







 本文探讨了图像建模的结构化损失与条件GAN在pix2pix模型中的应用,提出了一种通用框架解决图像到图像转换问题。文章详细介绍了目标函数、网络架构,特别是U-Net生成器和PatchGAN判别器的设计,以及如何结合L1loss和GANloss优化图像质量。
本文探讨了图像建模的结构化损失与条件GAN在pix2pix模型中的应用,提出了一种通用框架解决图像到图像转换问题。文章详细介绍了目标函数、网络架构,特别是U-Net生成器和PatchGAN判别器的设计,以及如何结合L1loss和GANloss优化图像质量。
文章目录
pix2pix模型本质上是cGAN的一种特殊实现。一种Image-to-Image的实现,是一种基于GAN的图像到图像翻译架构,生成部分G用U-Net代替Encoder-Decoder。
一、前言
(一)研究目标
文章的主要目的是开发一个通用框架来解决图像-图像转换(从像素预测像素)的所有问题:
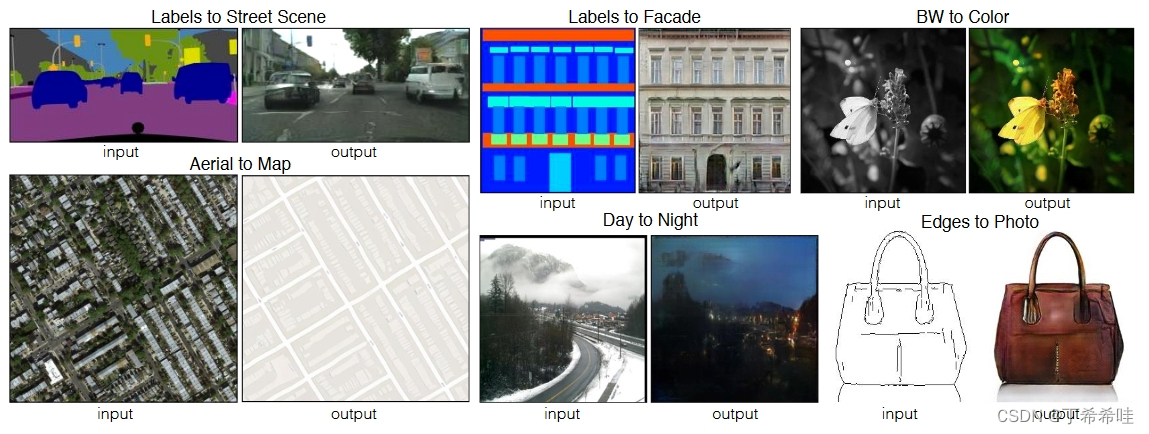
(二)图像建模的结构化损失
非结构化: 图像到图像的转换问题通常被表述为每像素分类或回归。这些公式将输出空间视为“非结构化”,因为每个输出像素被认为有条件地独立于给定输入图像的所有其他像素。
结构化: 结构化损失考虑了输出的联合配置,而不仅仅是单个像素的值。这意味着损失函数可以惩罚整个输出图像中的像素配置,而不仅仅是单个像素值的差异。
条件 GAN 会学习结构化损失: 条件生成对抗网络的损失是通过训练来学习的,因此可以根据数据集的特征来调整损失函数。这使得条件生成对抗网络可以惩罚任何可能的输出和目标之间的结构差异,而不仅限于特定的损失函数。
(三)条件GAN
cGAN就是在GAN的基础上加了一个条件向量。生成图片的时候在噪声后面接个条件向量,判别的时候图片也是和这个条件向量一起判别,这个条件向量在MNIST数据集上可以代表数字,CIFAR数据集上可以代表类别,总之按给定的条件生成相应的图像。
- GAN 是生成模型,它学习从随机噪声向量 z 到输出图像 y 的映射,G : z → y。
- 条件 GAN 学习从观察到的图像 x 和随机噪声向量 z 到 y, G : {x, z} → y 的映射。生成器 G 被训练为产生无法通过对抗性训练的判别器 D 区分出“真实”图像的输出,D 被训练为尽可能好地检测生成器的“赝品”。
二、模型方法
pix2pix模型本质上是cGAN的一种特殊实现。一种Image-to-Image的实现,是一种基于GAN的图像到图像翻译架构,生成部分G用U-Net代替Encoder-Decoder。
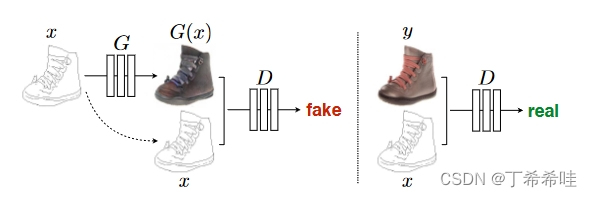 如上图,生成器G通过Unet结构,对输入图x编码与解码生成真实图片,判别器D在输入图x条件下,对于生成图片G(x)判别为假,对于真实图片判别为真,实现判别器的判别功能。
如上图,生成器G通过Unet结构,对输入图x编码与解码生成真实图片,判别器D在输入图x条件下,对于生成图片G(x)判别为假,对于真实图片判别为真,实现判别器的判别功能。
(一)目标函数
1、GAN与条件GAN
条件 GAN 的目标可以表示为:
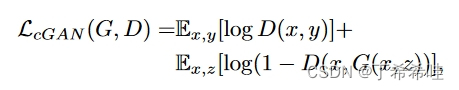
为了测试条件判别器的重要性,我们还与判别器不观察 x 的无条件变体进行比较:
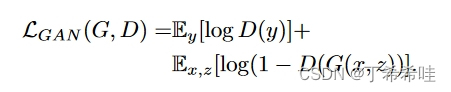
2、pix2pix的损失函数
pix2pix的目标函数采用将L1 loss与GAN loss相结合的方式:
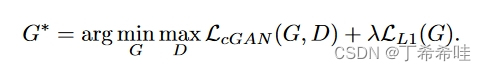
L1 loss:
- 评估生成图与真实图的“距离”(像素之间的差异)
- 选用L1是因为这些距离函数作用在像素层面上会激励图像模糊化,而L1距离相较L2来说图像的模糊程度会更少。(不会捕捉高频信息,但能捕捉到低频信息,高频信息已经丢给判别器去捕捉了)
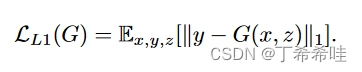
「低频」就是颜色缓慢变化,也就是灰度缓慢地变化,代表着那是连续渐变的一块区域;
「高频」就是频率变化快,相邻区域之间灰度相差很大。
通过下图可以看到,input输入了一张模糊的图片,在L1 losse,cGAN与L1 + cGAN下的图片清晰度对比,L1 + cGAN下图片清晰度较高。

(二)网络架构
生成器和判别器都使用卷积-BatchNorm-ReLu形式的模块。
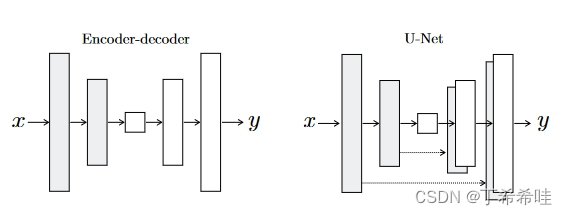
1、带有跳跃连接的生成器
过去大部分做 Image-to-Image 任务的GAN的生成器都是通过对输入先下采样再上采样的方式生成图像(encoder-decoder结构)。但是这样会导致在下采样通过瓶颈层时丢失掉很多特征,但是实际上很多图像翻译问题的输入和输出之间共享大量低级信息,如轮廓和边缘。而 U-Net 结构就很好的解决了这个问题,用类似 ResNet 那样的方法把通过瓶颈层前的特征直接送到对称的上采样层上,这样就保留了图像的底层特征 。
2、马尔可夫判别器(PatchGAN)
- 根据前面的损失函数分析可知,GAN 判别器仅对高频结构进行建模,而L1 项用于强制低频正确性,为了对高频进行建模,将我们的注意力限制在局部图像块的结构上就足够了。因此,文章设计了一种判别器架构(我们称之为 PatchGAN),它仅对补丁规模的结构进行惩罚。
- 马尔可夫判别器又叫 PatchGAN 分类器,这个判别器将一张图片视为一个马尔可夫随机场,如果像素之间的距离超过了一个Patch的直径就认为它们是独立无关的,实际上就是将图片分成很多小块(Patch)分别判别真假概率(Patch之间相互独立)。这样判别器的输出就不再是一个数值了,图片为真的概率为判别器输出结果平均的平均值。这么做的一个目的是为了方便捕捉图片的高频信息(纹理,边缘,风格等)。
这样的判别器有效地将图像建模为马尔可夫随机场,假设间隔大于斑块直径的像素之间是独立的。这种联系也是纹理和风格模型中的常见假设。因此,PatchGAN 也可以理解为纹理/风格损失的一种形式。

















 2893
2893

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









