







本文目录
硬件:Nvidia 3090 24G,Windows11
conda环境搭建,略。
一、数据集准备
在raw_data目录下新建一个Task137_BraTS21文件夹,将数据集download到Task137_BraTS21文件夹。
nnUNet_raw/nnUNet_raw_data/Task051_BraTSGLI/
├── BraTS-GLI-00005-100
│ ├── BraTS-GLI-00005-100-seg.nii.gz
│ ├── BraTS-GLI-00005-100-t1c.nii.gz
│ ├── BraTS-GLI-00005-100-t1n.nii.gz
│ ├── BraTS-GLI-00005-100-t2f.nii.gz
│ ├── BraTS-GLI-00005-100-t2w.nii.gz
├── BraTS-GLI-00005-101
│ ├── BraTS-GLI-00005-101-seg.nii.gz
│ ├── BraTS-GLI-00005-101-t1c.nii.gz
│ ├── BraTS-GLI-00005-101-t1n.nii.gz
│ ├── BraTS-GLI-00005-101-t2f.nii.gz
│ ├── BraTS-GLI-00005-101-t2w.nii.gz
|── ...
|
|── BraTS-GLI-03045-101
├── BraTS-GLI-03045-100-seg.nii.gz
├── BraTS-GLI-03045-100-t1c.nii.gz
├── BraTS-GLI-03045-100-t1n.nii.gz
├── BraTS-GLI-03045-100-t2f.nii.gz
├── BraTS-GLI-03045-100-t2w.nii.gz修改root路径
paths.py里要将数据路径修改
nnUNet_raw = 'E:/Dataset/nnUNetDataset/nnUNet_raw/' #os.environ.get('nnUNet_raw')
nnUNet_preprocessed = 'E:/Dataset/nnUNetDataset/nnUNet_preprocessed/' #os.environ.get('nnUNet_preprocessed')
nnUNet_results = 'D:/nnUNet-master/nnunetv2/nnUNet_results/' #os.environ.get('nnUNet_results')BraTS第一例里T1序列是(240,240,155),它的标签seg.nii.gz也是(240,240,155)
下载一些需要的包
ModuleNotFoundError: No module named 'batchgenerators'
ModuleNotFoundError: No module named 'acvl_utils'
ModuleNotFoundError: No module named 'dynamic_network_architectures'github上下载batchgenerators, acvl_utils, dynamic_network_architectures, batchgeneratorsv2, fft_conv_pytorch, cc3d(connected-components-3d),放到nnUNetv2目录下
二、数据集转换
dataset_conversion下的Dataset137_BraTS21.py
dataset_conversion下的convert_MSD_dataset.py
转换后数据集如下:
/nnUNetDataset/nnUNet_raw/nnUNet_raw_data/Dataset051_BraTSGLI/
├── imagesTr
├── labelsTr
├── (imagesTs)
└── dataset.json生成数据集json
运行generate_dataset_json.py
AssertionError: Target dataset id 50 is already taken, please consider changing it using overwrite_target_id. Conflicting dataset: ['Dataset050_BraTs'] (check nnUNet_results, nnUNet_preprocessed and nnUNet_raw!]
检查raw_dataset下面不能有Dataset050_BraTs同名的文件夹
ValueError: invalid literal for int() with base 10: 'Background'
生成dataset.json文件时,在Dataset051_BraTSGLI.py中设置参数:
output_folder输出数据集保存路径,channel_names模态,num_training_cases训练样本数/病例数。
其他地方跟Dataset137_BraTS21.py一样
if __name__ == '__main__':
#brats_data_dir = '/home/isensee/drives/E132-Rohdaten/BraTS_2021/training'
#brats_data_dir = 'E:/Dataset/nnUNetDataset/nnUNet_raw/nnUNet_raw_data/Task051_BraTSGLI/'
brats_data_dir = 'E:/CJY/brats2024-brats-gli-trainingdata/'
task_id = 51
task_name = "BraTSGLI"
foldername = "Dataset%03.0d_%s" % (task_id, task_name)
# setting up nnU-Net folders
out_base = join(nnUNet_raw, foldername)
imagestr = join(out_base, "imagesTr")
labelstr = join(out_base, "labelsTr")
maybe_mkdir_p(imagestr)
maybe_mkdir_p(labelstr)
case_ids = subdirs(brats_data_dir, prefix='BraTS', join=False)
for c in case_ids:
shutil.copy(join(brats_data_dir, c, c + "-t1n.nii.gz"), join(imagestr, c + '_0000.nii.gz'))
shutil.copy(join(brats_data_dir, c, c + "-t1c.nii.gz"), join(imagestr, c + '_0001.nii.gz'))
shutil.copy(join(brats_data_dir, c, c + "-t2W.nii.gz"), join(imagestr, c + '_0002.nii.gz'))
shutil.copy(join(brats_data_dir, c, c + "-t2f.nii.gz"), join(imagestr, c + '_0003.nii.gz'))
#copy_BraTS_segmentation_and_convert_labels_to_nnUNet(join(brats_data_dir, c, c + "-seg.nii.gz"),
# join(labelstr, c + '.nii.gz'))
shutil.copy(join(brats_data_dir, c, c+"-seg.nii.gz"),join(labelstr,c+'.nii.gz'))
generate_dataset_json(out_base,
channel_names={'001':'t1n','002':'t1c','003':'t2w','004':'t2f'},
labels={'background':0,'NETC':1,'SNFH':2,'ET':3,'RC':4},
num_training_cases=1350,
file_ending='.nii.gz',
license='see https://www.synapse.org/#!Synapse:syn25829067/wiki/610863',
reference='see https://www.synapse.org/#!Synapse:syn25829067/wiki/610863',
dataset_release='2.0')在这里你设置的task_id=51,task_name="BraTSGLI"需要记住,在后面训练run_training时候需要用到。
RuntimeError: Background label not declared (remember that this should be label 0!)
注意:数据集跑好了跑新实验就不用再跑
三、数据预处理Dataset Preprocessing
运行verify_dataset_integrity.py检验数据集是否可以用于nnUNet网络,在新数据集首次训练前运行一次就行。
E:\Anaconda\envs\sr3d\python.exe D:\nnUNet-master\nnunetv2\experiment_planning\verify_dataset_integrity.py
Using <class 'nnunetv2.imageio.simpleitk_reader_writer.SimpleITKIO'> as reader/writer
####################
verify_dataset_integrity Done.
If you didn't see any error messages then your dataset is most likely OK!
####################
Process finished with exit code 0运行D:\nnUNet-master\nnunetv2\experiment_planning\plan_and_preprocess_entrypoints.py验证数据集正确性,生成训练配置文件Configuration.json,这个configuration在后面的run_training.py用的到。
Run Edit Configuretion,设置运行参数

-d 051 --verify_dataset_integrity -c 3d_fullres
-d为137,数据集/Task的序号
-verify_dataset_integrity为True,True不用写
-c为3d_fullres,否则默认为2d
E:\Anaconda\envs\sr3d\python.exe D:\nnUNet-master\nnunetv2\experiment_planning\plan_and_preprocess_entrypoints.py -d 051 --verify_dataset_integrity -c 3d_fullres
Fingerprint extraction...
Dataset051_BraTSGLI
Using <class 'nnunetv2.imageio.simpleitk_reader_writer.SimpleITKIO'> as reader/writer
####################
verify_dataset_integrity Done.
If you didn't see any error messages then your dataset is most likely OK!
####################
Experiment planning...
############################
INFO: You are using the old nnU-Net default planner. We have updated our recommendations. Please consider using those instead! Read more here: https://github.com/MIC-DKFZ/nnUNet/blob/master/documentation/resenc_presets.md
############################
Dropping 3d_lowres config because the image size difference to 3d_fullres is too small. 3d_fullres: [142. 175. 136.], 3d_lowres: [142, 175, 136]
2D U-Net configuration:
{'data_identifier': 'nnUNetPlans_2d', 'preprocessor_name': 'DefaultPreprocessor', 'batch_size': 105, 'patch_size': (192, 160), 'median_image_size_in_voxels': array([175., 136.]), 'spacing': array([1., 1.]), 'normalization_schemes': ['ZScoreNormalization', 'ZScoreNormalization', 'ZScoreNormalization', 'ZScoreNormalization'], 'use_mask_for_norm': [True, True, True, True], 'resampling_fn_data': 'resample_data_or_seg_to_shape', 'resampling_fn_seg': 'resample_data_or_seg_to_shape', 'resampling_fn_data_kwargs': {'is_seg': False, 'order': 3, 'order_z': 0, 'force_separate_z': None}, 'resampling_fn_seg_kwargs': {'is_seg': True, 'order': 1, 'order_z': 0, 'force_separate_z': None}, 'resampling_fn_probabilities': 'resample_data_or_seg_to_shape', 'resampling_fn_probabilities_kwargs': {'is_seg': False, 'order': 1, 'order_z': 0, 'force_separate_z': None}, 'architecture': {'network_class_name': 'dynamic_network_architectures.architectures.unet.PlainConvUNet', 'arch_kwargs': {'n_stages': 6, 'features_per_stage': (32, 64, 128, 256, 512, 512), 'conv_op': 'torch.nn.modules.conv.Conv2d', 'kernel_sizes': ((3, 3), (3, 3), (3, 3), (3, 3), (3, 3), (3, 3)), 'strides': ((1, 1), (2, 2), (2, 2), (2, 2), (2, 2), (2, 2)), 'n_conv_per_stage': (2, 2, 2, 2, 2, 2), 'n_conv_per_stage_decoder': (2, 2, 2, 2, 2), 'conv_bias': True, 'norm_op': 'torch.nn.modules.instancenorm.InstanceNorm2d', 'norm_op_kwargs': {'eps': 1e-05, 'affine': True}, 'dropout_op': None, 'dropout_op_kwargs': None, 'nonlin': 'torch.nn.LeakyReLU', 'nonlin_kwargs': {'inplace': True}}, '_kw_requires_import': ('conv_op', 'norm_op', 'dropout_op', 'nonlin')}, 'batch_dice': True}
Using <class 'nnunetv2.imageio.simpleitk_reader_writer.SimpleITKIO'> as reader/writer
3D fullres U-Net configuration:
{'data_identifier': 'nnUNetPlans_3d_fullres', 'preprocessor_name': 'DefaultPreprocessor', 'batch_size': 2, 'patch_size': (128, 160, 112), 'median_image_size_in_voxels': array([142., 175., 136.]), 'spacing': array([1., 1., 1.]), 'normalization_schemes': ['ZScoreNormalization', 'ZScoreNormalization', 'ZScoreNormalization', 'ZScoreNormalization'], 'use_mask_for_norm': [True, True, True, True], 'resampling_fn_data': 'resample_data_or_seg_to_shape', 'resampling_fn_seg': 'resample_data_or_seg_to_shape', 'resampling_fn_data_kwargs': {'is_seg': False, 'order': 3, 'order_z': 0, 'force_separate_z': None}, 'resampling_fn_seg_kwargs': {'is_seg': True, 'order': 1, 'order_z': 0, 'force_separate_z': None}, 'resampling_fn_probabilities': 'resample_data_or_seg_to_shape', 'resampling_fn_probabilities_kwargs': {'is_seg': False, 'order': 1, 'order_z': 0, 'force_separate_z': None}, 'architecture': {'network_class_name': 'dynamic_network_architectures.architectures.unet.PlainConvUNet', 'arch_kwargs': {'n_stages': 6, 'features_per_stage': (32, 64, 128, 256, 320, 320), 'conv_op': 'torch.nn.modules.conv.Conv3d', 'kernel_sizes': ((3, 3, 3), (3, 3, 3), (3, 3, 3), (3, 3, 3), (3, 3, 3), (3, 3, 3)), 'strides': ((1, 1, 1), (2, 2, 2), (2, 2, 2), (2, 2, 2), (2, 2, 2), (2, 2, 1)), 'n_conv_per_stage': (2, 2, 2, 2, 2, 2), 'n_conv_per_stage_decoder': (2, 2, 2, 2, 2), 'conv_bias': True, 'norm_op': 'torch.nn.modules.instancenorm.InstanceNorm3d', 'norm_op_kwargs': {'eps': 1e-05, 'affine': True}, 'dropout_op': None, 'dropout_op_kwargs': None, 'nonlin': 'torch.nn.LeakyReLU', 'nonlin_kwargs': {'inplace': True}}, '_kw_requires_import': ('conv_op', 'norm_op', 'dropout_op', 'nonlin')}, 'batch_dice': False}
Plans were saved to E:/Dataset/nnUNetDataset/nnUNet_preprocessed/Dataset051_BraTSGLI\nnUNetPlans.json
Preprocessing...
Preprocessing dataset Dataset051_BraTSGLI
Configuration: 3d_fullres...
100%|██████████| 1350/1350 [11:41<00:00, 1.92it/s]
Process finished with exit code 0预处理后数据如下:
/nnUNetDataset/nnUNet_preprocessed/Dataset051_BraTSGLI/
├── gt_segmentations/
│ ├── BraTS-GLI-00005-100.nii.gz
│ ├── BraTS-GLI-00005-101.nii.gz
│ ├── BraTS-GLI-00006-100.nii.gz
│ ├── ...
├── nnUNetPlans_2d
│ ├── BraTS-GLI-00005-100.npz
│ ├── BraTS-GLI-00005-101.npz
│ ├── BraTS-GLI-00006-100.npz
│ ├── ...
├── nnUNetPlans_3d_fullres
│ ├── BraTS-GLI-00005-100.npy
│ ├── BraTS-GLI-00005-100.npz
│ ├── BraTS-GLI-00005-100.pkl
│ ├── BraTS-GLI-00005-100_seg.npy
│ ├── BraTS-GLI-00005-101.npy
│ ├── BraTS-GLI-00005-101.npz
│ ├── BraTS-GLI-00005-101.pkl
│ ├── BraTS-GLI-00005-101_seg.npy
│ ├── ...
├── dataset.json
├── dataset_fingerprint.json
├── nnUNetPlans.json
├── splits_final.json
Dataset Visualization
At this stage it is useful to examine the training and testing data.
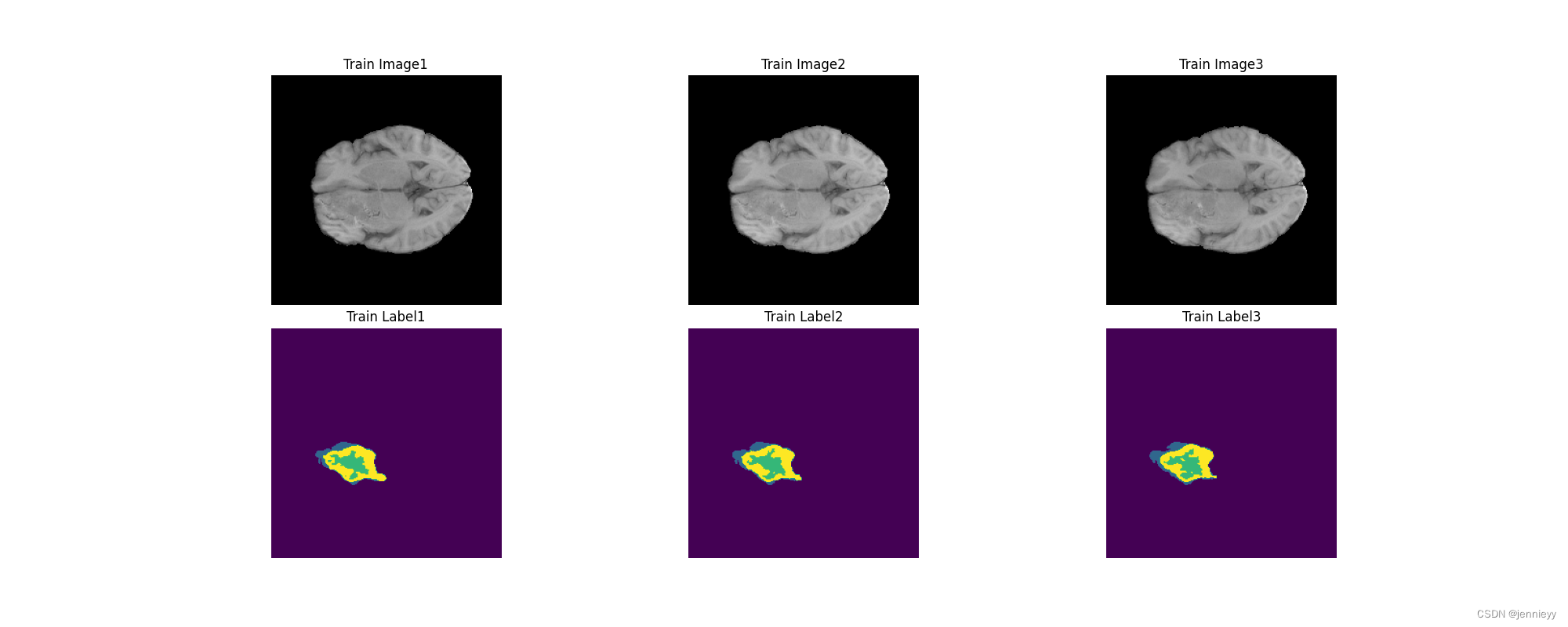
四、训练Training nnU-Net
configuration.py里面的processors参数要修改
修改了utilities/default_n_proc_DA里的default_process=0。在get_allowed_n_proc_DA()中加入本机的hostname,并设置本机的num_process为8。本机hostname可以debug时计算表达式得到。
def get_allowed_n_proc_DA():
if 'nnUNet_n_proc_DA' in os.environ.keys():
use_this = int(os.environ['nnUNet_n_proc_DA'])
else:
hostname = subprocess.getoutput(['hostname'])
if hostname in ['Fabian', ]:
use_this = 12
elif hostname in ['hdf19-gpu16', 'hdf19-gpu17', 'hdf19-gpu18', 'hdf19-gpu19', 'e230-AMDworkstation']:
use_this = 16
elif hostname.startswith('e230-dgx2'):
use_this = 6
elif hostname.startswith('e230-dgxa100-'):
use_this = 28
elif hostname.startswith('DESKTOP'):
use_this = 8
elif hostname.startswith('DESKTOP23'):
use_this = 8
else:
use_this = 0 # default value
use_this = min(use_this, os.cpu_count())
return use_thisD:\nnUNet-master\nnunetv2\training\nnUNetTrainer\nnUNetTrainer.py
class nnUNetTrainer(object):的参数需要修改
num_epochs改小,200
self.initial_lr = 1e-2
self.weight_decay = 3e-5
self.oversample_foreground_percent = 0.33
self.num_iterations_per_epoch = 250
self.num_val_iterations_per_epoch = 50
self.num_epochs = 1000
self.current_epoch = 0Generic Training Commands 训练运行命令:
nnUNetv2_train Dataset_NAME_OR_ID CONFIGURATION FOLD -tr TRAINER_CLASS_NAME (additional options)运行D:\nnUNet-master\nnunetv2\run\run_training.py
将run_training.py里的parser参数设置为实验的Task号,配置Configuration,五折交叉验证'fold'是第'0'折。
parser = argparse.ArgumentParser()
parser.add_argument('dataset_name_or_id', type=str, default='',
help="Dataset name or ID to train with")
parser.add_argument('configuration', type=str, default='',
help="Configuration that should be trained")
parser.add_argument('fold', type=str, default='0',
help='Fold of the 5-fold cross-validation. Should be an int between 0 and 4.')run_training.py: error: the following arguments are required: dataset_name_or_id, configuration, fold
在Run➡Edit Configuration中设置运行参数为137 3d_fullres 0,不需要写dataset_id_or_name,直接写三个值

ValueError: dataset_name_or_id must either be an integer or a valid dataset name with the pattern DatasetXXX_YYY where XXX are the three(!) task ID digits. Your input: '137'
RuntimeError: Requested configuration '3d_fullres' not found in plans. Available configurations: ['2d', '3d_fullres']
run_training.py: error: unrecognized arguments: E:/Dataset/nnUNetDataset/nnUNet_preprocessed/Dataset051_BraTSGLI/nnUNetPlans.json File "D:\nnUNet-master\nnunetv2\training\nnUNetTrainer\nnUNetTrainer.py", line 697, in get_dataloaders
_ = next(mt_gen_train)
^^^^^^^^^^^^^^^^^^
File "D:\nnUNet-master\nnunetv2\batchgenerators\dataloading\nondet_multi_threaded_augmenter.py", line 196, in __next__
item = self.__get_next_item()
^^^^^^^^^^^^^^^^^^^^^^
File "D:\nnUNet-master\nnunetv2\batchgenerators\dataloading\nondet_multi_threaded_augmenter.py", line 181, in __get_next_item
raise RuntimeError("One or more background workers are no longer alive. Exiting. Please check the "
RuntimeError: One or more background workers are no longer alive. Exiting. Please check the print statements above for the actual error message修改了utilitizes/default_n_OC里的default_process=0
else:
use_this = 0 #default process File "D:\nnUNet-master\nnunetv2\batchgeneratorsv2\transforms\spatial\spatial.py", line 285, in _create_identity_grid
grid = torch.meshgrid(space, indexing="ij")
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "E:\Anaconda\envs\sr3d\Lib\site-packages\torch\functional.py", line 497, in meshgrid
return _meshgrid(*tensors, indexing=indexing)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "E:\Anaconda\envs\sr3d\Lib\site-packages\torch\functional.py", line 512, in _meshgrid
return _VF.meshgrid(tensors, **kwargs, indexing='ij') # type: ignore[attr-defined]
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
TypeError: torch._VariableFunctionsClass.meshgrid() got multiple values for keyword argument 'indexing'之前有次调代码的时候把torch源码改了,现在要改回来
return _VF.meshgrid(tensors, **kwargs)代码运行成功,log信息如下:
E:\Anaconda\envs\sr3d\python.exe D:\nnUNet-master\nnunetv2\run\run_training.py 051 3d_fullres 0
############################
INFO: You are using the old nnU-Net default plans. We have updated our recommendations. Please consider using those instead! Read more here: https://github.com/MIC-DKFZ/nnUNet/blob/master/documentation/resenc_presets.md
############################
Using device: cuda:0
Trainer_logging
2024-07-17 15:34:38.624708: do_dummy_2d_data_aug: False
2024-07-17 15:34:38.631440: Using splits from existing split file: E:/Dataset/nnUNetDataset/nnUNet_preprocessed/Dataset051_BraTSGLI\splits_final.json
2024-07-17 15:34:38.633435: The split file contains 5 splits.
2024-07-17 15:34:38.633435: Desired fold for training: 0
2024-07-17 15:34:38.633435: This split has 1080 training and 270 validation cases.
E:\Anaconda\envs\sr3d\Lib\site-packages\torch\optim\lr_scheduler.py:28: UserWarning: The verbose parameter is deprecated. Please use get_last_lr() to access the learning rate.
warnings.warn("The verbose parameter is deprecated. Please use get_last_lr() "
This is the configuration used by this training:
Configuration name: 3d_fullres
{'data_identifier': 'nnUNetPlans_3d_fullres', 'preprocessor_name': 'DefaultPreprocessor', 'batch_size': 2, 'patch_size': [128, 160, 112], 'median_image_size_in_voxels': [142.0, 175.0, 136.0], 'spacing': [1.0, 1.0, 1.0], 'normalization_schemes': ['ZScoreNormalization', 'ZScoreNormalization', 'ZScoreNormalization', 'ZScoreNormalization'], 'use_mask_for_norm': [True, True, True, True], 'resampling_fn_data': 'resample_data_or_seg_to_shape', 'resampling_fn_seg': 'resample_data_or_seg_to_shape', 'resampling_fn_data_kwargs': {'is_seg': False, 'order': 3, 'order_z': 0, 'force_separate_z': None}, 'resampling_fn_seg_kwargs': {'is_seg': True, 'order': 1, 'order_z': 0, 'force_separate_z': None}, 'resampling_fn_probabilities': 'resample_data_or_seg_to_shape', 'resampling_fn_probabilities_kwargs': {'is_seg': False, 'order': 1, 'order_z': 0, 'force_separate_z': None}, 'architecture': {'network_class_name': 'dynamic_network_architectures.architectures.unet.PlainConvUNet', 'arch_kwargs': {'n_stages': 6, 'features_per_stage': [32, 64, 128, 256, 320, 320], 'conv_op': 'torch.nn.modules.conv.Conv3d', 'kernel_sizes': [[3, 3, 3], [3, 3, 3], [3, 3, 3], [3, 3, 3], [3, 3, 3], [3, 3, 3]], 'strides': [[1, 1, 1], [2, 2, 2], [2, 2, 2], [2, 2, 2], [2, 2, 2], [2, 2, 1]], 'n_conv_per_stage': [2, 2, 2, 2, 2, 2], 'n_conv_per_stage_decoder': [2, 2, 2, 2, 2], 'conv_bias': True, 'norm_op': 'torch.nn.modules.instancenorm.InstanceNorm3d', 'norm_op_kwargs': {'eps': 1e-05, 'affine': True}, 'dropout_op': None, 'dropout_op_kwargs': None, 'nonlin': 'torch.nn.LeakyReLU', 'nonlin_kwargs': {'inplace': True}, 'deep_supervision': True}, '_kw_requires_import': ['conv_op', 'norm_op', 'dropout_op', 'nonlin']}, 'batch_dice': False}
These are the global plan.json settings:
{'dataset_name': 'Dataset051_BraTSGLI', 'plans_name': 'nnUNetPlans', 'original_median_spacing_after_transp': [1.0, 1.0, 1.0], 'original_median_shape_after_transp': [142, 175, 136], 'image_reader_writer': 'SimpleITKIO', 'transpose_forward': [0, 1, 2], 'transpose_backward': [0, 1, 2], 'experiment_planner_used': 'ExperimentPlanner', 'label_manager': 'LabelManager', 'foreground_intensity_properties_per_channel': {'0': {'max': 9210.0, 'mean': 1083.545654296875, 'median': 776.2343139648438, 'min': -38.0, 'percentile_00_5': 60.319400787353516, 'percentile_99_5': 3614.736328125, 'std': 863.6681518554688}, '1': {'max': 37011.69921875, 'mean': 1248.953857421875, 'median': 950.2376708984375, 'min': 0.0, 'percentile_00_5': 64.50062900543213, 'percentile_99_5': 5005.8203125, 'std': 1037.698486328125}, '2': {'max': 12372.0, 'mean': 1316.230224609375, 'median': 1016.6731262207031, 'min': 0.0, 'percentile_00_5': 215.22721061706542, 'percentile_99_5': 5257.6171875, 'std': 933.8424682617188}, '3': {'max': 4578.0, 'mean': 707.5701904296875, 'median': 619.3465881347656, 'min': -1.0, 'percentile_00_5': 11.428452491760254, 'percentile_99_5': 2516.0, 'std': 507.3000183105469}}}
2024-07-17 15:34:44.464195: unpacking dataset...
2024-07-17 15:45:31.072240: unpacking done...
2024-07-17 15:45:31.138645: Unable to plot network architecture:
2024-07-17 15:45:31.139634: No module named 'hiddenlayer'
2024-07-17 15:45:31.209124:
2024-07-17 15:45:31.209124: Epoch 0
2024-07-17 15:45:31.225324: Current learning rate: 0.01
2024-07-17 15:55:33.894585: train_loss 0.0152
2024-07-17 15:55:33.896632: val_loss -0.1503
2024-07-17 15:55:33.897704: Pseudo dice [0.0, 0.652, 0.6059, 0.1973]
2024-07-17 15:55:33.898211: Epoch time: 602.69 s
2024-07-17 15:55:33.899211: Yayy! New best EMA pseudo Dice: 0.3638
2024-07-17 15:55:35.807925:
2024-07-17 15:55:35.807925: Epoch 1
2024-07-17 15:55:35.809896: Current learning rate: 0.00995
2024-07-17 16:05:06.998181: train_loss -0.207
2024-07-17 16:05:06.998181: val_loss -0.2459
2024-07-17 16:05:06.999322: Pseudo dice [0.0, 0.7181, 0.6561, 0.5611]
2024-07-17 16:05:06.999322: Epoch time: 571.19 s
2024-07-17 16:05:07.000320: Yayy! New best EMA pseudo Dice: 0.3758
2024-07-17 16:05:08.070824:
2024-07-17 16:05:08.070824: Epoch 2
2024-07-17 16:05:08.072373: Current learning rate: 0.00991
2024-07-17 16:14:33.596678: train_loss -0.263
2024-07-17 16:14:33.596678: val_loss -0.2952
2024-07-17 16:14:33.597677: Pseudo dice [0.0565, 0.7641, 0.6878, 0.6381]
2024-07-17 16:14:33.598648: Epoch time: 565.53 s
2024-07-17 16:14:33.598648: Yayy! New best EMA pseudo Dice: 0.3919
2024-07-17 16:14:34.678348:
2024-07-17 16:14:34.678348: Epoch 3
2024-07-17 16:14:34.679782: Current learning rate: 0.00986
2024-07-17 16:23:50.189426: train_loss -0.2858
2024-07-17 16:23:50.190423: val_loss -0.3222
2024-07-17 16:23:50.195040: Pseudo dice [0.1426, 0.7698, 0.7906, 0.6304]
2024-07-17 16:23:50.196958: Epoch time: 555.51 s
2024-07-17 16:23:50.197965: Yayy! New best EMA pseudo Dice: 0.411
2024-07-17 16:23:51.282467:
2024-07-17 16:23:51.282467: Epoch 4
2024-07-17 16:23:51.284584: Current learning rate: 0.00982
2024-07-17 16:33:04.511223: train_loss -0.3396
2024-07-17 16:33:04.512225: val_loss -0.3435
2024-07-17 16:33:04.513178: Pseudo dice [0.0731, 0.8362, 0.7256, 0.6954]
2024-07-17 16:33:04.514213: Epoch time: 553.23 s
2024-07-17 16:33:04.514213: Yayy! New best EMA pseudo Dice: 0.4282
2024-07-17 16:33:05.555011:
2024-07-17 16:33:05.555011: Epoch 5
2024-07-17 16:33:05.557006: Current learning rate: 0.00977
2024-07-17 16:41:55.537683: train_loss -0.3309
2024-07-17 16:41:55.537683: val_loss -0.3609
2024-07-17 16:41:55.538650: Pseudo dice [0.3348, 0.8236, 0.8066, 0.7565]
2024-07-17 16:41:55.539636: Epoch time: 529.98 s
2024-07-17 16:41:55.541166: Yayy! New best EMA pseudo Dice: 0.4534
2024-07-17 16:41:56.612189:
2024-07-17 16:41:56.613185: Epoch 6
2024-07-17 16:41:56.614182: Current learning rate: 0.00973

















 21万+
21万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









