







一、语法分析
语法分析是自然语言处理中一个重要的任务,其目的是分析句子的语法结构并将其表示为容易理解的结构。语法分析是所有工具性NLP任务中较为高级、较为复杂的一种任务。
二、短语结构树
短语结构语法是分析句子如何产生的方法。由于语言满足复合性原理,通过分解句子为短语、分解短语为单词,下游应用将会得到更多更深层次的结构化信息。复合性定理是指,一个复杂表达式的意义是由其各个组成部分的意义以及用以结合它们的规则来决定的。
短语结构语法描述了如何自顶而下地生成一个句子。反过来,句子也可以用短语结构语法来递归地分解。比如这句话“上海 浦东 开发 与 法制 建设 同步”是如何分解的?如果将语法成分的边界用括号括起来,这句话的基本短语结构为这样的一种主谓结构“:主语是短语(上海 浦东)( 开发 与 法制 建设)”,谓语是动词“同步”。如此,所有短语可以继续递归分解直到最小单元。由于词语不可再分,我们得到了最终的短语结构:“((上海 浦东)(开发 与 (法制 建设)))同步”。
这样的结构从上而下其实是一种树形结构。这样的树形结构称为短语结构树,相应的语法称为短语结构语法或上下文无关文法。
遗憾的是,虽然20世纪90年代大部分句法分析的研究工作都集中在短语结构树,但是由于短语结构语法比较复杂,相应的句法分析器的精度不高。因此,现在绝大部分研究者都转向了另一种语法形式:依存句法树。
三、依存句法树
不同于短语结构树,依存句法树并不关注如何生成句子这种宏大的命题。依存句法树只关注句子中句子中词语之间的语法联系,并将其约束为树形结构。
3.1 依存句法理论
依存句法理论认为,词与词之间存在主从关系,这是一种二元不等价关系。在句子中,如果一个词修饰另一个词,则称修饰词为从属词,被修饰的词语称为支配词。二者之间的语法关系称为依存关系。比如句子“大梦想”中形容词“大”与“梦想”便是从属词和支配词的关系。
现代依存语法中,语言学家对依存句法提出了四个约束性公理“
1.有且只有一个词语(ROOT,虚拟根节点,简称虚根)不依存于其他词语。
2.除此之外所有单词必须依存于其他单词。
3.每个单词不能依存于多个单词。
4.如果单词A依存于B,那么位置处于A和B之间的单词C只能依存于A、B或AB之间的单词。
这四条公理分别约束了依存句法树的根节点唯一性、连通性、无环性和投射性。这些约束对语料库的标注以及依存句法分析器的设计奠定了基础。
3.2 依存句法分析
依存句法分析指的是分析句子的依存语法的一种中高级NLP任务,其输入通常是词语和词性,输出则是一棵依存句法树。
(1)基于图的依存句法分析
正如树是图的特例一样,依存句法树其实是完全图的一个子图。如果为完全图中的每条边是否属于句法树的可能性打分,然后就可以利用Prim之类的算法找出最大生成树作为依存句法树了。这样将整棵树的分数分解为每条边上的分数之和,然后在图上搜索最优解的方法统称为基于图的方法。
基于图的依存句法分析通常需要一个特征提取器为每个单词提取特征,然后将每两个单词的特征向量交给分类器打分,作为他们之间依存关系的分数。在传统机器学习时代,基于图的依存句法分析器往往面临运行开销大的问题。这是由于传统机器学习的所依赖的特征过于稀疏,训练算法往往需要在整个图上进行全局的结构化预测等。考虑到这一问题,另一种基于转移的路线在传统机器学习框架下显得更为实用。
(2)基于转移的依存句法分析
我们以”人吃鱼“为例,构建句法依存树,假定每一步只能操作两个单词,那么按顺序发生的步骤如下。
(1)从‘人’连线到‘吃’建立依存关系,标记为‘主谓关系’。
(2)从‘吃’连线到‘鱼’建立依存关系,标记为‘动宾关系’。
如此,我们将一颗依存句法树的构建过程表示为两个动作。如果机器学习模型能够根据句子的某些特征准确地预测这些动作,那么计算机便能够根据这些动作拼装出正确的依存句法树了。这样的拼装动作称为转移。而这类算法统称为基于转移的依存句法分析。
四、基于转移的句法分析
虽然基于转移的依存句法分析涉及许多组件,但其原理依然属于监督学习的范畴。我们先定义一台虚拟的机器,这台机器根据自己的状态和输入的单词预测下一步要执行的转移动作,最后根据转移动作拼接句法树
4.1 Arc-Eager转移系统
一个转移系统
S
S
S由四个部件构成:
S
=
(
C
,
T
,
f
,
s
)
S=(C,T,f,s)
S=(C,T,f,s)。其中:
1.
C
C
C是系统状态的集合;
2
T
T
T是所有可执行的转移动作的集合,每个转移动作都可以视为输入输出都为系统状态的函数;
3.
f
f
f是一个初始化函数,将一个句子转换为一个初始的系统状态;
4.
s
s
s是集合
C
C
C中一系列的终止状态,系统进入这些状态后即可停机输出最终的动作序列。
该系统的终止状态为
s
s
s=
(
n
u
l
l
,
R
O
O
T
,
A
)
{(null,{ROOT},A)}
(null,ROOT,A),即栈为空且队列仅剩下虚根时的状态。
4.2 特征提取
在传统机器学习时代,我们一般利用手工定制的特征模板提取特征。依存句法也不例外。依存句法的特征一般涉及栈顶或者队首单词的子节点,当然还可以拓展到这些单词与孙节点的各种组合。
除了单词本身的特征之外,还可以根据单词的聚类信息作为特征。之前介绍了文本聚类的概念和算法,其实对于单词本身,也可以聚类。对单词聚类时,常用的算法为Brown聚类算法。
Brown聚类算法的原理是利用相似单词的左右上下文也相似的这一语言现象来进行层次化聚类。定义词表为
V
V
V,单词
w
w
w的簇为
C
(
w
)
C(w)
C(w),Brown聚类算法尝试找出一个将词表划分为
k
k
k个簇的映射
C
C
C:
V
−
>
1
,
2
,
.
.
.
.
.
.
k
V-> {1,2,......k}
V−>1,2,......k,使得语料库在下列语言模型下的似然概率最高:

最重要的东西就是分类器C,怎么衡量C的好坏呢:
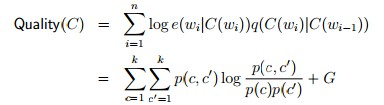
所以整个Brown算法的流程如下:
开始设置一个参数m,比如m=1000,我们按照词汇出现的频率对其进行排序
然后把频率最高的m个词各自分到一个类中,对于第m+1到|V|个词进行循环:
1.对当前词新建一个类,我们现在又m+1个类了
2.从这m+1个类中贪心选择最好的两个类合并(和方法1一个意思),现在我们剩下m个类
最后我们再做m-1词合并,就得到了我们一开始说的一串01编码所对应的树,可以转化为响应编码。
特征提取完毕之后,就可以交给分类器预测接下来要进行的转移动作了。
4.3 转移动作预测
特征提取完毕之后,接下来便是传统的机器学习预测分类步骤了。这一步可用的分类模型较多,如,感知机,支持向量机,朴素贝叶斯,Xgboost等等。这些属于机器学习领域的知识,此处就不再赘述啦。
五、依存句法的作用
很多人有一个疑问:依存句法分析究竟可以用来干什么?下面,就用一个实际的例子来说明依存句法分析的作用:我们往依存句法分析模型输入一个句子:‘电池非常棒,机身不长,长的是待机,但是屏幕分辨率不高。’,那么依存句法模型的输出结果为:
电池=棒
机身=不长
待机=长
分辨率=不高
至此,四个属性被完整正确地提取出来。















 6902
6902











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









