







1、卷积神经网络
这文章讲的很好。不过是别人的,好可惜
1.1、卷积神经网络大致过程
covolutional layer(卷积)、ReLu layer(非线性映射)、pooling layer( 池化)、fully connected layer(全连接)、output(输出)的组合,例如下图所示的结构。
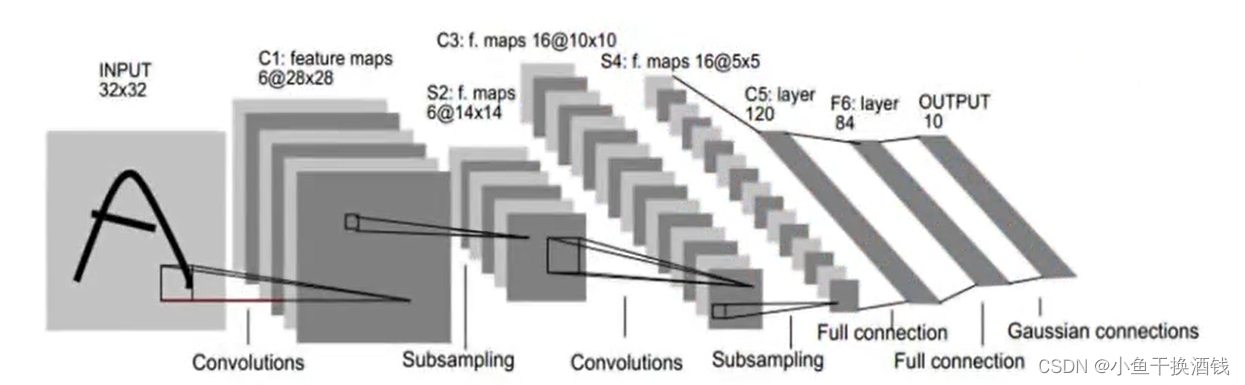
1.2、全连接与局部连接(权值共享)
在CNN中,先选择一个局部区域( filter),用这个局部区域去扫描整张图片。局部区域所圈起来的所有节点会被连接到下一层的一个节点上。


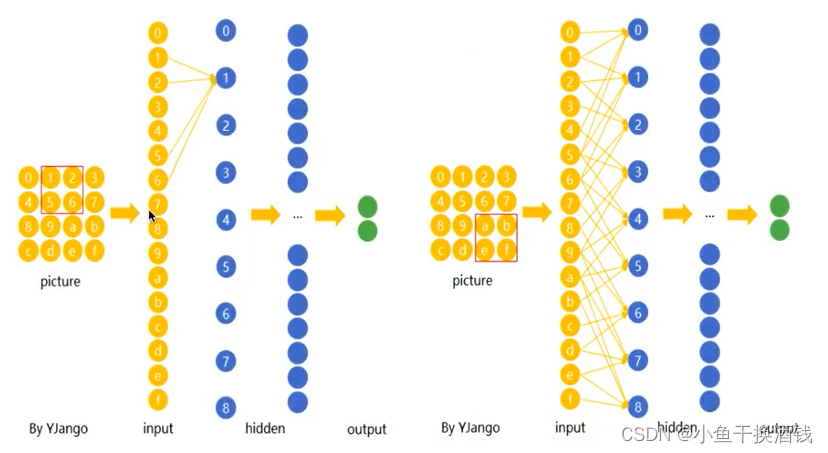
下图(右边像素减左边像素)说明了权值共享是如何提高线性函数在图像边缘检测上的效率的。

输入:280x320 pix ,输出 :280x319 pix , filter :2 x 1
全连接:320x 280 x 319 x 280 = 80亿个权值、160亿次浮点计算
卷积:2个权值、319 x 280 x 3 =267, 960 次浮点计算
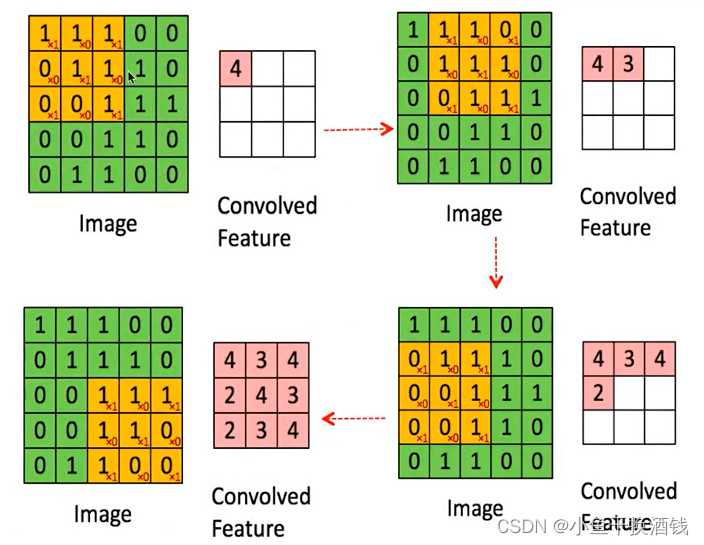
1.3、卷积层- CNN权值共享
filter :

1.4、非线性映射ReLU ( Rectified Linear Units )
加入非线性映射ReLU ( Rectified Linear Units )
- 和前馈神经网络一样,经过线性组合和偏移后,会加入非线性增强模型的拟合能力。
- 经过线性组合和偏移后,会加入非线性增强模型的拟合能力。将卷积所得的Feature Map经过ReLU变换( elementwise)。

1.5、池化( pooling)
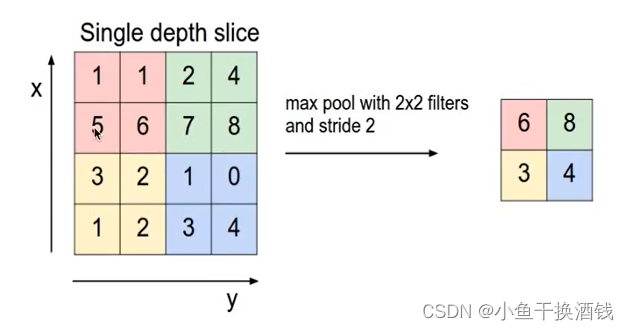
1.6、全连接层
- 当抓取到足以用来识别图片的特征后,接下来的就是如何进行分类。
- 全连接层(也叫前馈层)就可以用来将最后的输出映射到线性可分的空间。
- 卷积网络的最后会将末端得到一个长长的向量,并送入全连接层配合输出层进行分类。
1.6.1、高维输入

多filters

2、代码
用的是TensorFlow2.X,但是用到的api是基于TensorFlow1.X,需要做一层转换。
使用到的仓库:
pip install tensorflow
pip install opencv-python
pip install opencv-contrib-python
# 版本信息
tensorflow 2.13.0
opencv-contrib-python 4.8.0.74
opencv-python 4.8.0.742.1、使用openCV获取图片
使用openCV调用电脑的摄像头拍摄图片用于训练。这里每人拍了600张。
这里可以改为每一秒或者半秒一次的方式抓拍,可以轻松点。
# coding:utf-8
import cv2
"""
########## 电脑摄像头拍摄训练用 ##########
"""
cap = cv2.VideoCapture(0) # 创建一个 VideoCapture 对象
flag = 1 # 设置一个标志,用来输出视频信息
num = 1 # 递增,用来保存文件名
while (cap.isOpened()): # 循环读取每一帧
ret_flag, Vshow = cap.read() # 返回两个参数,第一个是bool是否正常打开,第二个是照片数组,如果只设置一个则变成一个tumple包含bool和图片
cv2.imshow("Capture_Test", Vshow) # 窗口显示,显示名为 Capture_Test
k = cv2.waitKey(1) & 0xFF # 每帧数据延时 1ms,延时不能为 0,否则读取的结果会是静态帧
if k == ord('s'): # 若检测到按键 ‘s’,打印字符串
cv2.imwrite("D:/faceImages/wjw/{}.jpg".format(num), Vshow)
print("success to save" + str(num) + ".jpg")
print("-------------------------")
num += 1
elif k == ord('q'): # 若检测到按键 ‘q’,退出
break
cap.release() # 释放摄像头
cv2.destroyAllWindows() # 删除建立的全部窗口
2.2、人脸检测并灰度化处理
将图片中人脸部分框出并进行截取,然后进行灰度化处理,灰度人脸照片才能用于后面的训练和测试。
注:这里的人脸框获取的算法比较差,如果图片角度不好或者较为模糊,会导致识别率不高,只有大概80%的准确率,后面有空再找找更好的,为了后面训练和测试需要,只能先把识别正确的人脸copy几份,凑集600份。。。
其中的 haarcascade_frontalface_default.xml 文件下载地址:
https://github.com/opencv/opencv/blob/master/data/haarcascades/haarcascade_frontalface_default.xml
import cv2
import os, re
"""
########## 图片截取人脸并进行灰度化处理 ##########
"""
# 照片所在文件路径
path = 'D:/cnn/faceImages/wjw/'
# 获取整个文件图片路径
def getimgnames(path=path):
filenames = os.listdir(path)
imgnames = []
for i in filenames:
if re.findall('^\d+\.jpg$', i) != []:
imgnames.append(i)
return imgnames
imgnames = getimgnames(path)
num = 1
for image_path in imgnames:
img = cv2.imread(path + image_path)
# 灰度化
gary = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 得到人脸框
face_cascade = cv2.CascadeClassifier("../data/haarcascade_frontalface_default.xml")
# image:待处理的图像
# scaleFactor:检测框的最小尺寸
# minNeighbors:相当于检测的阈值,过小会出现误检现象,即把一些其他元素误判成人脸,过大可能会检测不到目标
#
# 函数输出的是检测到目标图片中的每个人脸的x、y坐标值和宽度、高度。
face_rect = face_cascade.detectMultiScale(gary, scaleFactor=1.2, minNeighbors=5)
if len(face_rect) != 0:
face_position = face_rect[0]
face_position = face_position.astype(int)
cv2.rectangle(img, (face_position[0], face_position[1]), (face_position[0]+face_position[2], face_position[1]+face_position[3]), (0, 255, 0), 2)
face = gary[face_position[1]:(face_position[1]+face_position[3]),
face_position[0]:(face_position[0]+face_position[2]), ]
# 图片保存
cv2.imwrite("D:/cnn/faceImageGray/wjw/{}.jpg".format(num), face)
num = num + 1
else:
print('第', num, '张图无法识别')
num = num + 1
2.3、划分数据为训练集和测试集
将图片数据整理成numpy中的ndarray格式,并将整理后的数据按8:2划分成训练集和测试集。
import numpy as np
import cv2
import os, re
class ImTrans:
"""
获取整个文件图片路径
"""
def __init__(self, path='faceImageGray/wjw/'):
self.path = path
def getimgnames(self):
filenames = os.listdir(self.path)
imgnames = []
for i in filenames:
if re.findall('^\d+\.jpg$', i) != []:
imgnames.append(i)
return imgnames
def getimgdata(self):
imgnames = self.getimgnames()
n = len(imgnames)
data = np.zeros([n, 32, 32, 3], dtype='float32')
for i in range(n):
img = cv2.imread(self.path + imgnames[i])
da_new = cv2.resize(img, (32, 32))
da_new = da_new[:, :, :] / 255
data[i, :, :, :] = da_new
return data
# 获取faceImageGray文件中的文件名
paths = os.listdir('D:/cnn/faceImageGray/')
# 将多个数据进行整合
Data = np.zeros([6000, 32, 32, 3], dtype='float32')
Labels = np.zeros([6000], dtype='float32')
k = 0
for i in paths:
imgtrans = ImTrans(path='D:/cnn/faceImageGray/' + i + '/')
data = imgtrans.getimgdata()
Data[k * 600:(k + 1) * 600, :, :, :] = data
Labels[k * 600:(k + 1) * 600] = k
k = k + 1
# 划分数据集
print('原始数据集数据的形状为:', Data.shape)
print('原始数据集标签的形状为:', len(Labels))
from sklearn.model_selection import train_test_split
data_train, data_test, labels_train, labels_test = train_test_split(Data, Labels, test_size=0.2, random_state=42)
print('训练集数据的形状为:', data_train.shape)
print('训练集标签的形状为:', len(labels_train))
print('测试集数据的形状为:', data_test.shape)
print('测试集标签的形状为:', len(labels_test))
np.save("D:/cnn/data/data_train.npy", data_train)
np.save("D:/cnn/data/labels_train.npy", labels_train)
np.save("D:/cnn/data/data_test.npy", data_test)
np.save("D:/cnn/data/labels_test.npy", labels_test)
结果:
原始数据集数据的形状为: (6000, 32, 32, 3)
原始数据集标签的形状为: 6000
训练集数据的形状为: (4800, 32, 32, 3)
训练集标签的形状为: 4800
测试集数据的形状为: (1200, 32, 32, 3)
测试集标签的形状为: 12002.4、模型搭建和测试
将训练集样本放入模型进行训练,用测试集样本进行模型性能测试,并将训练好的模型进行保存,模型文件夹命名为model”。
import numpy as np
# import tensorflow as tf
# 用tensorflow2运行tensorflow1的代码
import tensorflow._api.v2.compat.v1 as tf
# 去掉tensorflow2的特性,防止报错
tf.disable_v2_behavior()
tf.reset_default_graph() # 清除变量
# 数据读入
data_train = np.float32(np.load("D:/cnn/data/data_train.npy"))
labels_train = np.load("D:/cnn/data/labels_train.npy")
data_test = np.float32(np.load("D:/cnn/data/data_test.npy"))
labels_test = np.load("D:/cnn/data/labels_test.npy")
# 独热化
labels_train, labels_test = tf.one_hot(labels_train, 10), tf.one_hot(labels_test, 10) #
# tf.disable_eager_execution()
x_data = tf.placeholder(tf.float32, [None, 32, 32, 3], name='x_data')
y_data = tf.placeholder(tf.float32, [None, 10])
# ====数据卷积--池化--卷积--池化====
w1 = tf.Variable(tf.random_normal([3, 3, 3, 32], stddev=0.01)) # 卷积核/filter的初始权值
w2 = tf.Variable(tf.random_normal([3, 3, 32, 50], stddev=0.01)) # 卷积核/filter的初始权值
conv1 = tf.nn.conv2d(x_data, w1, strides=[1, 1, 1, 1], padding='SAME') # 卷积
conv1 = tf.nn.relu(conv1)
pool1 = tf.nn.max_pool(conv1, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='VALID') # 池化
conv2 = tf.nn.conv2d(pool1, w2, strides=[1, 1, 1, 1], padding='VALID') # 卷积
conv2 = tf.nn.relu(conv2)
pool2 = tf.nn.max_pool(conv2, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='VALID') # 池化
data = tf.reshape(pool2, [-1, 2450])
# =====BP神经网络=====
global_step = tf.Variable(0, trainable=False) # 迭代的速率变化
learning_rate = tf.train.exponential_decay(0.3, global_step, 100, 0.95)
w3 = tf.Variable(tf.random_normal([2450, 60], stddev=0.1)) # 隐层权值
bias1 = tf.Variable(tf.constant(0.1), [60]) # 隐层阈值/偏置项
w4 = tf.Variable(tf.random_normal([60, 10], stddev=0.1)) # 输出层权值
bias2 = tf.Variable(tf.constant(0.1), [10]) # 输出层阈值/偏置项
# 输入层到隐层
H = tf.sigmoid(tf.matmul(data, w3) + bias1)
H = tf.nn.relu(H)
# 隐层到输出层
y = tf.nn.softmax(tf.matmul(H, w4) + bias2, name='y')
cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_data * tf.log(y), axis=1)) # 交叉熵
optimizer = tf.train.GradientDescentOptimizer(learning_rate) # 梯度下降法优化器
train = optimizer.minimize(cross_entropy, global_step=global_step) # 利用优化器对交叉熵进行优化
saver = tf.train.Saver() # 保存
init = tf.global_variables_initializer()
# ===运行会话====
x_s = np.zeros([400, 32, 32, 3], dtype='float32')
y_s = np.zeros([400, 10], dtype='float32')
with tf.Session() as sess:
sess.run(init)
labels_train, labels_test = sess.run([labels_train, labels_test])
for i in range(2001):
k = 0
if i % 100 == 0: # 每训练100轮打印一次训练集样本的预测精度
pre = tf.equal(tf.argmax(y, axis=1), tf.argmax(y_data, axis=1))
acc = sess.run(pre, feed_dict={x_data: data_test, y_data: labels_test})
print(i, 'acc: ', sum(acc) / len(acc), sess.run(learning_rate))
print(sess.run(cross_entropy, feed_dict={x_data: x_s, y_data: y_s})) # 交叉熵
for j in np.random.randint(0, 4799, size=[400]):
x_s[k] = data_train[j, :]
y_s[k] = labels_train[j]
k = k + 1
sess.run(train, feed_dict={x_data: x_s, y_data: y_s})
saver.save(sess, 'D:/cnn/model/train_model')
# 准确率为99.5%
结果:

生成模型:

2.5、模型应用
模型对实时抓拍到的人脸进行识别。
import numpy as np
# import tensorflow as tf
# 用tensorflow2运行tensorflow1的代码
import tensorflow._api.v2.compat.v1 as tf
import cv2
"""
########## 模型应用 ############
"""
# 去掉tensorflow2的特性,防止报错
tf.disable_v2_behavior()
cap = cv2.VideoCapture(0) # 创建一个 VideoCapture 对象
# 会话读入
sess = tf.Session()
saver = tf.train.import_meta_graph('D:/cnn/model/train_model.meta')
saver.restore(sess, tf.train.latest_checkpoint('D:/cnn/model/'))
graph = tf.get_default_graph()
x_new = graph.get_tensor_by_name('x_data:0')
y_new = graph.get_tensor_by_name('y:0')
Name = ['daiyejun', 'gaohongbin', 'heziwei', 'lgh', 'ljh', 'lzy', 'pcm', 'renhuikang', 'wjw', 'wy']
while (cap.isOpened()): # 循环读取每一帧
# 返回两个参数,第一个是bool是否正常打开,第二个是照片数组,如果只设置一个则变成一个tuple包含bool和图片
ret_flag, Vshow = cap.read()
# 得到人脸框
face_cascade = cv2.CascadeClassifier("../data/haarcascade_frontalface_default.xml")
# image:待处理的图像
# scaleFactor:检测框的最小尺寸
# minNeighbors:相当于检测的阈值,过小会出现误检现象,即把一些其他元素误判成人脸,过大可能会检测不到目标
#
# 函数输出的是检测到目标图片中的每个人脸的x、y坐标值和宽度、高度。
face_rect = face_cascade.detectMultiScale(Vshow, scaleFactor=1.2, minNeighbors=5)
# bounding_boxes中第一个为所需的人脸
if len(face_rect) != 0: # and bounding_boxes[0][0]>0 and bounding_boxes[0][1]>0:
face_position = face_rect[0]
face_position = face_position.astype(int)
cv2.rectangle(Vshow, (face_position[0], face_position[1]), (face_position[0]+face_position[2], face_position[1]+face_position[3]), (0, 255, 0), 2)
crop = Vshow[face_position[1]:(face_position[1]+face_position[3]),
face_position[0]:(face_position[0]+face_position[2]), ]
gary = cv2.cvtColor(crop, cv2.COLOR_BGR2GRAY)
da_new = cv2.resize(crop, (32, 32))
da_new = da_new / 255
data = np.reshape(da_new, [1, 32, 32, 3])
pre = sess.run(y_new, feed_dict={x_new: data})
acc = np.max(pre)
num = np.argmax(pre) # 循序
font = cv2.FONT_HERSHEY_SIMPLEX # 字体
if acc > 0.8:
cv2.putText(Vshow, Name[num] + '%.4f' % acc, (50, 300), font, 1.2, (255, 255, 255), 2)
else:
cv2.putText(Vshow, 'unknow', (50, 300), font, 1.2, (255, 255, 255), 2)
cv2.imshow("Capture_Test", Vshow) # 窗口显示,显示名为 Capture_Test
k = cv2.waitKey(1) & 0xFF # 每帧数据延时 1ms,延时不能为 0,否则读取的结果会是静态帧
if k == 27: # 若检测到按键 ‘esc’,退出
break
cap.release() # 释放摄像头
sess.close()
cv2.destroyAllWindows() # 删除建立的全部窗口
结果展示:

3、总结
看了别人的文章,觉得很不错,所以在这里就只记录一些重要的点。文章主要做了人脸识别的代码实现。
缺点:需要的训练集太多了,在实际的使用中,没有人会让你采集那么多的照片。
优化:支付宝之类的人脸识别只需要眨眼和左右摇头的动作就可以实现人脸的高准确率识别,是怎么做到的呢?用到了计算机图像处理技术与生物统计学的原理。
最后,觉得有帮助或者有点收获的话,帮忙点个赞吧!















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









