







前言
各位伙伴们,大家好!由于篇幅较长,所以笔者将采用多篇Blog发布的形式来方便大家阅读,整篇Blog全程干货满满,给大家带来不便敬请谅解!
最后附上前篇Blog链接:Redis进阶之持久化机制及主从复制(干货满满),如有需要的小伙伴可点击查看哦~
Redis
1 Redis Cluster集群
1.1 问题
容量不够,redis如何进行扩容?
并发写操作, redis如何分摊?
另外,主从模式,薪火相传模式,主机宕机,导致ip地址发生变化,应用程序中配置需要修改对应的主机地址、端口等信息。
之前通过代理主机来解决,但是redis3.0中提供了解决方案。就是无中心化集群配置。
1.2 什么是集群
Redis 集群实现了对Redis的水平扩容,即启动N个redis节点,将整个数据库分布存储在这N个节点中,每个节点存储总数据的1/N。
Redis 集群通过分区(partition)来提供一定程度的可用性(availability): 即使集群中有一部分节点失效或者无法进行通讯, 集群也可以继续处理命令请求。
1.3 删除持久化数据
将rdb,aof文件都删除掉。
1.4 制作6个实例,6379,6380,6381,6389,6390,6391
1.4.1 配置基本信息
开启daemonize yes
Pid文件名字
指定端口
Log文件名字
Dump.rdb名字
Appendonly 关掉或者换名字
1.4.2 redis cluster配置修改
cluster-enabled yes 打开集群模式
cluster-config-file nodes-6379.conf 设定节点配置文件名
cluster-node-timeout 15000 设定节点失联时间,超过该时间(毫秒),集群自动进行主从切换。
include /usr/myredis/redis.conf
pidfile /var/run/redis_6379.pid
port 6379
dbfilename dump6379.rdb
cluster-enabled yes
cluster-config-file nodes-6379.conf
cluster-node-timeout 15000
1.4.3 修改好redis6379.conf文件,拷贝多个redis.conf文件
使用查找替换修改另外5个文件
例如::%s/6379/6380
启动6个redis服务
redis-server /usr/myredis/redis6379.conf
redis-server /usr/myredis/redis6380.conf
redis-server /usr/myredis/redis6381.conf
redis-server /usr/myredis/redis6389.conf
redis-server /usr/myredis/redis6390.conf
redis-server /usr/myredis/redis6391.conf
1.4.4 将六个节点合成一个集群
- 合体:
cd /usr/software/redis-6.2.1/src
redis-cli --cluster create --cluster-replicas 1 192.168.136.172:6379 192.168.136.172:6380 192.168.136.172:6381 192.168.136.172:6389 192.168.136.172:6390 192.168.136.172:6391
此处不要用127.0.0.1, 请用真实IP地址
–replicas 1 采用最简单的方式配置集群,一台主机,一台从机,正好三组。
- 普通方式登录
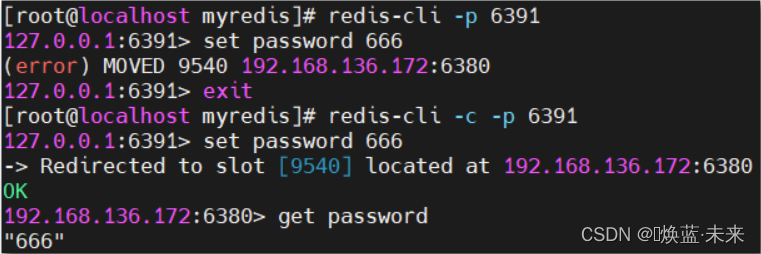
1、可能直接进入读主机,存储数据时,会出现MOVED重定向操作。所以,应该以集群方式登录。
2、-c 采用集群策略连接,设置数据会自动切换到相应的写主机
redis-cli -c -p 6379
3、通过 cluster nodes 命令查看集群信息

- 批量关闭服务
ps -ef | grep redis | grep -v grep |cut -c 9-15|xargs kill -9
ps -ef | grep redis | cut -c 9-15 | xargs kill -9
1.4.5 redis cluster 如何分配这六个节点?
一个集群至少要有三个主节点。
选项 --cluster-replicas 1 表示我们希望为集群中的每个主节点创建一个从节点。
分配原则尽量保证每个主数据库运行在不同的IP地址,每个从库和主库不在一个IP地址上。
1.5 什么是slots
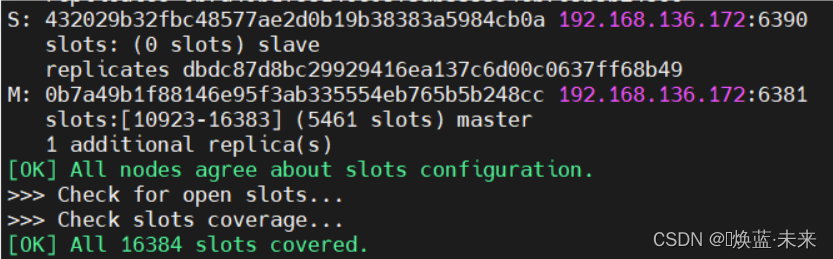
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
一个 Redis 集群包含 16384 个插槽(hash slot), 数据库中的每个键都属于这 16384 个插槽的其中一个,
集群使用公式 CRC16(key) % 16384 来计算键 key 属于哪个槽, 其中 CRC16(key) 语句用于计算键 key 的 CRC16 校验和 。
集群中的每个节点负责处理一部分插槽。 举个例子, 如果一个集群有多个主节点, 其中:
节点 A 负责处理 0 号至 5460 号插槽。
节点 B 负责处理 5461 号至 10922 号插槽。
节点 C 负责处理 10923 号至 16383 号插槽。
1.6 在集群中录入值
在redis-cli每次录入、查询键值,redis都会计算出该key应该送往的插槽,如果不是该客户端对应服务器的插槽,redis会报错,并告知应前往的redis实例地址和端口。
redis-cli客户端提供了 –c 参数实现自动重定向。
如 redis-cli -c –p 6379 登入后,再录入、查询键值对可以自动重定向。
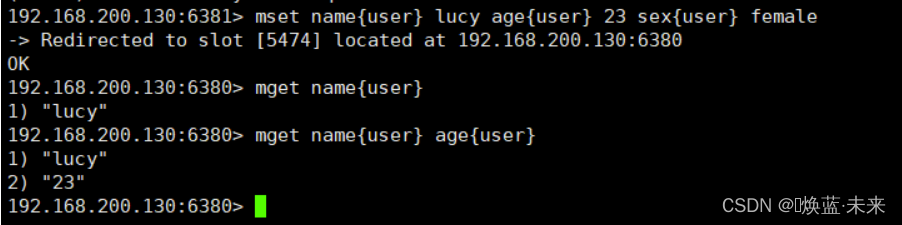
不在一个slot下的键值,是不能使用mget,mset等多键操作。

可以通过{}来定义组的概念,从而使key中{}内相同内容的键值对放到一个slot中去。
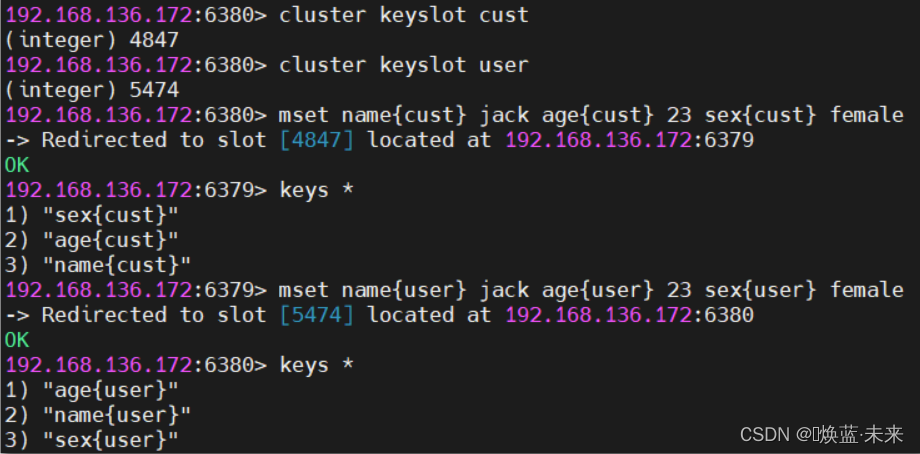
1.7 查询集群中的值
-
cluster keyslot 指定key 槽slot
-
cluster countkeysinslot 指定slot槽中键的个数
-
CLUSTER GETKEYSINSLOT 返回 count 个 slot 槽中的键。
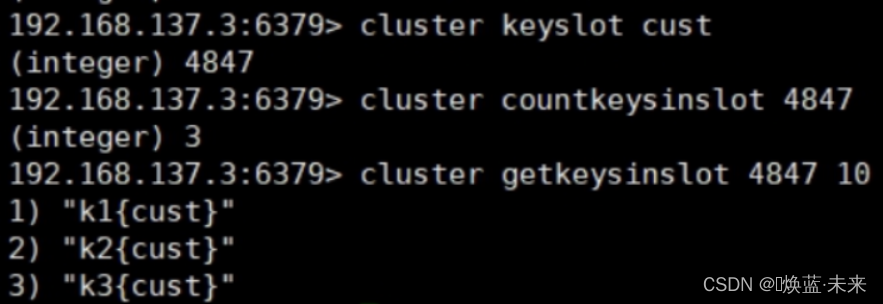
1.8 故障恢复
1、如果主节点下线?从节点能否自动升为主节点?注意:15秒超时
2、主节点恢复后,主从关系会如何?主节点回来变成从机。
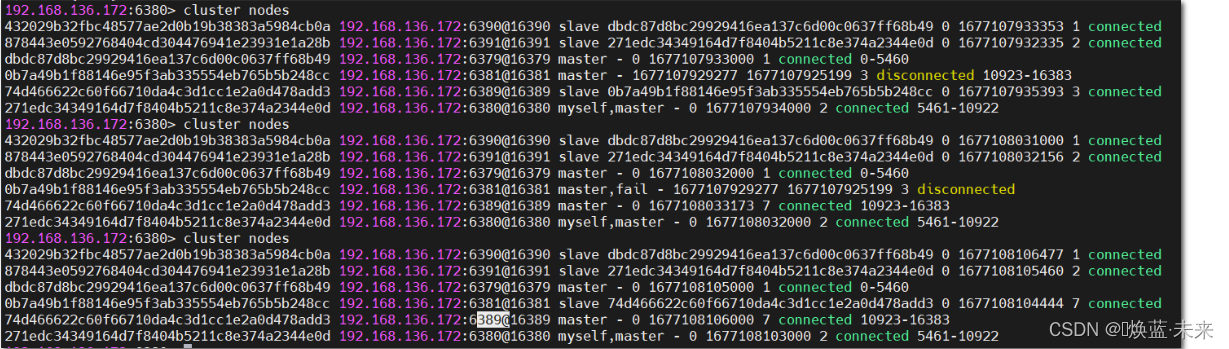
3、如果所有某一段插槽的主从节点都宕掉,redis服务是否还能继续?
如果某一段插槽的主从都挂掉,而cluster-require-full-coverage 为yes ,那么 ,整个集群都挂掉
如果某一段插槽的主从都挂掉,而cluster-require-full-coverage 为no ,那么,该插槽数据全都不能使用,也无 法存储。
redis.conf中的参数 cluster-require-full-coverage
1.9 添加节点
1.9.1 准备新节点
- 添加新的redis服务:6392和6393
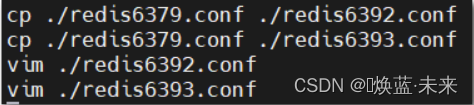
-
并启动新节点

1.9.2 添加主节点
- 命令
redis-cli --cluster add-node new_host:new_port existing_host:existing_port --cluster-master-id node_id
* new_host:new_port:新添加的主节点IP和端口
* existing_host:existing_port:最后一个主节点的 IP 和端口。(16383 表示的是最后的槽数)
* --cluster-master-id:最后一个主节点的节点 ID。表示的是新添加的主节点要在这个节点后面

- 添加节点
redis-cli --cluster add-node 192.168.136.172:6392 192.168.136.172:6389 --cluster-master-id 74d466622c60f66710da4c3d1cc1e2a0d478add3
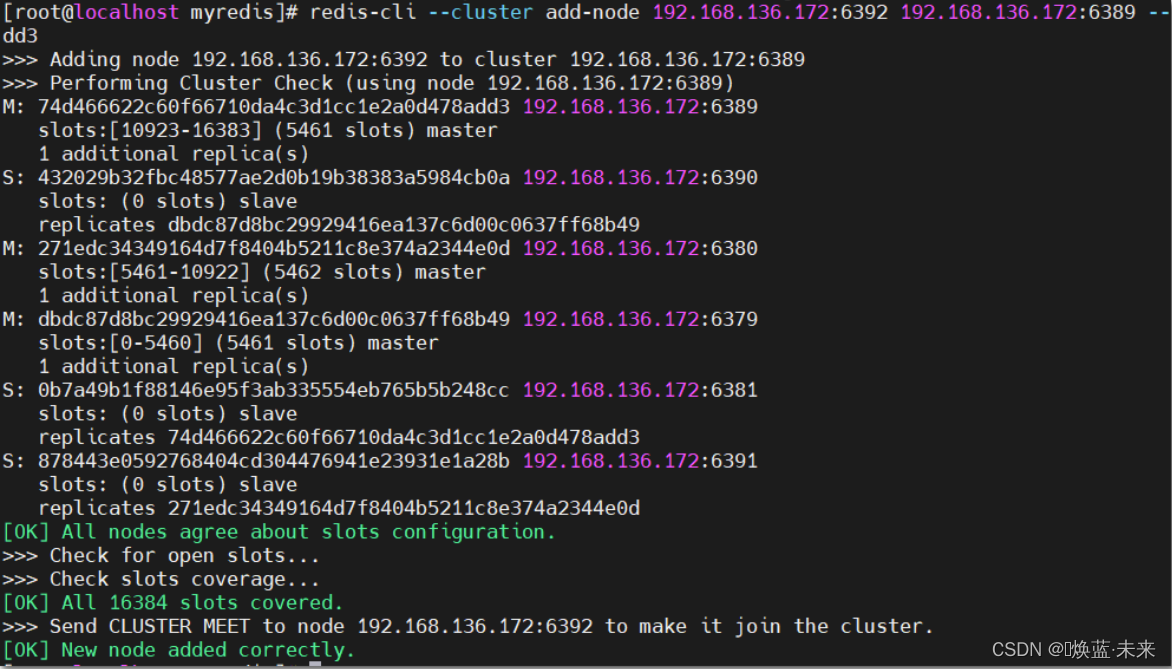
- 查看节点情况,添加节点成功, 但没有分配槽数

1.9.3 分配槽数
- 添加完新节点后,需要对新添加的主节点进行 hash 槽重新分配,这样该主节点才能存储数据,Redis 共有16384个槽。
redis-cli --cluster reshard host:port --cluster-from node_id --cluster-to node_id --cluster-slots <args> --cluster-yes
* host:port:集群中随便一个节点的IP:PORT,用于连接集群。
* --cluster-from node_id:表示的是从哪个节点取出槽,节点 ID
* --cluster-to node_id:表示的是取出的槽添加给哪个节点,也就是新添加的那个主节点 ID
* --cluster-slots 2000:表示的是给新主节点分配多少。
* --cluster-yes:不用再次确认分槽信息,直接移动。
- 分配前:

- 分配后:
redis-cli --cluster reshard 192.168.136.172:6379 --cluster-from 271edc34349164d7f8404b5211c8e374a2344e0d --cluster-to abd6ba38d0b05182f8a1044552c34a3a047a298f --cluster-slots 2000
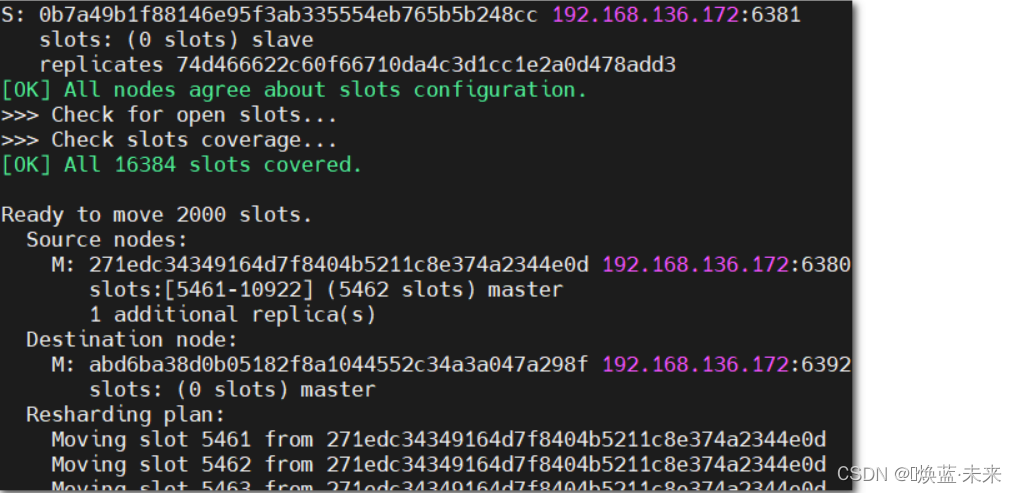
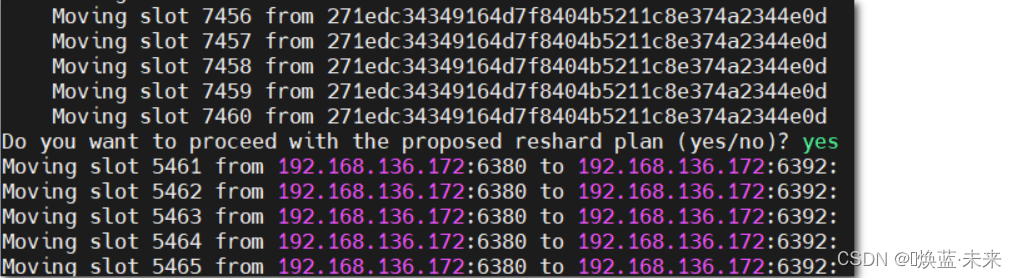

redis-cli --cluster reshard 192.168.136.172:6379 --cluster-from 271edc34349164d7f8404b5211c8e374a2344e0d --cluster-to abd6ba38d0b05182f8a1044552c34a3a047a298f --cluster-slots 1000 --cluster-yes
1.9.4 添加从节点
- 使用以下命令添加从节点
redis-cli --cluster add-node new_host:new_port existing_host:existing_port --cluster-slave --cluster-master-id node_id
* new_host:new_port:要添加从节点的IP和端口
* existing_host:existing_port:所属主节点的IP和端口
* --cluster-slave:添加从节点
* --cluster-master-id node_id:主节点ID
redis-cli --cluster add-node 192.168.136.172:6393 192.168.136.172:6392 --cluster-slave --cluster-master-id abd6ba38d0b05182f8a1044552c34a3a047a298f
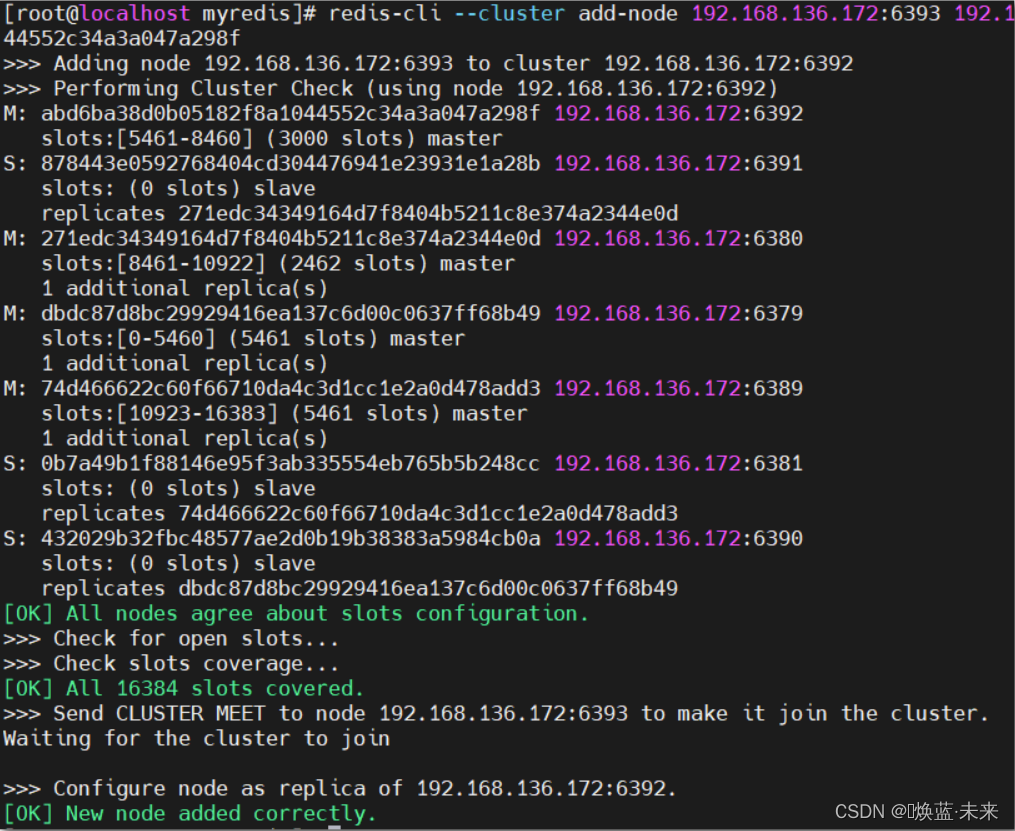
- 查看添加结果

1.10 集群的Jedis开发
即使连接的不是主机,集群会自动切换主机存储。主机写,从机读。
无中心化主从集群。无论从哪台主机写的数据,其他主机上都能读到数据。
1.11 Redis 集群提供了以下好处
实现扩容
分摊压力
无中心配置相对简单
1.12 Redis 集群的不足
由于集群方案出现较晚,很多公司已经采用了其他的集群方案,而代理或者客户端分片的方案想要迁移至redis cluster,需要整体迁移而不是逐步过渡,复杂度较大。
2 Redis应用问题解决
① 缓存穿透:大量请求根本不存在的key
② 缓存雪崩:redis中大量key集体过期
③ 缓存击穿:redis中一个热点key过期(大量用户访问该热点key,但是热点key过期)
2.1 缓存穿透
获取的key不存在,此时又有大量请求这个key
2.1.1 问题描述
key对应的数据在数据源种并不存在,每次针对此key的请求从缓存获取不到,请求都会压到数据源,从而可能压垮数据源。比如用一个不存在的用户id获取用户信息,不论缓存还是数据库都没有,若黑客利用此漏洞进行攻击可能压垮数据库。
2.1.2 问题排查
- Redis中大面积出现未命中
- 出现非正常URL访问
2.1.3 问题分析
- 获取的数据在数据库中也不存在,数据库查询未得到对应数据
- Redis获取到null数据未进行持久化,直接返回
- 下次此类数据到达重复上述过程
- 出现黑客攻击服务器
2.1.4 解决方案
一个一定不存在缓存及查询不到的数据,由于缓存是不命中时被动写的,并且出于容错考虑,如果从存储层查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到存储层去查询,失去了缓存的意义。
解决方案:
-
缓存null
对查询结果为null的数据进行缓存(长期使用,定期清理),设定短时限,例如30-60秒,最高5分钟 -
白名单策略
- 提前预热,提前加载,当加载正常数据时放行,加载异常数据时直接拦截(效率偏低)
- 使用布隆过滤器(有关布隆过滤器的命中问题对当前状况可以忽略)
-
实施监控
实时监控redis命中率(业务正常范围时,通常会有一个波动值)与null数据的占比- 非活动时段波动:通常检测3-5倍,超过5倍纳入重点排查对象
- 活动时段波动:通常检测10-50倍,超过50倍纳入重点排查对象
根据倍数不同,启动不同的排查流程。然后使用黑名单进行防控(运营)
-
key加密
问题出现后,临时启动防灾业务key,对key进行业务层传输加密服务,设定校验程序,过来的key校验
例如每天随机分配60个加密串,挑选2到3个,混淆到页面数据id中,发现访问key不满足规则,驳回数据访问
2.2 缓存击穿
2.2.1 问题描述
key对应的数据存在,但在redis中过期,此时若有大量并发请求过来,这些请求发现缓存过期一般都会从后端DB加载数据并回设到缓存,这个时候大并发的请求可能会瞬间把后端DB压垮。
2.2.2 问题排查
- Redis中某个key过期,该key访问量巨大
- 多个数据请求从服务器直接压到Redis后,均未命中
- Redis在短时间内发起了大量对数据库中同一数据的访问
2.2.3 问题分析
- 单个key高热数据
- key过期
2.2.4 解决方案
key可能会在某些时间点被超高并发地访问,是一种非常“热点”的数据。这个时候,需要考虑一个问题:缓存被“击穿”的问题。
解决问题:
- 当某一个请求去数据库查询的时候,同时在redis中将值设为null,待他从数据库查到数据返回后,设置具体的值
- 预先设定
以电商为例,每个商家根据店铺等级,指定若干款主打商品,在购物节期间,加大此类信息key的过期时长
注意:购物节不仅仅指当天,以及后续若干天,访问峰值呈现逐渐降低的趋势 - 现场调整
监控访问量,对自然流量激增的数据延长过期时间或设置为永久性key - 后台刷新数据
启动定时任务,高峰期来临之前,刷新数据有效期,确保不丢失 - 二级缓存
设置不同的失效时间,保障不会被同时淘汰就行 - 加锁
分布式锁,防止被击穿,但是要注意也是性能瓶颈,慎重!
2.3 缓存雪崩
2.3.1 问题描述
key对应的数据存在,但在redis中过期,此时若有大量并发请求过来,这些请求发现缓存过期一般都会从后端DB加载数据并回设到缓存,这个时候大并发的请求可能会瞬间把后端DB压垮。
缓存雪崩与缓存击穿的区别在于这里针对很多key缓存,缓存击穿则是某一个key
2.3.2 问题排查
-
在一个较短的时间内,缓存中较多的key集中过期
-
此周期内请求访问过期的数据,redis未命中,redis向数据库获取数据
-
数据库同时接收到大量的请求无法及时处理
-
Redis大量请求被积压,开始出现超时现象
-
数据库流量激增,数据库崩溃
-
重启后仍然面对缓存中无数据可用
-
Redis服务器资源被严重占用,Redis服务器崩溃
-
Redis集群呈现崩塌,集群瓦解
-
应用服务器无法及时得到数据响应请求,来自客户端的请求数
越来越多,应用服务器崩溃
-
应用服务器,redis,数据库全部重启,效果不理想
2.3.3 问题分析
- 短时间范围内
- 大量key集中过期
2.3.4 解决方案
解决方案
缓存失效时的雪崩效应对底层系统的冲击非常可怕!
解决方案:
(1) 构建多级缓存架构:nginx缓存 + redis缓存 +其他缓存(ehcache、memcache等)
(2) 使用锁或队列:
用加锁或者队列的方式保证来保证不会有大量的线程对数据库一次性进行读写,从而避免失效时大量的并发请求落到底层存储系统上。不适用高并发情况
(3) 设置过期标志更新缓存:
记录缓存数据是否过期(设置提前量),如果过期会触发通知另外的线程在后台去更新实际key的缓存。
(4) 将缓存失效时间分散开:
比如我们可以在原有的失效时间基础上增加一个随机值,比如1-5分钟随机,这样每一个缓存的过期时间的重复率就会降低,就很难引发集体失效的事件。
=========================================================
后记

好啦,以上就是本期全部内容,能看到这里的人呀,都是能人。
十年修得同船渡,大家一起点关注。
我是♚焕蓝·未来,感谢各位【能人】的:点赞、收藏和评论,我们下期见!
各位能人们的支持就是♚焕蓝·未来前进的巨大动力~
注:如果本篇Blog有任何错误和建议,欢迎能人们留言!
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











