







多处理器系统必须应对的一个重要问题是存储一致性问题,这关乎着所有处理器看到的对任意处理器地址的访问(加载或者存储)之间的次序问题。值得注意的是,这不是缓存一致性协议所能覆盖的问题,因为缓存一致性协议仅解决对单个存储器块地址的访问之间如何排序的问题,而对于不同地址的访问并不是缓存一致性协议所要考虑的问题。事实上,与仅在高速缓存的系统中出现的缓存一致性问题不同,存储一致性问题在任何具有或者不具有高速缓存的系统中都存在,虽然高速缓存的存在可能进一步加剧该问题。
对于一个存储器访问的全序问题,其排序需求的模型称为顺序一致性SC模型。对于SC模型,处理器或者一致性协议机制的那些部分必须改变。还讨论由于这些改变过于严厉,很可能产生巨大性能开销,最后结果是许多处理器并不实现SC,而是实现更为松弛的一致性模型,如处理器一致性,弱序和释放一致性。
9.1 程序员的直觉
程序员隐式地期望在线程中存储器访问操作按照源代码中它们出现的次序执行。这种期望为程序次序program order期望。
在一个具有高速缓存的系统中,一条load指令的执行体现在它已经从高速缓存读到数据。此刻load指令不再受到其他处理器的无效化或干预请求的影响。因此,处理器能一致同意达成load指令已经完成。一条store指令的执行只有在将其无效化或更新请求传播给所有其他高速缓存时才算完成。此刻,所有处理器能够同意store指令已完成或者将被完成而不存在任何问题。
P0:
S1: x = 5;
S2: xReady = 1;
P1:
S3: while(!xReady);
S4: y = x + 4;
S5: xyReady = 1;
P2:
S6: while(!xyReady);
S7: z = x + y;
上述期望实际上隐式地假定了存储器访问操作的原子性,即期望各个存储器访问操作即时发生,不与任何其他存储器访问操作重叠。
为什么P0发出的对应x写入的无效化请求能到达P1却未能立即到达P2呢?答案是,在某种类型的互联网络中这的确会发生。在基于总线的多处理器中,当写操作到达总线,所有侦听者P1和P2将看到这个写操作并无效化它们的高速缓存中对应的块。因此,上述情形不会发生。但是,如果处理器使用点对点互联网络,P0会向P1和P2分别发出无效化消息。由于消息会经过不同的路径,或者发向P2的无效化消息所经历的延迟较大。那么发送给P1的无效化消息完全有可能比发送给P2的无效化消息早到达。
在P0,P1,P2代码中,若想代码能正常工作,意味着写传播必须是即时的,或以专业术语来说是原子性的。这样一种期待被正式定义为顺序一致性模型SC。下面是Lamport对于顺序一致形的定义:
如果所有处理器的操作都已按某种顺序的次序执行,每次执行的结果都相同,且在这个顺序中每个独立的处理器的操作都已按程序指定的次序发生,则称该多处理器是顺序一致的。
非确定性程序的正确性推断和调试是“臭名昭著”的困难问题。程序员错误地遗漏同步操作也会导致非确定性程序的出现,在这种情况下非确定性的出现是一种意外。
9.2 保证顺序一致性的体系结构机制
为了保证顺序一致性,来自一个处理器的存储器访问必须遵循程序次序,而且每一个访问必须是原子性的。一种基本实现由于缺少存储器访问间的重叠,性能损失很大。然后讨论通过允许存储器访问操作间的重叠而改善SC性能的技术。请注意,重叠存储器访问操作有可能潜在地违反原子性。因此,需要一种安全机制来自动发现违反原子性的情况并从中恢复。
9.2.1 在基于总线的多处理器中基本的SC实现
最简单和正确的原子性实现方法是一次只执行一个存储器访问操作,使存储器访问之间不重叠。为此,我们需要知道存储器访问操作什么时候开始,什么时候结束。以load为例,load指令的执行在逻辑上分为四步。首先。功能部件计算它的有效地址,然后向存储器层次结构发出针对该有效地址的高速缓存访问,接着存储器层次结构找到与该地址相关的数据的值(有可能在本地高速缓存、主存或远地高速缓存),最后将这个值交回load指令的目的寄存器。注意,第一步(计算有效地址)并不受其他存储器访问的影响,可以不管程序次序而进行,因此,这一步可以与其他存储器访问操作的任何步骤重叠。最后一步(把从高速缓存读取的值交回load指令的目标寄存器)也不受其他存储器访问操作的影响,因为该值已经从高速缓存获得。所以,从存储器访问次序的角度看,一条load指令始于对高速缓存发出访问,当获得高速缓存的值(假定读出的值以后不在改变)时,可认定它已被执行了,其间两步是必须原子执行的。
类似的,一条store指令也分几步执行。首先,功能部件计算出它的有效地址,随后,如果它不是一条投机指令(如不是一条处于分支的错误路径上的指令,而且未发生异常),该store指令就可以被提交了。store指令的提交是将其目标地址和值写入一个称为写缓冲区的结构中,写缓冲区是一个先入先出的队列,保存着处理器流水线已经提交的store操作,稍后,写缓冲区的store值将被释放到高速缓存中。如果被写入的是整个系统中的唯一副本,store指令直接修改高速缓存中的副本,如果系统中里还有其他副本存在,store就向其他高速缓存发出无效化操作,当store指令的操作已经完整传播到所有处理器时,我们认为该条store指令已被执行。在基于更新的协议中,所有高速缓存的副本已经更新完毕;在无效协议中,所有高速缓存的副本已经作废。请注意,第一步(计算有效地址)并不受其他存储器访问的影响,不管程序次序如何。注意,store和load指令一个重要区别是:store指令对高速缓存的访问非常晚(在store指令提交之后),而load指令对高速缓存访问发生较早(在laod指令提交之前)。另一个重要区别是,load指令仅涉及一个处理器,而store指令涉及多个高速缓存副本的无效化。所以,从存储器访问次序的角度来看,一条store指令始于对有效地址发出访问请求,当全局性动作完成时(即已经向所有处理器传播了要写入的值),就可认定它已被执行了。
如何检测store指令的完成呢?在基本实现中,一种检测store结束的方法是要求所有的共享者都对无效化请求作出应答,由store的发起者收集所有的无效化应答。在一个基于总线的多处理器中,简单地将一个独占请求发布到总线上,就能保证所有处理器看到这个store操作。但是,在一个不依赖于广播和侦听的系统中,就要在请求者从所有共享哪里获得无效化应答消息之后,才能认定store已经被执行了。
9.2.2 改善SC性能的技术
改善SC实现性能的关键是使存储器访问执行得更快,并允许存储器访问相互重叠。但是,某些重叠可能违反访问的原子性,所以,需要一个安全机制来检测违反原子性的情况并从中恢复。
怎样才能使load在高速缓存中命中,store在高速缓存中待写的块处于独占/修改状态的概率最大呢?
1. 一旦获得load和store的有效地址或者有效地址可以预测时,立即发出预取请求。例如,当一个load指令的有效地址生成时,即使较早的load或者store还没有被执行,也可以对高速缓存发出一个预取请求。同样,当产生了一条store指令的有效地址时,即使此时较早的store或load指令还没有被执行,我们也可以发出一个独占预取(本质上是在总线上的一个更新或者独占读的请求)。
然而,预取不总是能改善性能。其原因之一是,在发起预取的load或store指令访问高速缓存之前,它预取到的块可能已经被窃取了。
2. 改善SC实现性能的第二个技术依赖于投机访问。基于较早的load指令原子执行的投机假设,我们可以让一条load指令的执行与一条较早的load指令重叠。大多数乱序执行处理器已经提供了取消一条指令并重新执行它的能力,以提供精确中断机制。
假设来自处理器的两条load指令针对不同的地址,第一条load指令遭遇高速缓存缺失,在基本的SC实现下即使使用了预取,在第一条load指令从高速缓存获得它的数据之前,第二条load指令仍不能访问高速缓存。使用投机机制,我们的确能允许第二条load指令访问高速缓存。由于投机失败必须刷新流水线,还要重新执行该条load指令及所有比错误投机的load指令更晚的指令,导致性能上的惩罚。
关于投机执行的讨论主要针对投机load,对store指令采用投机是更加困难的。其原因是load指令很容易取消并重新执行,而取消一条store指令要困难很多。
我们讨论了两种改善SC实现性能的非常强有力的机制。第一种技术(预取)不允许存储器访问之间的重叠,但是每次存储器访问的原子执行部分要比没有预取要短。第二种技术(投机load指令访问)允许存储器访问load的重叠。但是,仍然有一些根本的性能问题不能被预取和投机执行解决:编译器在编译程序时仍不能改变存储器访问的次序。只有松弛的存储一致性模型允许编译器改变存储器访问的次序。
9.3 松弛的一致性模型
放松SC对存储器访问次序限制的存储一致性模型的性能一般比SC更好,但是对程序员施加了额外的负担,需要程序员来保证它们所写的程序与硬件提供的一致性模型相容。
为了让程序员能够指明一对存储器访问之间的严格次序,典型的做法是提供一个安全网safety net。
9.3.1 安全网
保证两个存储器访问之间严格次序的典型的安全网以栅栏fence指令(也称为内存栅栏指令)的形式出现。栅栏指令的语义如下:在位于它之前的所有存储器访问都已经执行完毕之前,栅栏禁止跟随它后面的存储器访问的执行。在某些时候,栅栏仅作用于store操作,在这种情况下 ,它仅在位于它之前和之后的store操作之间强加次序,我们称为存栅栏。在另一些时候,栅栏仅作用于load操作,在这种情况下,它仅在位于它之前和之后的load之间强加次序,我们称之为取栅栏。
栅栏要求一下机制:当碰到一条栅栏指令时,流水线中跟在栅栏之后的存储器访问都被刷新(或者若那些存储器访问指令还没有取出,就避免被取出),所有在栅栏之前的存储器访问指令被执行。也就是说,load指令必须从高速缓存获得数据,而store指令必须访问高速缓存并产生总线请求。
为了使执行正确而在代码中插入栅栏指令是程序员的责任。在需要栅栏时不插入栅栏指令可能导致不正确的执行及非确定性结果,但在不需要它们时却插入栅栏则导致不必要的性能恶化。
9.3.2 处理器一致性PC
在处理器一致性PC模型中,放松了对较早执行的store指令和较晚的load指令之间的次序store-->load。这一点重要性在于,store指令可以在写缓冲区排队并在稍晚执行,且无需使用投机load。同时,load指令不需要等待较早store指令结束就可以访问高速缓存,所以降低了load指令的时延。
PC和SC的一个区别是:当一条load指令越过较早的store指令对高速缓存提前发出请求时,它并没有被当做投机处理,因为这样的次序改变是PC模型所允许的。
9.3.3 弱序一致性WO
另一种放松存储一致性模型的尝试来自于以下观察:大多数程序都是适当同步的。当程序员想让一个线程中的某个存储器访问在另一个线程中的另一个存储器访问之后发生,程序员会依靠同步来实现它。同步可能以栅栏、点对点同步等形式出现。
如果程序是适当同步的,数据竞争不会发生。数据竞争被定义为多个线程对存储器单一位置的同时访问,而且其中至少有一个访问是写入。同时发生的load指令不会改变取得的结果,同时发生的store指令可能会相互覆盖,产生数据竞争。所以,在一个适当同步的程序中,程序员的期望是不发生数据竞争。
适当同步的程序中不存在数据竞争这一事实意味着,存储器访问的次序在同步点之外可以放松。因为不会发生数据竞争,在同步点之外改变存储器访问的次序是安全地。
如果同步正确地工作,一次只能有一个线程在临界区。所以,在临界区内的存储器访问次序就无关紧要了,无需遵循程序次序。更进一步,在临界区之外的存储器访问也无关紧要,无需遵循程序次序,因为程序员如果在乎存储器访问的相对次序,他们应该已经插入同步来保证了。因此,同步点之外的程序次序无须保证。但是,为了保证同步的正确性,同步访问之间的次序仍然需要保证。
以上的观察是被称为弱序WO模型的松弛存储一致性模型的基础。WO模型利用了两个假设:
1)程序是适当同步的;
2)程序员正确地向硬件表示那些load和store是起到同步访问作用的。
基于这些假设,我们定义一个同步访问的正确行为如下:
1)在能够发出一个同步访问之前,所有前面的load、store和同步访问都已经执行;
2)在同步访问之后的所有load、store和同步访问必须没有发出。换言之,对于任何一对访问,其中之一在同步访问之前,另一个在同步访问之后,它们之间必须严格排序。
在处理器实现WO要用到那些机制呢?当在处理器的流水线碰到一个同步访问时,首先,将所有跟在同步访问后面的存储器访问从流水线中清空或者不把它们取进流水线,这事实上取消了它们的执行。然后,阻塞同步访问本身直到所有在它之前的存储器访问已被执行,即所有在它之前的laod指令必须得到了它们的值,所有在它之前的store指令已从写缓冲区中清空,并通过无效化请求全传播了它们的值。
WO比SC松弛的多。编译器可以自由改变laod和store指令的次序,只要它们不跨越同步边界。在执行过程中,只要同步访问之间的次序得到保证,load和store指令的执行就可以改变次序或相互重叠,无需原子性地执行这些指令。因此,WO能提供比SC更好地性能。但是,其代价是必须向硬件适当地标识和标识同步访问。
使用WO,存储器操作的重叠在以同步操作隔开的区域内都是允许的。
与PC相比,WO由于进一步放松了位于同步点之间的访存操作的次序而可能提供更好地性能。但是,如果,临界区的尺寸较小,或者频繁进入和退出临界区,在同步点之间可能只有少量的存储器访问。在这种情况下,只有少量的存储器访问可以被重叠,通过重叠存储器访问的执行而改善性能的机会很少。在临界区尺寸较小的情况下,PC在性能可能优于WO。在PC中,一个锁释放操作或者一个发布-等待同步的发布部分只包含一个store指令,store指令之后可以紧跟load指令。对于WO,同步store和后面的load间必须维持次序,而在PC中,它们之间无需排序。因此,在这种情况下,PC可能实现更高程度上的重叠。
9.3.4 释放一致性RC
放松存储一致性模型的一种更为激进的尝试来源于如下观察:存在两种类型的同步访问,
第一类释放数值以供其他线程去读,另一类获取其他线程释放的数值。例如,在发布-等待同步中,生产者线程置位一个信号,通知数据准备好了。信号置位使用了同步store,该同步store需要传播这个新的信号值和所有在同步store之前的数值。因此,同步store起到了释放的作用。消费者线程在访问新生成的数据之前读取这个信号值,因此,信号起到了获取的作用。
在锁被释放之前,所有在锁释放之前的存储器访问必须结束,这是强制性要求。此外,当P1进入临界区时,它必须没有执行过任何在其临界区内的存储器访问。所以,要求跟随在锁获取之后的所有存储器访问只能在锁获取完成之后才能发出。
在解锁unlock完成之前发出跟随在unlock之后的存储器访问请求不影响正确性,这是因为其排序效果和推迟锁的释放类似,只是使得临界区延长。因此,尽管位于unlock之前的存储器访问必须在unlock之前完成,但unlock之后的存储器访问却可以早点发出,不必等待unlock结束。如果临界区的存储器访问和临界区后面的存储器之间有数据依赖性,它们可以被单处理器的依赖型检测和保证机制正确地处理。因此,为了保证正确性,锁释放必须避免存储器访问的向后迁移,但向前迁移是可以的。
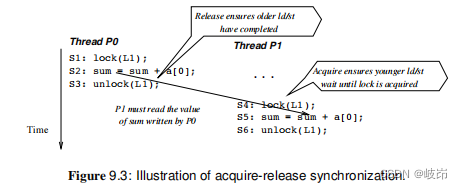
加锁lock之前的存储器访问在锁获取之后发出请求也不会影响正确性,这样做的效果和锁获取较早一样,即在临界区之内真正需要锁之前就获得了它。为了保证正确性,锁获取操作必须避免存储器访问的向前迁移,但是向后迁移是可以的。
注意释放一致性RC的编程复杂性超过WO,在WO下,作为同步操作,仅仅需要区分对datumIsReady的写入和读出,而在RC下,需要说明S2是一个释放同步,而S3是一个获取同步。
根据对于lock和unlock已经发布-等待的正确行为的直觉,现在能够讨论对获取-释放同步的更正式的正确性要求:
一个获取同步必须保证在获取完成之前,没有较晚的load/store能开始执行。一个释放同步必须保证在释放发出之前,所有较早的laod/store指令都已经完成。获取和释放之间必须原子性地执行。
最后一个要求指出,获取和释放彼此间必须是原子的,这意味它们的执行不能相互重叠。这个要求是有意义的。例如,一个锁获取操作不能与一个锁释放操作重叠以完全保证互斥性。
注意,对于获取和释放的要求意味着一个线程的两个临界区的执行可能重叠!
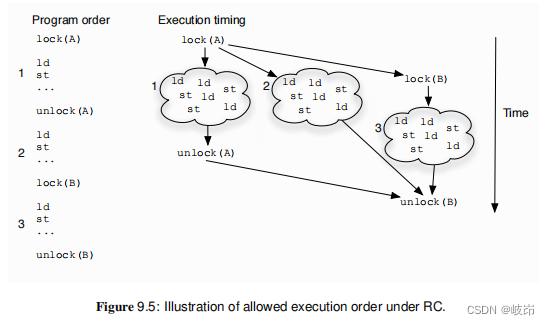
对于A的锁释放阻止向后迁移但不阻止向前迁移,因此,代码块2中的load/store的执行可以被向前移动到获得锁A之后的地方,同样对于锁B的获取的执行也可以这样移动。其结果是,代码块1、2和3的load/store指令的执行实际上可以重叠。然而,两条锁获取必须按序执行,因为它们阻止向前迁移。而两条锁的释放也必须按序执行,因为它们阻止向后迁移。动态地(硬件)和静态地(编译器对存储器访问的重排序)重叠执行代码1、2和3中存储器访问的能力与WO形成对比。在WO中,锁获取和释放锁操作维持所有在它们之前和之后的load/store指令的次序。因此,代码块1、2和3执行的相对次序是WO排定的,存储器访问的重叠只能在各个代码块的内部发生。
与WO类似,RC要求正确而且完整地标识程序中所有同步访问,这样,硬件能够保证适当同步的程序的正确执行。与WO相比,RC对程序员要求更多。程序员必须把同步访问标记为获取或释放,而不是笼统标记为同步访问。
在处理器中实现RC需要机制如下:回顾一下,释放同步必须阻止向后迁移。当在处理器流水线中碰到一个释放同步访问时,释放访问被阻塞(不能提交),直到前面的存储器访问都已经执行完毕。也就是说,所有的较早load值都已经得到它们的值,所有较早的store都已经从写缓冲区清空并已经完整地传播了它们的值(通过无效化请求)。
获取同步必须阻止向前迁移。当在处理器流水线中碰到一个获取同步访问时,在乱序执行的处理器流水线中,某些比这个获取更晚的访问可能已经被执行了。这种情形下与阻止它们向高速缓存和存储器层次其他结构发出请求的要求相矛盾。为了到达一种指令的特定状态,乱序执行处理器已经具有取消投机指令影响的机制,获取同步访问可以依靠这样的机制。当在处理器流水线碰到一个获取同步访问时,所有比其他更晚的指令(包括load和store)被取消,并在获取同步完成之后重新执行。另一种办法是,当在处理器流水线碰到一个获取同步访问时,所有处于取指和译码阶段的更晚的指令被丢弃,进一步的取值被阻塞,直到获取同步指令已经提交为止。
与WO类似,RC允许编译器自由改变load和store指令的次序,但不允许它们越过一个获取同步向前移动,也不允许它们越过一个释放同步向后移动。然而,RC的灵活性和性能优势的代价是需要适当地标识同步访问,并分别标识为获取和释放。与WO不同,单靠指令的操作码不容易标识同步访问。例如,像原子的fetch-and-op、test-and-set、LL、SC这样的特殊指令,从外观上并不能表明它们是获取还是释放。尽管一个释放总是涉及一个load,但一个获取可能涉及load及store二者。因此,合适地标识获取和释放同步的责任落在程序员的肩上。
9.3.5 惰性释放一致性
在一个获取同步完成之前,执行获取同步的线程并不需要另一个线程写入的值,从这个事实出发,可以对释放一致性RC做进一步优化。可以通过高速缓存的一致性行为的性能优化策略,若获取和释放同步访问被适当地标识,执行写传播的时序可以略微调整。
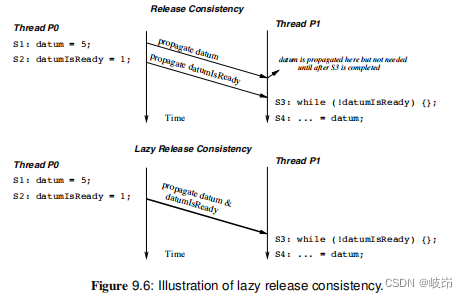
在RC模型中,datum在datumIsReady的传播之前完成传播。然而,线程P1在完成获取同步之前并不真正需要datum的值。在一个称作惰性释放一致性LRC的一致性模型中,在释放同步之前写入的值被推迟到释放同步本身一起传播。
为什么推迟写传播是有益的?的确,写的成块传播会减慢释放同步以及后续的获取同步,因此,在硬件实现的高速缓存一致性系统中它们得不到任何收益。但是,在一个处理器之间带宽很小的系统中,或者在一个少量数据的频繁传播比大量数据不频繁传播开销更高的系统中,LRC的确能改善性能。以上两种情形都存在的一个例子是不提供硬件共享存储抽象的多处理器系统,该系统用软件层提供共享存储抽象。在这样一个“软件共享存储”系统中,写传播以页的粒度传播,因此,每次传播只有一个块修改过的页的做法是非常昂贵的。
在硬件支持的高速缓存一致性系统中不使用LRC,因为在此类系统中,即使写传播是以高速缓存块这样的粒度传播,也可以被高效地执行。
9.4 不同存储一致性模型中的同步
那些编写线程库或者操作系统中同步原语的程序员最需要考虑存储一致性模型。
程序员采取的:
第一个步骤是分析系统保证了什么次序,以及他们软件正确执行需要什么次序。
然后,它们需要施加额外的排序要求。例如,通过在代码中插入栅栏指令,或者移除不必要的排序要求,如去除一些栅栏指令。多余的栅栏指令只会降低性能,但是缺少栅栏指令可能导致不正确的执行。在使用栅栏指令时,希望使用尽可能少和尽可能弱的栅栏指令仍能保证正确的执行。我们将以发布-等待同步为例说明这些模型的区别。
与依赖栅栏指令的PowerPC存储一致性编程对比,IA-64风格的存储一致性编程依赖于对存储器操作的标注。处于两个原因,标注存储器的方式更加有效。首先,它使用较少的指令,因此无须使用额外的指令。其次,使用栅栏的方法因采用了一条全功能栅栏指令(阻止向前和向后的迁移),对释放侧的限制更大,而标注方式只使用了一个释放同步(仅阻止向后迁移)。
不同的体系结构支持不同的存储器次序保证机制及安全网,这妨碍底层代码,如操作系统和线程库的可移植性。与更严格的存储一致性模型相比,RC通过允许存储器访问的重新排序而获得明显的性能收益,因此更具有吸引力。但是,其编程的复杂性,特别是不同体系结构中对同步的不同表达方式,可能是令人生畏。为了避免应对不同体系结构的复杂性,近来出现一些把存储一致性模型与编程语言相结合的做法。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









