







一、为什么要降维?
1. 直观比喻
假设你要描述一个人:
-
高维描述:身高、体重、发色、鞋码、星座、血型、喜欢的电影...(100个特征)
-
降维后:"运动型"(身高+体重)、"文艺型"(喜欢的电影+书籍)(2个特征)
2. 实际意义
-
解决维度灾难:特征太多会导致数据稀疏,模型难以学习
-
提升效率:减少计算时间,降低存储需求
-
可视化需求:人类只能理解2D/3D图形
二、主流降维方法
方法1:PCA(主成分分析)
核心思想:找到数据中方差最大的方向,将数据投影到这些方向上。
生活化比喻
把三维的西瓜🍉拍成二维照片,选择最能体现西瓜特征的拍摄角度。
计算步骤
-
中心化数据(减去均值)
-
计算协方差矩阵
-
计算特征值和特征向量
-
选择前k大特征值对应的特征向量
Python实现
from sklearn.decomposition import PCA
from sklearn.datasets import load_iris
# 加载数据
iris = load_iris()
X = iris.data
# 降维到2维
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X)
print("原始形状:", X.shape)
print("降维后形状:", X_pca.shape)
print("各主成分解释方差比例:", pca.explained_variance_ratio_)输出示例
原始形状: (150, 4)
降维后形状: (150, 2)
各主成分解释方差比例: [0.924 0.053] # 第一主成分保留了92.4%的信息优缺点
-
✅ 优点:线性方法简单有效,可解释性强
-
❌ 缺点:只能捕捉线性关系
方法2:t-SNE(t分布随机邻域嵌入)
核心思想:保持高维空间中数据点的局部相似性。
生活化比喻
把全世界城市的地理位置画到一张纸上,保证相邻城市在纸上仍然相邻。
Python实现
from sklearn.manifold import TSNE
tsne = TSNE(n_components=2, random_state=42)
X_tsne = tsne.fit_transform(X)适用场景
-
高维数据可视化(常降到2D/3D)
-
探索数据聚类结构
注意事项
-
计算成本高
-
超参数敏感(困惑度perplexity)
方法3:LDA(线性判别分析)
核心思想:找到能最好区分不同类别的投影方向。
与PCA对比
| PCA | LDA | |
|---|---|---|
| 目标 | 最大化总体方差 | 最大化类间方差/类内方差 |
| 有无监督 | 无监督 | 有监督 |
| 结果 | 主成分与类别无关 | 投影方向与类别相关 |
Python实现
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
lda = LinearDiscriminantAnalysis(n_components=2)
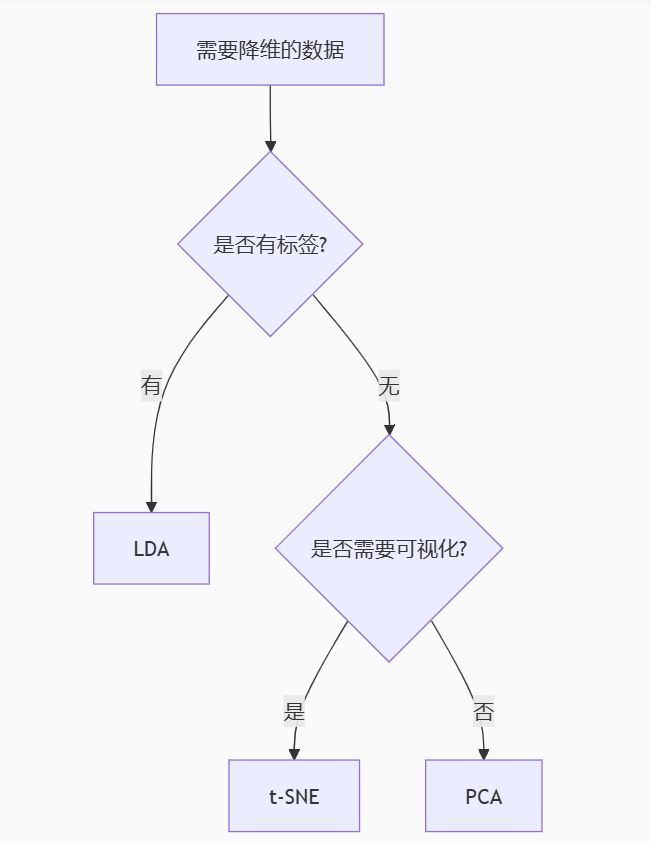
X_lda = lda.fit_transform(X, iris.target)三、如何选择降维方法?


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









