






taptap评论爬虫
1、下载fidder
1.1、官方下载
官网下载链接: fidder.
1.2、fidder使用
使用fidder获取url: b站视频.
1.3、获取并复制保存url
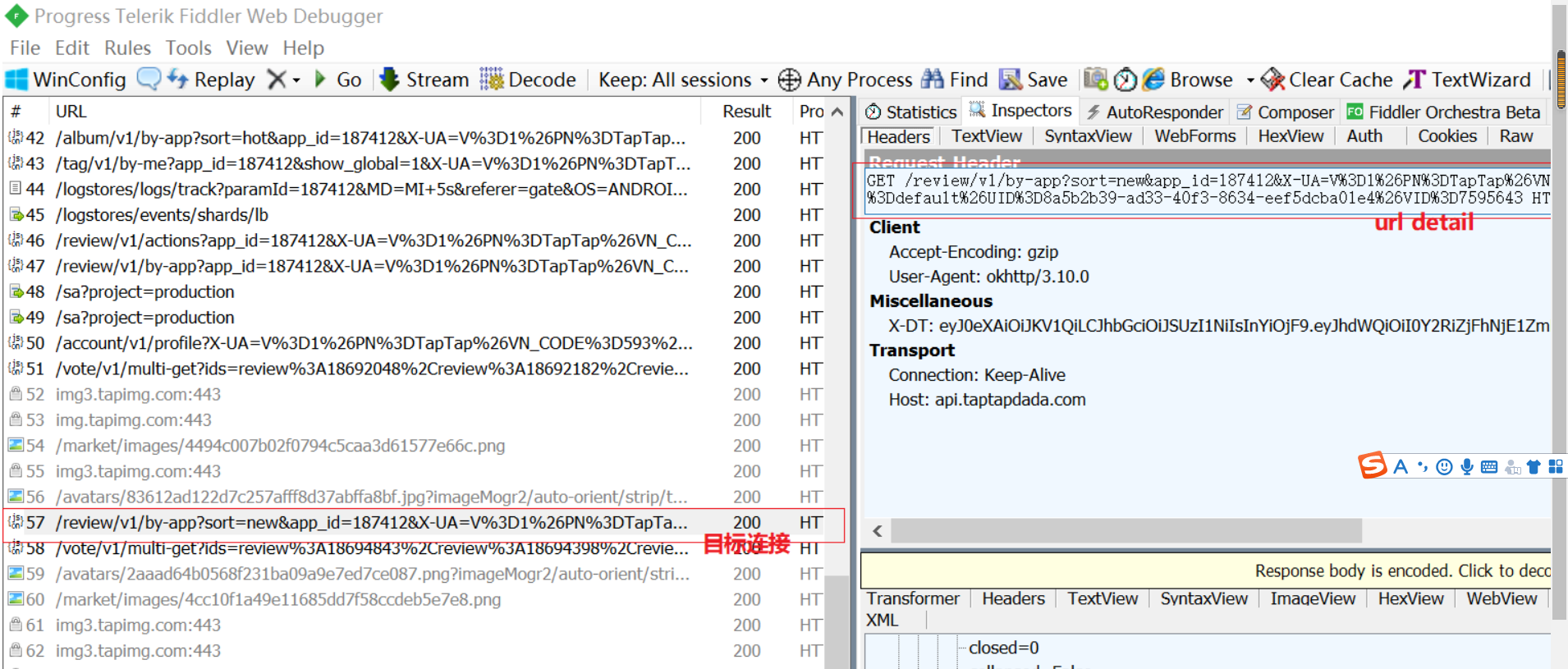
2、评论爬虫和保存
2.1、爬虫的代码
import requests
import os
import re
import random
import time
import csv
# 请求头
HEADERS = {'Host': 'api.taptapdada.com',
'Connection': 'Keep-Alive',
'Accept-Encoding': 'gzip',
'User-Agent': 'okhttp/3.10.0'}
# 基础页面 每个页面有10条评论,'from'参数表示评论序号,从0开始,每+10翻页一次
BASE_URL = 'https://api.taptapdada.com/review/v1/by-app?sort=new&app_id={}' \
'&X-UA=V%3D1%26PN%3DTapTap%26VN_CODE%3D593%26LOC%3DCN%26LANG%3Dzh_CN%26CH%3Ddefault' \
'%26UID%3D8a5b2b39-ad33-40f3-8634-eef5dcba01e4%26VID%3D7595643&from={}'
# 保存断点的文件
STOP_POINT_FILE = 'stop_point.txt'
class TapSpiderByRequests:
def __init__(self, csv_save_path, game_id):
"""
获取断点,激活爬虫
"""
# 获取断点
self.start_from = self.resume()
# 重置保存评论的列表
self.reviews = []
# 运行爬虫
self.spider(csv_save_path, game_id)
def spider(self, csv_save_path, game_id):
"""
发送请求,验证访问状态
:return: 网页返回的json数据
"""
end_from = self.start_from + 300
# 循环爬取30页
for i in range(self.start_from, end_from+1, 10):
url = BASE_URL.format(game_id, i)
try:
resp = requests.get(url, headers=HEADERS).json()
resp = resp.get('data').get('list')
self.parse_info(resp)
print('=============已爬取第 %d 页=============' % int(i/10))
# 等待0至2秒,爬下一页
if i != end_from:
print('爬虫等待中...')
pause = random.uniform(0, 2)
time.sleep(pause)
print('等待完成,准备翻页。')
# 顺利爬至末页,则保存断点
else:
with open(STOP_POINT_FILE, 'w') as f:
f.write(str(i+10))
# 出错,则中断爬虫,保存断点
except Exception as error:
with open(STOP_POINT_FILE, 'w') as f:
f.write(str(i))
# 打印异常信息
print('爬取第%i页出现异常,断点已保存,异常信息如下:' % int(i/10))
raise error
# 退出程序
exit()
# 将信息写入csv
self.write_csv(csv_save_path, self.reviews)
def parse_info(self, resp):
"""
:param resp: 本页返回的json数据
:return: 将本页评论信息追加至REVIEWS列表
"""
for r in resp:
review = {}
# id
review['id'] = r.get('id')
# 昵称
review['author'] = r.get('author').get('name').encode('gbk', 'ignore').decode('gbk')
# 评论时间
review['updated_time'] = r.get('updated_time')
# 设备
review['device'] = r.get('device').encode('gbk', 'ignore').decode('gbk')
# 游玩时长(分钟)
review['spent'] = r.get('spent')
# 打分
review['stars'] = r.get('score')
# 评论内容
content = r.get('contents').get('text').strip()
review['contents'] = re.sub('<br />| ', '', content).encode('gbk', 'ignore').decode('gbk')
# 支持度
review['ups'] = r.get('ups')
# 不支持度
review['downs'] = r.get('downs')
self.reviews.append(review)
# 断点续传
def resume(self):
"""
爬取出错时,将出错url的‘from’参数值保存至txt中,中断爬虫。再次运行爬虫程序后,从此页继续爬取
:return: 本次续连url的‘from’参数值
"""
start_from = 0
if os.path.exists(STOP_POINT_FILE):
with open(STOP_POINT_FILE, 'r') as f:
start_from = int(f.readline())
return start_from
# 追加写入csv
def write_csv(self, full_path, reviews):
"""
:param full_path: csv保存的完整路径
:param reviews: 列表形式的评论信息
"""
title = reviews[0].keys()
path, file_name = os.path.split(full_path)
if os.path.exists(full_path):
with open(full_path, 'a+', newline='', encoding='utf-8-sig') as f:
writer = csv.DictWriter(f, title)
writer.writerows(reviews)
else:
try:
os.mkdir(path)
except Exception:
print('路径已存在,或未获得建立路径的权限。请检查路径是否存在,或手动建立路径。')
with open(full_path, 'a+', newline='', encoding='utf-8-sig') as f:
writer = csv.DictWriter(f, title)
writer.writeheader()
writer.writerows(reviews)
if __name__ == '__main__':
# csv保存路径
csv_save_path = r'G:\设计\taptap\原神评论.csv'
# 游戏id
game_id = 168332
# 循环爬取至990页
for i in range(33):
TapSpiderByRequests(csv_save_path, game_id)
2.1、评论清洗
# coding=gbk
import pandas as pd
import time
import re
import numpy as np
# 爬虫获取的数据的所在路径
csv_path = r'G:\设计\taptap\原神评论.csv'
# 清洗后的数据的保存路径
clean_path = r'G:\设计\taptap\原神评论清洗.csv'
# 读取数据
data = pd.read_csv(csv_path, header=0, index_col='id')
# # 查看前20条数据和列名
# print(data[:20])
# print(data.columns)
# 将评论时间由时间戳转日期
data['updated_time'] = data['updated_time'].apply(lambda x: time.strftime('%Y-%m-%d', time.localtime(x)))
# 评论净支持数
data['net_support'] = data['ups'] - data['downs']
# 评论热度
data['heat'] = data['ups'] + data['downs']
data['heat'] = (data['heat'] - data['heat'].min()) / (data['heat'].max() - data['heat'].min())
# 评分
data['score'] = data['stars']*2
# 将游玩时间为0的标注为缺失值
data['spent'] = data['spent'].replace(0, np.nan)
# 清除无意义字符
data['contents'] = data['contents'].apply(lambda x: re.sub('&[\w]+;', '', str(x)))
data['contents'] = data['contents'].apply(lambda x: re.sub('\(\s*\)', '', str(x)))
# 删除用不上的列
data.drop(['ups', 'downs'], axis=1, inplace=True)
# 保存数据,转换成utf-8编码
data.to_csv(clean_path, encoding='utf_8_sig')

















 4682
4682

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









