







Interleave-VLA 论文
提出数据集的图像文本交错指令自动化转换以及 Interleave-VLA 使 VLA 模型能够处理交错指令,提升泛化性。但图像标记长度增加,交错输入训练的计算需求更高,且通常需要更多训练步骤才能收敛。
- 常规指令:<观测>将[微波炉附近的蓝色勺子]放入[毛巾上的银色锅]中。
- 交错式指令:<观测>将[图片1]放入[图片2]。其中<观测>是观测图像,[图片1]和[图片2]分别是代表目标物体和目的地的图像。
Interleave-VLA 对于观测 o t = ( I t , I , q ) o_t=(I_t,I,q) ot=(It,I,q) 对动作分布 P ( A t ∣ o t ) P(A_t|o_t) P(At∣ot) 进行建模, I t I_t It 是观测图像, q q q 是机器人本体状态, I = ( l 1 , I 1 , l 2 , I 2 , … … ) I=(l_1,I_1,l_2,I_2,……) I=(l1,I1,l2,I2,……) 是图文交错指令。
对于 OpenVLA,用 InternVL2.5 替换 Prismatic VLM;对于 π 0 \pi_0 π0,调整输入管道。

使用 Qwen2.5-VL 从语言指令提取关键对象,输入开放词汇检测器 OWLv2,在轨迹帧中定位并裁剪目标对象;如果 OWLv2 失败,则由 SAM 2 提供关键点以实现精确分割。
将数据集生成流程应用于Open X-Embodiment中的11个数据集,经过整理的数据集包含21万个情节和1300万帧,涵盖3500个独特对象和广泛的任务类型。
实验结果
为了全面评估泛化能力,依据Stone等人的研究设计了两类主要任务:视觉泛化和语义泛化。视觉泛化用于评估模型对新的桌布、光照和环境的鲁棒性。语义泛化则评估模型在存在各种干扰物的情况下,正确识别和操作目标物体的能力。该评估进一步分为两类:(1)来自先前见过类别的新颖物体;(2)来自全新未见类别的物体。


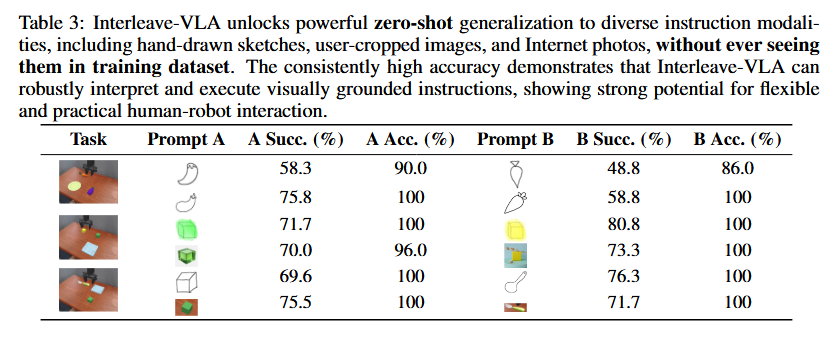
值得注意的是,Interleave-VLA展现出了一种显著的新兴能力:它允许用户以完全零样本的方式灵活指定指令,而无需对未见的输入模态进行任何额外的微调。表3展示了图像指令类型的示例及其相应的高成功率。指令可以采用多种格式,包括:(1)裁剪图像指令:用户可以直接从屏幕上裁剪一个区域来指示目标物体。(2)网络图像指令:用户可以提供任何图像,例如从互联网上检索到的照片,来代表所需的物体。(3)手绘草图指令:用户可以绘制关于物体的草图或卡通画。

















 780
780

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









