








论文地址:https://arxiv.org/pdf/2302.14390v1.pdf
代码地址:https://github.com/IkeYang/machine-vision-assisted-deep-time-series-analysis-MV-DTSA-
摘要
时间序列预测(TSF)一直是一个具有挑战性的研究领域,已经开发了各种模型来解决这一任务。然而,几乎所有这些模型都是用数值时间序列数据训练的,神经系统对这些数据的处理不如视觉信息有效。为了解决这一挑战,本文提出了一种新的机器视觉辅助深度时间序列分析(MV-DTSA)框架。MV-DTSA(machine vision assisted deep time series analysis)框架通过分析二进制机器视觉时间序列度量空间中的时间序列数据来运行,该框架包括从数值时间序列空间到二进制机器视觉空间的映射和逆映射函数,以及用于解决二进制空间中的TSF任务的深度机器视觉模型。综合计算分析表明,所提出的MV-DTSA框架优于最先进的深度TSF模型,无需复杂的数据分解或模型定制。
创新点
-
利用可视化模式,首次提出了时间序列分析的颠覆性框架MV-DTSA。
-
在MV-DTSA的基础上,设计了一种新的MV-DTSF模型,用于TSF任务。
-
提出的MV-DTSF框架无需复杂的数据分解和模型定制就能轻松获得优异的预测性能,这表明该框架在时间序列分析领域具有巨大的未开发潜力。
目前用于时间序列预测的模型主要有以下特点:
- 几乎只使用数值时间序列值作为输入。
- 经常采用复杂的数据预处理和分解技术来提高预测性能。
- 非常强调通过精心设计架构和损失函数来设计模型,以提高TSF任务的准确性和性能。
在本研究中,引入了一种破坏性方法,通过在二进制机器视觉时间序列度量空间中进行时间序列分析,而不是直接使用数值时间序列数据。结果表明,MV-DTSF模型不依赖复杂的数据分解技术,也不重视模型的设计,就能实现SOTA性能。
模型框架
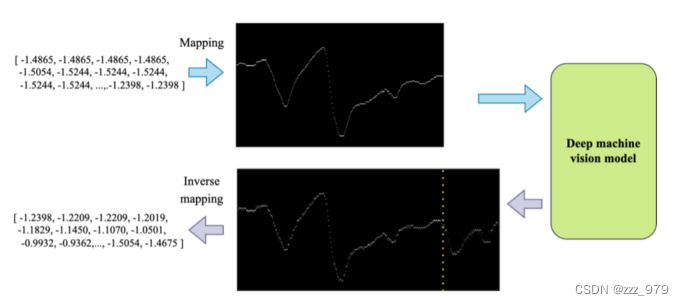
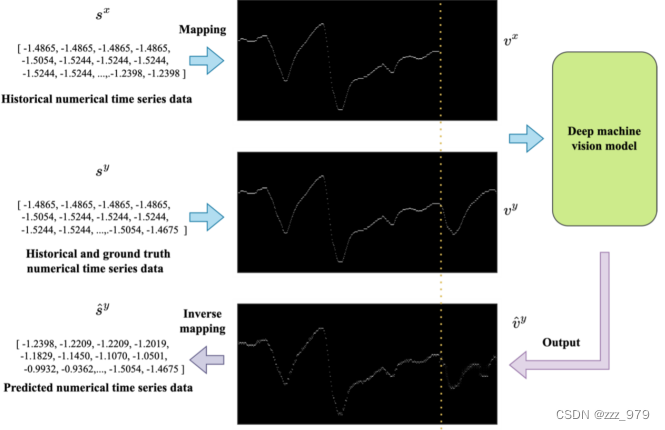
MV-DTSA的总体框架,包括三个基本步骤:
- 首先,将来自真实空间S的数值时间序列数据映射到所提出的二进制机器视觉时间序列度量空间v中。将原始一维数值时间序列映射到二维二元张量后,只保留了相对趋势关系。
- 其次,根据具体任务的要求选择深度机器视觉模型,并使用映射到v上的训练对进行训练。
- 最后,在必要时进行逆映射,将深度模型的输出转换回真实空间进行进一步分析。
数据映射

!!该部分为本文重点(图比公式好理解)
理论公式
定义1:二进制机器视觉时间序列度量空间。二进制机器视觉时间序列度量空间定义为一组(V, d),其中V是(1)中定义的元素集,d是(2)中定义的地球移动器距离的变体。其中c表示变量的数量,t表示时间序列的长度,h表示分辨率。

数值时间序列S = {S∈Rc×t|si,k∈R}到V的映射函数f(∗)和对应的逆映射函数f−1(∗),分别如式(3)和(4)所示。MS > 0表示最大尺度超参数。通常,在映射前,实空间S中的数值时间序列会进行零分归一化。映射到二进制机器视觉时间序列度量空间V后,只保留了原始时间序列的时空趋势。在映射后,原始时间序列转换为单通道二值图像。同时,在映射和逆映射过程中明显存在系统测量误差(SME),由定理1将其形式化。
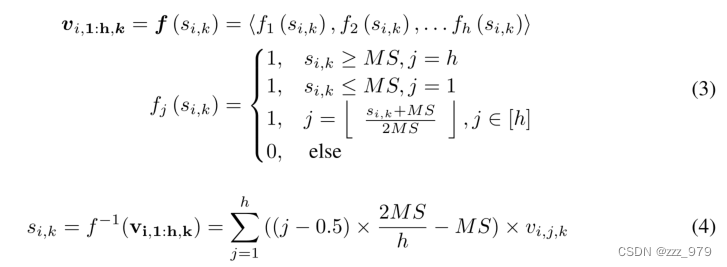
定理1:设bs∈S, SME定义为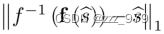 ,那么SME的期望可以被限定为
,那么SME的期望可以被限定为
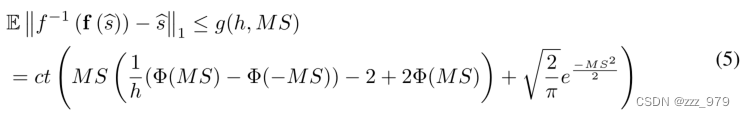
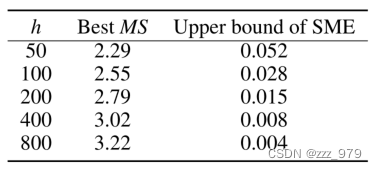
当MS一定时,SME的上界会随着h的增大而减小。如果有足够的GPU内存可用来指定足够大的h,那么在MS足够大的情况下,SME将收敛于0。然而,实际上,大的h值会导致二进制机器视觉时间序列度量空间内更大的张量大小,这可能会导致计算负载的增加。因此,h的选择应谨慎选择,以确保计算的可行性。
重要超参数选择
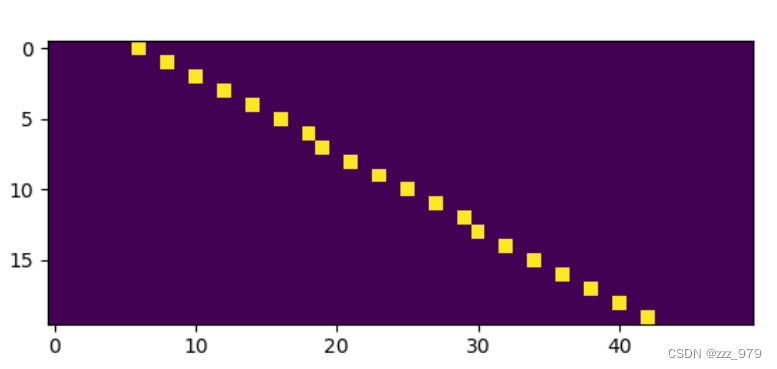
代码实现
时间数据转图像
def data2Pixel(self, dataXIn, dataYIN):
'''
:param dataX: tin,pX dataY: whole,pY
:return: imgX, (w,h,px)*C imgY, w,h,pY
'''
t1 = datetime.datetime.now()
dataX = np.copy(dataXIn.T)
dataY = np.copy(dataYIN.T)
dataX[dataX > self.maxScal] = self.maxScal
dataX[dataX < -self.maxScal] = -self.maxScal
dataY[dataY > self.maxScal] = self.maxScal
dataY[dataY < -self.maxScal] = -self.maxScal
px = dataX.shape[0]
py = dataY.shape[0]
TY = dataY.shape[1]
TX = dataX.shape[1]
imgY0 = np.zeros([py, TY, self.h])
maxstd = self.maxScal
resolution = maxstd * 2 / (self.h - 1)
indY = np.floor((dataY + maxstd) / resolution).astype('int16')
aY = imgY0
aY =aY.reshape(-1, self.h)
aY[np.arange(TY * py), indY.astype('int16').flatten()] = 1
imgY0= aY.reshape(py, TY, self.h)
d= self.D[list(indY), :]
imgX0=np.copy(imgY0)
imgX0[:,TX:,:]=0
return imgX0, imgY0, d##c,w,h d c,w,h
例子:
输入以下一维数据
dataXIn=np.arange(1,21).reshape(1,20)
展示转换后图像
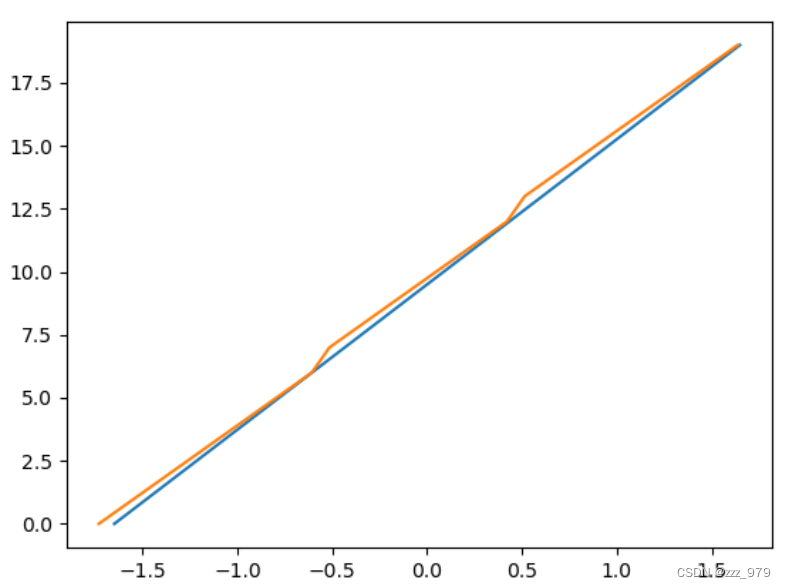
图像转时间数据
def Pixel2data(self, imgX0, method='max'):
if len(imgX0.shape) == 3:
imgX0 = imgX0.unsqueeze(0)
# bs,c,w,h imgX0
bs, ch, w, h = imgX0.shape
# res=np.zeros([bs,w,ch])
try:
imgX0 = imgX0.cpu().detach().numpy()
except:
pass
if method == 'max':
indx = np.argmax(imgX0, axis=-1)
elif method == 'expection':
imgX0 = imgX0 / np.sum(imgX0, axis=-1, keepdims=True)
indNumber = np.arange(0, h)
imgX0 *= indNumber
indx = np.sum(imgX0, axis=-1)
maxstd = self.maxScal
resolution = maxstd * 2 / (self.h - 1)
res = np.transpose(indx, (0, 2, 1)) * resolution - maxstd
return res
例子:
恢复上述二维图像并于原始输入对比
MV-DTSF的整体架构
伪代码
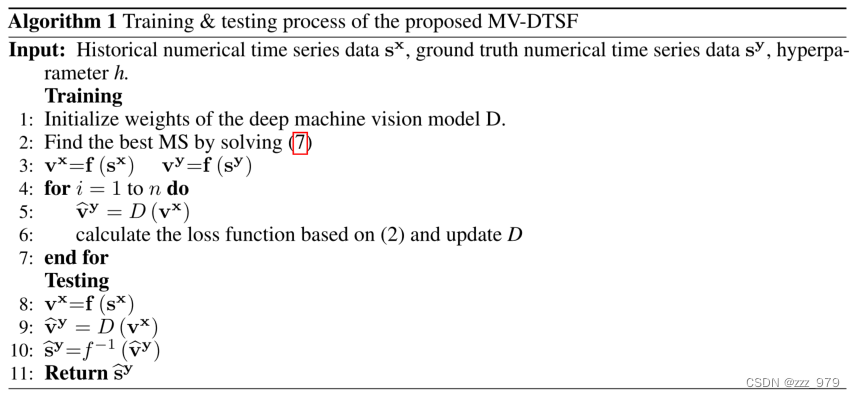
实验
实验设置
- 使用图像处理模型,该框架对模型无要求
- 使用训练集的均值和方差对测试集进行归一化
- 采用通道独立
数据集
- Electricity
- Exchange rate
- Traffic
- Weather
- ILI
- ETTm2
实验结果
选取了5个近期SOTA时间序列预测模型作为基准,分别为Informer、Autoformer、FEDformer、patchTST和DLinear。对于ILI数据集,预测长度T设置为{24,36,48,60},对于所有其他数据集,预测长度T设置为{96,192,336,720}。为了确保公平的比较,我们根据回溯窗口的原始长度和通道无关技术的使用将考虑的基准测试分为三组。分组结果如表所示。此外,在表中提出了四种MV-DTSF方法的变体。例如,MV-DTSF-Unet-96意味着使用U-net作为回退窗口为96的深度机器视觉模型的骨干,MV-DTSF-DeeplabV2-336-CI意味着使用DeeplabV2作为回退窗口为336的深度机器视觉模型的骨干,并采用通道独立技术。为了减轻计算负担,我们在第2组和第3组中只考虑DeeplabV2作为骨干。最后,由于计算资源的限制,将所有MV-DTSF模型的h设为200。
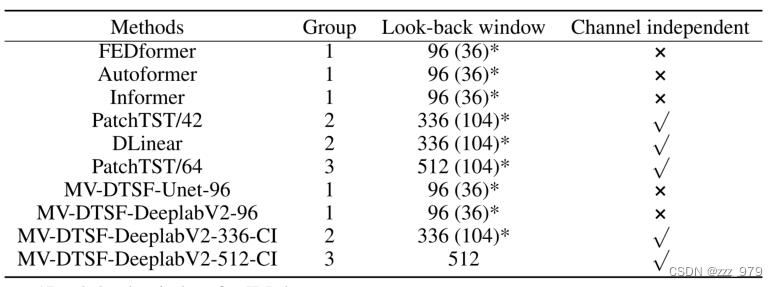
模型性能测试
图显示了MV -DTSF-DeeplabV2-336-CI模型在不同h值下对不同MS在数据集ETTm2上的预测性能。可以观察到,MS的最佳结果与表中报道的理论结果非常吻合。
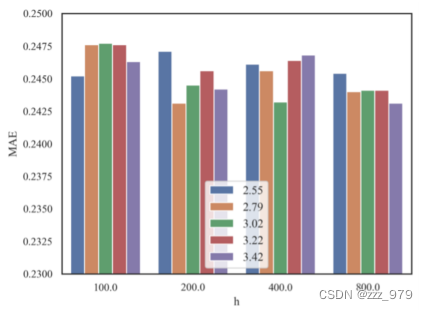
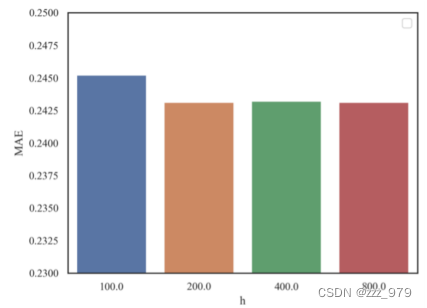
图给出了MV DTSF-DeeplabV2-336-CI在不同h下对数据集ETTm2的预测性能。显然,增加h的值会导致预测误差的减小,这支持了命题1,并进一步证明了所提出的MV-DTSA框架的有效性。
与SOTA比较
第1组所考虑方法的预测性能。最好的结果用粗体标出,次好的结果用下划线标出。

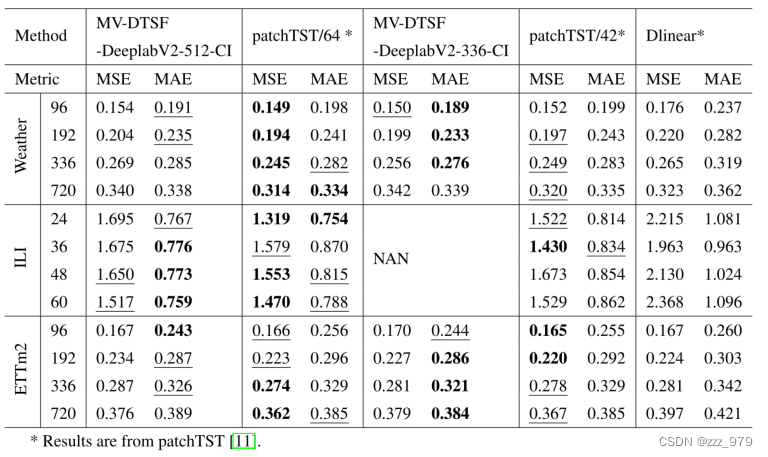
第2组和第3组所考虑方法的预测性能。最好的结果用粗体标出,次好的结果用下划线标出。
总结
-
该方法为,将一维时间序列数据转换为二维图像数据,使用图像中模型对数据进行处理,然后将处理结果转为一维时间序列数据,用于实现时间序列预测任务
-
在训练过程中,对具体模型无,使用了通道独立
-
该方法的重点在于一维时间序列空间与二维二进制图像空间的映射关系















 276
276











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









