







来源:
Yue, Z., Wang, Y., Duan, J., Yang, T., Huang, C., Tong, Y., & Xu, B. (2022). TS2Vec: Towards Universal Representation of Time Series. Proceedings of the AAAI Conference on Artificial Intelligence, 36(8), 8980-8987. https://doi.org/10.1609/aaai.v36i8.20881
摘要:
本文提出了TS2Vec,一个在任意语义层学习时间序列表示的通用框架。与现有方法不同,TS2Vec在增强的上下文视图上以分层方式执行对比学习,这使得每个时间戳都具有鲁棒的上下文表示。此外,为了获得时间序列中任意子序列的表示,我们可以对相应时间戳的表示应用简单的聚合。我们对时间序列分类任务进行了广泛的实验,以评估时间序列表示的质量。因此,TS2Vec在125个UCR数据集和29个UEA数据集上实现了对现有无监督时间序列表示的SOTA的显著改进。学习的时间戳级表示在时间序列预测和异常检测任务中也实现了优异的结果。在学习表示的基础上训练的线性回归优于时间序列预测的先前SOTA。此外,我们提出了一种简单的方法来将学习的表示应用于无监督异常检测,这在文献中建立了SOTA结果。源代码可在https://github.com/yuezhihan/ts2vec上公开获取。
创新点:
当前问题:
1)实例级表示可能不适用于需要细粒度表示的任务;
2)现有的方法很少区分具有不同粒度的多尺度上下文信息;
3)大多数现有的无监督时间序列表示方法都受到CV和NLP领域经验的启发,并不总是适用于时间序列建模。
通用的对比学习框架,称为TS2Vec,该框架支持时间序列在所有语义层的表示学习。它在实例和时间维度上分层区分正样本和负样本;对于任意子序列,其整体表示可以通过在相应时间戳上的最大池来获得。这使得模型能够以多分辨率捕获时间数据的上下文信息,并生成任意粒度的细粒度表示。此外,TS2Vec中的对比目标基于增强上下文视图,即两个增强上下文中相同子序列的表示应一致通过这种方式,我们获得了每个子序列的鲁棒上下文表示,而不会引入未被认可的归纳偏差,如变换和裁剪不变性。
本文的主要贡献总结如下:
•我们提出了TS2Vec,这是一个统一的框架,可以在不同语义级别学习任意子系列的上下文表示。据我们所知,这是首次为时间序列域中的各种任务提供灵活和通用的表示方法,包括但不限于时间序列分类、预测和异常检测。
•为了实现上述目标,我们在压缩学习框架中利用了两种新颖的设计。首先,我们在实例和时间维度上使用分层对比方法来捕获多尺度上下文信息。第二,我们提出了积极配对选择的上下文一致性。与以往的技术不同,它更适合于具有不同分布和尺度的时间序列数据。广泛的分析证明了TS2V ec对缺失值时间序列的稳健性,消融研究验证了分层对比和上下文一致性的有效性。
•TS2Vec在三个基准时间序列任务(包括分类、预测和异常检测)上优于现有SOTA。例如,与分类任务无监督表示的最佳SOTA相比,我们的方法在125个UCR数据集上平均提高了2.4%,在29个UEA数据集上提高了3.0%。
模型:
给定N个实例的一组时间序列X={x1,x2,··,xN},目标是学习非线性嵌入函数fθ,该函数将每个xi映射到其最能描述自身的表示ri。
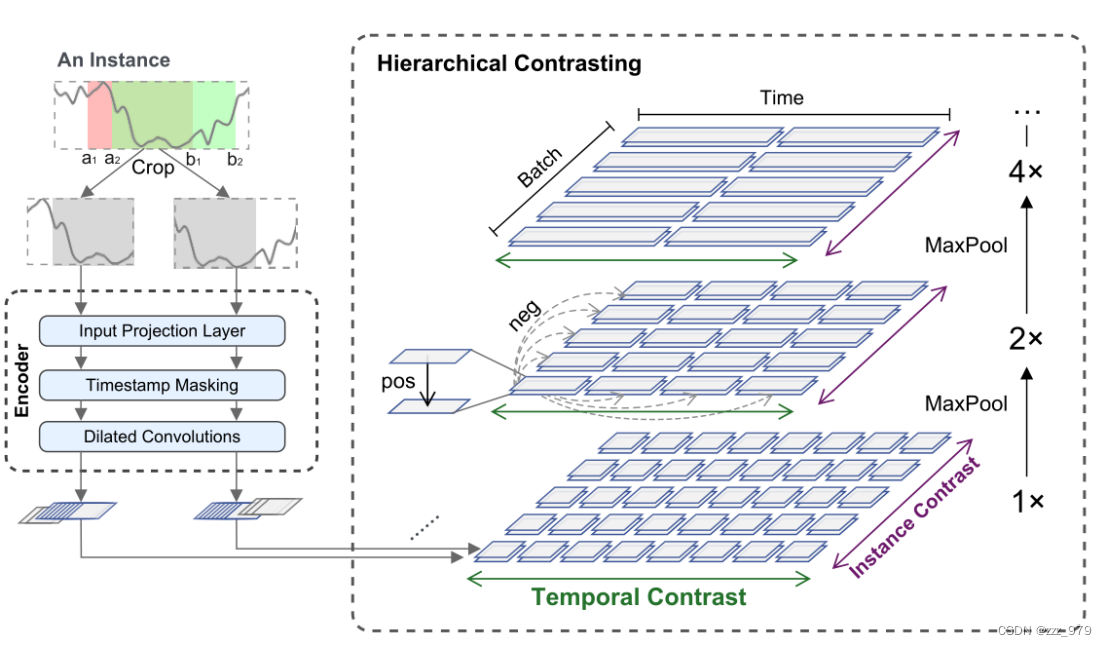
模型框架如图。对于xi,随机选取它的两个子序列(有重叠部分)。期望对于重叠部分获得一致的上下文表达。原始数据被投入编码器,编码器通过两方面进行优化:时间对比损失(temporal contrastive loss ),实例对比损失(instance-wise contrastive loss)。在当前的分层框架里,总损失是多种尺度损失之和。
编码器包含三部分:输入工程层(input projection layer)、时间戳掩码层(timestamp masking module)、扩张卷积层( dilated CNN module)。
输入工程层把各个xit(F维向量)映射到更高维度的zit(称作“潜在向量”)。
时间戳掩码层随机选择时间戳,对上一步得到的潜在向量zi进行掩码,目的是获得增强上下文视图。对潜在向量进行掩码,而不是直接对输入进行掩码,是因为时间序列的值的取值范围未必有界,而且不可能对于原始数据找到一个特殊的token。
扩张卷积层的目的是对于每个时间戳得到上下文表达。每个残差块拥有两个卷积层,并带有一个扩张参数(第l个块是2^l)。这种结构导致了不同层级拥有不同的感受野。
对比学习中的正样本对(positive pairs)的建立至关重要。
过去的论文采取了以下策略:
1.Subseries consistency:通过相同时间戳的不同时间序列生成正样本,一个时间序列的表达应当与它被选取出来的子序列尽量近
2.Temporal consistency:通过时间邻近的方式生成正样本,来增强表示的局部平滑性
3.Transformation consistency :通过数据增强的方式生成正样本,期望模型能够学到变幻不变性的表达。
上述策略是基于对数据分布的比较强的假设作出的,可能不适应时间序列。
亮点:
1)上下文不变性(contextual consistency):
把同一个时间戳在两个不同的增强上下文中的表达作为正样本对。通过对原始数据进行时间戳掩码(是先全连接,后掩码)和随机剪裁,就能得到一个上下文。
时间戳掩码
对一个实例的时间戳进行随机掩码,得到新的上下文视图。具体的来说,是对输入工程层(input projection layer)输出的向量zi = {zit}沿着时间轴进行掩码,过程中会用到二元掩码向量m ∈ {0, 1}T 。 掩码位置的选取是独立的,服从p=0.5的伯努利分布。在编码器的每个前向传播中,掩码都是随机选择的。
随机剪裁
对于每个T×F的xi,要随机从上面选取两个部分重叠的部分[a1,b1] , [a2,b2] 。对于两个上下文视图,重叠部分的上下文表达应当是一致的。
**时间戳掩码和随机剪裁只在训练阶段发生。**掩码和剪裁没有改变时间序列的量级( magnitude);强制让每个时间戳在不同的上下文中重建自身,这提高了学习到的特征的鲁棒性。
2)层次对比损失函数
为了让encoder更好的学习到时间序列在不同粒度下的表征,这里提出了一个新的对比损失函数。其计算步骤如下图所示:基于timestamp-level的表征,在时间粒度以及instance维度通过max pooling的方法迭代计算出instance-level 的表征
时间对比损失(Temporal Contrastive Loss)
为了学到随时间变化的不同表达,本模型把相同时间戳不同视图得到的表达作为正样本对,把不同时间戳对应的表达作为负样本对。
i是时间序列样本的下标,t是时间戳。ri,t 和r’it分别表示相同时间戳不同视图得到的表达(时间戳为t)。则第i个时间序列在时间戳t处的损失为
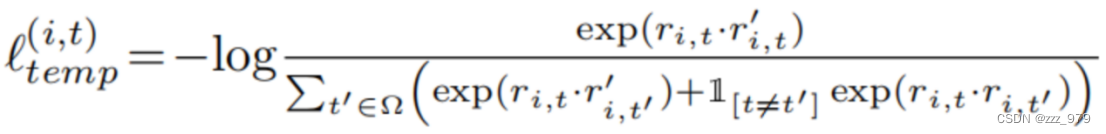
逐实例对比损失(Instance-wise Contrastive Loss)
B表示batch大小。把同一个batch里的其他时间序列在t时刻的表达作为负样本。

上面两种对损失的计算是互补的,所以总损失定义为:
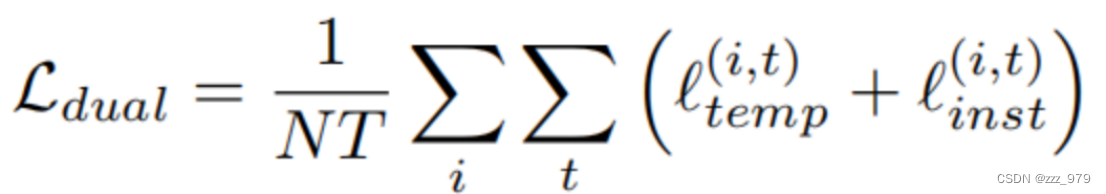
实验:
时序分类(Time Series Classifification)
每个实例对应一个标签。因此需要实例层级的表达,这可以通过对所有时间戳进行最大值池化得到。
流程:把一个时间序列采用不同的方式进行特征表达,然后用某种模型进行分类。发现用TS2Vec进行特征表达时,结果最好,且TS2Vec训练时间也更短。















 874
874











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









