






CLIP+domain adaption,正好是我想研究的课题,仔细读读看。
文章地址:2311.09191.pdf (arxiv.org)
摘要
类似CLIP的大型视觉-文本表示学习模型受益于通过contrastive objectives的跨模态alignment,在向下游任务的zero-shot transfer展示了令人印象深刻的表现。这个下游表现可以进一步通过大尺度微调加强,通常是compute intensive的,需要大量标签数据,而且会减少out-of-distribution robustness。而且,跨模态alignment的sole reliance可能忽视每个模态中的丰富信息。在本工作中引入了一个用于CLIP的sample-efficient domain adaptation strategy。起名,Domain Aligned CLIP(DAC),这可以同时提高在目标分布上的intra-modal alignment和inter-modal alignment,而不需要微调主模型。对于intra-modal alignment,引入一个专门用intra-modal contrastive objective训练的轻量adapter。对于inter-modal alignment,引入一个简单框架来对precomputed class text embeddings进行modulate。提出的few-shot fine-tuning framework是计算高效的,而且对分布偏移具备鲁棒性,且不改变CLIP的参数。
1 引言
CLIP,ALIGN,Florence等逐渐受欢迎,说明有必要探讨将这些模型用到不同domain和application的downstream的过程。比如在CLIP中,成功的zero-shot transfer依赖于在新的domain中适应图像和文本的modalities,以及在表示共享空间中对齐它们的表示(inter-modal alignment)。然而,CLIP的泛化能力受限于其预训练分布。为了提高它们的表现,这些模型通常会在目标分布上微调或者使用各种few-shot策略。而微调需要很多资源而且容易过拟合,few-shot adaptation可以提供一个training and sample efficient的替代方案。
在few-shot setup中,除了类别标签,我们还提供了目标分布中几张带标签的图像。这些带标签的图像的职责是data-specific priors,即需要更新CLIP已有的跨模态预测。我们提出了DAC,可以有效使用先验知识将CLIP适应到下游任务中。提升后的跨模态alignment和模态内alignment的结合可以带来downstream分类任务中few-shot transfer的更好表现。为了达到这个,我们将整个分类任务分成跨模态分类和模态内分类的ensemble。跨模态分类使用了图像-文本对的similarity,模态内分类的实现方式则是使用(由几个带标签图像的precomputed image embedding组成的)visual cache。如图1所示:

一个相似的ensembling框架最近被使用在(用于few-shot CLIP adaptation的)Tip-Adapter中。然而,针对模态内alignment的改进还没有显式的regularization。在保持模态内分类固定的同时,Tip-Adapter(-F)将visual cache当作可学习参数,并且通过优化它们来学习(可以提高上游分类表现的)residual信息。我们发现这样的优化会使得visual cache丢失其多样且丰富的visual信息,以及使得其模态内分类表现的discriminative能力恶化,如图2所示:
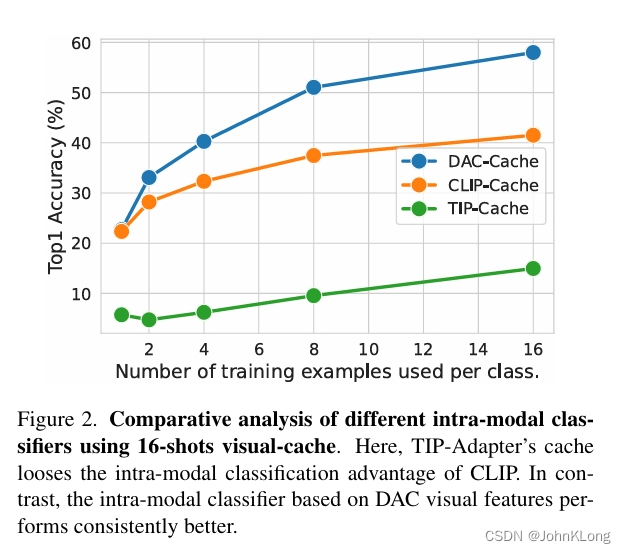
因此,忽略掉需要依赖ensemble来探索feature diversity这一点,Tip-Adapter-F减少了这个diversity并且限制了feature reuse,这对迁移学习和鲁棒性很关键。进一步地,Tip-Adapter-F不会在目标域中对文本特征进行adapt,这可能很关键,因为最近的工作聚焦于跨模态alignmentCLIP的局限,以及随着下游词汇拓展的表现衰减。
在本工作中,与Tip-Adapter-F不同,引入了两个stage adaptation strategy,单独地对模态内和跨模态分类器进行提升。图一是对整个方法的overview。我们的hypothesis被grounded在众所周知的现象,即有效的ensembles包含准确且只产生uncorrelated error的模型。在提出setup的第一阶段,一个线性adapter层被(自监督对比objective)单独训练,来对(采样自不同类别的)图像进行contrast。目标是在保持不同类别的图像的表示的距离的同时,提高来自同一类别的图像的latent表示的affinity。这将为模态内分类器带来提升,形成了DAC-V的基础。在第二阶段,引入了一个框架,可以直接优化CLIP的文本嵌入,并且提高跨模态分类器的表现,同时用来自第一阶段的模态内分类器ensemble跨模态分类器。我们称整个框架为DAC-VT,其中视觉和文本表示都被adapt到目标分布中。
我们的主要贡献如下:
一、提出DAC。一个新奇的框架,可以适应CLIP于few-shot分类任务,其学习过程是显式地对齐目标分的模态内表示和跨模态表示。就我们所知是首次利用模态内regularization进行大型视觉-语言模型的few-shot adaptation。
二、在许多图像分类benchmark上进行了广泛的量化分析,展示了我们方法比有竞争力的baseline更有限,且保有对分布偏移的合理的鲁棒性。
2 相关工作
学习能够泛化到不同任务的丰富表示是很有挑战但又很有需求的。这种表示不但可以用于向下游任务的sample-efficient tansfer,也可以简化超参数优化。鉴于此,基于自监督方法的对比学习在学习图像和文本的可转移表示这方面颇有成效。最近,这些objectives被用来在一个joint表示空间对齐不同模态的数据,在许多下游任务上取得了不错的zero-shot迁移学习表现。这些模型表现还能提升,只要在目标标签数据上微调,或者在保持特征可重新利用的同时将特征空间适应到目标分布上。第二个策略在实践上更有吸引力,因为它是sample efficient的,且只需要简单的超参数微调。对于CLIP,这种sample-efficient adaptation方法可以大致分成两类:(1)学习优化text prompt的方法(2)引入轻量adapter层来在目标分布上对齐图像和文本嵌入的方法。后者对于适应视觉和文本域都提供了更多灵活性,其中CLIP-Adapter微调(append在CLIP冻结的图像和文本编码器上的)adapter层。
DAC与CLIP-Adapter的不同
有三点不同:(1)DAC显式地优化视觉特征的模态内alignment,而CLIP-Adapter只对跨模态alignment进行处理(2)DAC只对模态内alignment使用一个single linear-layer adapter,而CLIP-Adapter在跨模态alignment的视觉和文本特征上使用two-layer MLPs(3)DAC的跨模态alignment通过直接对text cache建模完成,这比CLIP-Adapter更有效率,CLIP-Adapter是使用一个用于文本嵌入的单独的adapter。
DAC与Tip-Adapter的不同
Tip-Adapter使用一个visual caching structure来将整个分类任务分割成模态内分类器和跨模态分类器的ensemble。然而这种ensemble需要高效的子分类器,这限制了few-shot知识的充分利用。我们提出两种改进方案:第一,我们引入一个模态内对比学习框架,用于改善目标域中特征的visual alignment。我们将(论文Function contrastive learning of transferable meta-representations.)中用到的function contrastive objective,延伸到对下游类别的proxy visual function space的估计上。第二,我们微调CLIP的precomputed textual embedding,以此来mitigate其对于(目标域中类别标签的)unseen词汇的限制。这个框架比prompt tuning要简单,且不需要额外参数。而且,我们的方法区别于Tip-Adapter,消除了用于tuning image similarity scores的sharpness参数的需求。
在努力地在test-time不使用微调地前提下,适应CLIP特征的同时(代价是indistribution performance变差),我们尤其注重CLIP adaptation的few-shot fine-tuning。另外,最近的工作使用预训练语言模型,来生成额外目录信息;或者使用视觉生成模型来合成图像来拓展few-shot训练数据。不同于这些方法,DAC仅仅使用任务提供的few-shot数据。
3 背景
我们首先介绍CLIP以及其通过text-cache的实现zero-shot预测的过程。然后解释这个formulation怎么延伸到Tip-adapter上通过visual-cache来实现few-shot分类。
用Text-Cache实现zero-shot分类
CLIP是一个视觉-语言表示学习模型,它通过从图像-文本对(x,t)中学习,将视觉和文本模态对齐到一个共享嵌入空间,其中x是向量化的图像,t对应tokenized的文本。在inference-time期间,CLIP分别对文本和图像使用单独的编码器,将这些输入模态编码进d-维嵌入,即
为了简便,我们将L2-normalized embbeding记为:
然后是图像和文本嵌入的alignment,是通过cosine similarity得到的,即
CLIP使用这个图像-文本alignment来进行对新输入的zero-shot分类。
假设给定一个包含了N种分类标签的分类任务,我们首先构建precomputed weight matrix(或者说text-cache),方法是通过concatenating所有分类标签(normalized)文本嵌入:
这encapsulate了pre-computed文本知识,使其associated with任务。接着,text-cache,或者说可以被用于分类一个新的,unseen的输入图像(分为N类),方法是计算跨模态逻辑子,即:
注意仅仅需要在每个任务上计算一次。
使用Visual-Cache进行Few-shot分类
Tip-Adapter将CLIP拓展到few-shot分类上。对于每个新任务,它需要少许来自目标分布标签训练样本,其中N是类别的数量,K是每个类别的样本(或者说shot)的数量。TIp-Adapter编码这些few-shot知识,让它们变成带有分别的键和值的precomputed visual-cache。类似于等式(1),cache keys计算如下:
其中是(sub-)weight矩阵
水平地对分类标签的拼接。对应的cache values被接着构建为独热编码
,且带有真实标签
,构建方式是垂直地按每个shot拼接独热编码,然后水平地按每个分类标签进行拼接。注意这样一个key-value configuration有效地满足了visual-cache保持
中的所有few-shot知识。为了更新等式(2)中CLIP的逻辑子,要用上编码在等式(3)的visual-cache中的few-shot知识,Tip-adaptor引进了一个affinity vector:
其中exp是pointwise exponential function, modulates the sharpness of affinities。
保持了给定zimage和存储在
中的images的相似性。Tip-Adaptor最终计算合成逻辑子如下:
其中第二项代表模态内逻辑子。在这里,visual-cache中的few-shot知识被用来更新CLIP的跨模态预测,如图1中表示。注意权衡视觉和文本缓存对最终预测的贡献。进一步,Tip-Adapter-F在Tip-Adapter上改进,通过优化
的visual-cache(
)来学习residual信息,这个信息可以用来提高在目标域的上游分类表现。
4 DAC
现在我们介绍DAC,它可以分两步改善CLIP的few-shot domain adaptation表现。第一步,我们微调visual adapter layer,以此来对齐CLIP在目标分布中的视觉表示,实现更好的模态内分类器。这个模态内分类器接着成为DAC-V的基础。第二步,我们微调CLIP的文本表示,以此改善目标分布的跨模态alignment。这个跨模态分类器,与模态内分类器一起,构成DAC-VT。图1是对两种方法的overview。
4.1 adapting the visual domain
Tip-Adapter展示了基于text-cache的跨模态分类器是如何通过结合基于visual-cache的模态内分类器,得到性能上的改善的。然而,模态内分类器的表现劣于跨模态分类器的表现。这是因为CLIP被显式训练,用于图像和文本的跨模态alignment,这种情况下不建议对齐(享有相同底层概念/类别的)图像的嵌入。而且,最近的工作展示了在类CLIP模型的预训练中使用模态内alignment的优越性。
我们的工作不从scratch中训练模型,取而代之的是依赖于来自目标域的几个带标签样本,这样就能在不影响跨模态alignment的前提下,提高预训练CLIP模型的模态内alignment。
DAC visual adapter
为了对齐CLIP在目标域中的视觉特征,我们引入线性层作为一个附加到冻结了的CLIP图像编码器上的adapter。在visual adaptation的过程中我们只改变参数
。不同于两层adapter,我们发现单层线性层更有效且可以避免过拟合。为了在微调过程的开始阶段允许特征的unimpeded passage,我们初始化
为identity,使其稳定高效。
visual adapter training
接下来,我们训练,使同一类别的图像嵌入在latent space中距离更小,同时使不同类别的距离更大。和第三节背景类似,我们设定目标分布
,给定N类Kshots。为了确保同一类别的K副图像映射到相似的表示上,我们formulate一个supervised contrastive objective,如图3所示
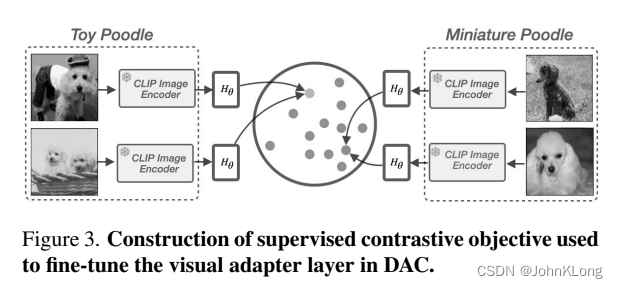
在这里,我们将K副图视作parent class为的context set
,接着这个集合被M副随机增强的图像填充,即
,在第六节中,我们提供了ablations,用于选择合适的M。为了实施visual adaptation,我们线性变换从冻结的CLIP图编码器
获得的图嵌入,紧接着是L2-normalization
,注意我们为了简便舍弃了
的dependency。我们的目标是寻找最优的变换,手段是最小化contrastive loss,即:
其中是一个scale consine similarities的temperature。最小化式(6)的目的是最大化同一类别图像embedding的相似度,同时可以最大化不同类别的不相似度(区分度)。注意其中的
考虑了
中的所有正样本,总共
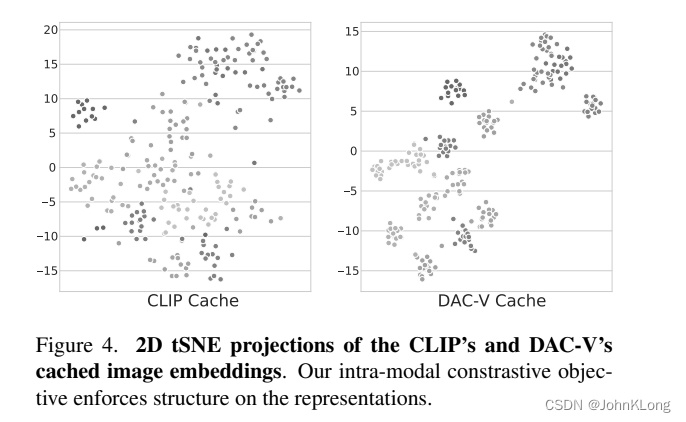
种结合。我们的visual adaptation可以用更好的cluster separation描述,见图4
constructing DAC-V
使用学习到的,就可以改善等式(3),使其变为adapted visual-cache
其中和之前一样仍是水平拼接,通过将等式(7)插入等式(4),我们获得一个适应到目标任务上的优化affinity vector。然而,注意参数是包含在可学习线性变换中的。因此,我们的optimized affinity vector为:
尽管等式(4)和等式(8)相似性是一样的,它们在关键处是不同的,具体来说,通过引入式(7)(8)的线性变化,DAC-V的新任务上的模态内表示得到了解决,而式(4)是静态的,且不能实现这种domain adaptation。和式(5)类似,我们最后将逻辑子定义为:
相比于式(5),式(9)的第二项是由在目标分布上visually aligned的图特征组成。在第五节中,我们的实验表示DAC-V在11个图像benchmark上平均超过了微调的Tip-Adaptor-F 0.83%。
4.2 adapting the textual domain
在优化了DAC-V的模态内表示后,我们着手增强目标域中图像和文本的跨模态alignment。前置工作描述了(通过优化text prompt的同时保持attached类别名称固定,以此来优化用于few-shot分类的文本嵌入的)好处。然而这样的prompt-tuning框架明显缺少微调文本嵌入的灵活度。有两个重要的问题:一,它没有解决CLIP的词汇适应到目标分布的新类别的问题,因为CLIP已有的词汇有限;二,不同的类别名称可能与多重视觉概念有关,这可能在CLIP的文本特征中引起混淆。见附录C。为了解决这些挑战,我们提出一个显著地简单的框架,用于对齐目标分布中的图像和文本标签。
DAC textual adapter
与前置工作不同,我们不为提高跨模态alignment引入新的adapter模块。取而代之的是直接微调text-cache()。注意文本嵌入是(encapsulate了目标分布的类别名称所特定的概念的)连续向量。因此,对它们的modulation影响了整个类别description。
constructing DAC-VT
为了确保DAC-V中的模态内分类器与跨模态alignment能够有丝滑的integration,我们在ensembled setting中优化。更特别地,我们转化
为一个可学习向量,并冻结包括visual cache component和
在内的所有部件。之后,使用few-shot数据集,我们优化
来合并文本嵌入和视觉嵌入,同时保持权重参数固定,即
。优化后的文本权重
引出了DAC-VT分类器,即:
直观上来说,在这个ensembled setting中优化跨模态alignment,可以使吸收DAC-V获得的few-shot知识。在第六节中,我们消融了其他几种构建DAC-VT的方法,这些方法产生的是模态内分类器和跨模态分类器的sub-optimal ensembles。
5 实验
在这一节中,我们在11个1常用图像分类任务上量化评估了我们提出的方法。我们也学习了其对分布偏移的鲁棒性。在第六节中,我们消融分析了DAC的部件和设计选择。
数据集
我们使用ImageNet,Caltech,FGVCAircraft,UCF101,EuroSAT,Flowers102,StanfordCars,DTD,Food101,OxfordPets,SUN397
training and evaluation protocol
我们遵循【33,53】中的few-shot原则,使用从训练集中采样的每种类别1,2,4,8,16shots来微调我们的模型。基于validation集,我们接着选择最佳微调adapters和最优。最后我们在测试集上评估。
对ImageNet,类似【53】,我们在validation集上报告结果。对于visual adapter的训练,我们使用Adam,使用500个epoch,0.00003的学习率,temperature =0.008,等同于数据集中类别数量的batchsize。我们将随机增强图像的数量M设为7,然后在第六节我们对这些参数做了消融实验。training augmentation包括随机水平翻转,随机腐蚀,重新调整大小至224x224。对于textual adapter的训练,我们遵循同样的数据预处理程序,但是仅仅使用100个epoch微调,学习率为0.00001.在inference time,我们使用了CLIP的预处理(中心腐蚀和resizing)。在一个single Nvidia V100 GPU上,visual adapter对16-shot的训练要花一个小时。相比之下,textual adapter只需要30秒。注意,为了建立visual cache,遵循【53】,我们随机增强每个训练图像10次,然后使用平均嵌入作为cache entry。为了公平,我们对ImageNet使用【53】的prompt ensembling,对其他数据集使用single prompt。
baselines
我们比较了DAC和其他的CLIP few-shot adaptation方法。包括linear-probe CLIP,CoOp,CLIP-Adapter,TIP-Adapter等。注意我们不和【47,51】比较,因为这些工作使用语言和视觉生成模型来生成更大的数据集。我们使用TIP-Adapter的官方代码重新产生了结果。队友其他baselines,我们提供reported scores,用于公平比较
results and discussion
在图5中,我们在所有数据集上比较了DAC-V,DAC-VT与TIP-Adapter的few-shot分类表现。
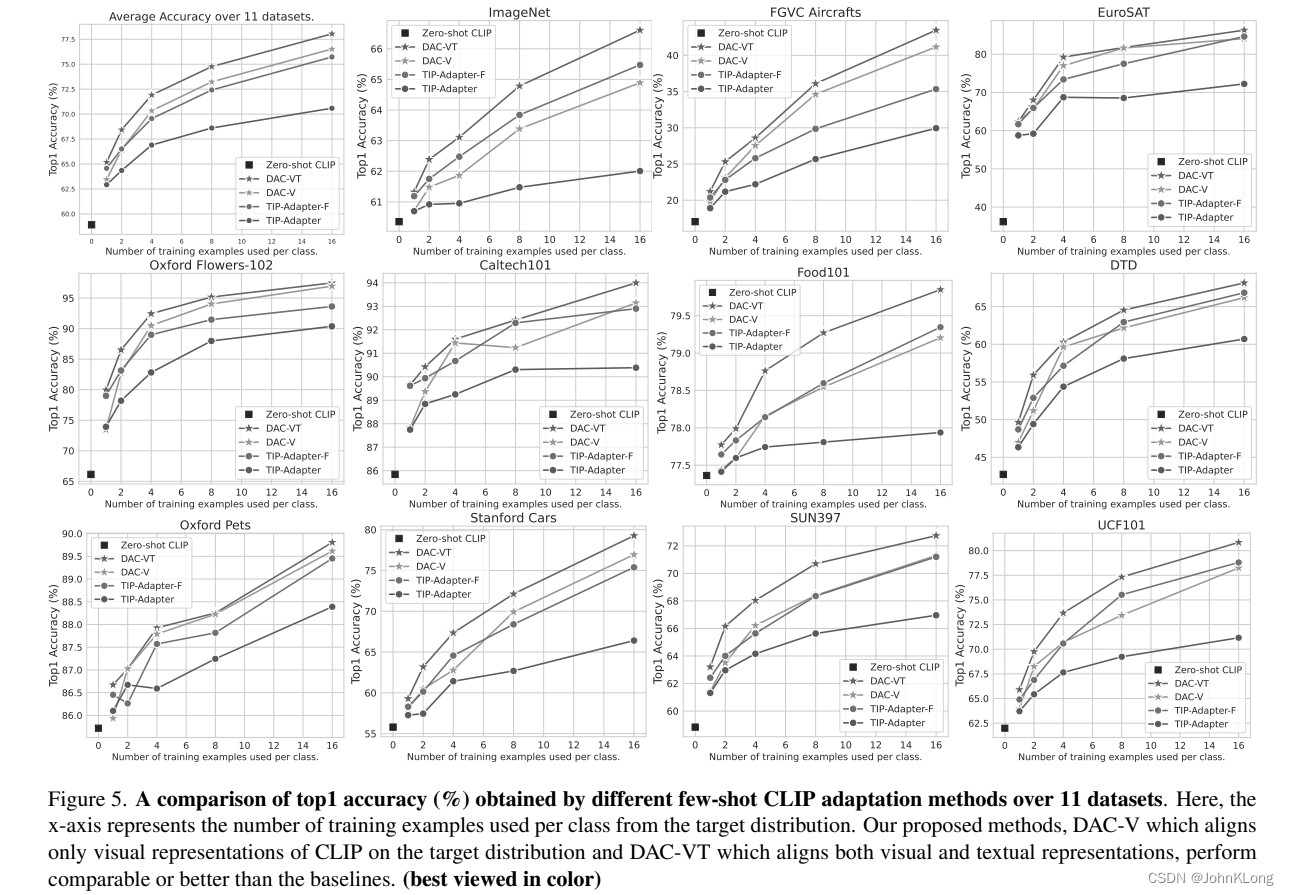
可以看到DAC-V相较于强baselineTip-Adapter-F的表现,随着shot数的增加,DAC-V的平均表现超过了Tip-Adapter-F 0.8%。注意DAC-V仅仅对齐表示,而没有通过微调进一步提高表现。这清晰地展示了拥有强大的模态内分类器的好处。随着对DAC-V的跨模态alignment的进一步优化,我们提出的DAC-VT显著超过了所有baseline。这个强有力的结果进一步描绘了在目标分布上对齐视觉和文本域的好处。图5的结果对应CLIP的ResNet-50 variant。在表1中,我们展示了使用不同CLIP骨架在ImageNet validation set上的few-shot adaptation结果。

这个结果指出了DAC-VT在所有CLIP变式中的鲁棒表现显著超过了其他baselines。
distributional robustness
Radford等展示了虽然微调能提高分布内表现,但却会减少对分布偏移的overall鲁棒性。目前为止我们发现同时在新的域中提高CLIP的视觉和文本表现,能提高其在那个域中的下游表现。然而,会不会它也减少了对分布偏移的鲁棒性呢?在这一节中,我们研究了训练于ImageNet的DAC模型对于四个ImageNet变式的转移。在表2中,我们执行一个跨数据集evaluation,并且发现模态内alignment可以比使用跨模态alignment有更好的OOD表现。我们猜想对visual特征的alignment比起跨模态alignment要对分布偏移更鲁棒。注意优化了跨模态alignment的Tip-Adapter-F,在OOD setting也没有赢过自己的untuned版本。
assaying inter- and intra-modal classifiers in DAC
图5和表1的结果证实了我们的主要假说,即强的模态内和跨模态分类器的ensemble可以带来更好的overall分类器。然而,出现了两个问题:(1)visual cache从模态内对比学习获益了多少?(2)跨模态和模态内分类器是否有制造足够不相关的错误?图2描述了模态内对比微调提高了visual cache的区分能力,在16-shot setting上提高了DAC-Cache 17%的表现。对比之下,Tip-Adapter-F的微调减少了这个表现,因为它隐式地迫使visual cache学习用于提高上游表现的residual信息,这个结果指出模态内adaptation是确定有益的。为了分析ensemble 跨模态和模态内分类器是否提升了整体表现,我们在图6(左)中画出了他们的error inconsistencies。这揭示了如果使用预训练CLIP特征,分类器会制造高度不相关错误。也就展示了通过ensembling反转错误预测的机会。DAC-Vt减少了这个error inconsistency,意味着两个分类器的预测都被翻转,不管是正确还是不正确。在图6(右)中我们展示了正确翻转百分比是非正确翻转的两倍以上,这指出了error inconsistency的减少是由于ensembled setting中的正确翻转。我们建议读者在附录B中查看不同数据集的error inconsistencies的相似行为。















 1284
1284











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









