







🍦前几天的课程我们学习了Hive数据的导入、导出、查询和排序,有兴趣的小伙伴可以查看以往的文章👇:
- 第一篇: Hadoop之Hive数据的导入与导出(DML).
- 第二篇: Hadoop之Hive查询语句.
- 第三篇:Hadoop之Hive的7种Join语句.
- 第四篇: Hadoop之Hive的排序.
❗️❗️❗️ 今天要介绍的内容在Hive中非常重要,即分区表
分区表
1.分区表
分区表实际上就是对应一个 HDFS 文件系统上的独立的文件夹,该文件夹下是该分区所有的数据文件。Hive 中的分区就是分目录,把一个大的数据集根据业务需要分割成小的数据集。在查询时通过 WHERE 子句中的表达式选择查询所需要的指定的分区,这样的查询效率会提高很多。
1.1 分区表的建立
- 引入分区表(一般情况下,企业中的分区表都是以时间作为分区的)
我们首先建立三个分区表内所需要的文件
--dept1.txt
10 ACCOUNTING 1700
20 RESEARCH 1800
--dept2.txt
30 SALES 1900
40 OPERATIONS 1700
--dept3.txt
50 TEST 2000
60 DEV 1900
创建成功
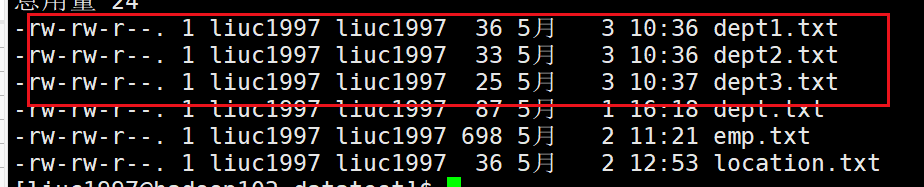
- 创建分区表
create table dept_par(deptno int, dname string, loc string)
partitioned by (day string)--分区表特有
row format delimited fields terminated by '\t';

- 各分区表导入数据
--第一天添加
load data local inpath '/opt/modul/datatest/dept1.txt'
into table dept_par
partition(day="2021-05-01");--指定分区目录
--第二天添加
load data local inpath '/opt/modul/datatest/dept2.txt'
into table dept_par
partition(day="2021-05-02");
--第三天添加
load data local inpath '/opt/modul/datatest/dept3.txt'
into table dept_par
partition(day="2021-05-03");
都按这种方式导入

我们在web服务上看一下数据:我们发现分区表可以理解为在数据表中创建了文件夹来管理数据。
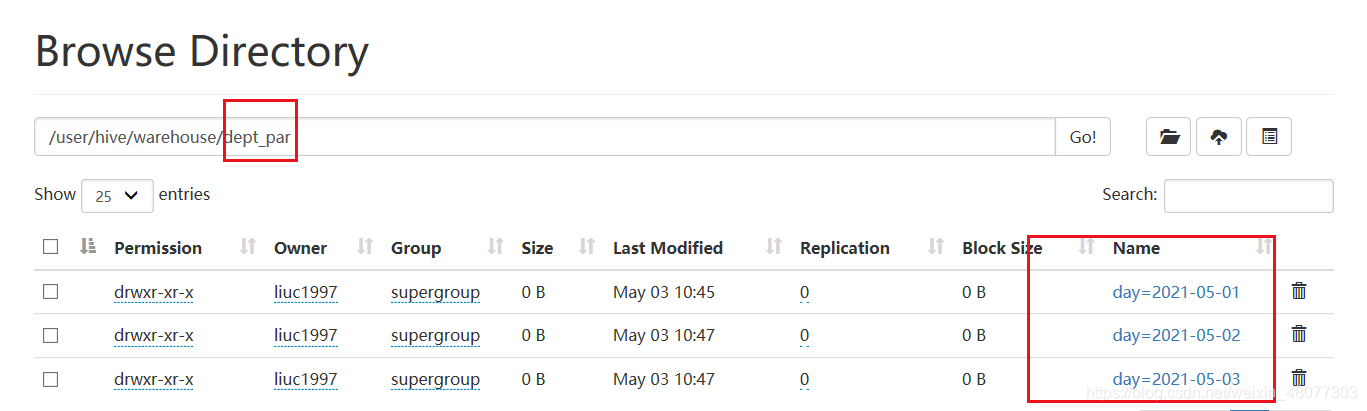
分区信息也是数据的一个字段,用法和普通属性用法一样。
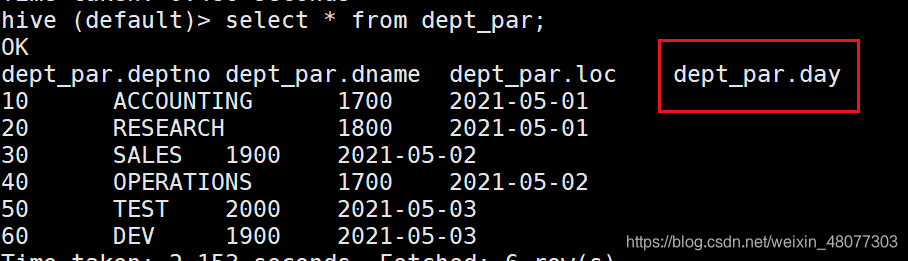
例如查询某天的数据
select * from dept_par where day="2021-05-01";
查询分区信息超级快!因为分区表就相当于目录,可以避免全表扫描。

1.2 查询分区表中数据
刚才其实演示过了,分区查询就相当于属性就行
--单分区查询
select * from dept_par where day="2021-05-01";
--多个分区查询
select * from dept_par where day="2021-05-01"
union
select * from dept_par where day="2021-05-02"
union
select * from dept_par where day="2021-05-03"
--多表分区的另一种写法
select * from dept_par where day="2021-05-01" or day="2021-05-02" or day="2021-05-03";
结果如下:

1.3 增加分区
也是使用alter…add…语句,需要添加多个分区时需要用空格隔开。
--添加一个分区
alter table dept_par add partition(day='2021-05-04');
--添加多个分区
alter table dept_par add partition(day='2021-05-04') partition(day='2021-05-05');
添加分区成功,但是里面没有数据。
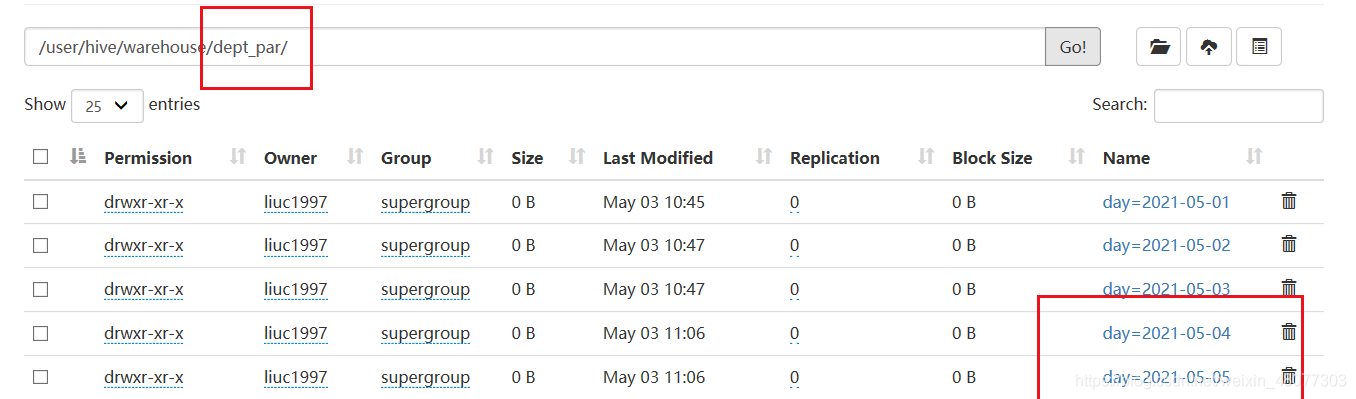
1.4 删除分区
删除分区用alter…drop…语句,删除多个分区时需要用逗号隔开(吐槽它😟)
--删除一个
alter tabel dept_par drop partition(day='2021-05-04');
--删除多个分区
alter table dept_par drop partition(day='2021-05-04'),partition(day='2021-05-05');
删除成功。
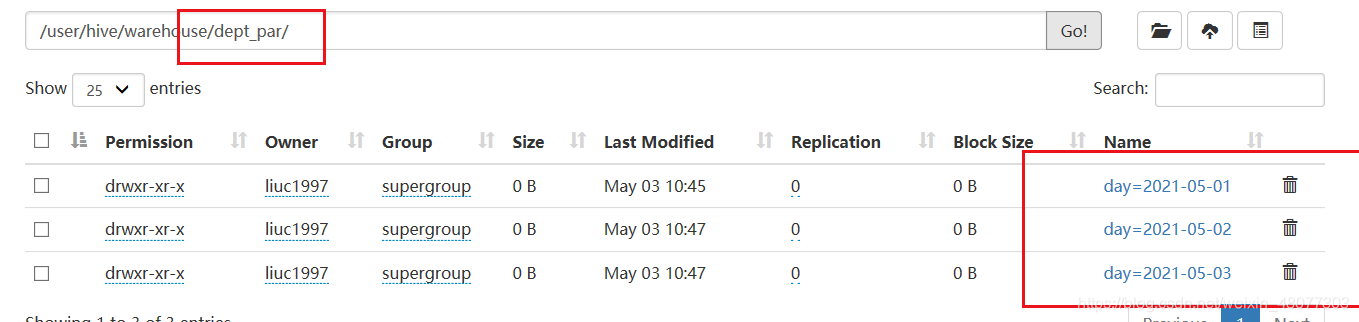
1.5 查看分区
show partitions dept_par;
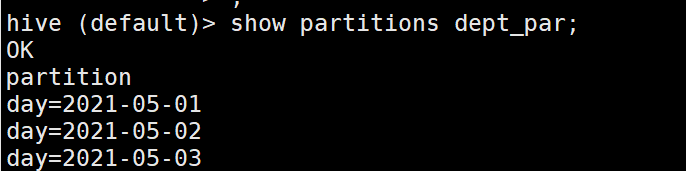
1.6 查看分区表结构
desc formatted dept_partition;
2. 二级分区
上一章节讲述了我们将天为单位进行分区,可如果按天分区数据量依然很大,我们这时就需要按照更小的范围分区,比如小时。
2.1 建立二级分区分区
--创建二级分区表
create table dept_par2(deptno int, dname string, loc string)
partitioned by (day string,hour string)
row format delimited fields terminated by '\t';
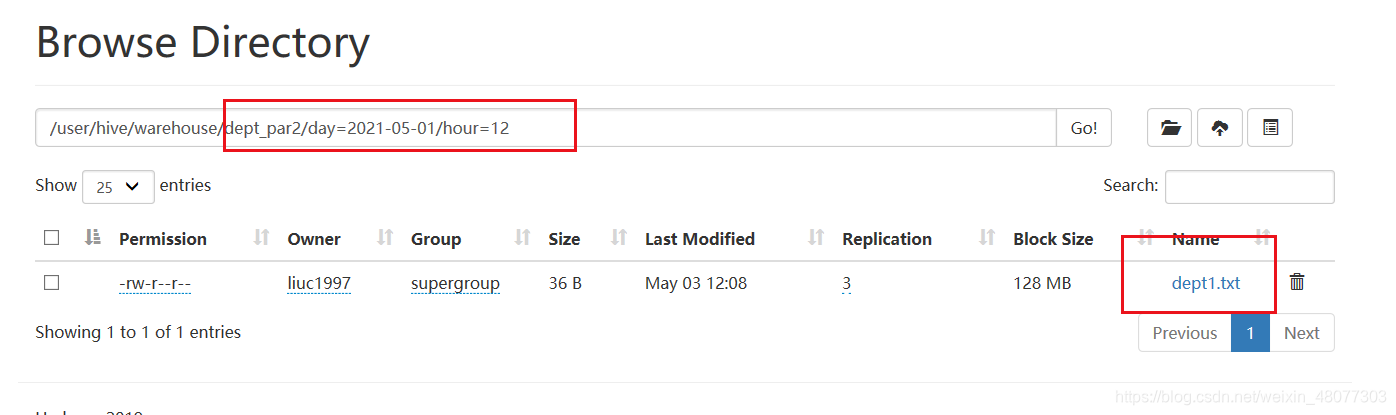
- 导入数据
load data local inpath '/opt/modul/datatest/dept3.txt'
into table dept_par2
partition(day="2021-05-02",hour='12');--指定二级分区信息
创建成功
2.2 查询二级分区
这里查询也是将分区信息当成属性即可
--查询所有信息
select * from dept_par2;
--查询某天的信息
select * from dept_par2 where day='2021-05-01';
--查询某天某时的信息
select * from dept_par2 where day='2021-05-01' and hour='12';
结果:

3. HDFS数据与分区表关联的方法
在最开始的普通数据库建表语句中我们说过,数据是存在HDFS上面的,也就是说,如果通过hdfs命令直接在文件夹先存数据,后建表,都是可以查询到的,但是分区表也是这样的吗?
我们试一试:我们在分区表中建立一个day="2021-05-04"的目录,里面给他数据dept1.txt
#创建一个类似分区表的文件夹
hadoop fs -mkdir /user/hive/warehouse/dept_par/day=2021-05-04
#给他数据
hadoop fs -put dept1.txt /user/hive/warehouse/dept_par/day=2021-05-04
结果如下:
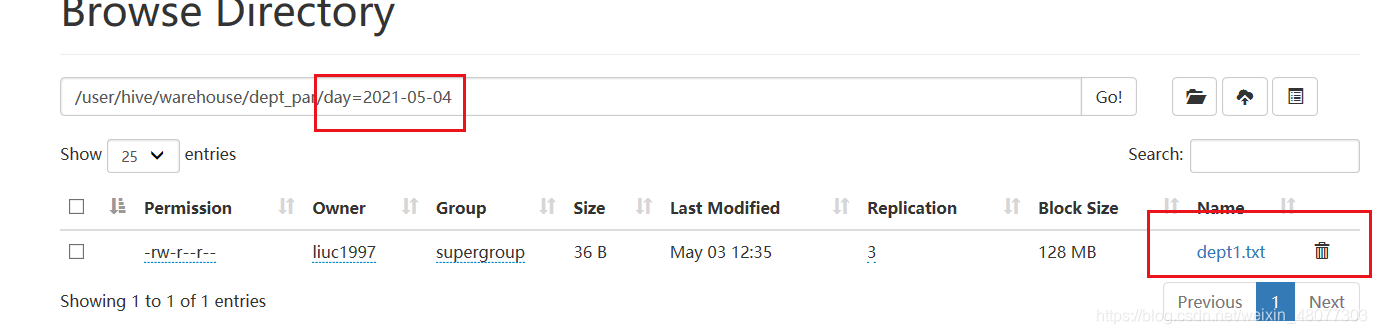
然后我们用语句查询一下:发现找不2021-05-04的数据!!!
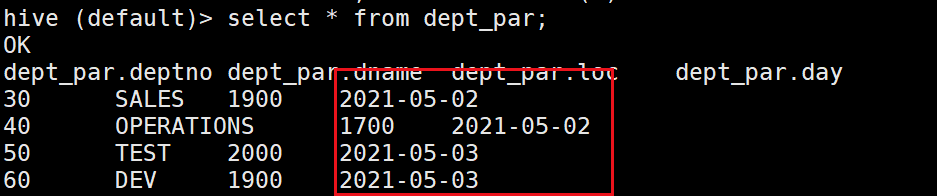
说明元数据中对分区表也有数据的存储,我们应该怎么样才能将我们自建的目录统一到元数据中呢?
3.1 修复分区
- 通过修复分区
--修复分区命令,该命令会匹配分区数据表,补充元数据。
msck repair table dept_par;
修复完成后,成功找到。
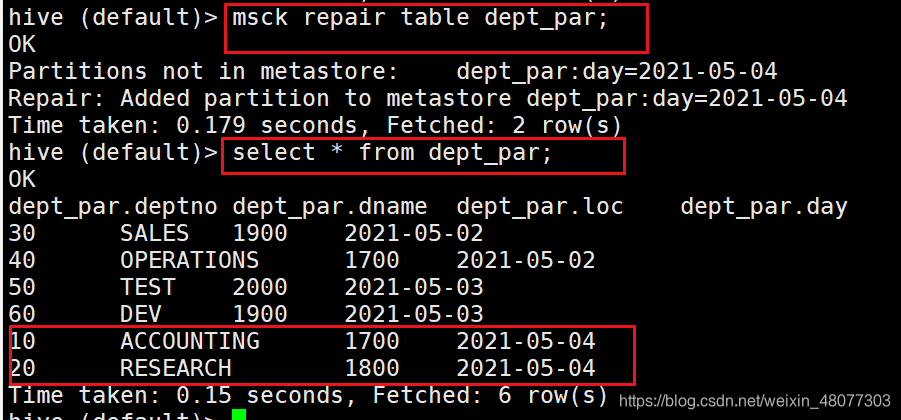
3.2 添加分区
我们在hdfs上再创建目录day=2021-05-05
#创建一个类似分区表的文件夹
hadoop fs -mkdir /user/hive/warehouse/dept_par/day=2021-05-05
#给他数据
hadoop fs -put dept2.txt /user/hive/warehouse/dept_par/day=2021-05-05
- 添加分区
--添加对应分区
alter table dept_par add partition(day="2021-05-05");
结果如下:
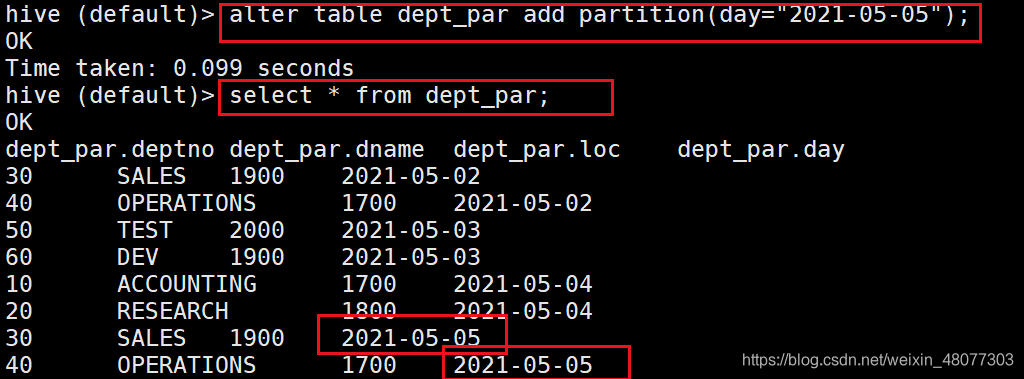
3.3 创建文件夹后load数据
我们可以事先创建文件夹后,然后再使用load数据
-- 创建文件夹
hadoop fs -mkdir /user/hive/warehouse/dept_par/day=2021-05-06
- load数据
--数据只能load方式,才会添加元数据
load data local inpath
'/opt/modul/datatest/dept3.txt'
into table dept_par
partition(day="2021-05-06");
4. 动态分区
动态分区是指分区标准不确定,想依据表中的某个字段进行分区。例如,根据dept表中的deptno进行分区

- 创建分区表
--首先我们创建一个分区表
create table dept_no_par(dname string, loc string)
partitioned by (deptno int)
row format delimited fields terminated by '\t';
- 传递数据
--动态分区会默认将最后一个字段名(deptno)作为分区标准
insert into table dept_no_par
partition(deptno)
select dname,loc,deptno from dept;
--也可以这样,这种不需要改严格模式
insert into table dept_no_par
select dname,loc,deptno from dept;
提示动态分区要在非严格模式

- 设置非严格模式
set hive.exec.dynamic.partition.mode=nonstrict;
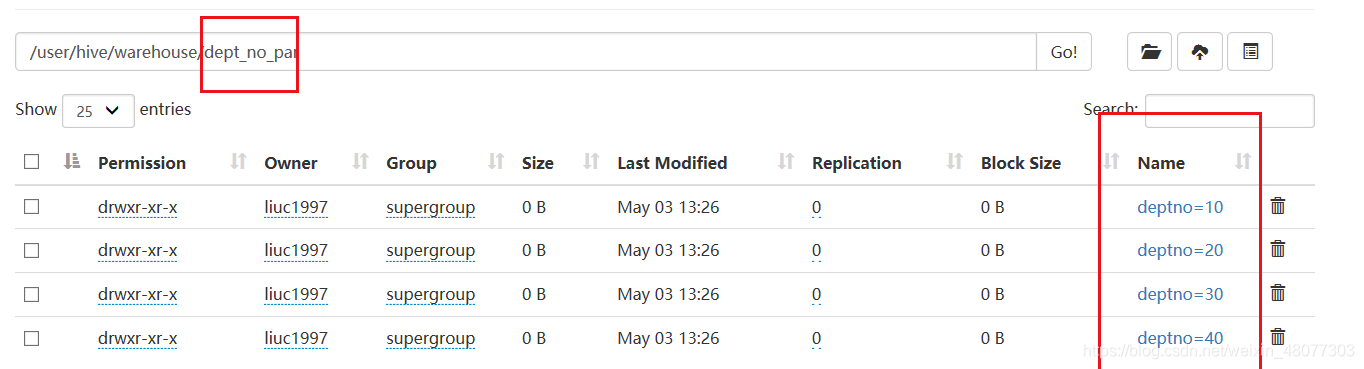
- 再此执行,结果如下:分区成功。
参考资料
《大数据Hadoop3.X分布式处理实战》















 1688
1688











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











