







这里写目录标题
前言
关于java集合的一些知识点可看我之前的文章进行预习
javaSE从入门到精通的二十万字总结(二)
下面的博文主要是java集合中的一些常见面试题以及一些知识点
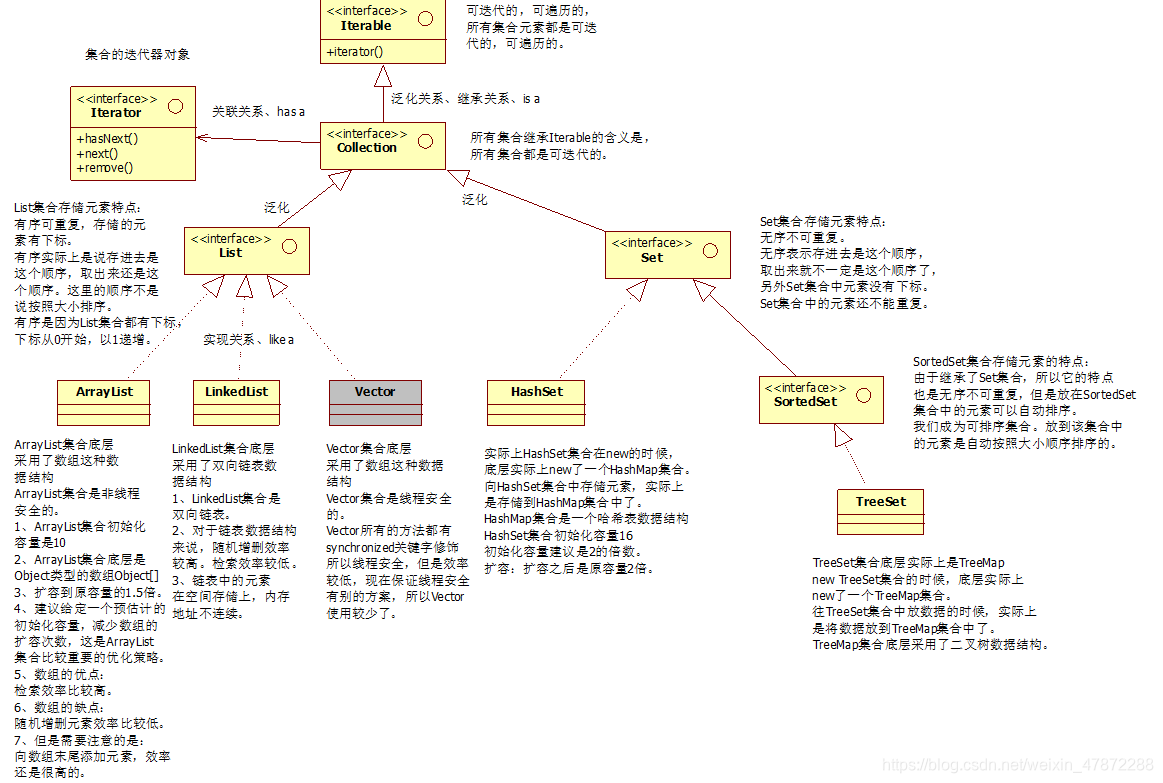
常用的集合类有哪些
可以通过如上所示
主要的两个大类有Map接口和Collection接口
| 实现类 | 底层元素 |
|---|---|
| Arraylist | 底层是数组。 |
| LinkedList | 底层是双向链表。 |
| Vector | 底层是数组,线程安全的,效率较低,使用较少。 |
| HashSet | 底层是HashMap,放到 HashSet集合中的元素等同于放到HashMap集合key部分了。 |
| TreeSet | 底层是TreeMap,放到 TreeSet集合中的元素等同于放到TreeMap集合key部分了。 |
| HashMap | 底层是哈希表。 |
| Hashtable | 底层也是哈希表,只不过线程安全的,效率较低,使用较少。 |
| Properties | 是线程安全的,并且 key 和value只能存储字符串String。 |
| TreeMap | 底层是二叉树。TreeMap集合的 key可以自动按照大小顺序排序。 |
集合底层数据结构
- list接口主要常用的实现类有
- ArrayList集合底层采用了
数组这种数据结构,非线程安全。 - LinkedList集合底层采用了
双向链表的数据结构 - Vector集合底层采用了
数组这种数据结构,线程安全的,所有的方法都有synchronized关键字修饰,比较安全但效率低,所以使用率低
- set接口主要常用的实现类有
- HashSet集合在new的时候,底层实际上new了一个HashMap集合。向HashSet集合中存储元素,实际上是存储到HashMap集合中,HashMap集合是一个哈希表数据结构
- TreeSet集合实际是TreeMap,new TreeSet集合的时候,底层实际上new了一个TreeMap集合,和上面同理。
采用了二叉树数据结构
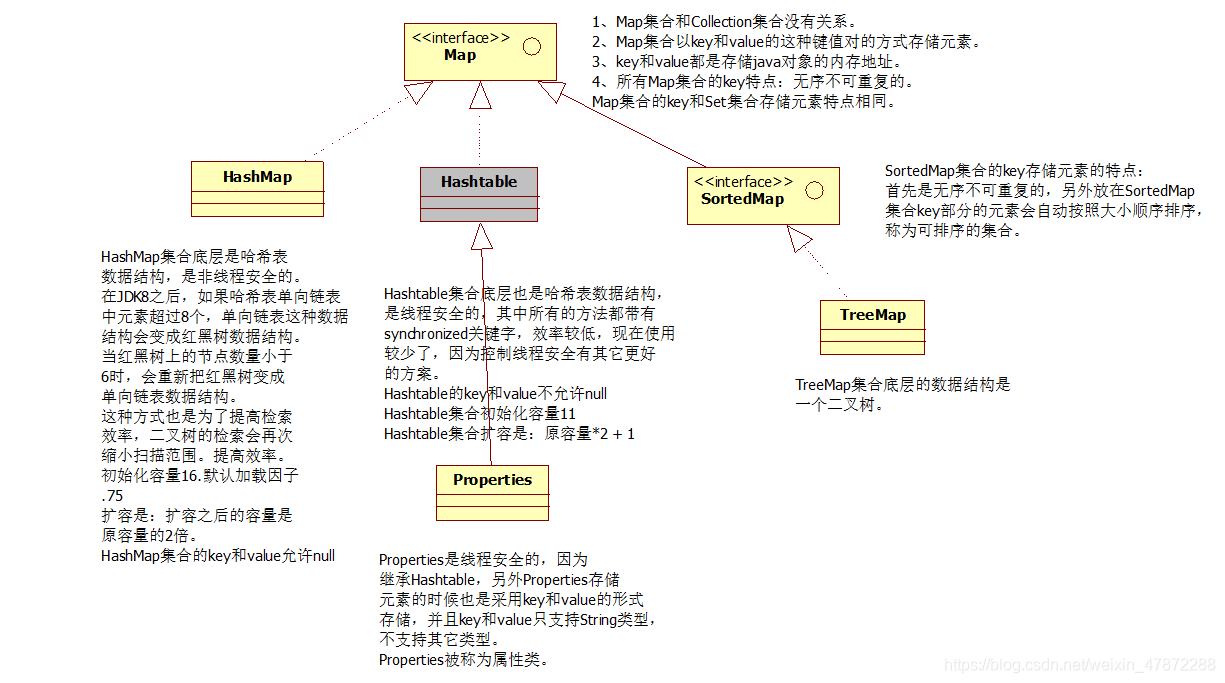
Map集合和Collection集合没有关系,存储的方式不同
所有Map集合key元素无序不可重复
Map接口的常用实现类有
- HashMap集合底层是
哈希表数据结构,非线程安全 - Hashtable集合是哈希表数据结构,
线程安全,所有的方法都有synchronized关键字,效率比较低,使用比较少了 - 还有一个接口SortedMap,本身不可重复无序,但是此处有自动排序,按照大小进行排序。此接口的实现类有TreeMap(二叉树结构)
ArrayList 和 LinkedList 的区别
这部分的知识主要涉及数组和双向链表的区别
两者都是不保证线程安全
再讲这部分知识的时候,涉及单链表和双向链表以及对比线性表的区别
可查看我之前写过的文章
【数据结构】顺序表及链表详细分析(全)
具体涉及单链表和双链表的创建可查看这篇代码
【leetcode】链表-设计链表(单双链表全)
HashSet 如何检查重复
当你把对象加⼊ HashSet 时,HashSet 会先计算对象的 hashcode 值来判断对象加⼊的位置,同时也会与其他加⼊的对象的 hashcode 值作⽐较,如果没有相符的 hashcode,HashSet 会假设对象没有重复出现。
但是如果发现有相同 hashcode 值的对象,这时会调⽤ equals() ⽅法来检查 hashcode 相等的对象是否真的相同。如果两者相同,HashSet 就不会让加⼊操作成功。
HashSet与HashMap的区别
| HashMap | HashSet |
|---|---|
| 实现Map接口 | 实现Set接口 |
| 存储键值对 | 仅存储对象 |
| 调用put()向map中添加元素 | 调用add()方法向Set中添加元素 |
HashMap使用键(Key)计算Hashcode ,而HashSet使用成员对象来计算hashcode值
HashMap相对于HashSet较快,因为它是使用唯一的键获取对象
HashMap 和 Hashtable 的区别
- 线程是否安全: HashMap 是⾮线程安全的,HashTable 是线程安全的,因为 HashTable 内部的⽅法基本都经过 synchronized 修饰。(如果你要保证线程安全的话就使⽤ConcurrentHashMap 吧!);
- 效率: 因为线程安全的问题,HashMap 要⽐ HashTable 效率⾼⼀点。另外,HashTable 基本被淘汰,不要在代码中使⽤它
- 对 Null key 和 Null value 的⽀持: HashMap 可以存储 null 的 key 和 value,但 null 作为键只能有⼀个,null 作为值可以有多个;HashTable 不允许有 null 键和 null 值,否则会抛出 NullPointerException
- 初始容量⼤⼩和每次扩充容量⼤⼩的不同 :
创建时如果不指定容量初始值, HashMap 默认的初始化⼤⼩为16。之后每次扩充,容量变为原来的 2 倍。
Hashtable 默认的初始⼤⼩为 11,之后每次扩充,容量变为原来的 2n+1。
HashMap 的底层实现
JDK1.8 之前 HashMap 底层是 数组和链表 结合在⼀起使⽤也就是 链表散列
JDK1.8 之后在解决哈希冲突时有了较⼤的变化,当链表⻓度⼤于阈值(默认为8)(将链表转换成红⿊树前会判断,如果当前数组的⻓度⼩于 64,那么会选择先进⾏数组扩容,⽽不是转换为红⿊树)时,将链表转化为红⿊树,以减少搜索时间
补充:红黑树转换是链表节点大于8且数组长度大于64
TreeMap、TreeSet 以及 JDK1.8 之后的 HashMap 底层都⽤到了红⿊树。红⿊树就是为了解决⼆叉
查找树的缺陷,因为⼆叉查找树在某些情况下会退化成⼀个线性结构
HashMap 的长度为什么是 2 的幂次方
为了能让 HashMap 存取⾼效,尽量较少碰撞,也就是要尽量把数据分配均匀
⽤之前还要先做对数组的⻓度取模运算,得到的余数才能⽤来要存放的位置也就是对应的数组下标。这个数组下标的计算⽅法是“ (n - 1) & hash ”。
hash%length==hash&(length-1)的前提是 length 是 2的 幂次⽅
ConcurrentHashMap 和 Hashtable 的区别
-
底层数据结构: JDK1.7 的 ConcurrentHashMap 底层采⽤ 分段的数组+链表 实现,JDK1.8 采⽤的数据结构跟 HashMap1.8 的结构⼀样,数组+链表/红⿊⼆叉树。Hashtable 和 JDK1.8 之前的 HashMap 的底层数据结构类似都是采⽤ 数组+链表 的形式,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突⽽存在的
-
实现线程安全的⽅式(重要): ① 在 JDK1.7 的时候,ConcurrentHashMap(分段锁) 对整个桶数组进⾏了分割分段(Segment),每⼀把锁只锁容器其中⼀部分数据,多线程访问容器⾥不同数据段的数据,就不会存在锁竞争,提⾼并发访问率。 到了 JDK1.8 的时候已经摒弃了Segment 的概念,⽽是直接⽤ Node 数组+链表+红⿊树的数据结构来实现,并发控制使⽤synchronized 和 CAS 来操作。(JDK1.6 以后 对 synchronized 锁做了很多优化) 整个看起来就像是优化过且线程安全的 HashMap,虽然在 JDK1.8 中还能看到 Segment 的数据结构,但是已经简化了属性,只是为了兼容旧版本;② Hashtable(同⼀把锁) :使⽤ synchronized 来保证线程安全,效率⾮常低下。当⼀个线程访问同步⽅法时,其他线程也访问同步⽅法,可能会进⼊阻塞或轮询状态,如使⽤ put 添加元素,另⼀个线程不能使⽤ put 添加元素,也不能使⽤get,竞争会越来越激烈效率越低
HashMap源码细节
1.8之前的版本:数组+链表(使用了拉链法解决冲突)
1.8之后的版本:链表长度大于8的阈值,如果数组长度要大于64(转化为红黑树),如果数组长度小于64(扩容树组)
初始化的容量为16,扩容的时候为原来的2倍
加载因子0.75:
加载因子是控制数组存放数据的疏密程度
- 接近1的时候,数组数据密集,让其链表长度增加
- 接近0的时候,数组数据稀疏,链表长度不长
以上两种,加载因子过大,导致元素查找效率降低(链表过长),利用率低。加载因子过小,利用率低(存放数据过于稀疏)。
综上所述,0.75的加载因子是很好的临界值
通过这个加载因子来考虑什么时候扩容:threshold = capacity * loadFactor
如果size大于等于threshold的时候,对数组进行扩容
put函数:(注意两者之后的区别)
-
1.7版本:
定位到的数组如果没有元素,则直接插入。如果有元素,则以这个元素为头结点,依次插入key比较,如果相同弄则进行覆盖(更新),不同则用头插法 -
1.8版本:
定位道德数组如果没有元素,则直接插入。如果有元素,则则以这个元素为头结点,依次插入key比较,如果相同弄则进行覆盖,不同则判断该节点是否为树节点,调用树的put节点将元素加入,如果不是则遍历链表之后进行尾结点插入
get函数此处比较简单(省略)
resize函数:
每次的resize都要进行重新hash分配,并且会遍历hash表中的所有元素,比较耗时
ConcurrentHashMap源码细节
1.8以前的版本:分段锁+数组+链表
以下为1.8的版本:数组+链表+红黑树
put函数:
- 通过key计算出hashcode,判断是否需要初始化
- 通过定位的key写入数组中,如果数组为空,则通过CAS进行写入。如果当前数组的位置不存在,则通过扩容。
- 以上情况都不满足则通过synchronized锁进行写入。数量如果大于TREEIFY_THRESHOLD 则进行树形化,在treeifyBin函数中判断数组长度,大于64才会转为红黑树
get函数:
- 计算hash值,找到指定位置,如果头结点符合,则返回value值
- 头结点hash值小于0,说明正在扩容或者红黑树
- 如果是链表,则进行遍历
Array 和 ArrayList 的区别
Array 可以存储基本数据类型和对象,存储的数据都是固定大小
ArrayList 只能存储对象,存储的数据大小可以自动扩展
Collection 和 Collections的区别
Collection 提供了对集合对象进行基本操作的通用接口方法。其直接继承接口有List与Set
Collections是工具类,主要功能有用于对集合中元素进行排序、搜索以及线程安全等
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











