







TAPTAP评论的文本挖掘
背景
玩家评论可以为游戏的版本迭代提供重要参考,假如可以快速定位玩家的负面评价,则能够节约收集意见的时间成本。本项目通过文本挖掘方法,展示从数据采集到情感模型评价的全过程。
本项目的完整代码:Github地址
本项目可视化的动态展示:和鲸地址
一、爬虫
TAPTAP评论数据通过JSON返回,使用python中的Requests库非常容易就可以提取里面的内容。下面这幅图是Fiddler抓包时看到的数据:
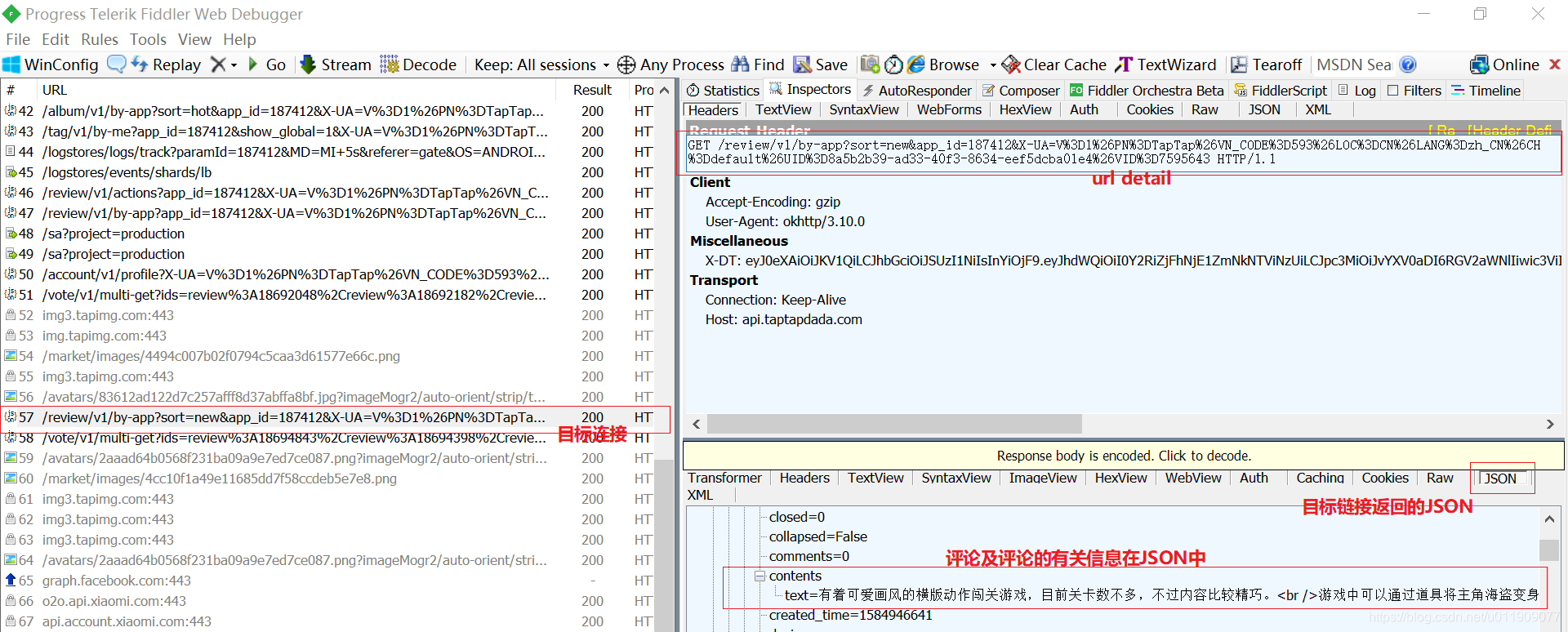
断点续传:
建立断点txt文件,在因网络等原因中断时,重启程序,可以在断点处续爬,在中断时,已缓存的数据将保存至csv
def resume(self):
"""
爬取出错时,将出错url的‘from’参数值保存至txt中,中断爬虫。再次运行爬虫程序后,从此页继续爬取
:return: 本次续连url的‘from’参数值
"""
start_from = 0
if os.path.exists(STOP_POINT_FILE):
with open(STOP_POINT_FILE, 'r') as f:
start_from = int(f.readline())
return start_from
爬虫休眠:
文明爬虫,虽未发现反爬,但爬完每个页面后暂停0-2秒,减轻服务器负担
import random
import time
pause = random.uniform(0, 2)
time.sleep(pause)
编码转换:
python中比较容易出现编码问题,在中文环境下更甚,评论里可能会有无法打印的字符,虽然不影响数据下载,但容易影响后续处理。先把数据进行gbk编码,丢弃无法识别的字符,再进行解码,最后将数据保存为utf-8格式,上面的问题就不存在啦~
review['author'] = r.get('author').get('name').encode('gbk', 'ignore').decode('gbk')
其他信息:
每页10条数据,每个游戏的评论最多可爬990页,超过990页,TAPTAP拒绝访问。爬至页面上限需要约30分钟,可以去喝喝茶再回来(因为爬虫不是重点,没有进行速度方面的优化)。程序将采集到的数据存放至你指定路径的csv中。完整代码
二、数据清洗
这一步主要为数据可视化服务,使用pandas库可以很方便地进行数据清洗。
时间戳转换日期:
为了让pyecharts识别出时间标签,需要进行日期转换
import time
data['updated_time'] = data['upda 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1754
1754

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









