







依存句法分析
了解语言结构的不同角度就是依存句法结构,通过找到句子中每一个词语所依赖的部分来描述句子结构。如果一个词修饰另一个词,它就是那个词的依赖。例如barking dog中,barking就是dog的依赖。通常用箭头来表示他们的依赖关系,下面是一个画出依存结构的句子:

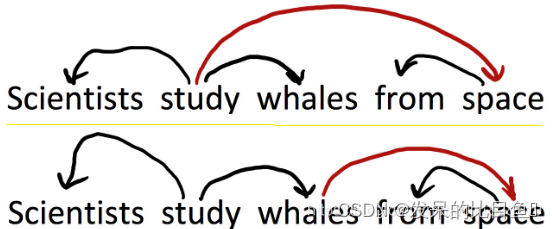
虽然这种做法低效,速度慢,而且没有基于短语结构文法的规则普适性好,但是这个行为形成了丰富的语言学资源,而且对于目前大火的机器学习来说,这就是我们梦寐以求的具有ground-truth的标注好的数据,这是一个相当具有前瞻性的工程。
在机器学习领域,依存树可以合理地解释句子结构。建议一个可见的、有标注的依存树,最后会给我们提供很多的优势,依存树存在的有点如下:
(1) 首先它可以被重复利用;而每个人写的规则却不同,所以规则不能被重复利用,依存树却可以。
(2) 依存树库使用了真实的、覆盖面广的数据;而人们写规则时只是依靠对语法的直觉判断,容易考虑不周。
(3) 依存树不仅仅能给出所有的可能性,还能给出各种可能性同事发生的概率。
(4) 最重要的一点是他可以评估我们构建的任何系统,因为他给了我们具有ground truth的标准数据。
依存句法树
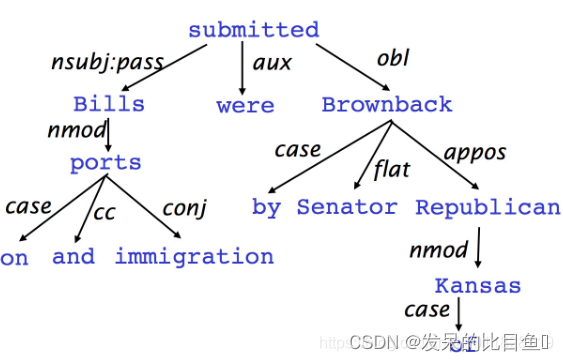
箭头的初始位置为被修饰的,称为:监督项(头部)
箭头的指向位置是修饰词,称为:下属项(独立项)
上图箭头指向的词语是依赖者,箭头初始位置的词语是被依赖者。也可以根据自己写喜好来颠倒用途。
依存句法分析方法 的 效果评估方法
评测指标有两种。一种是标准是UAS,此标准不考虑标签只考虑弧;另一种标准是LAS,此标准同时考虑标签和弧。
具体例子如下:
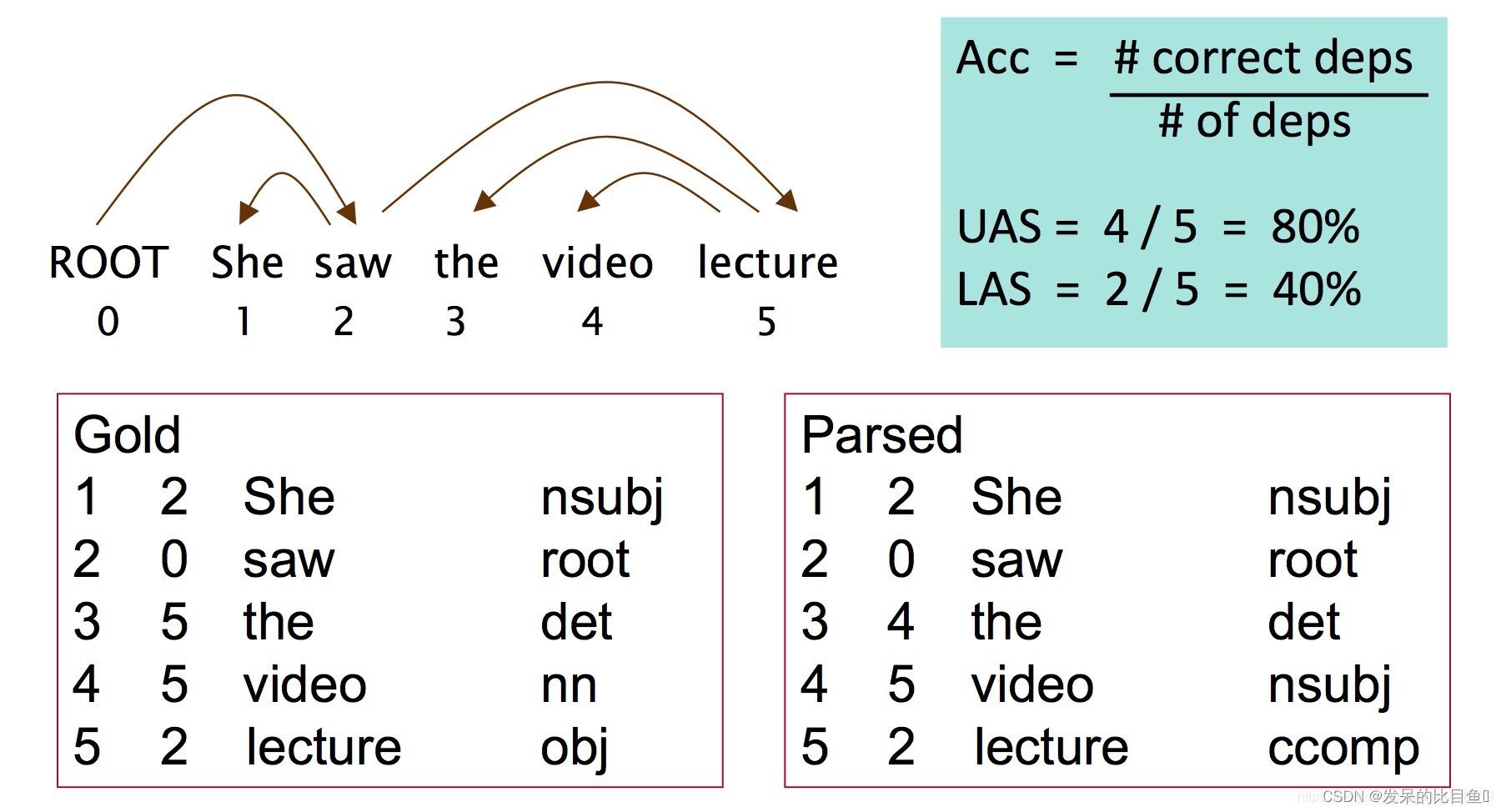
英文依存语法关系集
其中‘ROOT’,‘case’,‘det’,'nmod’等符号就是语法关系。
目前国际公认的语法关系定义框架是Universal Dependencies (UD)。英语的通用语法关系有37种:
| 语法关系 | 解释 | 链接 |
|---|---|---|
| nsubj | 名词主语 | nsubj |
| nsubjpass | 被动名词主语 | nsubjpass |
| obj | 宾语 | obj |
| iobj | 间接宾语 | iobj |
| csubj | 从句主语 | csubj |
| csubjpass | 被动从句主语 | csubjpass |
| ccomp | 从句补语 | ccomp |
| xcomp | 开放式补语 | xcomp |
| nummod | 数词修饰语 | nummod |
| appos | 介词修饰语 | appos |
| nmod | 标称修饰语 | nmod |
| acl | 名词从句修饰语 | acl |
| acl:relcl | 相对从句修饰语 | acl:relcl |
| amod | 形容词修饰语 | amod |
| det | 限定词 | det |
| det:predet | 前位限定词 | det:predet |
| neg | 否定修饰符 | neg |
| case | 格标记 | case |
| nmod | 标称修饰符 | nmod |
| nmod:npmod | 名词短语作为副词修饰语 | nmod:npmod |
| nmod:tmod | 时间修饰符 | nmod:tmod |
| nmod:poss | 所有格名词修饰符 | nmod:poss |
| advcl | 状语从句修饰语 | advcl |
| advmod | 状语修饰语 | advmod |
| compound | 复合标识符 | compound |
| compound:prt | 动词短语介副词 | compound:prt |
| flat | 由多个名词性元素组成的专有名词 | flat |
| fixed | 固定的语法化表达式 | fixed |
| foreign | 外来词 | foreign |
| goeswith | 与 | goeswith |
| list | 并列关系 | list |
| dislocated | 错位的元素 | dislocated |
| parataxis | 副词关系 | parataxis |
| orphan | 省略关系 | orphan |
| reparandum | (演讲中)不流利的地方 | reparandum |
| vocative 呼唤(人们) | vocative | |
| discourse | 话语元素 | discourse |
| expl | 专指 | expl |
| aux | 辅助词 | aux |
| auxpass | 被动辅助词 | auxpass |
| cop | 系词 | cop |
| mark | 标记词 | mark |
| punct | 标点符号 | punct |
| conj | 连词 | conj |
| cc | coordination | cc |
| cc:preconj | preconjunct | cc:preconj |
| root | 根节点 | root |
| dep | 无法确定两个词之间的更精确的依赖关系 | dep |
Spacy依存分析代码
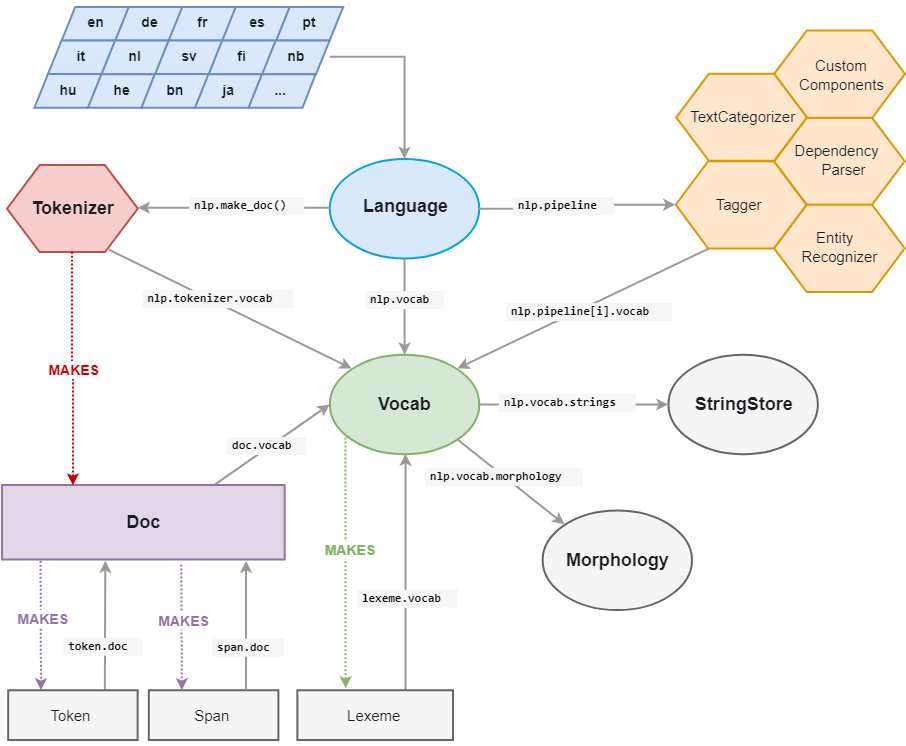
spaCy模块有4个非常重要的类:
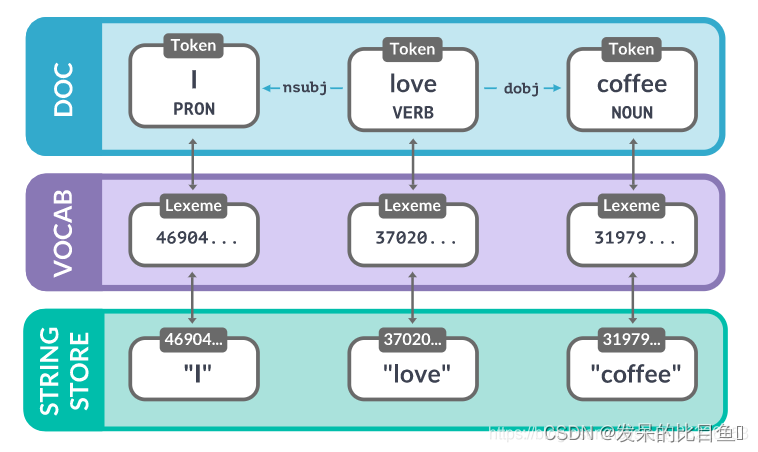
- Doc:Doc对象由Tokenizer构造,然后由管道的组件进行适当的修改。doc对象是token的序列
- Span:Span对象是Doc对象的一个切片。
- Token:在自然语言处理中,把一个单词,一个标点符号,一个空格等叫做一个token。
- Vocab:存储词汇表和语言共享的数据。词汇表使用Lexeme对象和StringStore对象来表示。
功能
- 找出活动的管道组件
nlp.pipe_names
- 禁用/添加管道组件
nlp.disable_pipes('tagger', 'parser') # 禁用
nlp.add_pipe("parser") # 添加
- 模型
# 方式一
import spacy
nlp = spacy.load("zh_core_web_sm")
# 方式二
import zh_core_web_sm
nlp = zh_core_web_sm.load()
- 依存分析
# -*- coding:utf8 -*-
import spacy
nlp = spacy.load('zh_core_web_sm')
doc = nlp('猴子喜欢香蕉')
for token in doc:
print("{0}/{1} <--{2}-- {3}/{4}".format(
token.text, token.tag_, token.dep_, token.head.text, token.head.tag_))
>>> 猴子/NN <--nsubj-- 喜欢/VV
>>> 喜欢/VV <--ROOT-- 喜欢/VV
>>> 香蕉/NN <--dobj-- 喜欢/VV
- 可视化
from spacy import displacy
txt = '''In particle physics, a magnetic monopole is a hypothetical elementary particle.'''
displacy.render(nlp(txt), style='dep', jupyter=True, options = {'distance': 90})
from spacy import displacy
displacy.render(doc, style='ent', jupyter=True)
参考
https://blog.csdn.net/u011828519/article/details/84565920


















 4788
4788

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











