |
| float | 4 | 4 |
| double | 8 | 8 |
| long | 4 | 8 |
| long long | 8 | 8 |
| unsigned long | 4 | 8 |
我们可以用图来描述一下这个读写过程
数组是内存的实现
数组是指多个相同的数据类型在内存中连续排列的一种形式。作为数组元素的各个数据会通过下标编号来区分,这个编号也叫做索引,如此一来,就可以对指定索引的元素进行读写操作。
首先先来认识一下数组,我们还是用 char、short、long 三种元素来定义数组,数组的元素用[value] 扩起来,里面的值代表的是数组的长度,就像下面的定义
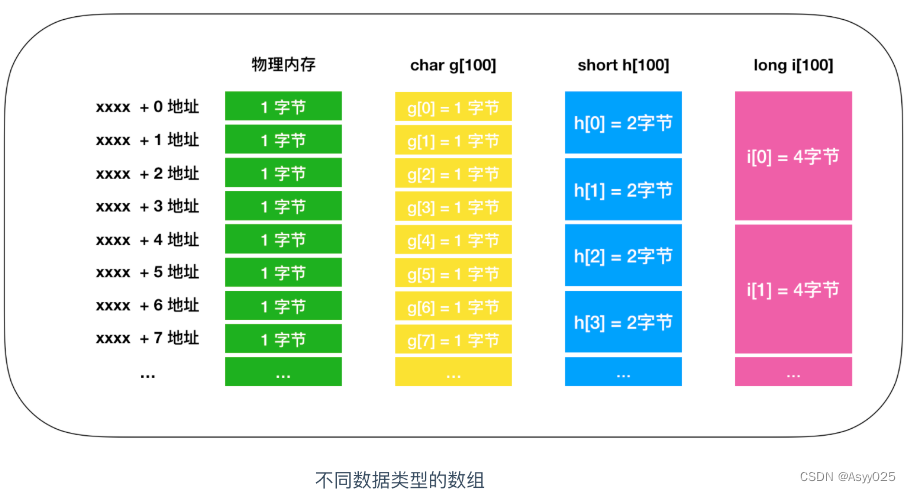
char g[100];
short h[100];
long i[100];数组定义的数据类型,也表示一次能够读写的内存大小,char 、short 、long 分别以 1 、2 、4 个字节为例进行内存的读写。
数组是内存的实现,数组和内存的物理结构完全一致,尤其是在读写1个字节的时候,当字节数超过 1 时,只能通过逐个字节来读取,下面是内存的读写过程
栈和队列
我们上面提到数组是内存的一种实现,使用数组能够使编程更加高效,下面我们就来认识一下其他数据结构,通过这些数据结构也可以操作内存的读写。
栈
栈(stack)是一种很重要的数据结构,栈采用 LIFO(Last In First Out)即后入先出的方式对内存进行操作。
栈的数据结构就是这样,你把书籍压入收纳箱的操作叫做压入(push),你把书籍从收纳箱取出的操作叫做弹出(pop),它的模型图大概是这样
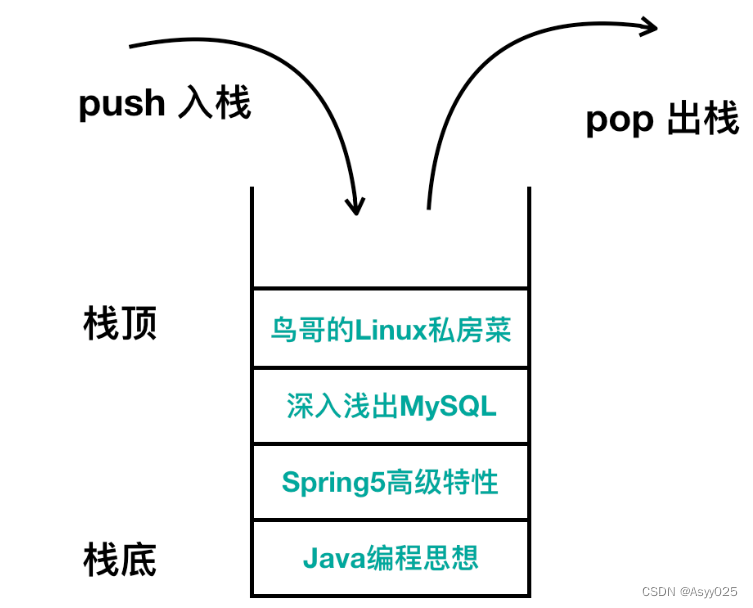
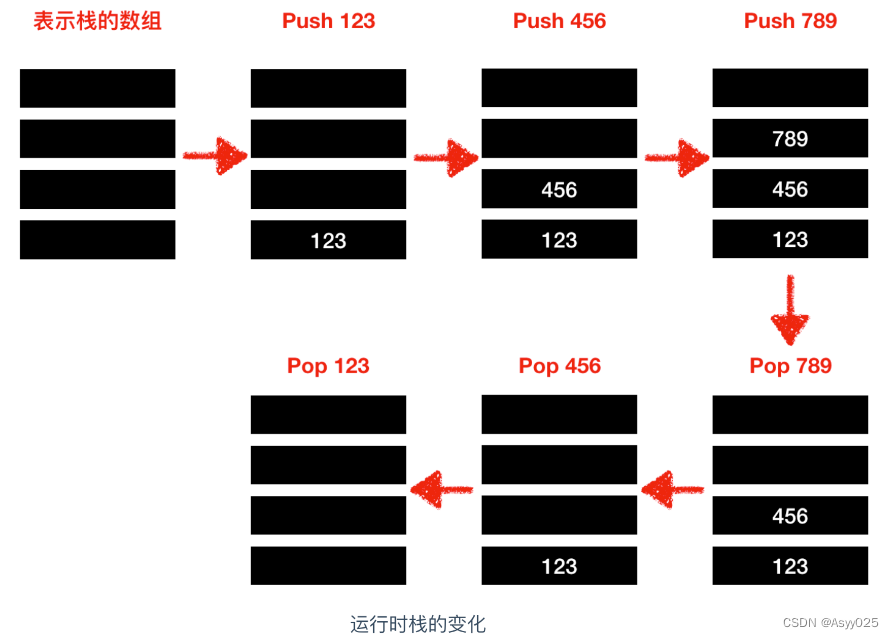
入栈相当于是增加操作,出栈相当于是删除操作,只不过叫法不一样。栈和内存不同,它不需要指定元素的地址。它的大概使用如下
// 压入数据
Push(123);
Push(456);
Push(789);
// 弹出数据
j = Pop();
k = Pop();
l = Pop();在栈中,LIFO 方式表示栈的数组中所保存的最后面的数据(Last In)会被最先读取出来(First On)。
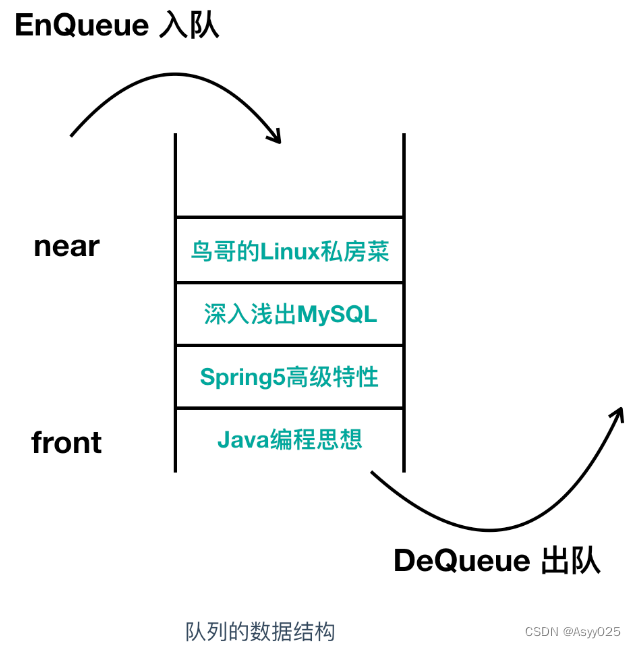
队列
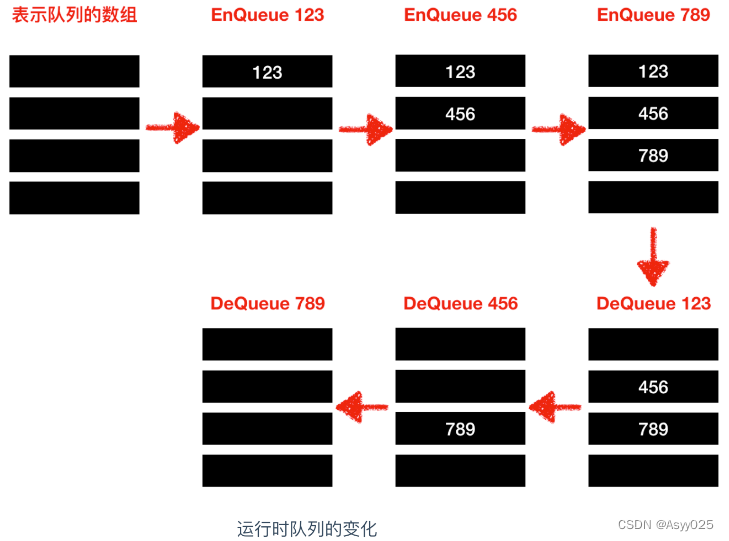
队列和栈很相似但又不同,相同之处在于队列也不需要指定元素的地址,不同之处在于队列是一种 先入先出(First In First Out) 的数据结构。队列在我们生活中的使用很像是我们去景区排队买票一样,第一个排队的人最先买到票,以此类推,俗话说: 先到先得。它的使用如下
// 往队列中写入数据
EnQueue(123);
EnQueue(456);
EnQueue(789);
// 从队列中读出数据
m = DeQueue();
n = DeQueue();
o = DeQueue();向队列中写入数据称为 EnQueue()入列,从队列中读出数据称为DeQueue()。
与栈相对,FIFO 的方式表示队列中最先所保存的数据会优先被读取出来。
队列的实现一般有两种:顺序队列 和 循环队列,我们上面的事例使用的是顺序队列,那么下面看一下循环队列的实现方式
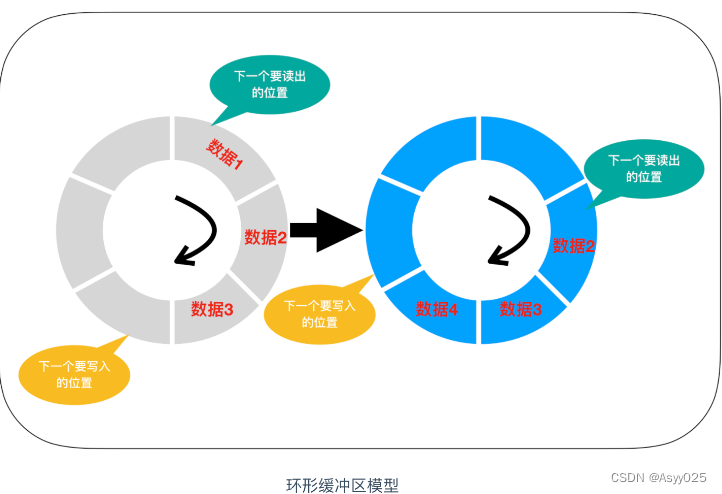
环形缓冲区
循环队列一般是以环状缓冲区(ring buffer)的方式实现的,它是一种用于表示一个固定尺寸、头尾相连的缓冲区的数据结构,适合缓存数据流。假如我们要用 6 个元素的数组来实现一个环形缓冲区,这时可以从起始位置开始有序的存储数据,然后再按照存储时的顺序把数据读出。在数组的末尾写入数据后,后一个数据就会从缓冲区的头开始写。这样,数组的末尾和开头就连接了起来。
链表
下面我们来介绍一下链表和 二叉树,它们都是可以不用考虑索引的顺序就可以对元素进行读写的方式。通过使用链表,可以高效的对数据元素进行添加 和 删除操作。而通过使用二叉树,则可以更高效的对数据进行检索。
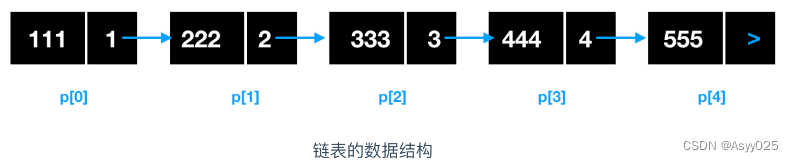
在实现数组的基础上,除了数据的值之外,通过为其附带上下一个元素的索引,即可实现链表。数据的值和下一个元素的地址(索引)就构成了一个链表元素,如下所示
对链表的添加和删除都是非常高效的,我们来叙述一下这个添加和删除的过程,假如我们要删除地址为 p[2] 的元素,链表该如何变化呢?

我们可以看到,删除地址为 p[2] 的元素后,直接将链表剔除,并把 p[2] 前一个位置的元素 p[1] 的指针域指向 p[2] 下一个链表元素的数据区即可。
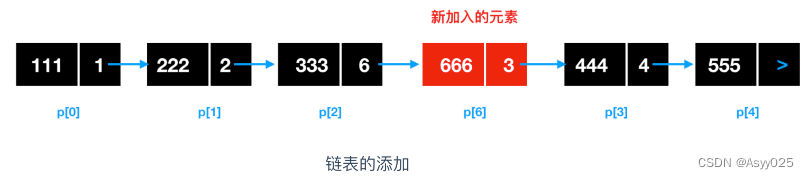
那么对于新添加进来的链表,需要确定插入位置,比如要在 p[2] 和 p[3] 之间插入地址为 p[6] 的元素,需要将 p[6] 的前一个位置 p[2] 的指针域改为 p[6] 的地址,然后将 p[6] 的指针域改为 p[3] 的地址即可。
链表的添加不涉及到数据的移动,所以链表的添加和删除很快,而数组的添加设计到数据的移动,所以比较慢,通常情况下,使用数组来检索数据,使用链表来进行添加和删除操作。
二叉树
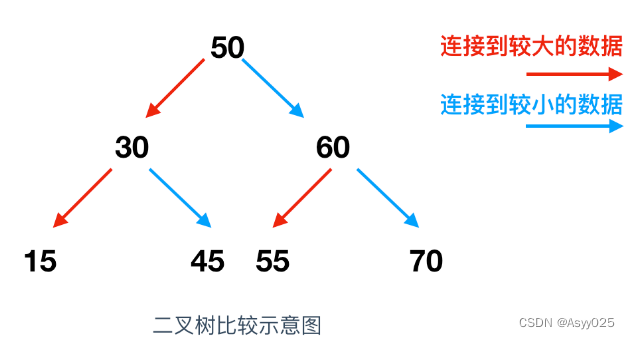
二叉树也是一种检索效率非常高的数据结构,二叉树是指在链表的基础上往数组追加元素时,考虑到数组的大小关系,将其分成左右两个方向的表现形式。假如我们把 50 这个值保存到了数组中,那么,如果接下来要进行值写入的话,就需要和50比较,确定谁大谁小,比50数值大的放右边,小的放左边,下图是二叉树的比较示例
二叉树是由链表发展而来,因此二叉树在追加和删除元素方面也是同样有效的。
磁盘
认识磁盘
计算机的五大基础部件是 存储器、控制器、运算器、输入和输出设备,其中从存储功能的角度来看,可以把存储器分为内存和 磁盘。
磁盘和内存都具有存储功能,它们都是存储设备。区别在于,内存是通过电流 来实现存储;磁盘则是通过磁记录技术来实现存储。内存是一种高速,造假昂贵的存储设备;而磁盘则是速度较慢、造假低廉的存储设备;电脑断电后,内存中的数据会丢失,而磁盘中的数据可以长久保留。内存是属于内部存储设备,硬盘是属于 外部存储设备。一般在我们的计算机中,磁盘和内存是相互配合共同作业的。
一般内存指的就是主存(负责存储CPU中运行的程序和数据);早起的磁盘指的是软磁盘(soft disk,简称软盘

如今常用的磁盘是硬磁盘(hard disk,简称硬盘),就是下面这个

程序不读入内存就无法运行
程序被保存在存储设备中,通过使用 CPU 读入来实现程序指令的执行。这种机制称为存储程序方式,现在看来这种方式是理所当然的,但在以前程序的运行都是通过改变计算机的布线来读写指令的。
计算机最主要的存储部件是内存和磁盘。磁盘中存储的程序必须加载到内存中才能运行,在磁盘中保存的程序是无法直接运行的,这是因为负责解析和运行程序内容的 CPU 是需要通过程序计数器来指定内存地址从而读出程序指令的。
磁盘构件
磁盘缓存
磁盘往往和内存是互利共生的关系,每次内存都需要从磁盘中读取数据,必然会读到相同的内容,所以一定会有一个角色负责存储我们经常需要读到的内容。 做软件的时候经常会用到缓存技术,那么硬件层面也不例外,磁盘也有缓存,磁盘的缓存叫做磁盘缓存。
磁盘缓存指的是把从磁盘中读出的数据存储到内存的方式,这样一来,当接下来需要读取相同的内容时,就不会再通过实际的磁盘,而是通过磁盘缓存来读取。某一种技术或者框架的出现势必要解决某种问题的,那么磁盘缓存就大大改善了磁盘访问的速度。
Windows 操作系统提供了磁盘缓存技术,不过,对于大部分用户来说是感受不到磁盘缓存的,并且随着计算机的演进,对硬盘的访问速度也在不断演进,实际上磁盘缓存到 Windows 95/98 就已经不怎么使用了。
把低速设备的数据保存在高速设备中,需要时可以直接将其从高速设备中读出,这种缓存方式在web中应用比较广泛,web 浏览器是通过网络来获取远程 web 服务器的数据并将其显示出来。因此,在读取较大的图片的时候,会耗费不少时间,这时 web 浏览器可以把获取的数据保存在磁盘中,然后根据需要显示数据,再次读取的时候就不用重新加载了。
虚拟内存
虚拟内存是内存和磁盘交互的第二个媒介。虚拟内存是指把磁盘的一部分作为假想内存来使用。这与磁盘缓存是假想的磁盘(实际上是内存)相对,虚拟内存是假想的内存(实际上是磁盘)。
虚拟内存是计算机系统内存管理的一种技术。它使得应用程序认为它拥有连续可用的内存(一个完整的地址空间),但是实际上,它通常被分割成多个物理碎片,还有部分存储在外部磁盘管理器上,必要时进行数据交换。
计算机中的程序都要通过内存来运行,如果程序占用内存很大,就会将内存空间消耗殆尽。为了解决这个问题,WINDOWS 操作系统运用了虚拟内存技术,通过拿出一部分硬盘来当作内存使用,来保证程序耗尽内存仍然有可以存储的空间。虚拟内存在硬盘上的存在形式就是 PAGEFILE.SYS 这个页面文件。
通过借助虚拟内存,在内存不足时仍然可以运行程序。例如,在只剩 5MB 内存空间的情况下仍然可以运行 10MB 的程序。由于 CPU 只能执行加载到内存中的程序,因此,虚拟内存的空间就需要和内存中的空间进行置换(swap),然后运行程序。
虚拟内存与内存的交换方式
刚才我们提到虚拟内存需要和内存中的部分内容做置换才可让 CPU 继续执行程序,那么做置换的方式是怎样的呢?又分为哪几种方式呢?
虚拟内存的方法有分页式 和 分段式 两种。Windows 采用的是分页式。该方式是指在不考虑程序构造的情况下,把运行的程序按照一定大小的页进行分割,并以页为单位进行置换。在分页式中,我们把磁盘的内容读到内存中称为 Page In,把内存的内容写入磁盘称为 Page Out。Windows 计算机的页大小为 4KB ,也就是说,需要把应用程序按照 4KB 的页来进行切分,以页(page)为单位放到磁盘中,然后进行置换。
为了实现内存功能,Windows 在磁盘上提供了虚拟内存使用的文件(page file,页文件)。该文件由 Windows 生成和管理,文件的大小和虚拟内存大小相同,通常大小是内存的 1 - 2 倍。
节约内存
Windows 是以图形界面为基础的操作系统。它的前身是 MS-DOC,最初的版本可以在 128kb 的内存上运行程序,但是现在想要 Windows 运行流畅的花至少要需要 512MB 的内存,但通常往往是不够的。
也许许多人认为可以使用虚拟内存来解决内存不足的情况,而虚拟内存确实能够在内存不足的时候提供补充,但是使用虚拟内存的 Page In 和 Page Out 通常伴随着低速的磁盘访问,这是一种得不偿失的表现。所以虚拟内存无法从根本上解决内存不足的情况。
为了从根本上解决内存不足的情况,要么是增加内存的容量,加内存条;要么是优化应用程序,使其尽可能变小。第一种建议往往需要衡量口袋的银子,所以我们只关注第二种情况。
注意:以下的篇幅会涉及到 C 语言的介绍,是每个程序员(不限语言)都需要知道和了解的知识。
通过 DLL 文件实现函数共有
DLL(Dynamic Link Library)文件,是一种动态链接库 文件,顾名思义,是在程序运行时可以动态加载 Library(函数和数据的集合)的文件。此外,多个应用可以共有同一个 DLL 文件。而通过共有一个 DLL 文件则可以达到节约内存的效果。
例如,假设我们编写了一个具有某些处理功能的函数 MyFunc()。应用 A 和 应用 B 都需要用到这个函数,然后在各自的应用程序中内置 MyFunc()(这个称为Static Link,静态链接)后同时运行两个应用,内存中就存在了同一个函数的两个程序,这会造成资源浪费。
为了改变这一点,使用 DLL 文件而不是应用程序的执行文件(EXE文件)。因为同一个 DLL 文件内容在运行时可以被多个应用共有,因此内存中存在函数 MyFunc()的程序就只有一个
Windows 操作系统其实就是无数个 DLL 文件的集合体。有些应用在安装时,DLL文件也会被追加。应用程序通过这些 DLL 文件来运行,既可以节约内存,也可以在不升级 EXE 文件的情况下,通过升级 DLL 文件就可以完成更新。
通过调用 _stdcall 来减少程序文件的大小
通过调用 _stdcall 来减小程序文件的方法,是用 C 语言编写应用时可以利用的高级技巧。我们来认识一下什么是 _stdcall。
_stdcall 是 standard call(标准调用)的缩写。Windows 提供的 DLL 文件内的函数,基本上都是通过 _stdcall 调用方式来完成的,这主要是为了节约内存。另一方面,用 C 语言编写的程序默认都不是 _stdcall 。C 语言特有的调用方式称为 C 调用。C 语言默认不使用 _stdcall 的原因是因为 C 语言所对应的函数传入参数是可变的,只有函数调用方才能知道到底有多少个参数,在这种情况下,栈的清理作业便无法进行。不过,在 C 语言中,如果函数的参数和数量固定的话,指定 _stdcall 是没有任何问题的。
C 语言和 Java 最主要的区别之一在于 C 语言需要人为控制释放内存空间
C 语言中,在调用函数后,需要人为执行栈清理指令。把不需要的数据从接收和传递函数的参数时使用的内存上的栈区域中清理出去的操作叫做 栈清理处理。
例如如下代码
// 函数调用方
void main(){
int a;
a = MyFunc(123,456);
}
// 被调用方
int MyFunc(int a,int b){
...
}代码中,从 main 主函数调用到 MyFunc() 方法,按照默认的设定,栈的清理处理会附加在 main 主函数这一方。在同一个程序中,有可能会多次调用,导致 MyFunc() 会进行多次清理,这就会造成内存的浪费。
汇编之后的代码如下
push 1C8h // 将参数 456( = 1C8h) 存入栈中
push 7Bh // 将参数 123( = 7Bh) 存入栈中
call @LTD+15 (MyFunc)(00401014) // 调用 MyFunc 函数
add esp,8 // 运行栈清理C 语言通过栈来传递函数的参数,使用 push 是往栈中存入数据的指令,pop 是从栈中取出数据的指令。32 位 CPU 中,1次 push 指令可以存储 4 个字节(32 位)的数据。上述代码由于进行了两次 push 操作,所以存储了 8 字节的数据。通过 call 指令来调用函数,调用完成后,栈中存储的数据就不再需要了。于是就通过 add esp,8 这个指令,使存储着栈数据的 esp 寄存器前进 8 位(设定为指向高 8 位字节的地址),来进行数据清理。由于栈是在各种情况下都可以利用的内存领域,因此使用完毕后有必要将其恢复到原始状态。上述操作就是执行栈的清理工作。另外,在 C 语言中,函数的返回值,是通过寄存器而非栈来返回的。
栈执行清理工作,在调用方法处执行清理工作和在反复调用方法处执行清理工作不同,使用 _stdcall 标准调用的方式称为反复调用方法,在这种情况下执行栈清理开销比较小。
磁盘的物理结构
之前我们介绍了CPU、内存的物理结构,现在我们来介绍一下磁盘的物理结构。磁盘的物理结构指的是磁盘存储数据的形式。
磁盘是通过其物理表面划分成多个空间来使用的。划分的方式有两种:可变长方式 和 扇区方式。前者是将物理结构划分成长度可变的空间,后者是将磁盘结构划分为固定长度的空间。一般 Windows 所使用的硬盘和软盘都是使用扇区这种方式。扇区中,把磁盘表面分成若干个同心圆的空间就是 磁道,把磁道按照固定大小的存储空间划分而成的就是 扇区
扇区是对磁盘进行物理读写的最小单位。Windows 中使用的磁盘,一般是一个扇区 512 个字节。不过,Windows 在逻辑方面对磁盘进行读写的单位是扇区整数倍簇。根据磁盘容量不同功能,1簇可以是 512 字节(1 簇 = 1扇区)、1KB(1簇 = 2扇区)、2KB、4KB、8KB、16KB、32KB( 1 簇 = 64 扇区)。簇和扇区的大小是相等的。
不管是硬盘还是软盘,不同的文件是不能存储在同一簇中的,否则就会导致只有一方的文件不能删除。所以,不管多小的文件,都会占用 1 簇的空间。这样一来,所有的文件都会占用 1 簇的整数倍的空间。
我们使用软盘做实验会比较简单一些,我们先对软盘进行格式化。
接下来,我们保存一个 txt 文件,并在文件输入一个字符,这时候文件其实只占用了一个字节,但是我们看一下磁盘的属性却占用了 512 字节
然后我们继续写入一些东西,当文件大小到达 512 个字节时,已用空间也是 512 字节,但是当我们继续写入一个字符时,我们点开属性会发现磁盘空间会变为 1024 个字节(= 2 簇),通过这个实验我们可以证明磁盘是以簇为单位来保存的。















 2871
2871











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









