







文本情感分析
1 任务目标
1.1 案例简介
情感分析旨在挖掘文本中的主观信息,它是自然语言处理中的经典任务。在本次任务中,我们将在影评文本数据集(Rotten Tomato)上进行情感分析,通过实现课堂讲授的模型方法,深刻体会自然语言处理技术在生活中的应用。
同学们需要实现自己的情感分析器,包括特征提取器(可以选择词袋模型、n-gram模型或词向量模型)、简单的线性分类器以及梯度下降函数。随后在数据集上进行训练和验证。我们提供了代码框架,同学们只需补全model.py中的两个函数。
1.2 数据说明
我们使用来自Rotten Tomato的影评文本数据。其中训练集data_rt.train和测试集data_rt.test均包含了3554条影评,每条影评包含了文本和情感标签。示例如下:
+1 visually , 'santa clause 2' is wondrously creative .
其中,+1 表示这条影评蕴涵了正面感情,后面是影评的具体内容。
1.3 数据特征提取
TODO:补全featureExtractor函数
在这个步骤中,同学们需要读取给定的训练和测试数据集,并提取出文本中的特征,输出特征向量。
同学们可以选择选择词袋模型、n-gram模型或词向量模型中的一种,也可以对比三者的表现有何差异。
1.4 训练分类器
TODO:补全learnPredictor函数
我们提供的训练数据集中,每句话的标签在文本之前,其中+1表示这句话蕴涵了正面感情,-1表示这句话蕴涵了负面感情。因此情感分析问题就成为一个分类问题。
我们采用最小化hinge loss的方法训练分类器,假设我们把每条影评文本
x
x
x映射为对应的特征向量
ϕ
(
x
)
\phi(x)
ϕ(x),hinge loss的定义为
L
(
x
,
y
;
w
)
=
max
(
0
,
1
−
w
⋅
ϕ
(
x
)
y
)
L(x,y; \mathbf{w})=\max(0,1-\mathbf{w}\cdot\phi(x)y)
L(x,y;w)=max(0,1−w⋅ϕ(x)y)
同学们需要实现一个简单的线性分类器,并推导出相应的梯度下降函数。
1.5 实验与结果分析
在训练集上完成训练后,同学们需要在测试集上测试分类器性能。本小节要求同学们画出训练集上的损失函数下降曲线和测试集的最终结果,并对结果进行分析。
1.6 评分要求
同学们需要提交源代码和实验报告。实验报告中应包含两部分内容:
- 对hinge loss反向传播的理论推导,请写出参数的更新公式。
- 对实验结果的分析,请描述采用的模型结构、模型在训练集上的损失函数下降曲线和测试集的最终结果,并对结果进行分析。分析可以从模型的泛化能力、参数对模型性能的影响以及不同特征的影响等方面进行。
2 代码构建
2.1 数据特征提取
-
词袋模型
词袋模型将文本中的每个单词作为一个特征,特征值为该单词在文本中出现的次数。
def extractFeatures_bow(x): features = collections.defaultdict(float) for word in x.split(): features[word] += 1.0 return features -
n-gram模型
n-gram模型考虑了文本中的n个连续单词,将它们作为特征。在本实验中,我们使用了2-gram模型。
def extractFeatures_ngram(x, n=2): features = collections.defaultdict(float) words = x.split() for i in range(len(words) - n + 1): ngram = ' '.join(words[i:i+n]) features[ngram] += 1.0 return features -
词向量模型
本实验词向量模型采用了预训练的 word2vec 模型(FastText Word Embeddings)加载词向量。
# 使用预训练的word2vec模型(FastText Word Embeddings)加载词向量 def loadWord2VecModel(filename): wordVectors = {} with open(filename, 'r', encoding='utf-8') as f: for line in f: values = line.split() word = values[0] vector = np.array(values[1:], dtype='float32') wordVectors[word] = vector return wordVectors wiki_news= './data/wiki-news-300d-1M.vec' wordVectors = loadWord2VecModel(wiki_news)词向量模型使用预训练的词向量(如FastText、Word2Vec)将文本中的单词表示为向量,并将这些向量的平均值作为文本的特征向量。
def extractFeatures_wordvec(x): # 将句子x拆分成单个字符或单词 tokens = x.split() # 句子的词向量表示 vectors = [wordVectors[token] for token in tokens if token in wordVectors.keys()] # 将句子中的每个单词转换为对应的词向量,然后将这些词向量的平均值作为该句子的特征向量 if vectors: # 将句子中的每个单词转换为对应的词向量,然后将这些词向量的平均值作为该句子的特征向量 vectors = np.mean(vectors, axis=0) else: # 处理句子中所有单词都不在模型中的情况 vectors = np.zeros(len(next(iter(wordVectors.values())))) # 将特征向量表示为字典 featureDict = {} for i, value in enumerate(vectors): featureDict[f'feature_{i}'] = value return featureDict
2.2 训练分类器
训练数据集中,每句话的标签在文本之前,其中+1表示这句话蕴涵了正面感情,-1表示这句话蕴涵了负面感情。因此情感分析问题就成为一个分类问题。
在情感分析任务中,我们的目标是学习一个分类器,将文本表示为特征向量,并根据这些特征向量对文本进行分类。我们使用的是最小化hinge loss的方法训练分类器。
-
参数更新公式推导
假设我们的分类器参数为 w \mathbf{w} w,对于给定的训练样本 ( x i , y i ) (x_i, y_i) (xi,yi),其中 x i x_i xi 是文本的特征向量, y i y_i yi 是其对应的情感标签(+1 或 -1)。
我们的目标是最小化hinge loss,即:
L ( x i , y i ; w ) = max ( 0 , 1 − w ⋅ ϕ ( x i ) ⋅ y i ) L(x_i, y_i; \mathbf{w}) = \max(0, 1 - \mathbf{w} \cdot \phi(x_i) \cdot y_i) L(xi,yi;w)=max(0,1−w⋅ϕ(xi)⋅yi)
其中 ϕ ( x i ) \phi(x_i) ϕ(xi) 是文本 x i x_i xi 的特征向量。
我们使用随机梯度下降法来更新参数 w \mathbf{w} w。参数的更新公式可以通过对hinge loss进行梯度下降来得到。梯度的计算需要考虑 hinge loss 在 w ⋅ ϕ ( x i ) ⋅ y i ≤ 1 \mathbf{w} \cdot \phi(x_i) \cdot y_i \leq 1 w⋅ϕ(xi)⋅yi≤1 和 w ⋅ ϕ ( x i ) ⋅ y i > 1 \mathbf{w} \cdot \phi(x_i) \cdot y_i > 1 w⋅ϕ(xi)⋅yi>1 两种情况下的情况:
当 w ⋅ ϕ ( x i ) ⋅ y i ≤ 1 \mathbf{w} \cdot \phi(x_i) \cdot y_i \leq 1 w⋅ϕ(xi)⋅yi≤1 时,梯度为:
∂ L ∂ w = − ϕ ( x i ) ⋅ y i \frac{\partial L}{\partial \mathbf{w}} = - \phi(x_i) \cdot y_i ∂w∂L=−ϕ(xi)⋅yi
当 w ⋅ ϕ ( x i ) ⋅ y i > 1 \mathbf{w} \cdot \phi(x_i) \cdot y_i > 1 w⋅ϕ(xi)⋅yi>1 时,梯度为零。
因此,参数的更新公式为:
$$
\mathbf{w} := \mathbf{w} + \eta \cdot \left{
\begin{array}{ll}- \phi(x_i) \cdot y_i & \text{if } \mathbf{w} \cdot \phi(x_i) \cdot y_i \leq 1 \
0 & \text{otherwise}
\end{array}
\right.
$$
其中 η \eta η 是学习率。
- \phi(x_i) \cdot y_i & \text{if } \mathbf{w} \cdot \phi(x_i) \cdot y_i \leq 1 \
-
代码
代码中同时加入了绘制曲线部分。
def learnPredictor(trainExamples, testExamples, featureExtractor, numIters, eta): ''' 给定训练数据和测试数据,特征提取器|featureExtractor|、训练轮数|numIters|和学习率|eta|, 返回学习后的权重weights 你需要实现随机梯度下降优化权重 ''' weights = collections.defaultdict(float) trainErrors = [] testErrors = [] trainLosses = [] testLosses = [] for i in range(numIters): totalTrainLoss = 0 totalTestLoss = 0 for x, y in trainExamples: featureVector = featureExtractor(x) predicted = dotProduct(featureVector, weights) loss = max(0, 1 - predicted * y) totalTrainLoss += loss if loss > 0: for feature, value in featureVector.items(): weights[feature] += eta * value * y for x, y in testExamples: featureVector = featureExtractor(x) predicted = dotProduct(featureVector, weights) loss = max(0, 1 - predicted * y) totalTestLoss += loss trainError = evaluatePredictor(trainExamples, lambda x: (1 if dotProduct(featureExtractor(x), weights) >= 0 else -1)) testError = evaluatePredictor(testExamples, lambda x: (1 if dotProduct(featureExtractor(x), weights) >= 0 else -1)) trainErrors.append(trainError) testErrors.append(testError) trainLosses.append(totalTrainLoss / len(trainExamples)) testLosses.append(totalTestLoss / len(testExamples)) print("At iteration %d, loss on training set is %f, loss on test set is %f, error rate on training set is %f, error rate on test set is %f" % (i, totalTrainLoss / len(trainExamples), totalTestLoss / len(testExamples), trainError, testError)) plt.figure(figsize=(12, 5)) plt.subplot(1, 2, 1) plt.plot(range(numIters), trainLosses, label="Train Loss") plt.plot(range(numIters), testLosses, label="Test Loss") plt.xlabel("Epoch") plt.ylabel("Loss") plt.title("Loss vs. Epoch") plt.legend() plt.subplot(1, 2, 2) plt.plot(range(numIters), trainErrors, label="Train Error Rate") plt.plot(range(numIters), testErrors, label="Test Error Rate") plt.xlabel("Epoch") plt.ylabel("Error Rate") plt.title("Error Rate vs. Epoch") plt.legend() plt.tight_layout() plt.show() return weights
3 训练结果
3.1 词袋模型训练结果
-
训练代码
设置超参数,训练轮次epoch为30,学习率为0.01。
def BOW_Model(numIters, eta): trainExamples = readExamples('data/data_rt.train') testExamples = readExamples('data/data_rt.test') featureExtractor = extractFeatures_bow weights = learnPredictor(trainExamples, testExamples, featureExtractor, numIters=numIters, eta=eta) trainError = evaluatePredictor(trainExamples, lambda x : (1 if dotProduct(featureExtractor(x), weights) >= 0 else -1)) testError = evaluatePredictor(testExamples, lambda x : (1 if dotProduct(featureExtractor(x), weights) >= 0 else -1)) print ("train error = %s, test error = %s" % (trainError, testError)) BOW_Model(30, 0.01) -
训练结果
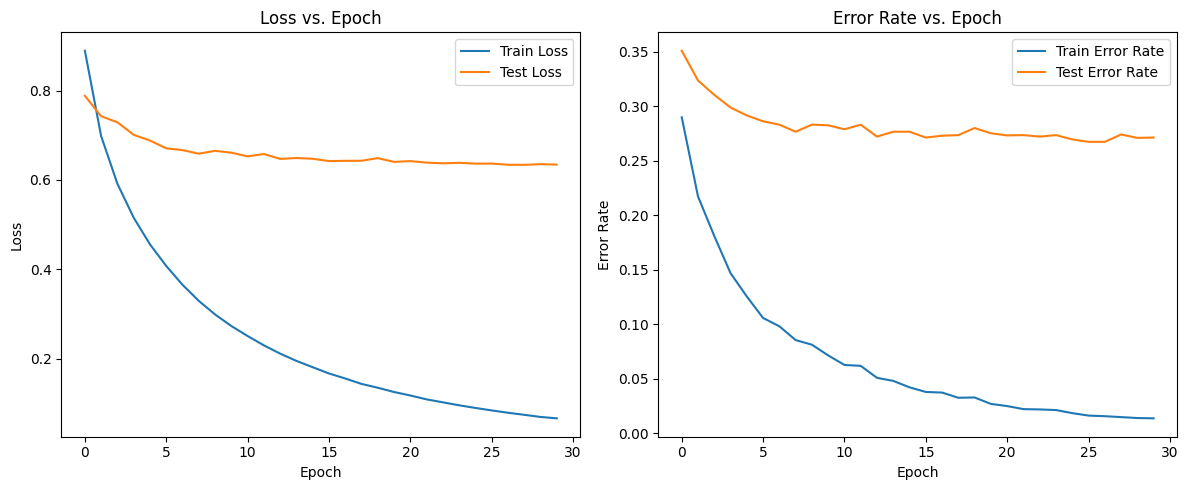
train error = 0.013787281935846933, test error = 0.27124366910523356
3.2 n-gram模型训练结果
-
训练代码
设置超参数,训练轮次epoch为30,学习率为0.01。
def Ngram_Model(numIters, eta): trainExamples = readExamples('data/data_rt.train') testExamples = readExamples('data/data_rt.test') featureExtractor = extractFeatures_ngram weights = learnPredictor(trainExamples, testExamples, featureExtractor, numIters=numIters, eta=eta) trainError = evaluatePredictor(trainExamples, lambda x : (1 if dotProduct(featureExtractor(x), weights) >= 0 else -1)) testError = evaluatePredictor(testExamples, lambda x : (1 if dotProduct(featureExtractor(x), weights) >= 0 else -1)) print ("train error = %s, test error = %s" % (trainError, testError)) Ngram_Model(30, 0.01) -
训练结果
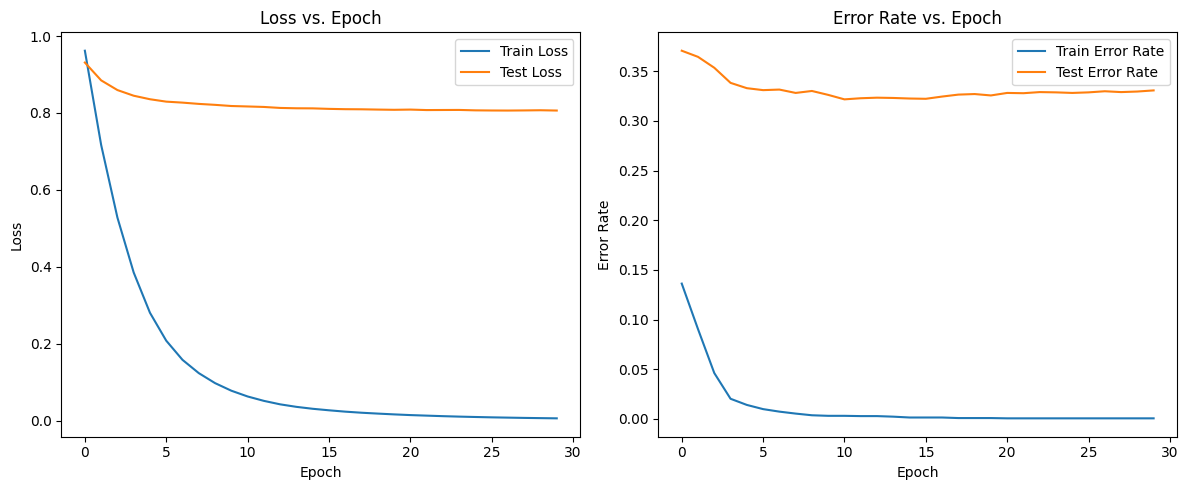
train error = 0.0005627462014631402, test error = 0.33061339335959483可以看到,使用n-gram模型的收敛速度比词袋模型稍快,但训练结果却更差,明显产生了过拟合。
3.3 词向量模型训练结果
-
训练代码
设置超参数,训练轮次epoch为30,学习率为0.01。
def Word2Vec_Model(numIters, eta): trainExamples = readExamples('data/data_rt.train') testExamples = readExamples('data/data_rt.test') featureExtractor = extractFeatures_wordvec weights = learnPredictor(trainExamples, testExamples, featureExtractor, numIters=numIters, eta=eta) trainError = evaluatePredictor(trainExamples, lambda x : (1 if dotProduct(featureExtractor(x), weights) >= 0 else -1)) testError = evaluatePredictor(testExamples, lambda x : (1 if dotProduct(featureExtractor(x), weights) >= 0 else -1)) print ("train error = %s, test error = %s" % (trainError, testError)) Word2Vec_Model(30, 0.01) -
训练结果
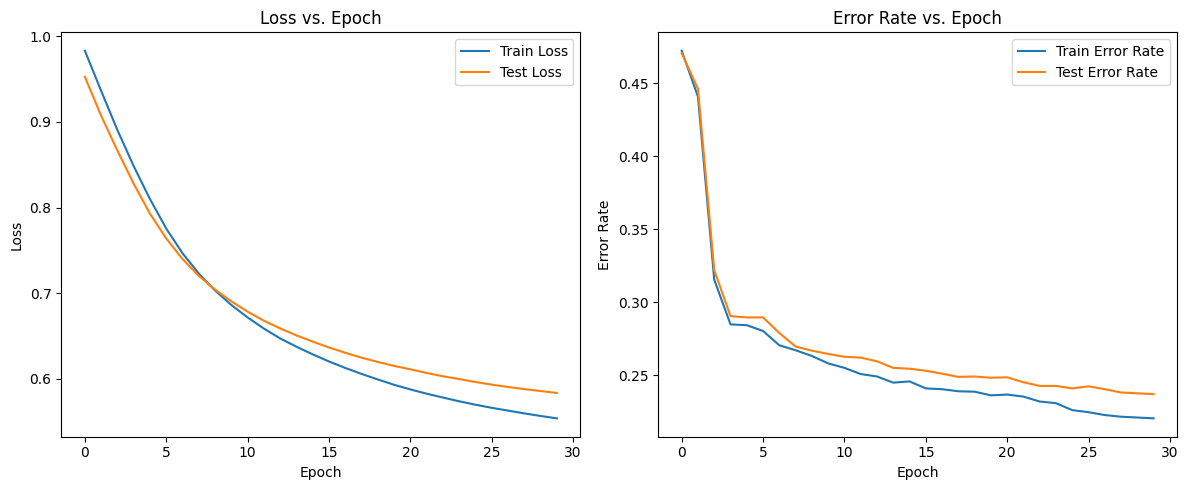
train error = 0.22031513787281937, test error = 0.236916150815982可以看到,使用预训练模型的词向量训练结果最好,得到的erro值最低,并且没有过拟合。
4 总结
以下是各特征提取方法的最终训练和测试误差:
| 特征提取方法 | 训练误差 | 测试误差 |
|---|---|---|
| 词袋模型 | 0.0138 | 0.2712 |
| n-gram模型 | 0.0006 | 0.3306 |
| 词向量模型 | 0.2203 | 0.2369 |
从表格可以看出,n-gram模型在训练集上的误差最低,但在测试集上的误差却最高,表明其可能过拟合了训练数据。词袋模型在训练集和测试集上的误差较为平衡,而词向量模型在测试集上的表现最好,尽管其在训练集上的误差较高。
-
性能:
-
词袋模型在训练集上表现很好,但在测试集上有较高的误差,可能存在一定的过拟合。
-
n-gram模型在训练集上表现最佳,但在测试集上表现最差,明显过拟合。
-
词向量模型在测试集上的误差最低,泛化能力最好。
-
-
泛化能力:
-
词袋模型和n-gram模型都有一定的过拟合风险,尤其是在处理复杂文本时。
-
词向量模型由于捕捉到词语的语义关系,能够更好地泛化到未见过的数据。
-
-
权重可解释性:
-
词袋模型的权重最易解释,可以直接看到每个词对情感预测的影响。
-
n-gram模型的权重解释性相对较低,但仍能提供一定的短语信息。
-
词向量模型的权重解释性最差,但它在捕捉语义信息方面表现最好。
-
根据以上分析,我们可以得出以下结论:
- 如果需要一个解释性较强的模型,可以选择词袋模型。
- 如果需要一个泛化能力较好的模型,可以选择词向量模型。
- n-gram模型在小数据集上容易过拟合,不建议在数据较少或分布复杂时使用。
实际应用中,可以根据具体需求选择合适的特征提取方法和模型,并通过调整学习率、正则化等超参数来优化模型性能。



















 4859
4859

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











