






CROSS-DOMAIN FEW-SHOT CLASSIFICATION VIA LEARNED FEATURE-WISE TRANSFORMATION
文章汇总
存在的问题
从不同领域的任务中提取的图像特征的分布有明显的不同。因此,在训练阶段,度量函数可能会过度拟合仅从可见域编码的特征分布,从而无法推广到不可见域。
解决办法
通过一个可学习的特征转换层,以模拟从不同域编码的图像特征的各种分布。
流程解读
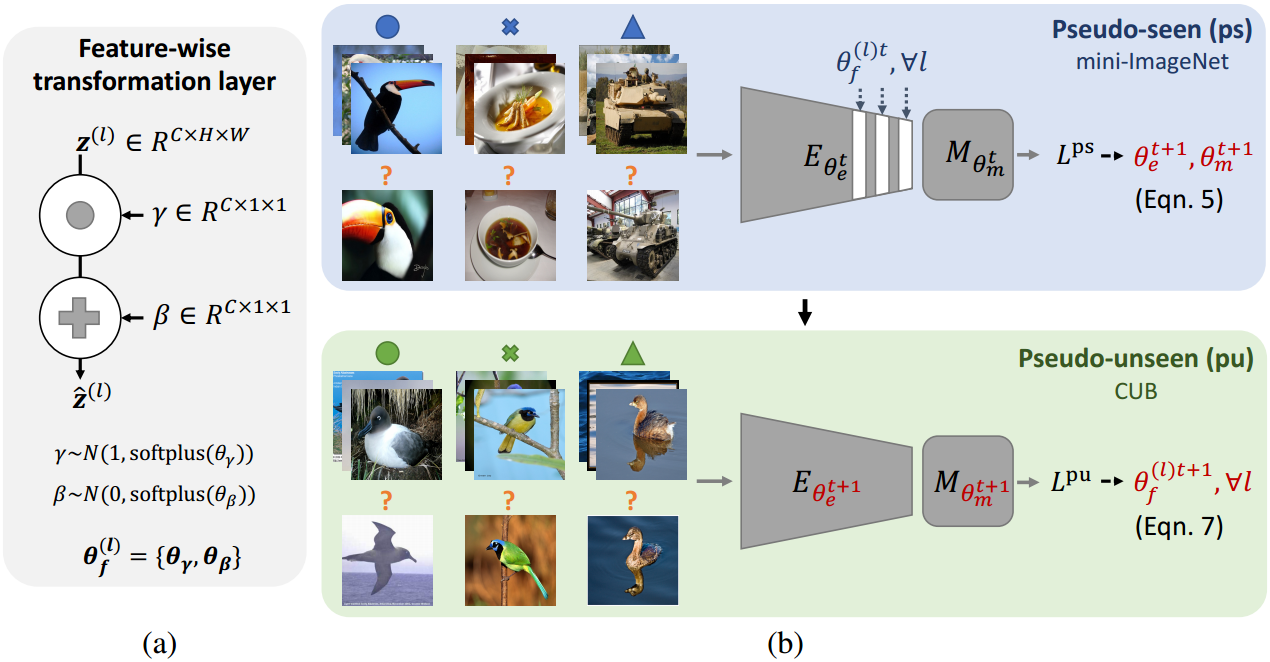
作者提出了一个在跨域领域上的即插即用模块 feature-wise transformation layer,图(a),本质有点像projection head 是一个数据增强操作,在跨域问题上,也可以被视为一种正则化网络训练的方法,为了模拟不可见域的特征分布。值得注意的是,在测试的时候是不需要数据增强的,所以需要测试时候去掉特征转换层。(对比学习中的projection head 也是如此)
关于参数的更新:
在可见域上,就是正常的步骤,用分类损失去更新encoder和度量方法的参数。
在未知域上,才用loss去更新the feature-wise transformation layers中的超参数
θ
f
=
{
θ
y
,
θ
β
}
\theta_f=\{\theta_y,\theta_{\beta}\}
θf={θy,θβ}。
feature-wise transformation layer的结构如图(a),对应公式如下

摘要
少样本分类旨在识别新类别,每个类别中只有很少的标记图像。现有的基于度量的少样本分类算法通过使用学习的度量函数将查询图像的特征嵌入与少数标记图像(支持示例)的特征嵌入进行比较来预测类别。虽然这些方法已经证明了良好的性能,但由于域间特征分布的巨大差异,这些方法往往不能推广到未见过的域。在这项工作中,我们解决了基于度量的方法在域移位下的少样本分类问题。我们的核心思想是在训练阶段使用特征转换层来增强图像特征,使用仿射变换来模拟不同域下的各种特征分布。为了捕获不同域下特征分布的变化,我们进一步应用学习到学习的方法来搜索特征转换层的超参数。我们使用5个小样本分类数据集(mini-ImageNet、CUB、Cars、Places和Plantae)在领域泛化设置下进行了广泛的实验和研究。实验结果表明,所提出的基于特征的转换层适用于各种基于度量的模型,并在域移位下对少样本分类性能有一致的改进。
1 介绍
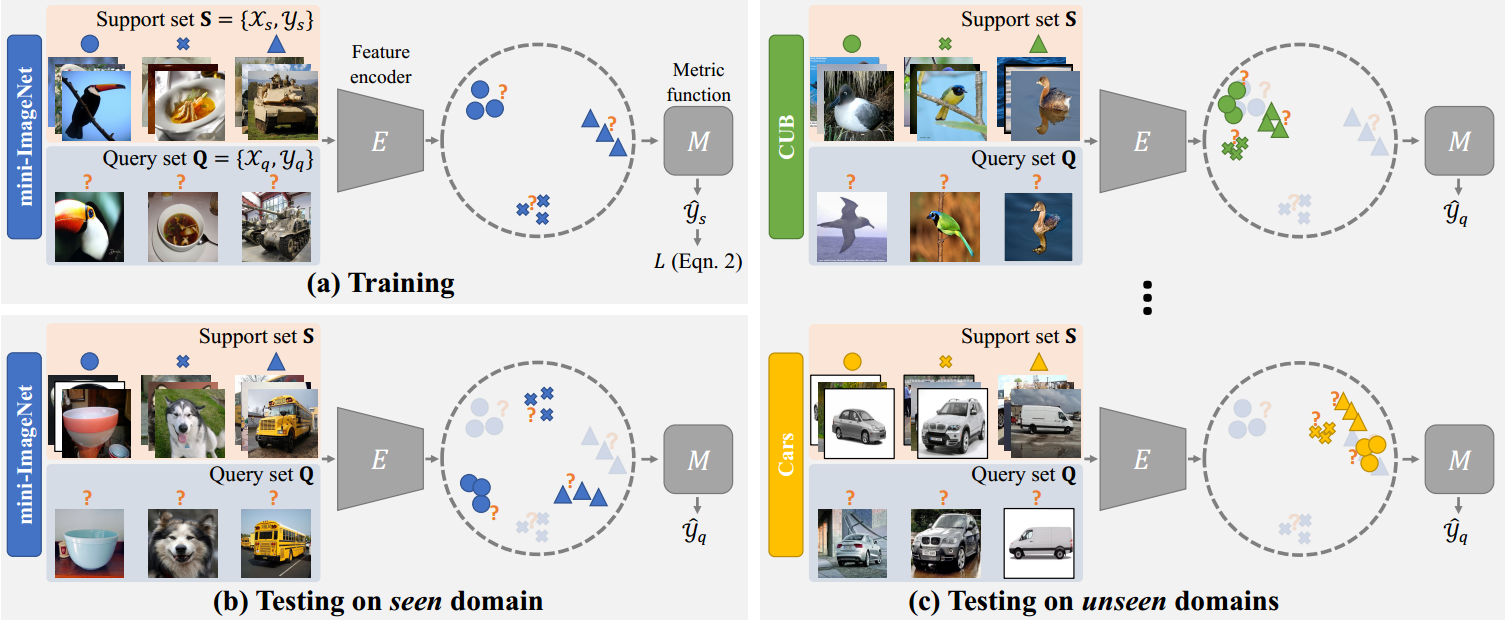
图1:问题形式和动机。基于度量的元学习模型通常由特征编码器
E
E
E和度量函数
M
M
M组成。我们的目标是提高模型从可见域训练到任意不可见域的泛化能力。关键的观察结果是,从任务中提取的图像特征分布在看不见的领域与在看到的领域有显著不同。
少样本分类(Lake et al, 2015)旨在从新类别(查询实例)中识别实例,每个类别中只有很少的标记示例(支持示例)。在最近解决少样本分类问题的各种方法中,基于度量的元学习方法(Garcia & Bruna, 2018;Sung等,2018;Vinyals et al, 2016;Snell等,2017;Oreshkin等人,2018)由于其简单和有效而受到了相当大的关注。通常,基于度量的少少样本分类方法是根据查询图像和支持样例之间的相似度进行预测的。如图1所示,基于度量的方法由1)特征编码器和2)度量函数组成。给定一个输入任务,该任务由来自新类的少量标记图像(支持集)和未标记图像(查询集)组成,编码器首先提取图像特征。然后度量函数将标记和未标记图像的特征作为输入,并预测查询图像的类别。尽管在训练阶段成功地识别了从同一领域采样的新类(例如,训练和测试都是在mini-ImageNet类上进行的),但Chen等人(Chen等人,2019a)最近提出了一个问题,即现有的基于度量的方法通常不能很好地推广到来自不同领域的类别。然而,由于为稀有类别构建大型训练数据集的困难(例如,在细粒度分类设置中识别稀有鸟类),对不可见域的泛化能力至关重要。因此,理解和解决小样本分类的域转移问题具有重要的意义。
为了缓解领域转移问题,人们提出了许多无监督的领域自适应技术(Pan & Yang, 2010;Chen et al ., 2018;Tzeng et al, 2017)。这些方法侧重于将同一类别的分类器从源域调整到目标域。Dong and Xing (Dong & Xing, 2018)在领域自适应公式的基础上,放宽了约束,跨领域转移知识,实现了一次性新类别识别。然而,无监督域自适应方法假设在训练过程中目标域中存在大量未标记的图像。在许多情况下,这种假设可能并不现实。例如,收集大量稀有鸟类的图像的成本和努力可能高得令人望而却步。另一方面,领域泛化方法得到了发展(Blanchard et al ., 2011;Li等人,2019)来学习分类器,这些分类器可以很好地泛化到多个看不见的领域,而不需要访问这些领域的数据。然而,现有的领域泛化方法的目标是在训练阶段识别同一类别的实例。
在本文中,我们解决了在少样本分类设置下识别新类别的领域泛化问题。如图1©所示,我们的关键观察是,**从不同领域的任务中提取的图像特征的分布有明显的不同。因此,在训练阶段,度量函数可能会过度拟合仅从可见域编码的特征分布,从而无法推广到不可见域。**为了解决这个问题,我们建议在特征编码器中集成基于特征的转换层,以调制具有仿射变换的特征激活。这些特征转换层的使用使我们能够在训练阶段模拟图像特征的各种分布,从而提高度量函数在测试阶段的泛化能力。然而,由于难以对不同域的图像特征分布的复杂变化进行建模,因此特征转换层的超参数可能需要细致的手工调整。鉴于此,我们开发了一种学习到学习的算法来优化所提出的特征转换层。核心思想是优化特征转换层,以便在使用可见域训练模型后,模型可以在不可见域上很好地工作。我们将源代码和数据集公开,以模拟该领域的未来研究在这项工作中,我们做出了以下三点贡献:
•我们建议使用特征转换层来模拟从不同领域的任务中提取的各种图像特征分布。我们的特征转换层是方法无关的,可以应用于各种基于度量的少样本分类方法,以提高它们对未知领域的泛化。
•我们开发了一种学习到学习的方法来优化特征转换层的超参数。与穷举参数手动调整过程相比,提出的“学习到学习”算法能够找到特征转换层的超参数,以捕获图像特征分布在各个领域的变化。
•我们在领域泛化设置下进行了大量实验,评估了三种基于度量的少样本分类模型(包括MatchingNet (Vinyals等人,2016)、RelationNet (Sung等人,2018)和图神经网络(Garcia & Bruna, 2018))的性能。我们证明了所提出的特征转换层可以有效地提高基于度量的模型对未知域的泛化能力。我们还演示了进一步的性能改进,使用我们的学习到学习方案来学习特征转换层。
2 相关工作
少样本分类
少样本分类旨在通过在每个类别中使用有限数量的标记示例来学习识别新类别。使用基于元学习的公式已经取得了重大进展。有三种主要的元学习方法用于解决少样本分类问题。首先,基于循环的框架(Rezende等人,2016;Santoro等人,2016)依次处理和编码新类别的少数标记图像。第二,基于优化的方案(Finn et al ., 2017;Rusu等人,2019;Tseng等,2019;Vuorio等人,2019)通过整合元训练阶段的微调过程,学习使用少量示例图像对模型进行微调。第三,基于度量的方法(Koch et al ., 2015;Vinyals et al, 2016;Snell等,2017;Oreshkin et al, 2018;Sung等,2018;Lifchitz et al, 2019)通过计算查询图像与少数新类别标记图像之间的相似度来对查询图像进行分类。
在这三类中,基于度量的方法由于其简单和有效而引起了相当大的关注。基于度量的少样本分类方法包括:1)特征编码器从标记和未标记的图像中提取特征;2)度量函数以图像特征作为输入并预测未标记图像的类别。例如,MatchingNet (Vinyals等人,2016)将余弦相似度与循环网络一起应用,ProtoNet (Snell等人,2017)使用欧氏距离,RelationNet (Sung等人,2018)使用CNN模块,GNN (Garcia & Bruna, 2018)使用图卷积模块作为度量函数。然而,这些度量函数可能无法推广到未知域,因为从任务中提取的图像特征在各个域的分布可能会有很大的不同。Chen等人(Chen et al ., 2019a)最近表明,在域移位下,现有的少样本分类方法的性能显著下降。我们的工作重点是提高基于度量的少样本分类模型对未知领域的泛化能力。最近,Triantafillou等人(Triantafillou等,2020)也针对跨域的少样本分类问题进行了研究。我们鼓励读者回顾以获得更完整的画面。
域适应
领域自适应方法(Pan & Yang, 2010)旨在减少源域和目标域之间的领域转移。自从领域对抗神经网络(DANN)出现以来(Ganin等人,2016),已经提出了许多框架来应用对抗训练来在特征级别上对齐源和目标分布(Tzeng等人,2017;Chen et al ., 2018;Hsu et al, 2020)或像素级(Tsai et al, 2018;Hoffman等人,2018;Bousmalis等,2017;Chen et al ., 2019b;Lee et al, 2018)。然而,大多数领域框架的目标是将从源学习到的相同类别的知识适应到目标领域,因此在处理新类别时不如在少样本分类场景中有效。一个例外是Dong和Xing (Dong & Xing, 2018)的研究,该研究解决了one-shot学习环境中的领域转移问题。然而,这些领域自适应方法需要在训练过程中访问目标领域中未标记的图像。这种假设在许多应用中可能不可行,因为很难收集到大量的稀有类别(例如稀有鸟类)的例子。
基于学习的数据增强
数据增强方法的目的是增加训练过程中数据的多样性。与水平翻转和随机裁剪等手工制作的方法不同,最近提出了几种学习数据增强的方法(Cubuk等人,2019;DeVries & Taylor, 2017a;Lemley et al, 2017;Perez & Wang, 2017;Sixt et al, 2018;Tran et al, 2017)。例如,SmartAugmentation (Lemley et al, 2017)方案训练一个网络,该网络结合了来自同一类别的多个图像。贝叶斯数据挖掘(Tran et al ., 2017)方法根据从训练集中学习到的分布来增强数据,RenderGAN (Sixt et al ., 2018)模型使用生成对抗网络模拟真实图像。此外,AutoAugment (Cubuk等人,2019)算法通过强化学习来学习增强。两个最近的框架(Shankar等人,2018;Volpi等人,2018)的目标是通过对抗性学习对不同领域的差异进行建模来增强数据。与这些捕获跨多个域的变化的方法类似,我们开发了一个学习到学习的过程来优化所提出的特征转换层,以模拟从不同域编码的图像特征的各种分布。
有条件的标准化
条件归一化旨在通过以外部数据为条件的学习仿射变换来调节激活(例如,用于捕获特定风格的艺术品图像)。条件归一化方法,包括条件批归一化(Dumoulin等人,2017)、自适应实例归一化(Huang & Belongie, 2017)和SPADE (Park等人,2019),广泛用于风格迁移和图像合成任务(Karras等人,2019;Lee et al, 2020;AlBahar & Huang, 2019)。除了图像风格化和生成之外,条件归一化也被用于对齐不同的数据分布以进行域适应(Cariucci等,2017;Li et al, 2017b)。特别是,TADAM方法(Oreshkin等人,2018)将条件批处理归一化应用于基于度量的模型,用于少样本分类任务。TADAM方法旨在对同一域下的训练任务分布进行建模。相反,我们侧重于模拟来自不同领域的各种特征分布。
神经网络的正则化
在训练阶段加入某种形式的随机性是提高泛化的有效方法(Srivastava et al ., 2014;Wan et al ., 2013;Larsson et al, 2017;DeVries & Taylor, 2017b;Zhang et al ., 2018;Ghiasi等人,2018)。所提出的用于调制中间层的特征激活的特征转换层(通过应用随机仿射变换)也可以被视为一种正则化网络训练的方法。
3 方法
3.1 知识准备
(me:这段跟传统小样本有什么区别,为什么还要介绍一下[○・`Д´・ ○])
少样本分类和基于度量的方法
少样本分类问题通常表征为
N
w
N_w
Nw way(类别数)和
N
s
N_s
Ns shot(每个类别的标记示例数)。图1显示了基于度量的框架如何在3-way 3-shot 少样本分类任务中操作的示例。基于度量的算法通常包含一个特征编码器
E
E
E和度量函数
M
M
M。在训练阶段的每次迭代中,算法随机抽取
N
w
N_w
Nw个类别样本,并构造一个任务
t
t
t。我们将输入图像集合记为
X
=
{
x
1
,
x
2
,
.
.
.
,
x
n
}
X=\{x_1,x_2,...,x_n\}
X={x1,x2,...,xn}和对应的分类标签
Y
=
{
y
1
,
y
2
,
.
.
.
,
y
n
}
Y=\{y_1,y_2,...,y_n\}
Y={y1,y2,...,yn}。任务
T
T
T由支持集
S
=
{
(
X
s
,
Y
s
)
}
S=\{(X_s,Y_s)\}
S={(Xs,Ys)},查询集
Q
=
{
(
X
q
,
Y
q
)
}
Q=\{(X_q,Y_q)\}
Q={(Xq,Yq)}。通过对每一个
N
w
N_w
Nw类别随机选择
N
s
N_s
Ns个和
N
q
N_q
Nq个样本,分别形成支持集
S
S
S和查询集
Q
Q
Q。
特征编码器
E
E
E首先从支持和查询图像中提取特征。然后,度量函数
M
M
M根据支持图像
Y
s
Y_s
Ys、编码后的查询图像
E
(
x
q
)
E(x^q)
E(xq)和编码后的支持图像
E
(
X
s
)
E(X_s)
E(Xs)的标签,预测查询图像
X
q
X_q
Xq的类别。该过程可表述为
Y
^
q
=
M
(
Y
s
,
E
(
X
s
)
,
E
(
X
Q
)
)
(
1
)
\hat Y_q=M(Y_s,E(X_s),E(X_Q)) \ (1)
Y^q=M(Ys,E(Xs),E(XQ)) (1)
最后,基于度量的框架的训练目标是查询集中图像的分类损失,
L
=
L
c
l
s
(
Y
q
,
Y
^
q
)
(
2
)
L=L_{cls}(Y_q,\hat Y_q) \ (2)
L=Lcls(Yq,Y^q) (2)
各种基于度量的算法之间的主要区别在于度量函数
M
M
M的设计选择。例如,MatchingNet (Vinyals等人,2016)方法利用长短期记忆(LSTM), RelationNet (Sung等人,2018)模型应用卷积神经网络(CNN),而GNN (Garcia & Bruna, 2018)方案使用图卷积网络。
问题设置
在本工作中,我们解决了领域泛化设置下的少样本分类问题。我们表示一个由少量分类任务集合组成的域为 T = { T 1 , T 2 , . . . , T n } T=\{T_1,T_2,...,T_n\} T={T1,T2,...,Tn}。我们假设 N N N个可见定义域 { T 1 s e e n , T 2 s e e n , . . . , T N s e e n } \{T_1^{seen},T_2^{seen},...,T_N^{seen}\} {T1seen,T2seen,...,TNseen}在训练阶段可用。目标是学习使用可见域的基于度量的少样本分类模型,这样该模型可以很好地推广到未知域。例如,可以使用mini-ImageNet (Ravi & Larochelle, 2017)数据集以及一些公开可用的细粒度少量分类域(例如CUB)训练模型(Welinder等人,2010),然后评估模型在未知植物域上的泛化能力。注意,我们的问题公式在训练阶段不访问未见域的图像。
3.2 特征转换层
图2:方法概述。(a)我们提出了一个特征转换层,通过从超参数
θ
y
,
θ
β
\theta_y,\theta_{\beta}
θy,θβ参数化的高斯分布中采样的缩放和偏置项来调制特征编码器E中的中间特征激活
z
z
z。在训练阶段,我们将一组特征转换层插入到特征编码器中,以模拟从各个领域的任务中提取的特征分布。(b)我们设计了一种学习到学习的算法,通过在伪可见域(上)上优化应用的基于度量的模型在伪不可见域(下)上的性能最大化,来优化特征转换层的超参数
θ
y
,
θ
β
\theta_y,\theta_{\beta}
θy,θβ。
我们的工作重点是提高基于度量的少镜头分类模型对任意不可见域的泛化能力。如图1所示,由于从任务中提取的特征分布在可见域和不可见域之间存在差异,**度量函数M可能会过拟合到可见域,而不能推广到不可见域。为了解决这一问题,我们建议将特征转换集成到特征编码器E中,以增强具有仿射变换的中间特征激活。**直观地看,与特征转换层集成的特征编码器
E
E
E可以产生更多样化的特征分布,从而提高度量函数
M
M
M的泛化能力。如图2(b)所示。我们在特征编码器
E
E
E的批归一化层之后插入特征转换层。超参数
θ
y
∈
R
C
×
1
×
1
,
θ
β
∈
R
C
×
1
×
1
\theta_y \in R^{C\times 1\times 1},\theta_{\beta} \in R^{C\times 1\times 1}
θy∈RC×1×1,θβ∈RC×1×1**表示仿射变换参数采样的高斯分布的标准差。**给定特征编码器中的中间特征激活图
z
z
z,尺寸为
C
×
H
×
W
C\times H\times W
C×H×W,我们首先从高斯分布中采样缩放项
y
y
y和偏置项
β
\beta
β,
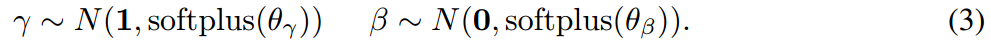
然后我们计算调制激活
z
^
\hat z
z^
其中
z
^
c
,
h
,
w
∈
z
^
,
z
c
,
h
,
w
∈
z
\hat z_{c,h,w}\in \hat z , z_{c,h,w}\in z
z^c,h,w∈z^,zc,h,w∈z。在实践中,我们在多个级别将特征转换层插入到特征编码器
E
E
E中。
3.3 学习特征转换层
虽然我们可以根据经验确定超参数
θ
f
=
{
θ
y
,
θ
β
}
\theta_f=\{\theta_y,\theta_{\beta}\}
θf={θy,θβ}的特征转换层,手动调整在不同设置(即,不同的基于度量的框架和不同的可见域)上有效的通用参数集仍然具有挑战性。为了解决这个问题,我们设计了一个学习到学习的算法来优化特征转换层的超参数。核心思想是,在可见域上训练基于度量的模型与提议的层集成,应该提高模型在不可见域上的性能。
我们在图2(b)和算法1中说明了这个过程。在每个训练迭代
t
t
t中,我们从一组可见域
{
T
1
s
e
e
n
,
T
2
s
e
e
n
,
.
.
.
,
T
N
s
e
e
n
}
\{T^{seen}_1,T^{seen}_2,...,T^{seen}_N\}
{T1seen,T2seen,...,TNseen}中抽取一个伪可见域
T
p
s
T^{ps}
Tps和一个伪不可见域
T
p
u
T^{pu}
Tpu;给定一个带有特征编码器
E
θ
e
t
E_{\theta^t_e}
Eθet和度量函数
M
θ
e
t
M_{\theta^t_e}
Mθet的基于度量的模型,我们首先用超参数
θ
f
t
=
{
θ
y
t
,
θ
β
t
}
\theta_f^t=\{\theta_y^t,\theta_{\beta}^t\}
θft={θyt,θβt}来整合所提出的层特征编码器(即
E
θ
e
t
,
θ
f
t
E_{\theta^t_e,\theta^t_f}
Eθet,θft)。然后,我们使用公式2中的损失来更新基于度量的模型中的参数,其中伪可见任务
T
p
s
=
{
X
s
p
s
,
Y
s
p
s
}
T^{ps}=\{{X^{ps}_s,Y^{ps}_s}\}
Tps={Xsps,Ysps},也就是
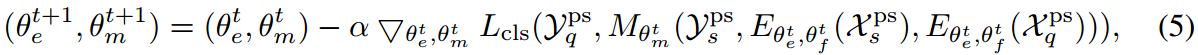
其中
α
\alpha
α是学习率。然后,我们通过以下方法来衡量更新后的基于度量的模型的泛化能力:1)**从模型中去除特征转换层;**2)计算更新后的模型在伪不可见任务
T
p
u
=
{
(
X
s
p
u
,
Y
s
p
u
)
,
(
X
q
p
u
,
Y
q
p
u
)
}
∈
T
p
u
T^{pu}=\{(X^{pu}_s,Y^{pu}_s),(X^{pu}_q,Y^{pu}_q)\}\in T^{pu}
Tpu={(Xspu,Yspu),(Xqpu,Yqpu)}∈Tpu,即
最后,由于损失
L
p
u
L^{pu}
Lpu反映了特征转换层的有效性,我们优化超参数
θ
f
\theta_f
θf

注意,基于度量的模型和基于特征的转换层在训练阶段是联合优化的。

4 实验结果
4.1 实验设置
我们用三种现有的基于度量的算法(Vinyals等,2016;Sung等,2018;Garcia & Bruna, 2018)在两个实验设置下。首先,我们经验地确定超参数特征转换层的
θ
f
=
{
θ
y
,
θ
β
}
\theta_f=\{\theta_y,\theta_{\beta}\}
θf={θy,θβ},分析特征转换层的影响。我们在mini-ImageNet (Bousmalis等人,2017)领域上训练了少样本分类模型,并在四个不同的领域上评估了训练好的模型:CUB (Welinder等人,2010)、Cars (Krause等人,2013)、Places (Zhou等人,2017)和Plantae (Van Horn等人,2018)。其次,我们证明了所提出的学习到学习方案对于优化特征转换层的超参数的重要性。我们通过从CUB、Cars、Places和Plantae域中选择一个不可见的域来采用留一个设置。然后,mini-ImageNet (Bousmalis等人,2017)和其余域作为使用算法1训练基于度量的模型和特征转换层的可见域。训练完成后,我们在选定的不可见域上对训练好的模型进行评估
数据集。我们使用五个数据集进行实验:mini-ImageNet (Ravi & Larochelle, 2017)、CUB (Welinder等人,2010)、Cars (Krause等人,2013)、Places (Zhou等人,2017)和Plantae (Van Horn等人,2018)。由于mini-ImageNet数据集作为所有实验的视觉域,我们在mini-ImageNet数据集的验证集上选择精度最高的训练迭代进行评估。更多数据集处理的细节见附录A.1。
实现细节。我们将特征转换层应用于三个基于度量的框架:MatchingNet (Vinyals等人,2016)、RelationNet (Sung等人,2018)和GNN (Garcia & Bruna, 2018)。我们使用Chen等人的公开实现(Chen等人,2019a)来训练MatchingNet和RelationNet模型对于GNN方法,我们将图卷积网络的官方实现集成到Chen的实现中在所有实验中,我们采用ResNet-10 (He et al ., 2016)模型作为特征编码器E的骨干网络。我们给出了1的平均结果;所有的实验都进行了1000次试验。在每次试验中,我们随机抽取Nw个类别(例如,5个类别进行5-way 分类)。对于每个类别,我们随机为支持集
X
s
X_s
Xs选择
N
s
N_s
Ns图像(例如,1-shot或5-shot),为查询集
X
q
X_q
Xq选择16图像。我们将在附录A.2中讨论实现细节。
预训练特征编码器。在少镜头分类训练阶段之前,我们首先通过最小化mini-ImageNet数据集中64个训练类别的标准交叉熵分类损失来预训练特征编码器E。此策略可以显著提高基于度量的模型 的性能,并在最近的几个框架中被广泛采用(Rusu等人,2019;Gidaris & Komodakis, 2018;Lifchitz et al, 2019)。
4.2 带有手动参数调优的特征转换
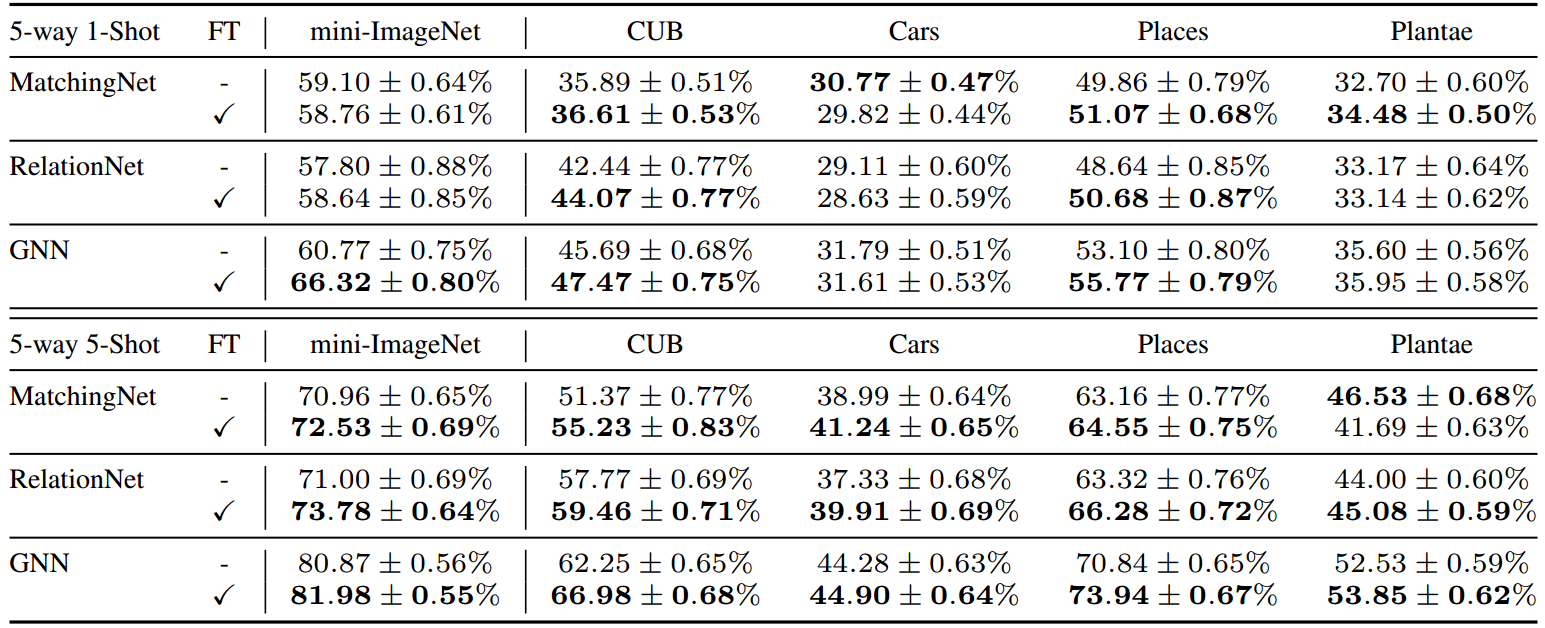
表1:使用mini-ImageNet数据集训练的少量分类结果。我们在mini-ImageNet域上训练模型,并在另一个域上评估训练好的模型。FT表明我们应用具有经验确定的超参数的特征转换层来训练模型。
我们使用mini-ImageNet数据集训练模型,并使用其他四个看不见的域(CUB、Cars、Places和Plantae)评估训练后的模型。在训练阶段,我们在特征编码器E中所有剩余块的最后一批归一化层之后添加所提出的特征转换层。我们经验地将所有特征转换层中的
θ
y
,
θ
β
\theta_y,\theta_{\beta}
θy,θβ分别设置为0:3和0:5。表1显示了使用特征转换层训练的基于度量的模型,它在单独的基线上表现良好。我们将泛化的改进归功于所提出的层的使用,使特征编码器E在训练阶段产生更多样化的特征分布。作为副产品,我们还观察到在视觉域(即mini-ImageNet)上的改进,因为从同一域的训练集和测试集提取的特征分布之间仍然存在轻微的差异。值得注意的是,我们还将所提出的方法与表8和表9中的几种最新方法(例如Lee等人(2019))进行了比较。通过提出的特征转换层,GNN (Garcia & Bruna, 2018)模型在可见域(即mini-ImageNet)和不可见域上与最先进的框架相比都表现良好。
4.3 多域泛化
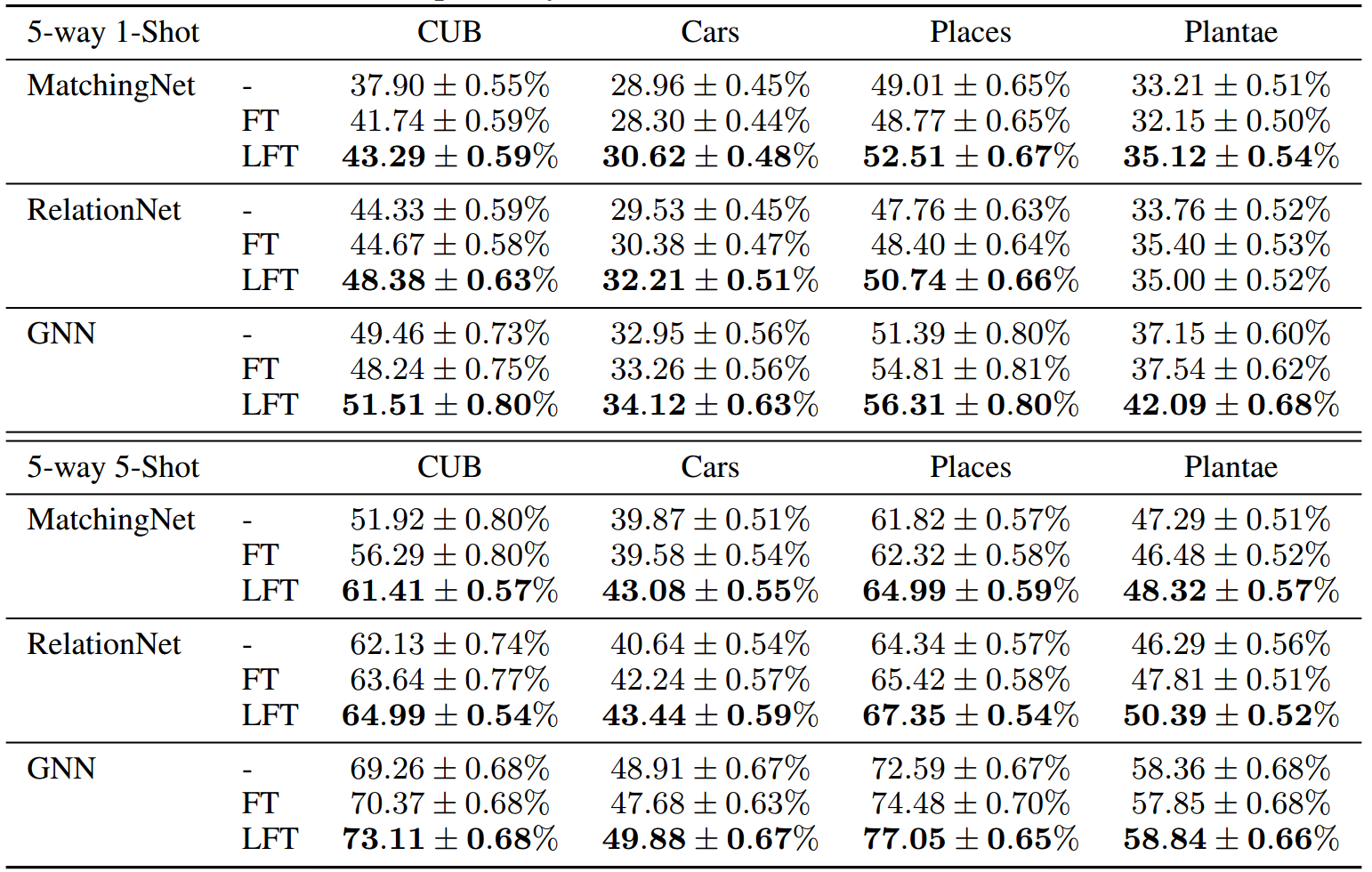
表2:多数据集训练的少样本分类结果。我们使用留一设置来选择看不见的域,并使用算法1训练模型以及特征转换层。FT和LFT表示应用预先确定的和学习到学习的特征转换
在这里,我们验证了所提出的学习到学习算法在优化特征转换层的超参数方面的有效性。我们将使用提出的学习过程训练的度量模型与使用预先确定的特征转换层训练的模型进行比较。left -one-out设置用于从CUB、Cars、Places和Plantae中选择一个域作为评估的不可见域。mini-ImageNet和其余域作为训练模型的可见域。由于我们根据mini-ImageNet域上的验证性能选择训练迭代进行评估,因此我们不将mini-ImageNet视为未见域。我们在表2中给出了结果。我们将**FT和LFT分别表示为应用预先确定的特征转换层和使用提出的学习到学习算法优化的那些层。**由于优化后的特征转换层可以更好地捕获不同域间特征分布的变化,因此使用该学习方案优化的模型优于使用预先确定的特征转换层训练的模型。表1和表2显示了所提出的特征转换层与“学习到学习”算法一起有效地缓解了基于度量的框架的领域转移问题。
注意,由于提出的“学习到学习”方法通过随机梯度下降来优化超参数,因此可能无法找到达到最佳性能的全局最小值。当然可以手动找到另一组实现更好性能的超参数设置。然而,这需要细致且计算代价高昂的超参数调优。具体来说,对于特征编码器中的第i个特征转换层,超参数
θ
y
,
θ
β
\theta_y,\theta_{\beta}
θy,θβ的维数为
c
i
×
1
×
1
c_i \times 1\times 1
ci×1×1,其中
c
i
c_i
ci是特征通道的数量。由于特征编码器E中有n个特征转换层,我们需要在
(
c
1
+
c
2
+
.
.
.
+
c
N
)
×
2
(c_1+c_2+...+c_N)\times 2
(c1+c2+...+cN)×2维空间中执行超参数搜索。在实际中,搜索空间的维数为1920。
可视化特征转换后的特征

图3:不同领域任务提取图像特征的T-SNE可视化。我们展示了由(a)原始特征编码器E提取的特征的t-SNE可视化,(b)具有预先确定的特征智能转换层的特征编码器,以及©具有学习到学习特征智能转换的特征编码器。
为了证明所提出的特征转换层可以模拟从不同领域的任务中提取的各种特征分布,我们在图3中展示了由RelationNet (Sung et al, 2018)模型中的特征编码器提取的图像特征的t-SNE可视化。该模型在mini-ImageNet、Cars、Places和Plantae域(即对应)上使用5-way 5-shot分类设置进行训练到表2中第二列的第五个块)。我们观察到,在特征转换层的帮助下,从不同域提取的特征之间的距离变得更小。此外,提出的“学习到学习”方案可以进一步帮助特征转换层捕获不同领域特征分布的变化,从而缩小领域差距,提高基于度量的模型的泛化能力。
可视化特征转换层
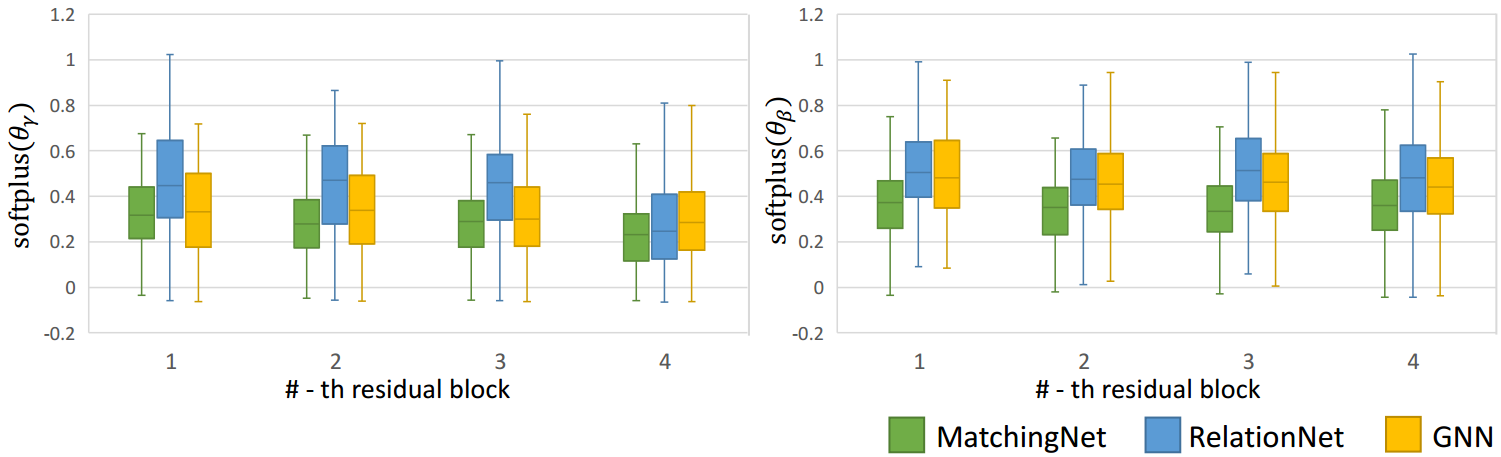
图4:特征转换层的可视化。我们展示了由提出的学习到学习算法优化的每个特征转换层的激活softplus(
θ
y
\theta_y
θy)和softplus(
θ
β
\theta_{\beta}
θβ)的四分位数可视化。
为了更好地理解学习到的特征转换层是如何操作的,我们展示了特征转换层中的softplus(
θ
y
\theta_y
θy)和softplus(
θ
β
\theta_{\beta}
θβ)的值。图4显示了可视化。尺度项softplus(
θ
y
\theta_y
θy)的值在较深的层中趋于变小,特别是在最后一个残差块中。另一方面,层的深度似乎对偏差项softplus(
θ
β
\theta_{\beta}
θβ)的分布没有明显的影响。在不同的基于度量的分类方法中,分布也是不同的。这些结果表明了所提出的“学习到学习”算法的重要性,因为不存在一组与所有基于度量的方法都能很好地工作的特征转换层的最优超参数。
5 结论
提出了一种在域移位下有效增强基于度量的少样本分类框架的方法。该方法的核心思想是利用特征转换层来模拟从不同领域的任务中提取的各种特征分布。我们开发了一种学习到学习的方法,通过模拟使用多个可见域的泛化过程来优化特征转换层的超参数。从大量的实验中,我们证明了我们的技术适用于不同的基于度量的少样本分类算法,并在基线上显示出一致的改进。
参考资料
论文下载(ICLR 2020)
https://arxiv.org/abs/2001.08735
代码地址
https://github.com/hytseng0509/CrossDomainFewShot
参考文章
https://blog.csdn.net/s_m_c/article/details/135721916?spm=1001.2014.3001.5502
















 1120
1120











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











