







我的目标:调研目前目前使用多模态融合研究动作识别的方法,内容也以此为重点(不全文解析)。
论文标题:Human Action Recognition from Various DataModalities: A Review
论文地址: https://arxiv.org/abs/2012.11866
作者:Zehua Sun, Qiuhong Ke, Hossein Rahmani, Mohammed Bennamoun, Gang Wang, and Jun Liu
文章的主要内容:回顾了使用单一数据模式进行人工智能的主流深度学习架构,以及利用多种模式进行人工智能增强的方法。
数据类型分类
Visual Data Modalities: RGB, skeleton, depth, infrared, point cloud;
Non-Visual Data Modalities: event stream, audio, acceleration, radar, and WiFi signal .etc
不同数据模态的动作展示及其优缺点(Pros:优势,Cons:劣势)
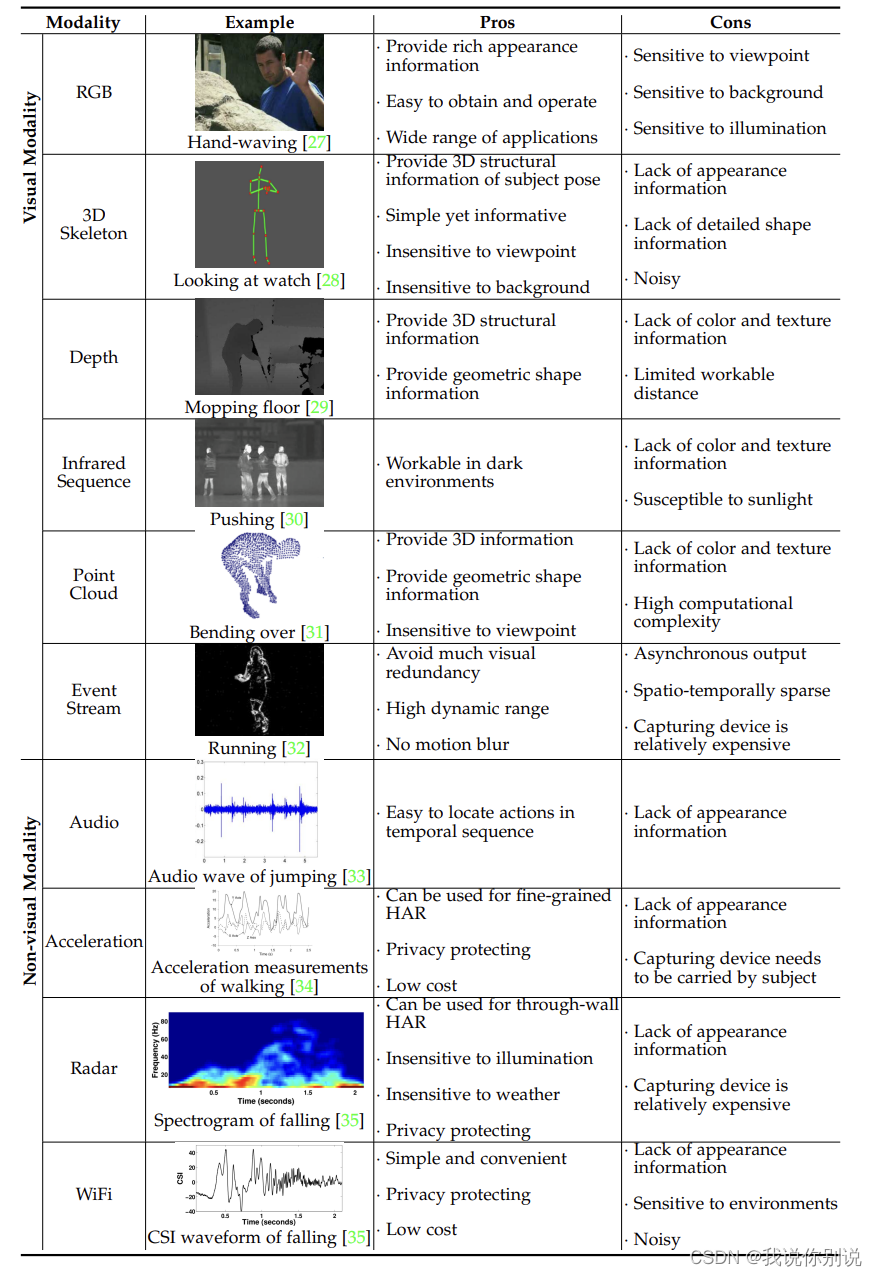
第二章为各数据类型单模态方法描述,这里不多过介绍,需要的可以自己拿上头链接看论文。
第三章多模态
1. 多模态学习方法分为:
融合:是指将来自两种或两种以上的训练和推理模式的信息进行整合。
联合学习: 是指知识在不同数据模式之间的转移。
2. 上述多模态的融合机制分为:
分数融合:集成了基于不同模态分别做出的决策,以产生最终的分类结果。(例如,通过加权平均或学习分数融合模型)。也可以称为后融合或者决策融合。
特征融合:通常结合来自不同模态的特征,以产生聚合特征,这些特征通常对HAR(Human Action Recognition)具有非常强的鉴别性。
注:数据融合,即在特征提取之前对多模态输入数据进行融合。由于输入数据可以被视为原始特征,所以该篇论文中将数据融合方法简单地分类为特征融合。
基于多模态融合的HAR方法比较和总结
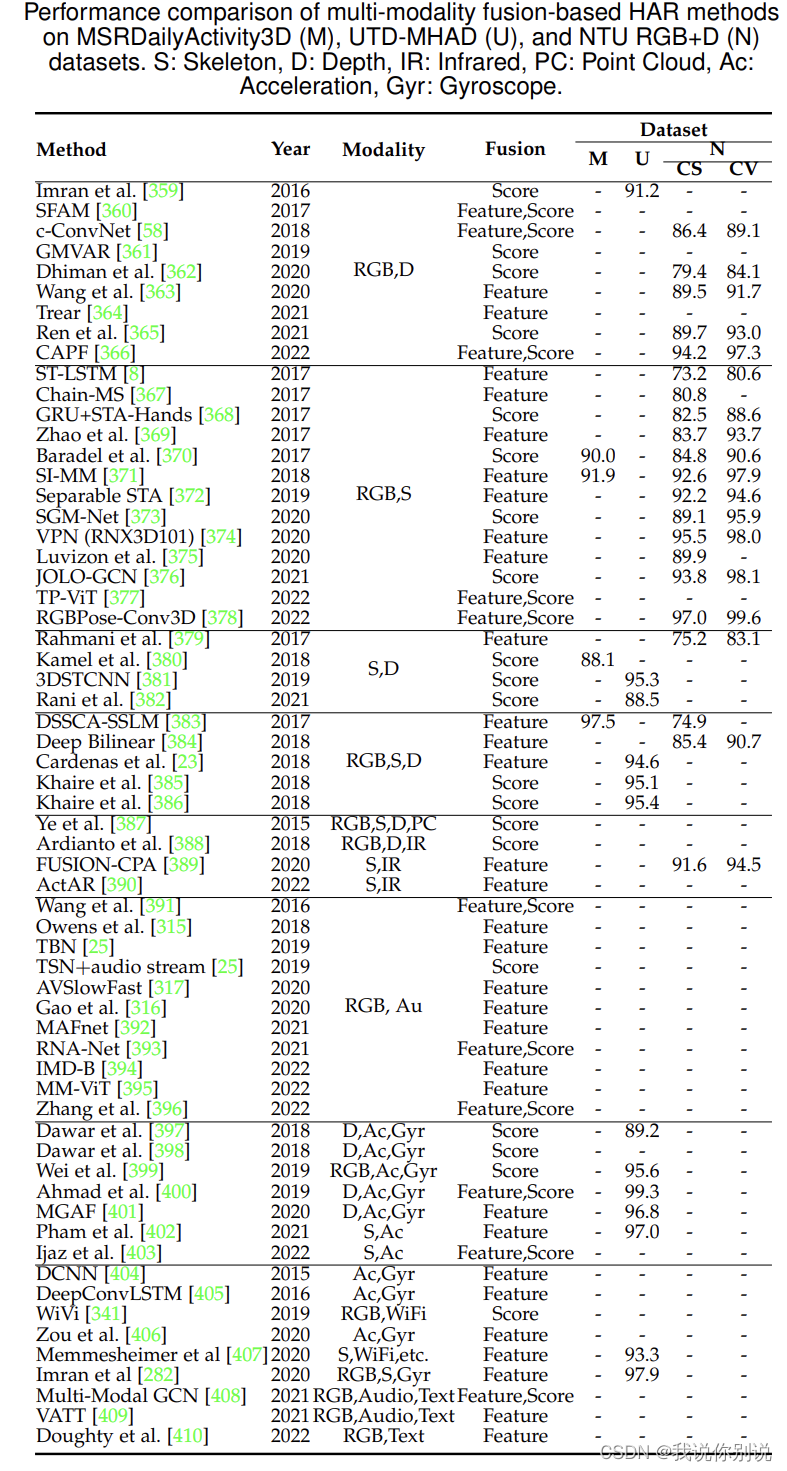
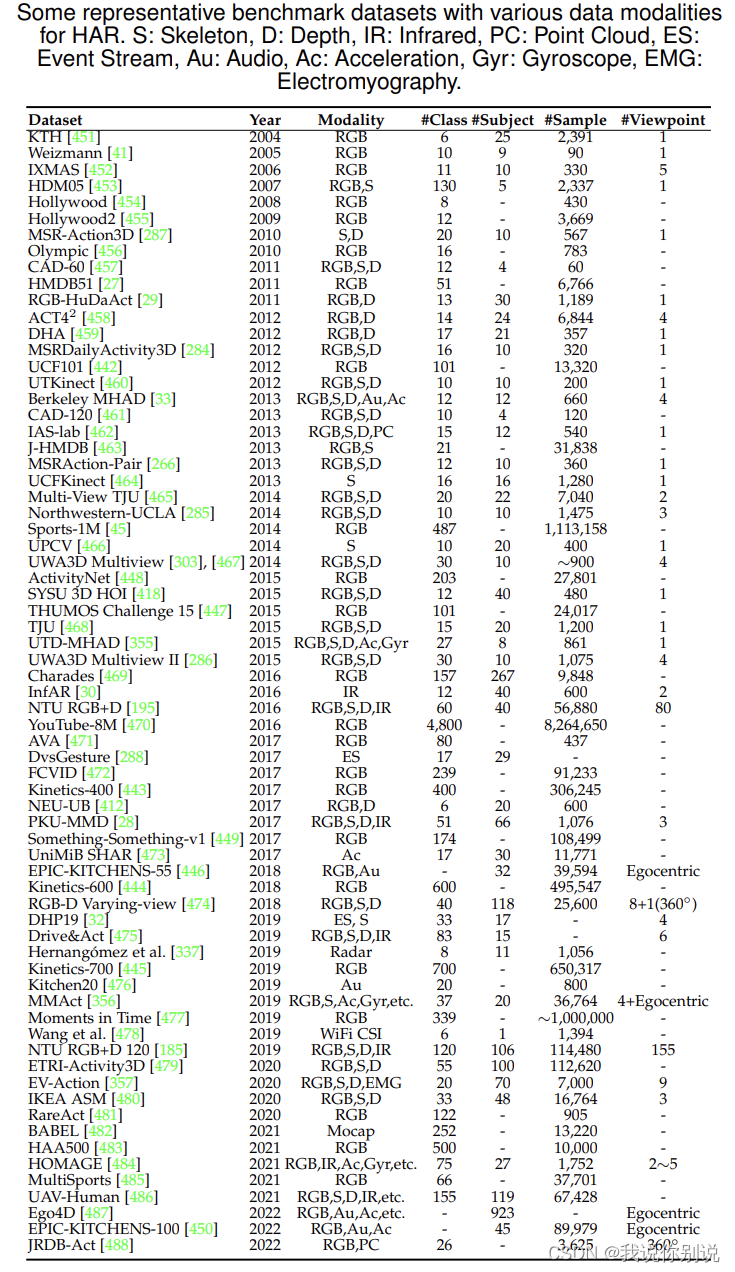
Dataset


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









