









0825(039天 集合框架04 队列、集合)
每日一狗(田园犬西瓜瓜)

集合框架04 队列、集合
1. 栈
栈:先进后出,容器,有序。
[外链图片转存失败,源站可能
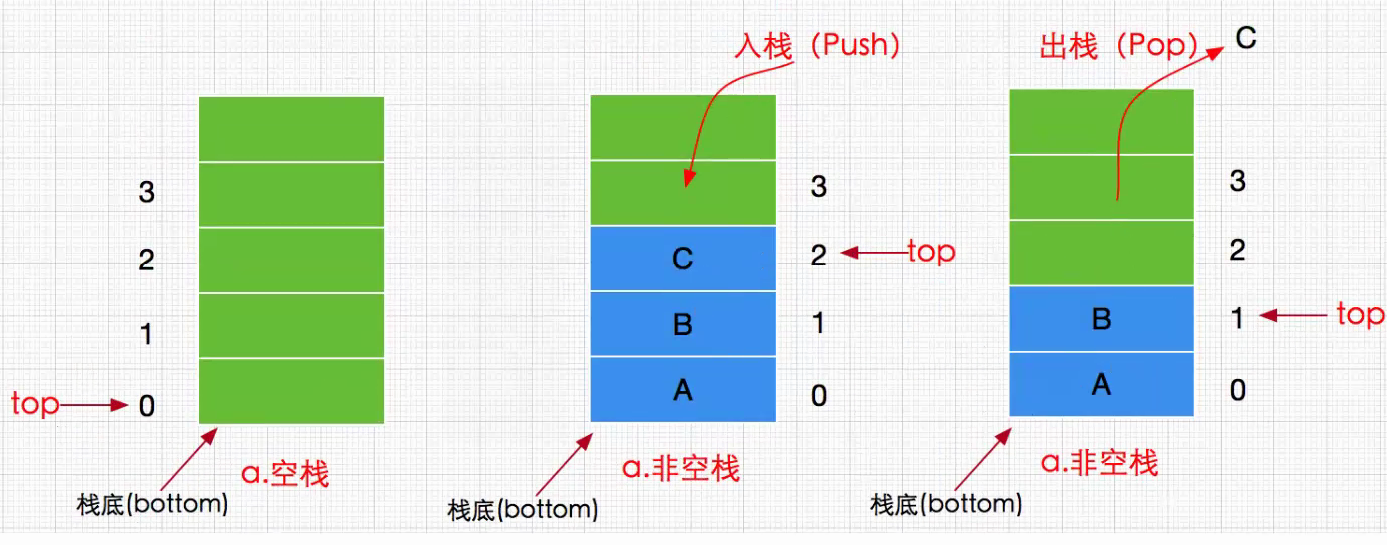
1.1 栈
使用数组实现栈结构
package com.yang1;
public class Test01 {
public static void main(String[] args) {
ArrayStack as = new ArrayStack();
as.push(20);
as.push(29);
as.push(-20);
System.out.println(as.pop()); // -20
}
}
/*
*
* 数组实现的栈结构
*
* 如果需要一个支持动态扩容的顺序栈,则底层还需要以来一个支持动态扩容的数组,
*
* 将原来的数据搬移到新数组中。也可以使用顺序栈支持动态扩容。
*/
class ArrayStack {
private Object[] items; // 栈中存放的数据
private int size; // 栈中存放数据的个数
public ArrayStack() {
this(10);
}
public ArrayStack(int capacity) {
items = new Object[capacity];
}
// 数据亚展--将数据存储在栈顶
public boolean push(Object item) {
// 如果已经满了则不允许再添加数据
if (size == items.length) {
return false;
}
items[size++] = item;
return true;
}
// 数据弹栈--将数据栈栈顶的数据获取出来,同时删除栈顶数据
public Object pop() {
//
if (size == 0)
return null;
return items[--size];
}
}
系统预定义的实现Stack
public class Stack<E> extends Vector<E>可以看到这个类继承于Vector,所以他线程安全,而且也间接的实现了List接口。
- E push(E item) :把项压入堆栈顶部
- synchronized E pop() :移除堆栈顶部的对象,并作为此函数的值返回该对象
- synchronized E peek():查看堆栈顶部的对象,但不从堆栈中移除它
- boolean empty() :测试堆栈是否为空
package com.yang1;
import java.util.Stack;
public class Test02 {
public static void main(String[] args) {
Stack<String> ss = new Stack<>();
System.out.println(ss.empty()); // true
ss.push("first");
System.out.println(ss.empty()); // false
for (int i = 0; i < 5; i++) {
ss.push(i + "");
}
System.out.println(ss); // [first, 0, 1, 2, 3, 4]
System.out.println(ss.pop()); // 4
System.out.println(ss); // [first, 0, 1, 2, 3]
System.out.println(ss.peek()); // 3
System.out.println(ss); // [first, 0, 1, 2, 3]
System.out.println(ss.search("3")); // 1
System.out.println(ss.search("first")); // 5
}
}
class A<T> {
void pp() {
Integer o = 20;
Object o1 = o;
T t = (T) o1;
System.out.println(t);
}
}
1.2 编码:总结自定义栈
总结自定义栈–在线考试题–放水题
栈是一种用于存储数据的简单数据结构,栈与线性表的最大区别是数据的存取的操作。
可以这样认为栈Stack是一种特殊的线性表,其插入和删除操作只允许在线性表的一端进行。
把允许操作的一端称为栈顶Top,不可操作的一端称为栈底Bottom。
同时把插入元素的操作称为入栈Push,删除元素的操作称为出栈Pop。
若栈中没有任何元素,则称为空栈。
栈的实现可以有数组实现的顺序栈和链表实现的链式栈。
要自定义搞的时候,第一件事要写接口,有时间写抽象类,实现公共程序,没有就直接写实现类
顺序栈
package com.yang1;
import java.io.Serializable;
public class Test03 {
}
// 先定义接口
interface Stack<T> {
// 栈是否为空
boolean empty();
// data元素入栈
void push(T data);
// 返回栈顶元素,未出栈
T peek();
// 出栈,返回栈顶元素,同时从栈中移除该元素
T pop();
}
/*
* 顺序栈,顾名思义就是采用顺序表实现的的栈,顺序栈的内部以顺序表为基础,实现对元素的存取操作,
* 当然还可以采用内部数组实现顺序栈,这里使用内部数据组来实现栈
*/
class SeqStack<T> implements Stack<T>, Serializable {
// 栈顶指针,-1代表空栈
private int top = -1;
// 容量大小默认为10
private int capacity = 10;
// 存放元素的数组
private T[] array;
private int size;
public SeqStack() {
array = (T[]) new Object[capacity];
}
// 一般情况下应该方法名称为getSize,但是遵循一般的使用习惯,所以命名为size()
public int size() {
return size;
}
@Override
public boolean empty() {
return this.top == -1;
}
// 添加元素,从栈顶(数组尾部)插入
public void push(T data) {
// 判断容量是否充足
if (size == array.length)
ensureCapacity(size * 2 + 1);// 扩容
// 从栈顶添加元素
array[++top] = data;
size++;
}
private synchronized void ensureCapacity(int len) {
Object[] res = new Object[len];
System.arraycopy(array, 0, res, 0, this.size);
this.array = (T[]) res;
}
// 获取栈顶元素的值,不删除
public T peek() {
if (empty())
throw new EmptyStackException();
return array[top];
}
// 从栈顶(顺序表尾部)删除
public T pop() {
if (empty())
throw new EmptyStackException();
size--;
return array[top--];
}
}
class EmptyStackException extends RuntimeException {
private static final long serialVersionUID = -4870633979582008865L;
public EmptyStackException() {
super("栈中没有数据");
}
public EmptyStackException(String message, Throwable cause, boolean enableSuppression, boolean writableStackTrace) {
super(message, cause, enableSuppression, writableStackTrace);
}
public EmptyStackException(String message, Throwable cause) {
super(message, cause);
}
public EmptyStackException(String message) {
super(message);
}
public EmptyStackException(Throwable cause) {
super(cause);
}
}
2. 队列
线性表:先进先出,后进后出
一般来说他只允许在表的前端进行删除操作,而在表的后端进行插入操作
Java的某些队列运行在任何地方插入删除,比如常用LinkedList集合,它实现了Queue接口,可以说LinkedList就是一个队列
和栈一样,队列是一种操作受限制的线性表。头指针负责读取数据,尾指针负责插入数据。
根据实现方式不同分为顺序队列和链式队列
2.1 自定义循环队列 顺序队列
一个数组
两个指针:头指针、尾指针。
- 头指针:负责记录即将取出数据的操作定位
- 尾指针:负责记录已经插入数据的操作定位
思想:
- 数组长度固定
- 取出一个数据头指针后移,插入一个数据尾指针后移。
- 插入或取出数据时指向了末尾时会循环回来在从头开始进行记录。
- 头尾指针重合后允许插入数据
存在一个没有存储的空值:
队列的状态:空队可存不可取,满队可取不可存。
这里必须要有这个空的缝隙存在,由于两个指针重合时已经被标示为没有数据了,必须要有一个标志,再来标识一下满队,所以就是在插入的时候判定下一个是否为头指针,标识一下满队。
解决上面的存在一个空值的情况可以在指针重合时判定存储的数据是否为null来分别标识空队和满队。但是我如果存储的就是一个null呢?这又该咋办。
package com.yang1;
public class Test04 {
public static void main(String[] args) {
SpinQueue sq = new SpinQueue();
for (int i = 1; i < 11; i++) {
System.out.println("第" + i + "次添加" + (sq.add(i) ? "成功" : "失败"));
}
for (int i = 1; i < 11; i++) {
Object obj = sq.takeOut();
System.out.println("第" + i + "次取出" + (obj != null ? "成功" : "失败") + " 数据为" + obj);
}
}
}
class SpinQueue {
private Object[] items;
private int head = 0;
private int tail = 0;
public SpinQueue() {
this(10);
}
public SpinQueue(int length) {
if (length <= 0) {
length = 10;
}
items = new Object[length];
}
public boolean add(Object item) {
// tail的next是head则不能插入数据
if ((tail + 1) % 10 == head) {
return false;
}
// 插入数据
items[tail] = item;
// 尾指针后移
tail = (tail + 1) % 10;
return true;
}
public Object takeOut() {
Object res = null;
if (head != tail) { // 两个指针指向同一位置时容器中没有数据
res = items[head];
head = (head + 1) % 10;
}
return res;
}
}
第1次添加成功;
第2次添加成功;
第3次添加成功;
第4次添加成功;
第5次添加成功;
第6次添加成功;
第7次添加成功;
第8次添加成功;
第9次添加成功;
第10次添加失败;
第1次取出成功 数据为1;
第2次取出成功 数据为2;
第3次取出成功 数据为3;
第4次取出成功 数据为4;
第5次取出成功 数据为5;
第6次取出成功 数据为6;
第7次取出成功 数据为7;
第8次取出成功 数据为8;
第9次取出成功 数据为9;
第10次取出失败 数据为null;
2.2 Queue接口
public interface Queue<E> extends Collection<E> {
boolean add(E e); // 在队尾添加数据
boolean offer(E e); // 在LinkedList中就是使用add提供的实现
E remove(); // 删除队列头部的数据,同时返回删除的数据
E poll();
E element(); // 获取队列头部的数据,并不会执行删除操作
E peek();
}
队列主要分为阻塞和非阻塞,有界和无界、单向链表和双向链表之分;
-
阻塞队列
-
满队时插入数据阻塞
-
空队时取出数据阻塞
-
-
非阻塞队列
- 不管出列还是入列,都不会进行阻塞,
- 入列时,如果元素数量超过队列总数,则会抛出异常,
- 出列时,如果队列为空,则取出空值;
- 一般情况下,非阻塞式队列使用的比较少,一般都用阻塞式的对象比较多;
- 阻塞和非阻塞队列在使用上的最大区别就是阻塞队列提供了以下2个方法:
出队阻塞方法 : take()
入队阻塞方法 : put()
- 有界和无界
- 有界:及长度受限,并不会随元素数量有改变
- 无界:向ArrayList一样自己会根据存储数量来扩容
阻塞队列的好处是可以防止队列容器溢出;
只要满了就会进行阻塞等待;
也就不存在溢出的情况;
只要是阻塞队列,都是线程安全的;
2.3 双向队列接口Deque
public interface Deque<E> extends Queue<E> {
void addFirst(E e); // 在队列头部添加数据
boolean offerFirst(E e);
void addLast(E e); // 在队尾添加数据
boolean offerLast(E e);
E removeFirst(); // 从对头中删除数据,同时返回删除的数据
E pollFirst();
E removeLast(); // 从队尾伤处数据
E pollLast();
E getFirst(); // 从对头获取数据
E peekFirst();
E getLast(); // 从队尾获取数据
E peekLast();
}
2.4 队列实现类
非阻塞队列
-
ConcurrentLinkedQueue:
-
单向链表
-
无界
-
并发,由CAS实现现成安全
-
并发访问不需要同步。 因为它在队列的尾部添加元素并从头部删除它们,所以只要不需要知道队列的大小,ConcurrentLinkedQueue对公共集合的共享访问就可以工作得很好。 收集关于队列大小的信息会很慢,需要遍历队列。
-
-
ConcurrentLinkedDeque
- 双向链表结构
- 无界
- 并发,由CAS实现线程安全
-
PriorityQueue
-
内部基于数组实现
-
线程不安全
-
PriorityQueue 类实质上维护了一个有序列表。 加入到Queue中的元素根据它们的天然排序 (通过其java.util.Comparable实现)或者根据传递给构造函数的java.util.Comparator实现来定位。
-
阻塞队列
实现阻塞接口的: java.util.concurrent中加入了 BlockingQueue ,它实质上就是一种带有一点扭曲的FIFO数据结构。不是立即从队列中添加或者删除元素,线程执行操作阻塞,直到有空间或者元素可用。
| 方法名 | 功能 | 特点 |
|---|---|---|
| add | 增加一个元索 | 队满抛出一个IllegalStateException异常 |
| offer | 添加一个元素并返回true | 队满,返回false |
| remove | 移除并返问队列头部的元素 | 队空,返回null |
| poll | 返回队列头部的元素 | 队空抛出一个NoSuchElementException异常 |
| element | 返回队列头部的元素 | 队空,返回null |
| peek | 添加一个元素 | 队满阻塞 |
| take | 移除并返回队列头部的元素 | 队空阻塞 |
阻塞队列的操作可以根据它们的响应方式分为以下三类:
add、removee和element操作在你试图为一个已满的队列增加元素或从空队列取得元素时抛出异常。
在多线程程序中,队列在任何时间都可能变成满的或空的,所以你可能想使用offer、poll、peek方法。这些方法在无法完成任务时 只是给出一个出错示而不会抛出异常。
注意:poll和peek方法出错进返回null。因此,向队列中插入null值是不合法的
-
DelayQueue:一个由优先级堆支持的、基于时间的调度队列。
-
基于PriorityQueue存储
-
支持延时获取元素
-
此队列不允许使用 null 元素。
-
无界
-
是一个存放 Delayed 元素的无界阻塞队列,只有在延迟期满时才能从中提取元素。 该队列的头部是延迟期满后保存时间最长的 Delayed 元素。 如果延迟都还没有期满,则队列没有头部,并且poll将返回null。 当一个元素的 getDelay(TimeUnit.NANOSECONDS) 方法返回一个小于或等于零的值时,则出现期满,poll就以移除这个元素了。
-
-
LinkedTransferQueue
- 基于单项链表进行存储
- 无界
-
ArrayBlockingQueue:一个由数组支持的有界队列。
-
底层存储使用数组
-
有界:初始化时必须指定队列大小,且不可改变;
-
ArrayBlockingQueue在构造时需要指定容量, 并可以选择是否需要公平性,如果公平参数被设置true,等待时间最长的线程会优先得到处理。 (其实就是通过将ReentrantLock设置为true来 达到这种公平性的:即等待时间最长的线程会先操作)。 通常,公平性会使你在性能上付出代价,只有在的确非常需要的时候再使用它。 但是它是基于数组的阻塞 循环队列 ,此队列按 FIFO(先进先出)原则对元素进行排序。
-
-
SynchronousQueue:一个利用 BlockingQueue 接口的简单聚集(rendezvous)机制。
-
有界:最多只能存储一个元素
-
这个队列一看就线程安全,就是之前的那个栅栏同步队列 每一个put操作必须等待一个take操作,否则不能继续添加元素
-
-
PriorityBlockingQueue:一个由优先级堆支持的无界优先级队列。
-
无界
-
一个带优先级的队列,而不是先进先出队列。元素按优先级顺序被移除
-
存储为数组
-
元素按优先级顺序被移除,该队列也没有上限( 看了一下源码,PriorityBlockingQueue是对 PriorityQueue的再次包装,是基于堆数据结构的,而PriorityQueue是没有容量限制的,与ArrayList一样,所以在优先阻塞队列上put时是不会受阻的。虽然此队列逻辑上是无界的,但是由于资源被耗尽,所以试图执行添加操作可能会导致 OutOfMemoryError ),但是如果队列为空,那么取元素的操作take就会阻塞,所以它的检索操作take是受阻的。 另外,往入该队列中的元素要具有比较能力实现了java.util.Comparator;接口,或者在创建PriorityBlockingQueue对象时传入一个Comparator比较器。
-
-
LinkedBlockingQueue :一个由链接节点支持的可选有界队列。
SynchronousQueue
实现生产者消费者模式
下边输出比较混乱的原因是由于他只保证了队列的存取操作的原子性,但是其他的提示符的输出依然是非原子的。
package com.yang2;
import java.util.concurrent.SynchronousQueue;
public class Test02 {
public static void main(String[] args) {
SynchronousQueue<Integer> sq = new SynchronousQueue<>();
for (int i = 0; i < 5; i++) {
int k = i;
new Thread(() -> {
// System.out.println(Thread.currentThread() + "开始生产");
try {
sq.put(k);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread() + "生产完毕");
}, "生产者" + i).start();
new Thread(() -> {
// System.out.println(Thread.currentThread() + "开始消费");
try {
System.out.println(sq.take());
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread() + "消费完毕");
}, "消费者" + i).start();
}
}
}
/*
Thread[生产者1,5,main]生产完毕
Thread[生产者2,5,main]生产完毕
2
Thread[消费者2,5,main]消费完毕
1
Thread[生产者0,5,main]生产完毕
Thread[消费者0,5,main]消费完毕
0
Thread[生产者3,5,main]生产完毕
4
Thread[生产者4,5,main]生产完毕
3
Thread[消费者3,5,main]消费完毕
Thread[消费者1,5,main]消费完毕
Thread[消费者4,5,main]消费完毕
*/
3. Set 接口
-
无序,元素不可重复,可以存在null
-
Set接口中没有新的特殊方法,全部都是继承于Collection的;
-
只对 add()、equals() 和 hashCode() 方法添加了限制不允许重复
规则:
先判断两个元素对象的hashCode值是否相等,如果相等再调用equals进行等值判断,如果相等则丢弃
如果两个元素对象的hashCode值不相等,则不会调用equals方法,直接进行添加
3.1 问:三个集合类型的区别(未完整)
HashSet、LinkedHashSet、TreeSet
特点
HashSet
- 底层数据存储使用的是HashMap,仅适用键值对中的键来进行存储
LinkedHashSet
- 继承于HashSet,在HashSet的基础上给每个存储的元素额外添加了一个链表用于记录添加元素的顺序
区别
HashSet是内置的Set接口实现类
LinkedHashSet继承于HashSet,存储使用的是HashSet,在HashSet的基础上为每一个存储的元素额外添加一个链表,用于记录添加元素的的顺序。
LinkedHashSet存储的数据之间存在顺序。
3.2 三个集合的底层实现(话术整理)
HashSet
声明
public class HashSet<E>
extends AbstractSet<E> // 抽象类中定义了所有的公共方法
implements Set<E>, //
Cloneable, // 克隆
java.io.Serializable // 序列化
{}
属性
private transient HashMap<E,Object> map; // 存储数据使用 哈希表结构,存储数据使用的是key和value,HashSet只使用了key部分
private static final Object PRESENT = new Object(); // 哈希表中的所有的value值
构造器
// 当元素多的时候,出现哈希冲突的情况就加大了,就需要将索引数组进行扩容,重新计算每个链子上的节点的归属
// 最大存储容积 = 容器*负载因子,如果太大了就去扩容
public HashSet(
int initialCapacity, // 初始化容积
float loadFactor // 负载因子 0~1 默认0.75
) {
map = new HashMap<>(initialCapacity, loadFactor);
}
///
// 负载因子=0.75
public HashSet(int initialCapacity) {
map = new HashMap<>(initialCapacity);
}
添加
// 把值存储到 哈希表的 键 上
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
删除
public boolean remove(Object o) {
return map.remove(o)==PRESENT;
}
LinkedHashSet
声明
public class LinkedHashSet<E>
extends HashSet<E> // 实现依赖于HashSet
implements Set<E>, Cloneable, java.io.Serializable
属性
// 没有属性
构造器
public LinkedHashSet(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor, true);
}
// 这个创建
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
map = new LinkedHashMap<>(initialCapacity, loadFactor);
}
TreeSet(待补充)
3.4 哈希算法
通过哈希(散列)算法。
这就是把任意长度的输入通过散列算法,变换成固定长度的(有损加密、有损压缩)。
md5
消息摘要算法md5。
-
无法反解密
-
输出密文24位
**碰撞算法:**是碰运气,硬算
MessageDigest md=MessageDigest.getInstance("md5");
String pwd="123456";
byte[] bb=md.digest(pwd.getBytes());
String ss=Base64.getEncoder().encodeToString(bb);
System.out.println(ss);
哈希冲突
当两个不同的输入值,根据同一散列函数计算出相同的散列值的现象,就把它叫做碰撞(哈希碰撞)。
这种情况我们可以在计算哈希值的时候加点盐(扰动信息),可以降低哈希冲突的概率。
HashMap
以key/value的方式存储数据,采用拉链法综合了数组和链表结构。如果key已知则存取效率较高,但是删除慢,如果不知道key存取则慢,对存储空间使用不充分。
最典型的实现是HashMap。
哈希表是由一个数组(哈希值)和一个个单向链表组成的。当这个链表过于长的时候,或者说总体容积过多时会导致索引效率低下。这时需要做的就是数组扩容,将原本挂载在一个链表上的数据分裂到不同的索引下进行维护。
扩展小芝士
- 哈希表(链地址法 拉链法)
nkedHashMap<>(initialCapacity, loadFactor);
}
#### TreeSet(待补充)
~~~java
3.4 哈希算法
通过哈希(散列)算法。
这就是把任意长度的输入通过散列算法,变换成固定长度的(有损加密、有损压缩)。
md5
消息摘要算法md5。
-
无法反解密
-
输出密文24位
**碰撞算法:**是碰运气,硬算
MessageDigest md=MessageDigest.getInstance("md5");
String pwd="123456";
byte[] bb=md.digest(pwd.getBytes());
String ss=Base64.getEncoder().encodeToString(bb);
System.out.println(ss);
哈希冲突
当两个不同的输入值,根据同一散列函数计算出相同的散列值的现象,就把它叫做碰撞(哈希碰撞)。
这种情况我们可以在计算哈希值的时候加点盐(扰动信息),可以降低哈希冲突的概率。
HashMap
以key/value的方式存储数据,采用拉链法综合了数组和链表结构。如果key已知则存取效率较高,但是删除慢,如果不知道key存取则慢,对存储空间使用不充分。
最典型的实现是HashMap。
哈希表是由一个数组(哈希值)和一个个单向链表组成的。当这个链表过于长的时候,或者说总体容积过多时会导致索引效率低下。这时需要做的就是数组扩容,将原本挂载在一个链表上的数据分裂到不同的索引下进行维护。
扩展小芝士
- 哈希表(链地址法 拉链法)















 3893
3893











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









