







目录
0 章节目标
- TiDB Server架构
- TiDB Server 作用
- TiDB Server 的进程
- TiDB Server 的缓存
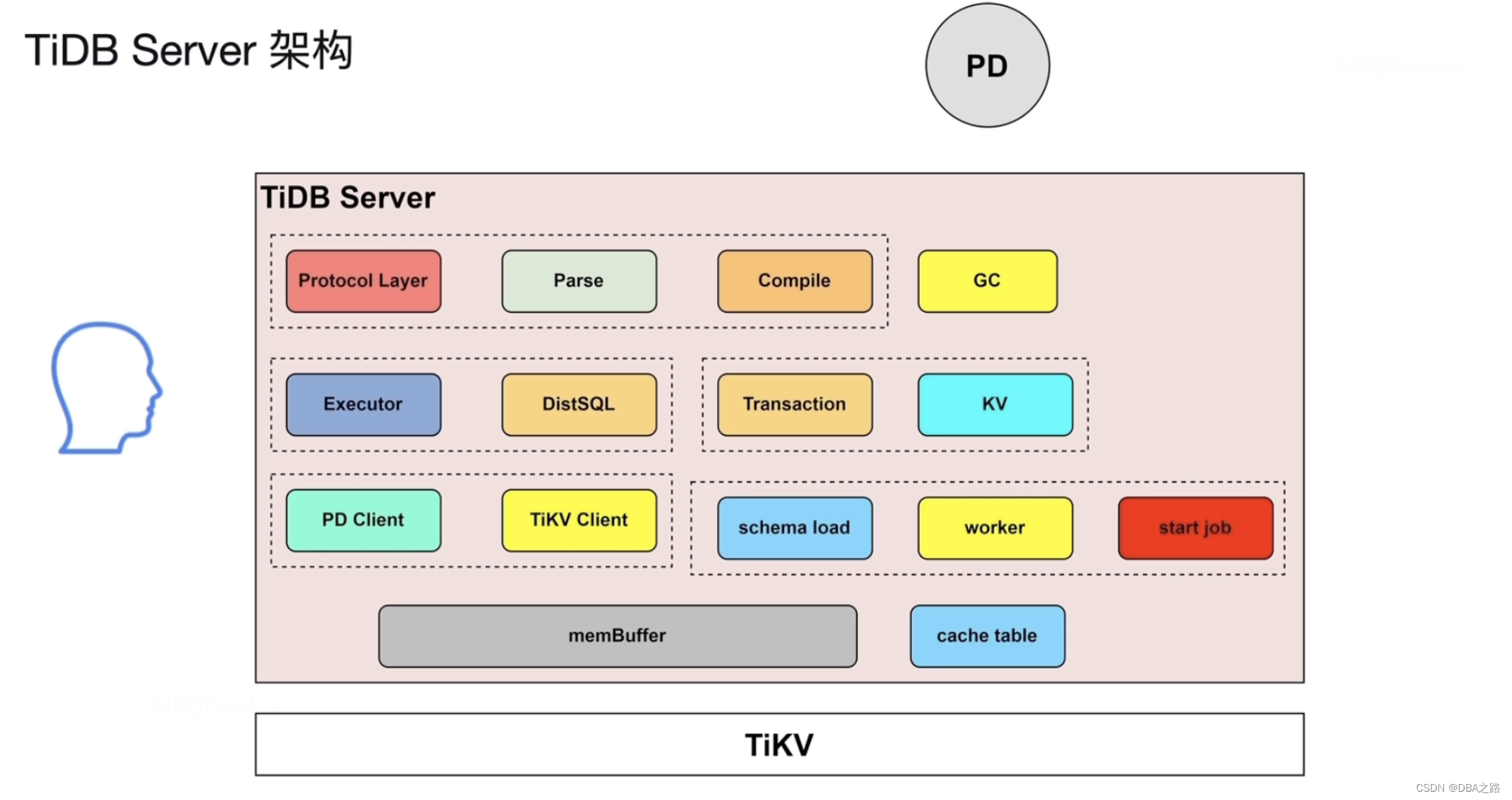
一 TiDB Server架构
-
TiDB Server:SQL 层,对外暴露 MySQL 协议的连接 endpoint,负责接受客户端的连接,执行 SQL 解析和优化,最终生成分布式执行计划。TiDB 层本身是无状态的,实践中可以启动多个 TiDB 实例,通过负载均衡组件(如 LVS、HAProxy 或 F5)对外提供统一的接入地址,客户端的连接可以均匀地分摊在多个 TiDB 实例上以达到负载均衡的效果。TiDB Server 本身并不存储数据,只是解析 SQL,将实际的数据读取请求转发给底层的存储节点 TiKV(或 TiFlash)。
核心线程:
- Protocal Layer /Parse/Compile线程 负责SQL语句的解析和编译SQL, 生成执行计划
- Execute 和 DistSQL 负责分批的执行SQL 的执行计划
- Transaction 和 KV 主要是事务相关
- PD Client 负责与PD 交互
- TIKV Client 负责与TIKV交互
- schema load / worker/ start job 负责 onlineDDL DDL不会阻塞读写
- memBuffer 缓存区 缓存读取的数据 元数据 连接的认证信息,统计信息等
二 TiDB Server 作用
- 处理客户端的连接 对应模块Protocal Layer
- SQL语句的解析和编译 对应 Parse/Compile
- 关系型数据与KV的转化对应
- SQL语句执行 对应 模块 Execute 和 DistSQL(范围查询,全表扫描,走索引的)和 KV (点查,根据主键 唯一索引直接找到数据)
- online DDL 对应 线程 schema load ,worker 和 start job
- 垃圾回收 MVCC的过期版本数据的回收
- 热点小表缓存v6.0 与模块 cache table
三 TiDB Server 的进程
1 SQL语句的解析和编译
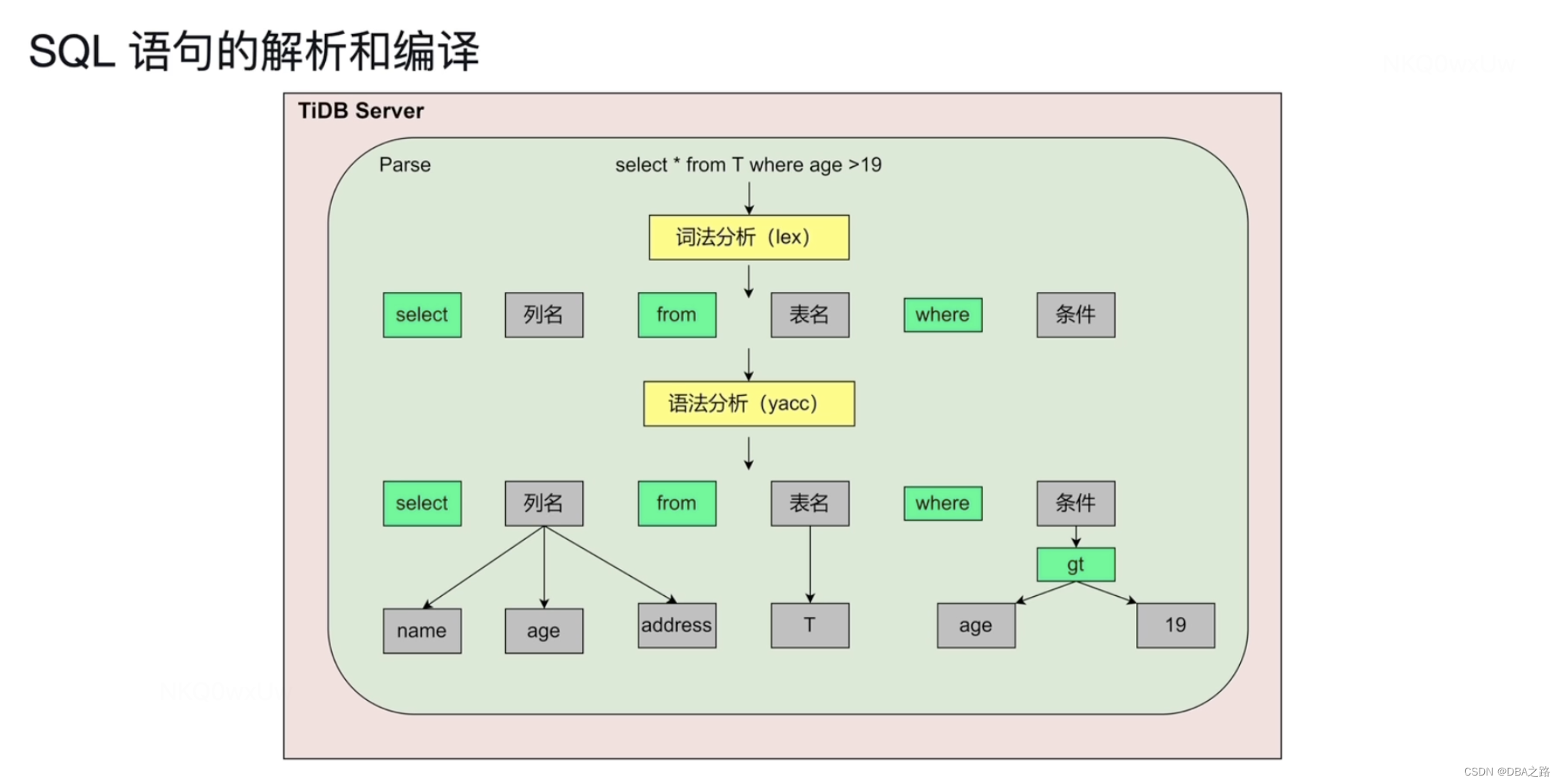
词法分析 lex
语法分析 yacc 生成树形结构
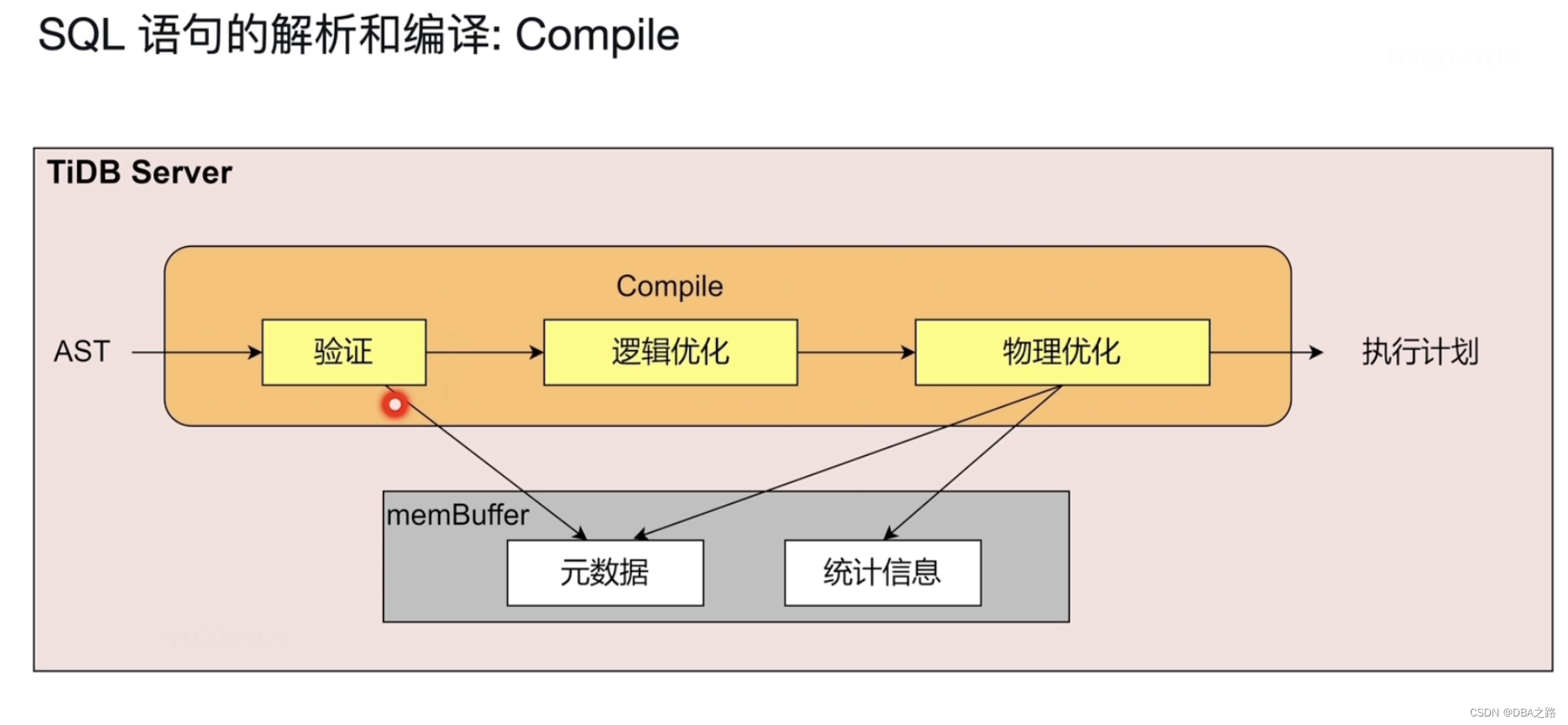
验证:表名列名是否存在等
逻辑优化 :
物理优化 :结合统计信息 选择全表扫描 或 索引扫描 ,如果选择索引 该使用哪个索引等
执行计划相当于导游图
2 关系型表与Key-Value的转换过程
更加详细的参考 :TiDB 数据库的计算 | PingCAP 文档中心
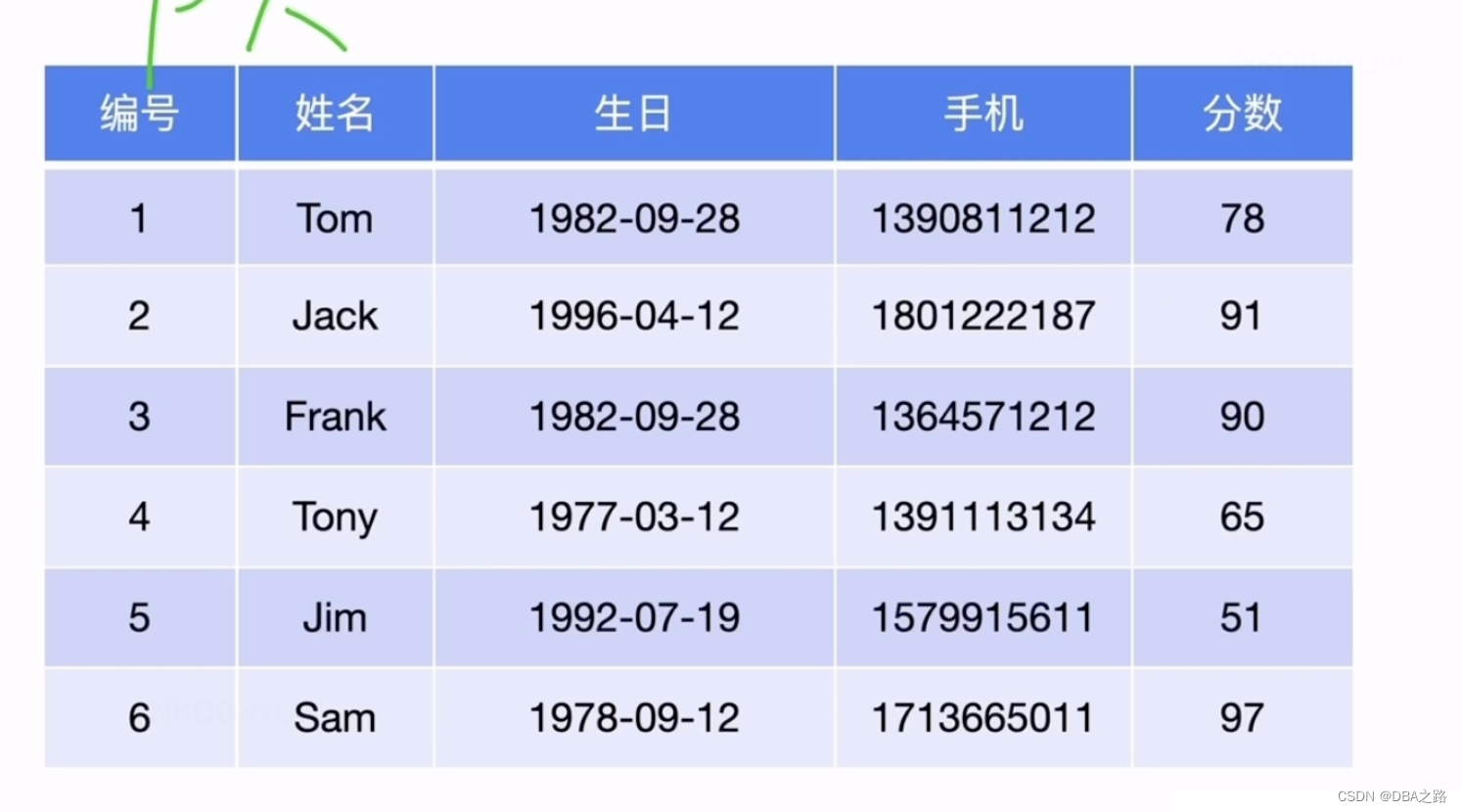
关系型数据库 例如Oracle或者MySQL 是以二维表的形式存储,如何转化为key-value的形式?
编号为主键 想转化为聚簇表
tableID_rowID 构成唯一 key
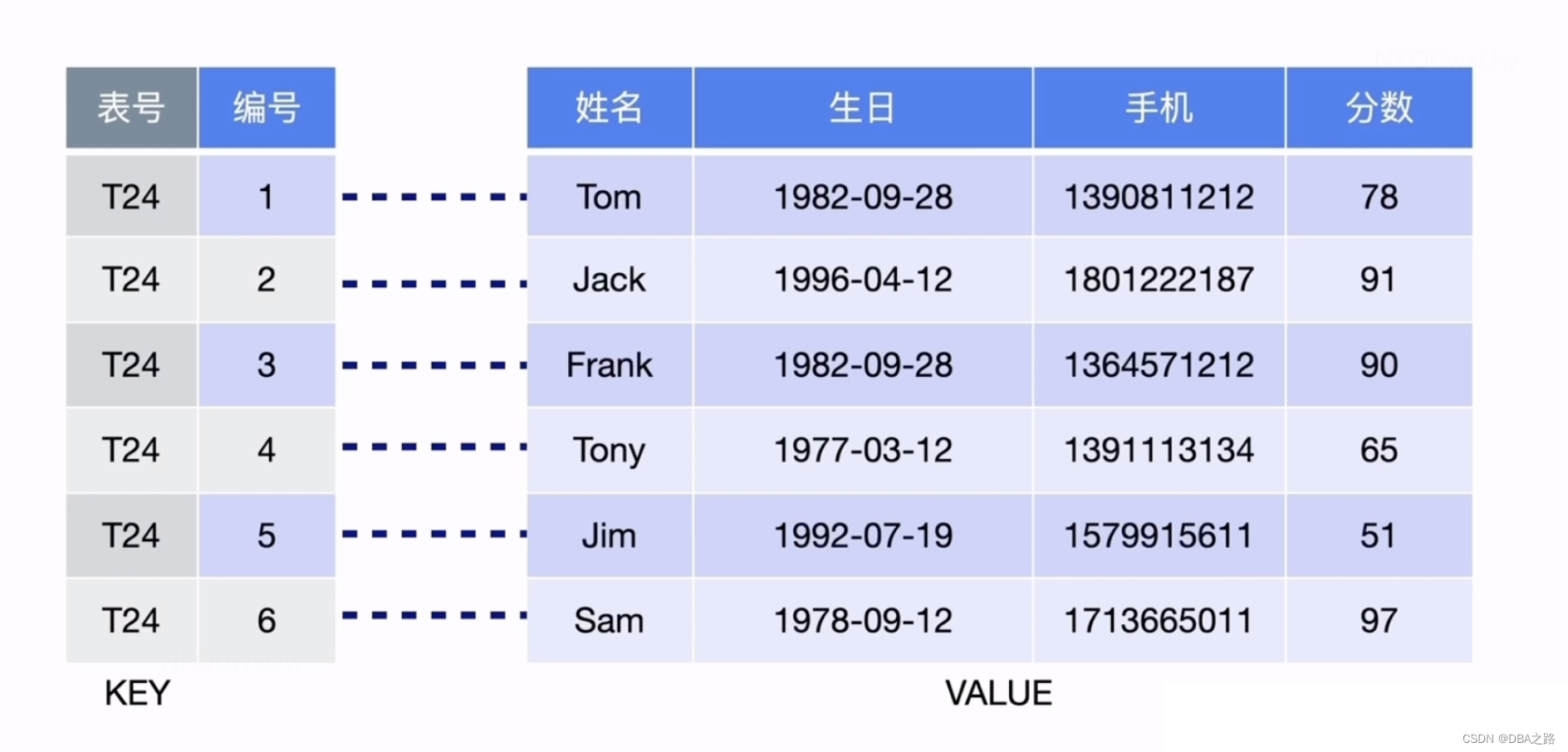
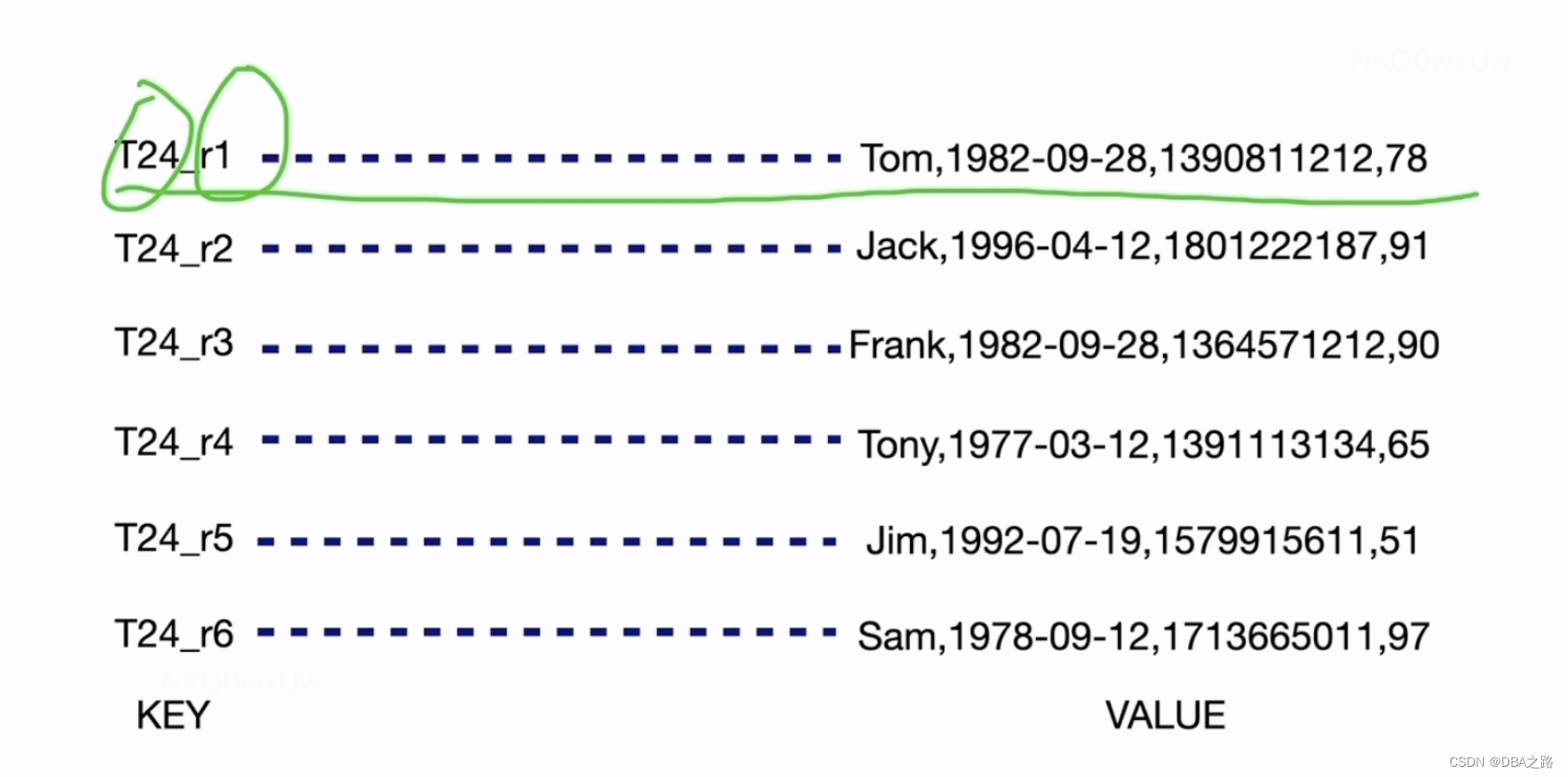
结合上图
表数据与 Key-Value 的映射关系
在关系型数据库中,一个表可能有很多列。要将一行中各列数据映射成一个 (Key, Value) 键值对,需要考虑如何构造 Key。首先,OLTP 场景下有大量针对单行或者多行的增、删、改、查等操作,要求数据库具备快速读取一行数据的能力。因此,对应的 Key 最好有一个唯一 ID(显示或隐式的 ID),以方便快速定位。其次,很多 OLAP 型查询需要进行全表扫描。如果能够将一个表中所有行的 Key 编码到一个区间内,就可以通过范围查询高效完成全表扫描的任务。
基于上述考虑,TiDB 中的表数据与 Key-Value 的映射关系作了如下设计:
- 为了保证同一个表的数据放在一起,方便查找,TiDB 会为每个表分配一个表 ID,用
TableID表示。表 ID 是一个整数,在整个集群内唯一。 - TiDB 会为表中每行数据分配一个行 ID,用
RowID表示。行 ID 也是一个整数,在表内唯一。对于行 ID,TiDB 做了一个小优化,如果某个表有整数型的主键,TiDB 会使用主键的值当做这一行数据的行 ID。
每行数据按照如下规则编码成 (Key, Value) 键值对:
Key: tablePrefix{TableID}_recordPrefixSep{RowID}
Value: [col1, col2, col3, col4]其中 tablePrefix 和 recordPrefixSep 都是特定的字符串常量,用于在 Key 空间内区分其他数据。其具体值在后面的小结中给出。
索引数据和 Key-Value 的映射关系
TiDB 同时支持主键和二级索引(包括唯一索引和非唯一索引)。与表数据映射方案类似,TiDB 为表中每个索引分配了一个索引 ID,用 IndexID 表示。
对于主键和唯一索引,需要根据键值快速定位到对应的 RowID,因此,按照如下规则编码成 (Key, Value) 键值对:
Key: tablePrefix{tableID}_indexPrefixSep{indexID}_indexedColumnsValue
Value: RowID对于不需要满足唯一性约束的普通二级索引,一个键值可能对应多行,需要根据键值范围查询对应的 RowID。因此,按照如下规则编码成 (Key, Value) 键值对:
Key: tablePrefix{TableID}_indexPrefixSep{IndexID}_indexedColumnsValue_{RowID}
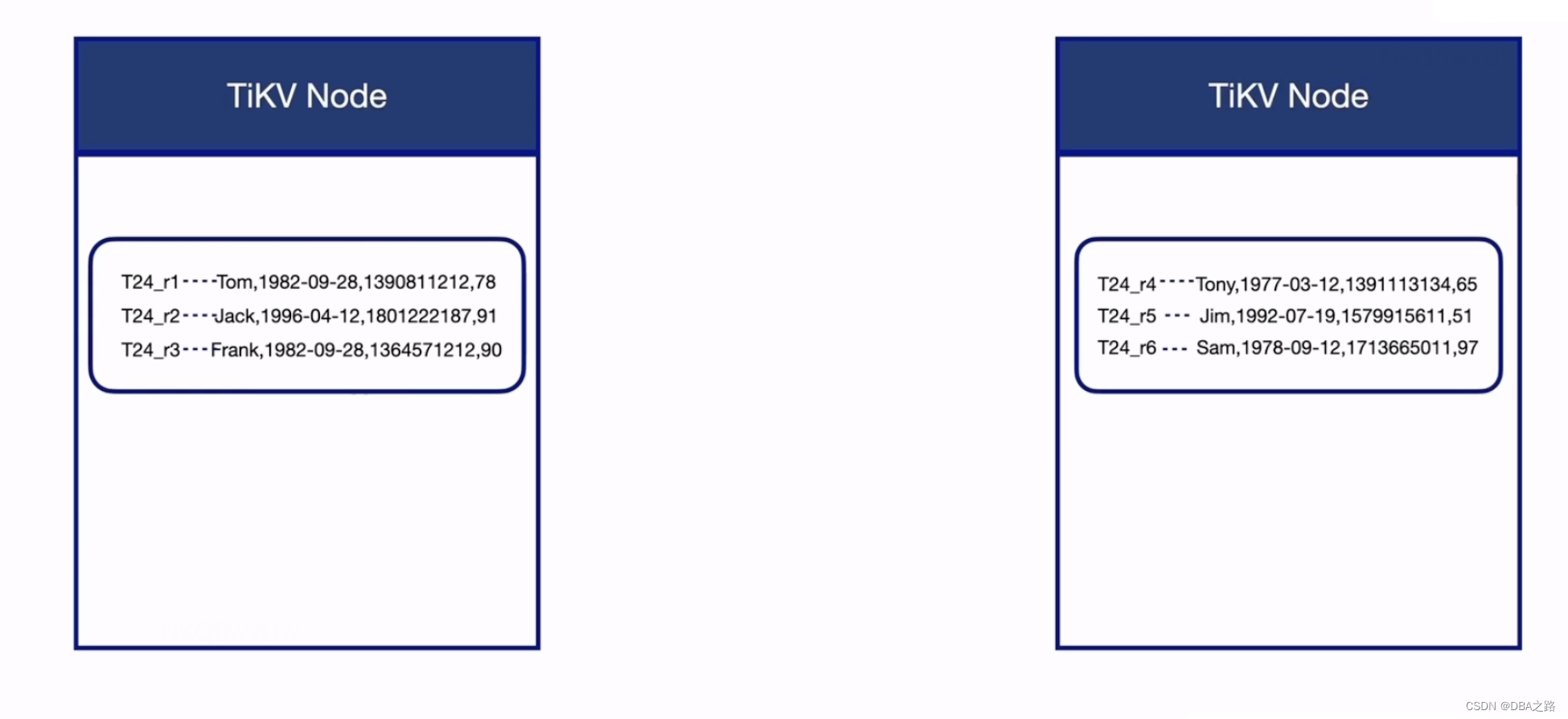
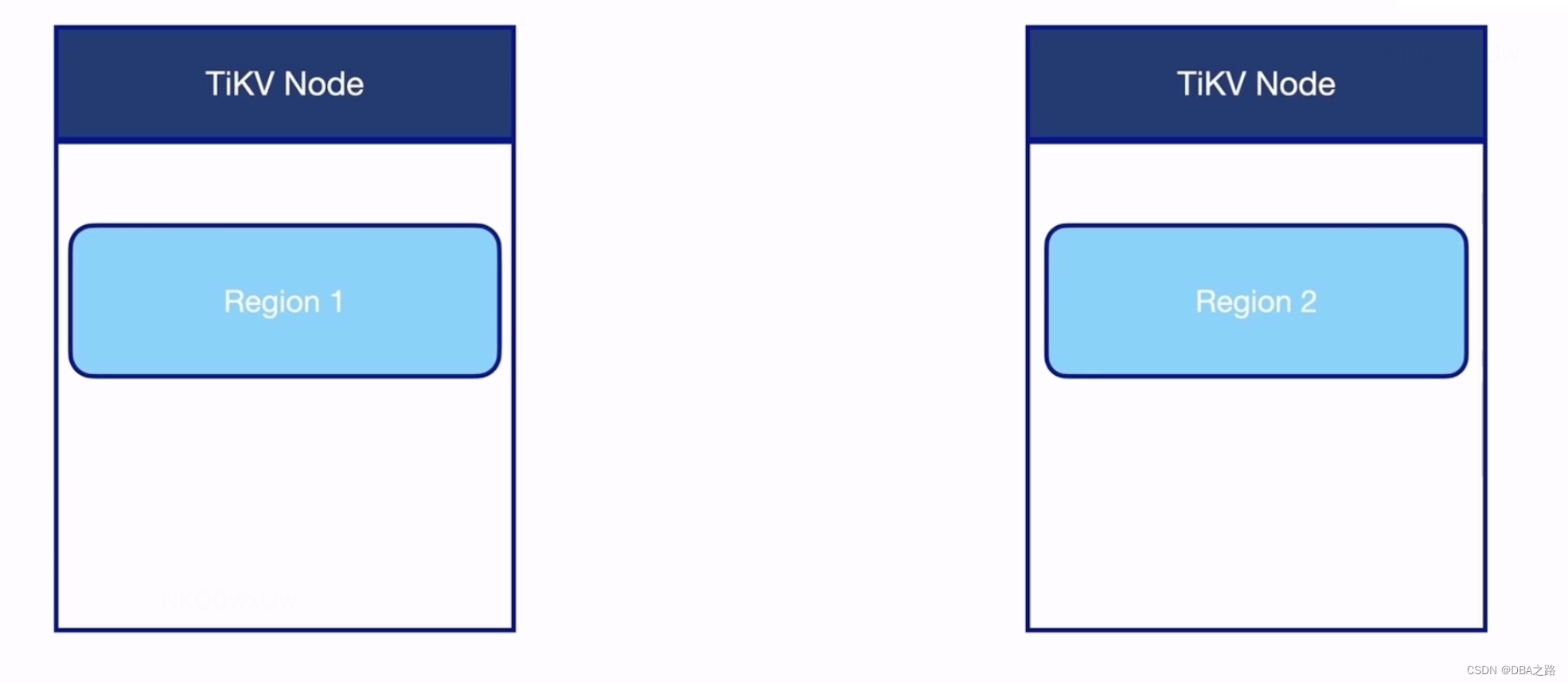
Value: nullRegion是kv的存储单位, 默认是96M 当达到144M的时候会进行split,即region分裂的过程,将一个region分裂成2个region
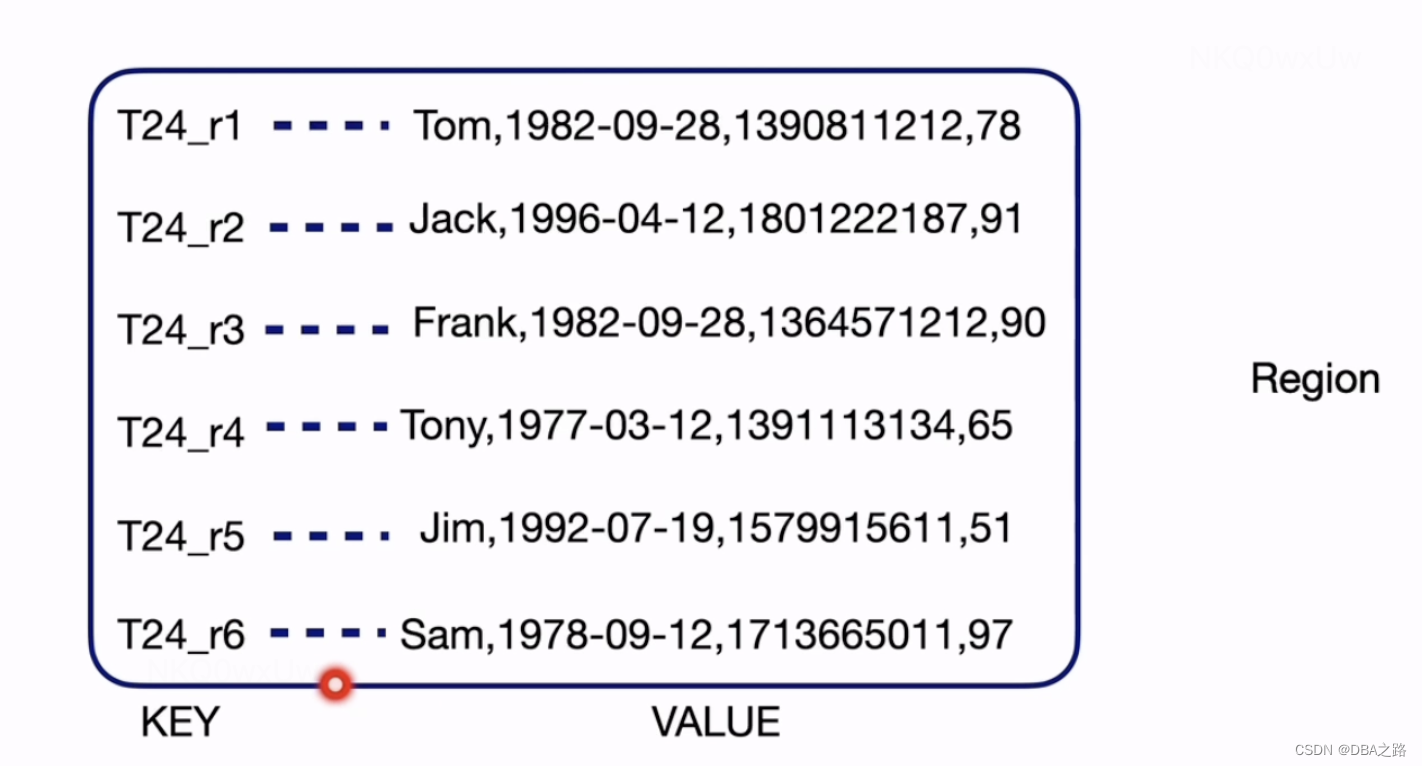
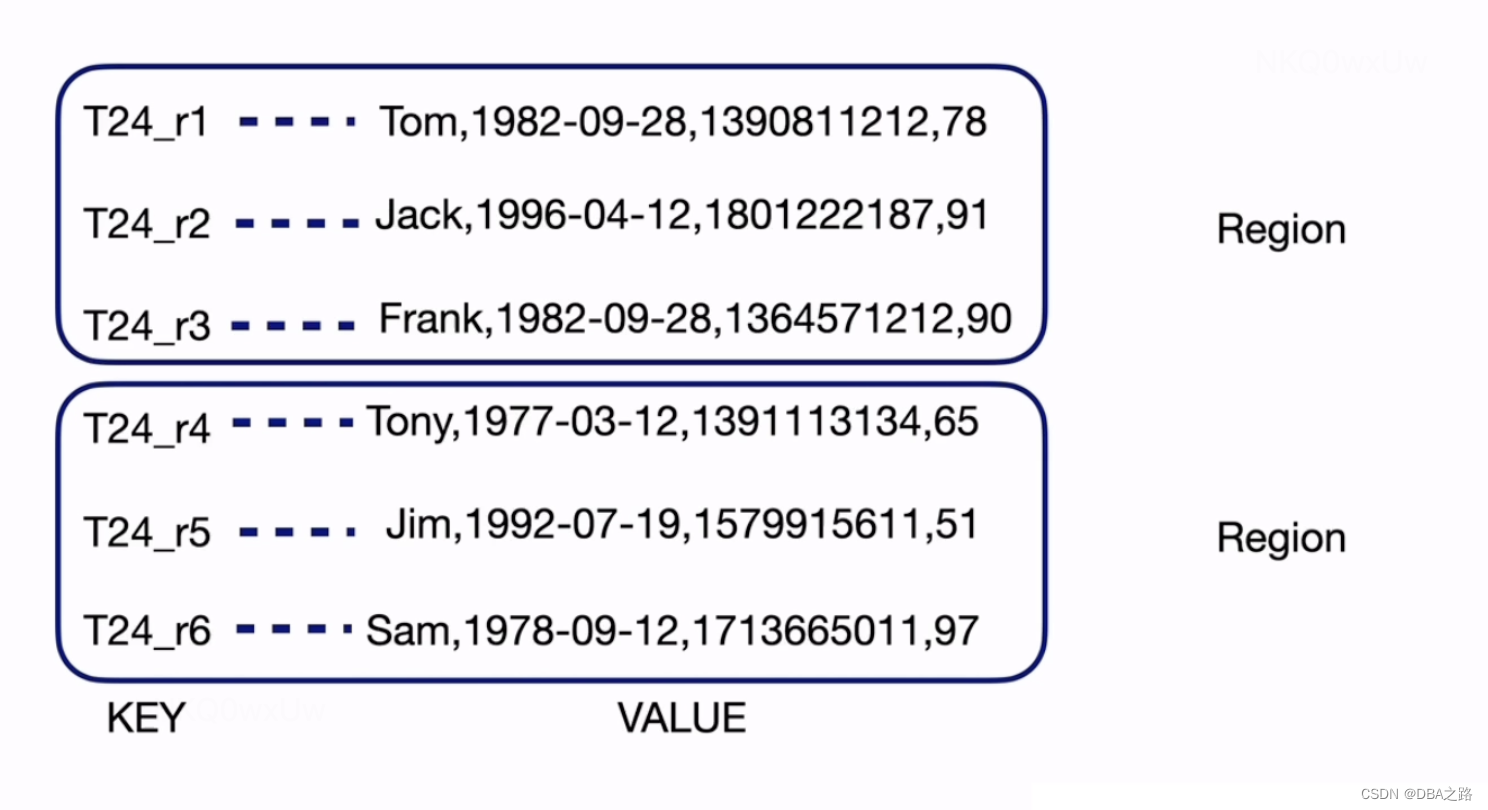
以region为单位 ,region 里面是kv的键值对 ,可以分布式存储在TiKV中
3 SQL读写相关模块
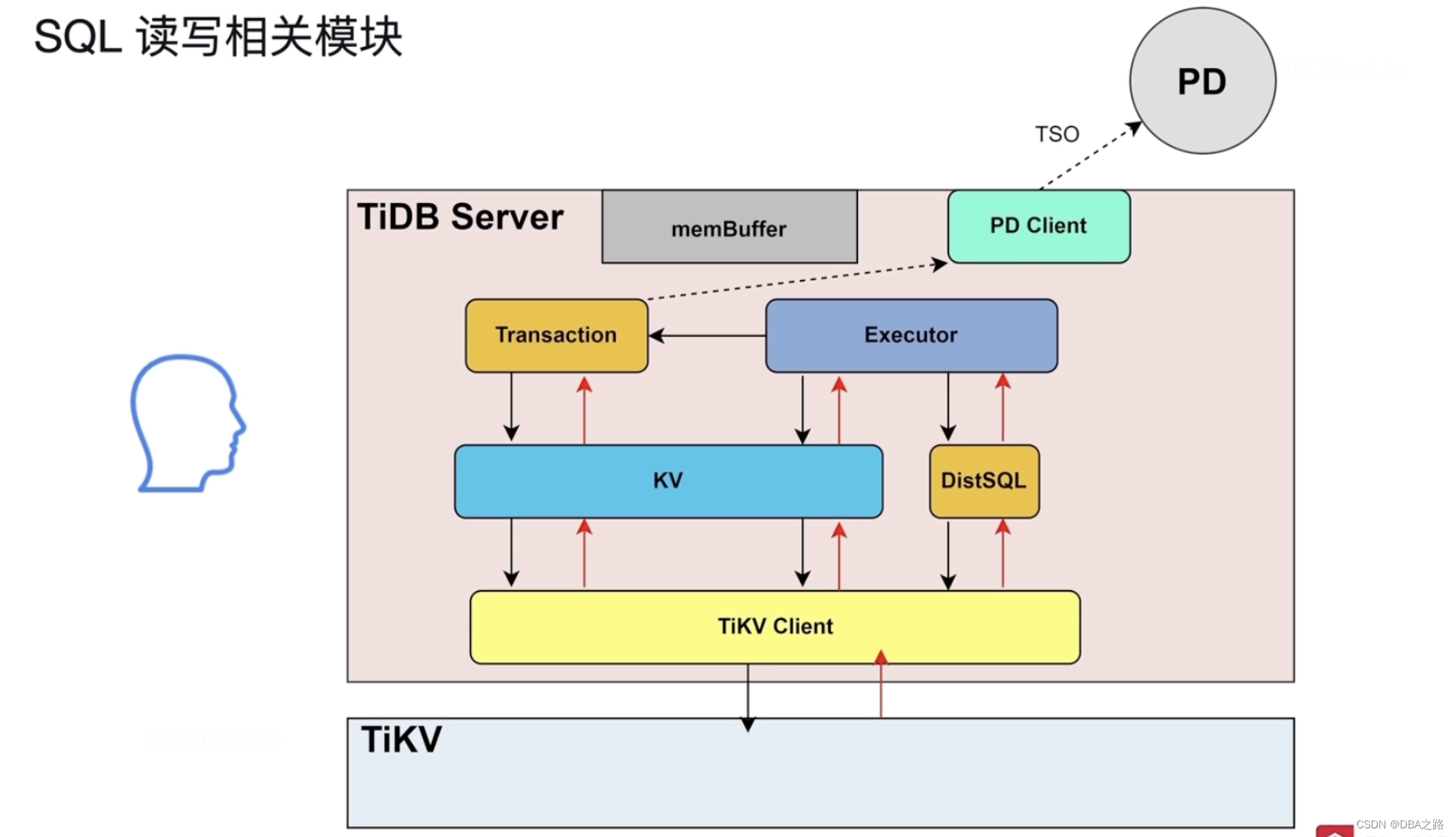
SQL执行计划分为两种 :
复杂查询 例如 范围查询 表连接 嵌套查询 为了避免复杂SQL和TiKV耦合太高 ,引入了DistSQL模块,把复杂SQL转换为对单表查询的SQL的组合。
点查 :Point 根据主键和唯一索引的等值查询 点查 使用到kv 模块
TIKV client 向tikv集群发送交互请求
Transaction 如果语句中有事务 二阶段提交 锁的管理
PD client transaction通过PDclient与 PD交互 获取TSO
4 在线DDL相关模块
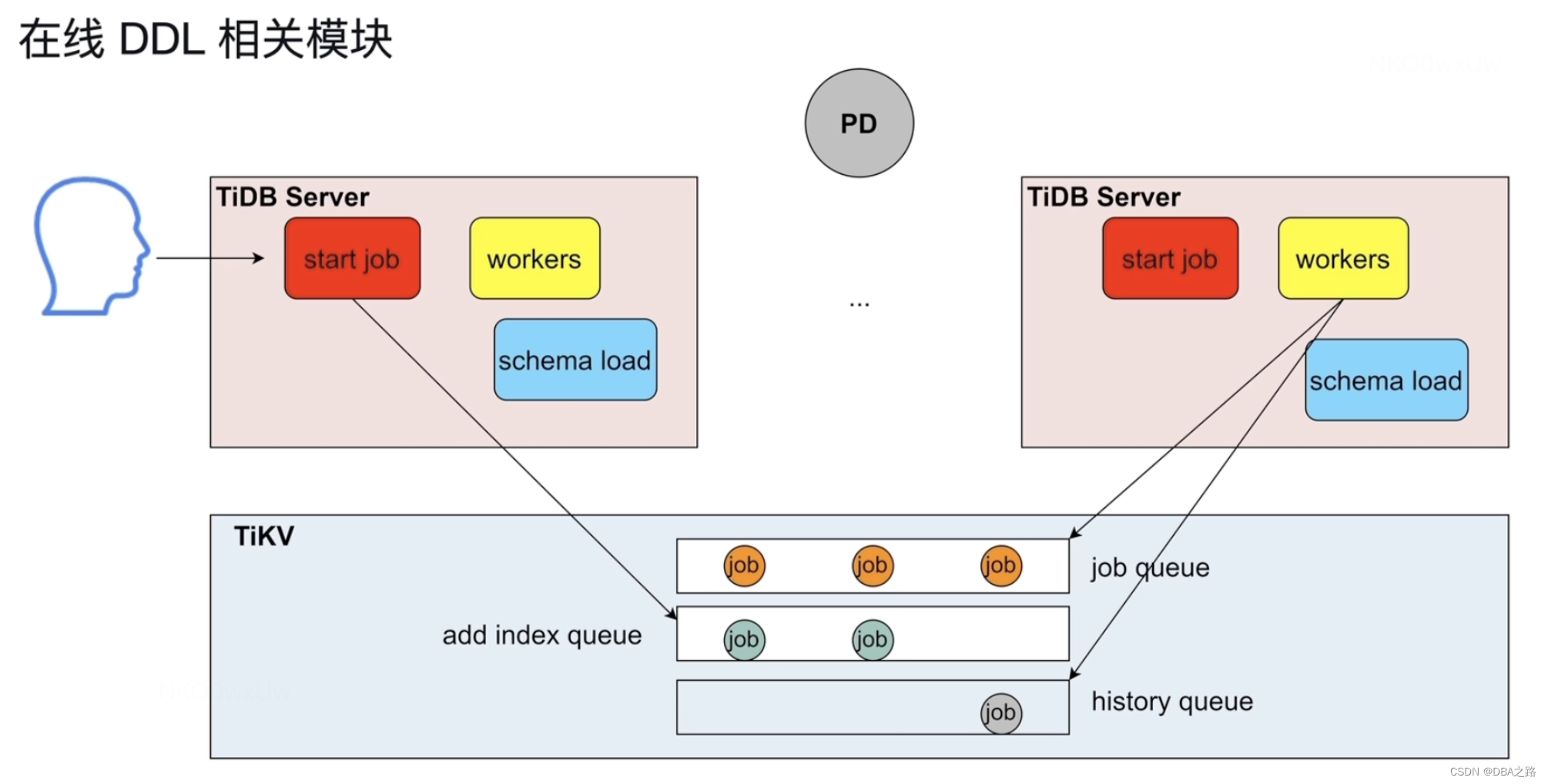
在集群中有多个TiDB Server .可能有多个DDL 发送到TiDB Server上。但是同一时刻只能有一个TiDB server在做DDL
用户发出DDL语句 由模块 start job 模块接受,然后放到job queue队列中。
在同一时刻 只有一个TiDB Server的角色为owner ,owner角色的 TiDB Server中从 job queue队列中取DDL,执行完成之后放到history queue中。
owner 角色有任期,并不是固定在一个Tidb Server上。
当成为owner后 ,schema load 会收集所有表的元数据。
队列放到TiKV上主要是为了持久化存储,一旦发生宕机断电可以防止数据丢失。
SQL执行流程中会详细介绍。
5 GC机制与相关模块
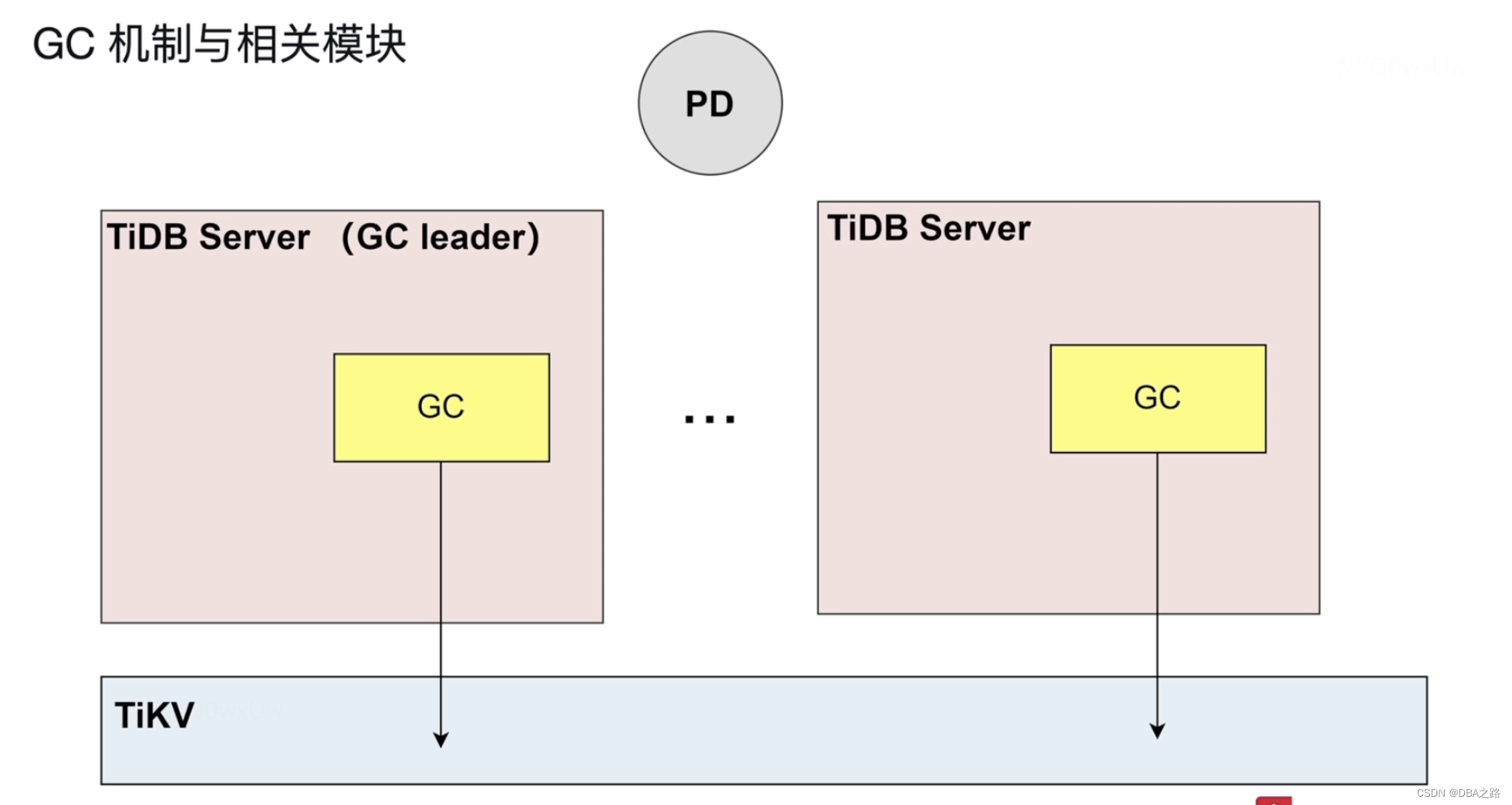
这里的GC是指数据库的GC ,并不是后端开发语言golang的GC 。
具体是 MVCC特性中的历史版本数据的回收
数据历史版本的作用:闪回,改错了想改回来可以用到。
历史版本数据可能会很多,对存储空间产生一定压力,所以要定期清理历史版本数据,这个过程就叫做GC。
会有一个 TiDB Server 被选举为 GC leader ,TiDB Server 会计算出一个时间点 ,比如现在是下午14点钟,计算出一个时间戳 叫做 safe point ,是上午10点钟。这4个小时的历史数据是保留的,但是10点之前的数据不会保留。每10分钟触发一次,找到过期的数据,看上面有没有锁信息,优先处理被drop 的表或索引的历史版本,然后处理delete 等
相关参数 GC_life_time = 10min
四 TiDB Server的缓存

1 TIDB的缓存组成
Tidb Server的缓存实际上使用 全部内存。
1 SQL结果 ,SQL结果不是从TiKV中获取到的吗?但是有一些表连接,子查询等 无法从某一个TiKV节点中把所有数据都获取到,可能需要的数据散落在多个TIKV节点,所以我需要一个TiDB Server 把 TiKV的数据汇聚起来,这些操作都是在 TiDB Server缓存中完成的。几张大表做join ,对缓存的占用是很大的
另外还有事务修改,如果事务很大 ,改的数据也要放到缓存中
2 线程缓存
3 元数据 统计信息 用户的用户密码
2 TiDB 缓存管理
tidb_mem_quota_query :控制每个SQL语句可以使用的缓存量
oom-action :当SQL使用的缓存超过tidb_mem_quota_query参数设置后 ,是中断返回error 还是记录日志。
在后面的故障分析中还会详细讲解
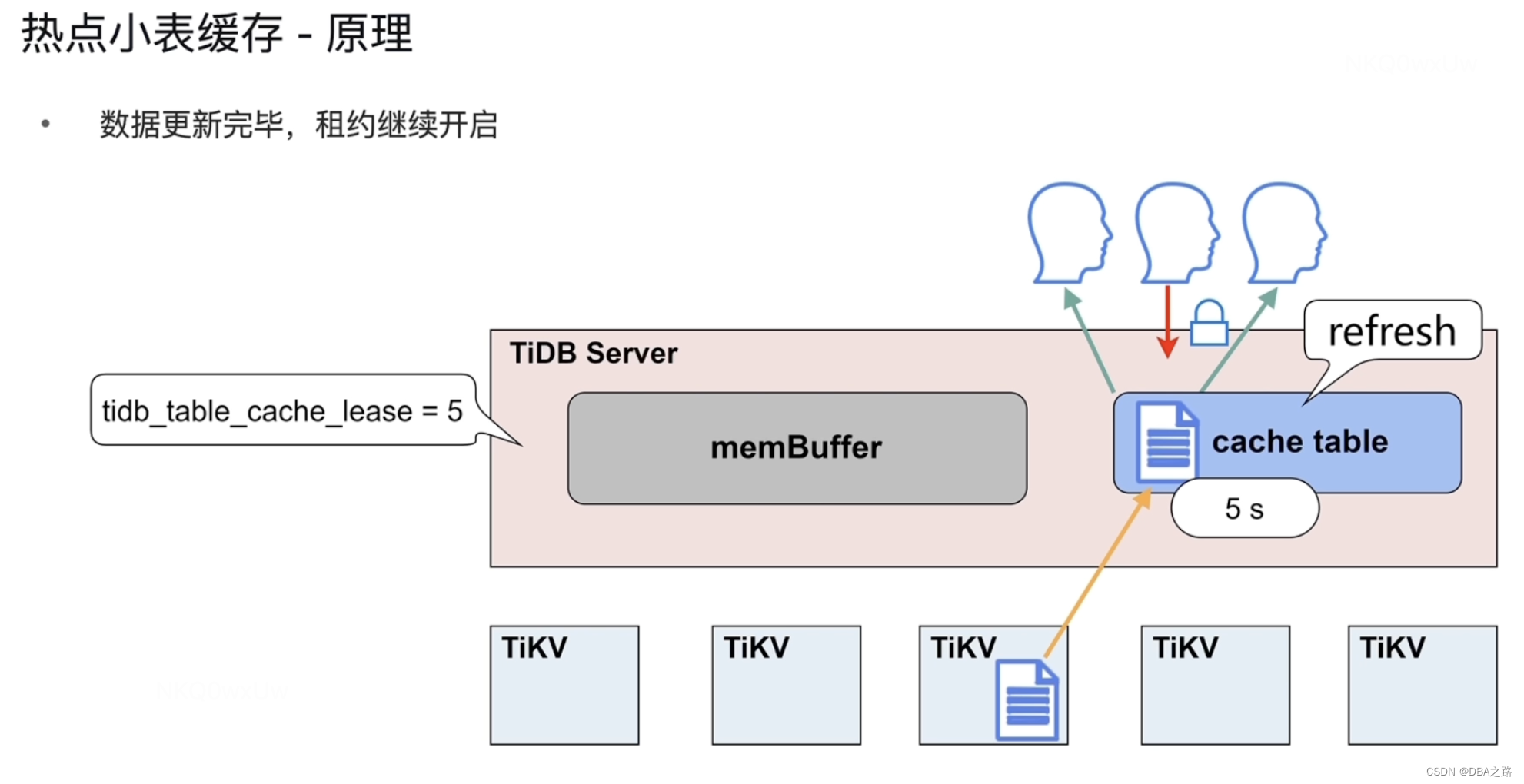
3 热点小表缓存
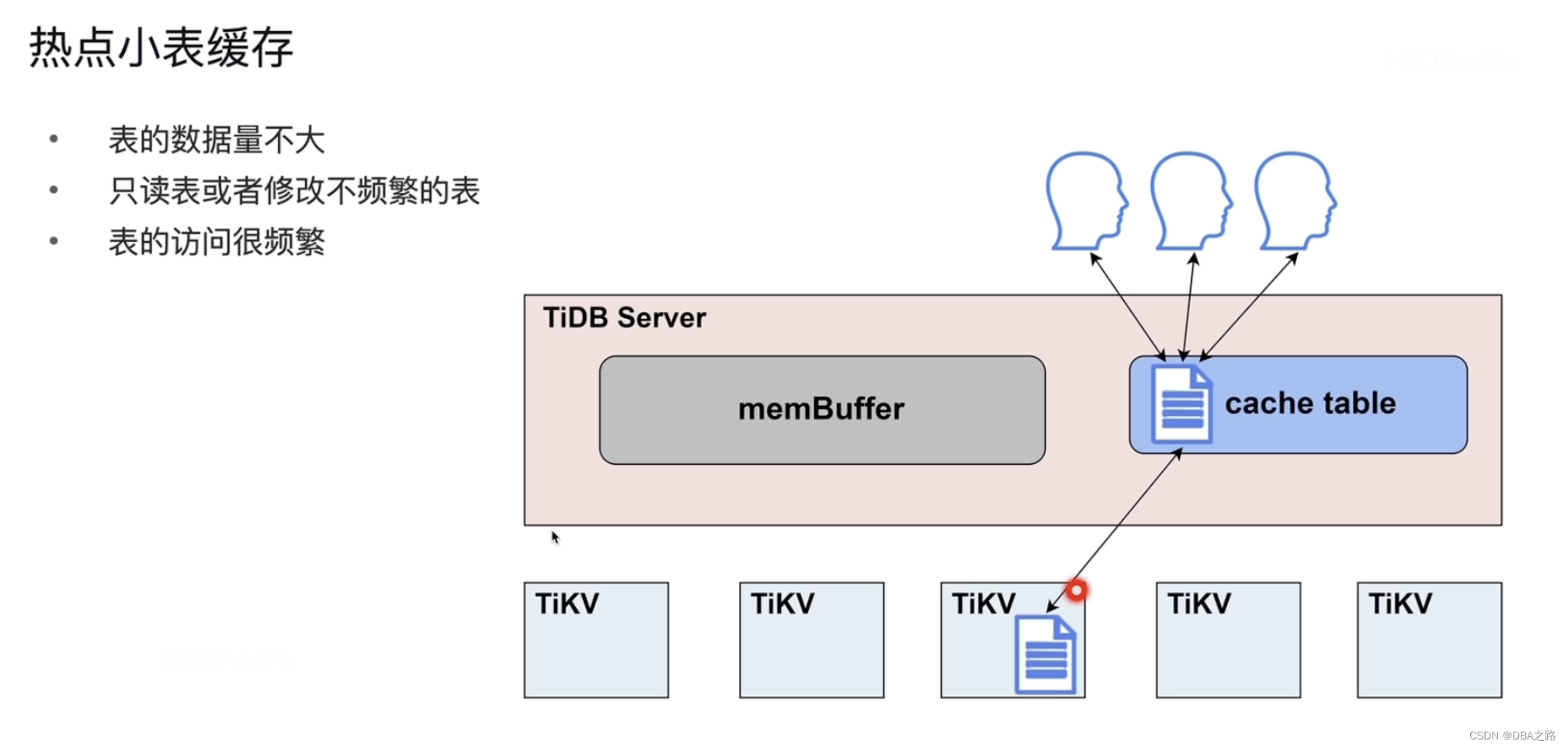
有一张表很小,不经常修改但读取特别频繁,这就是热点表。由于这个热点表很小,所以存在一个region上,这个region所在的TiKV负载就会很高。这就是典型的热点问题。
把这个表都读出来 直接缓存到 TiDB的缓存中,这是非常有效的一个解决热点表的方法。
如果这个表需要修改,这个表在内存中也有 在磁盘上也有,需要先修改哪个地方的数据。
热点小表听起来很简单 ,但是要解决缓存与磁盘不一致的问题。
4 热点小表缓存-原理
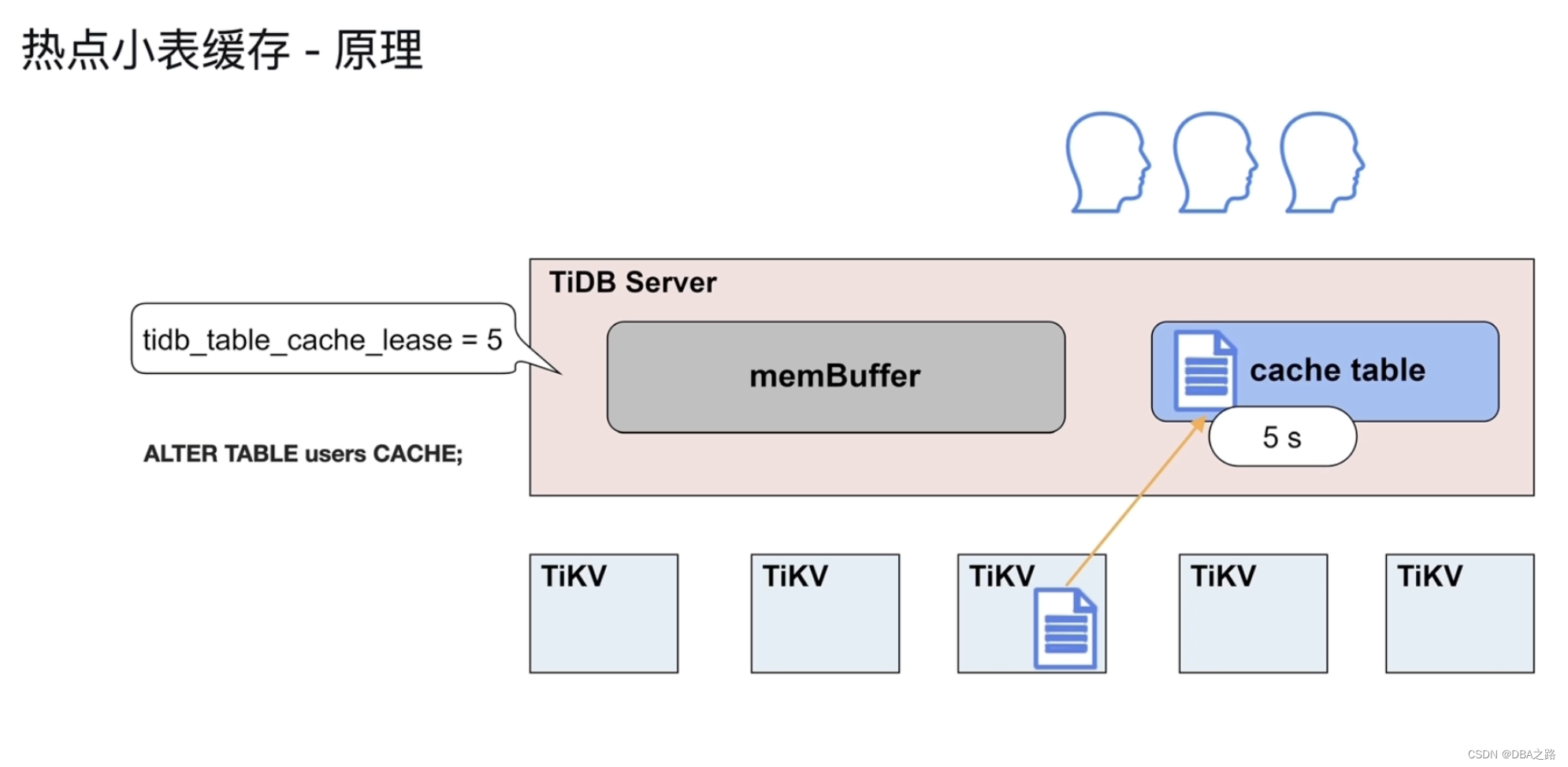
如何把表放到缓存中 使用
alter table table_name cache;
限制:这张表要小于 64M。
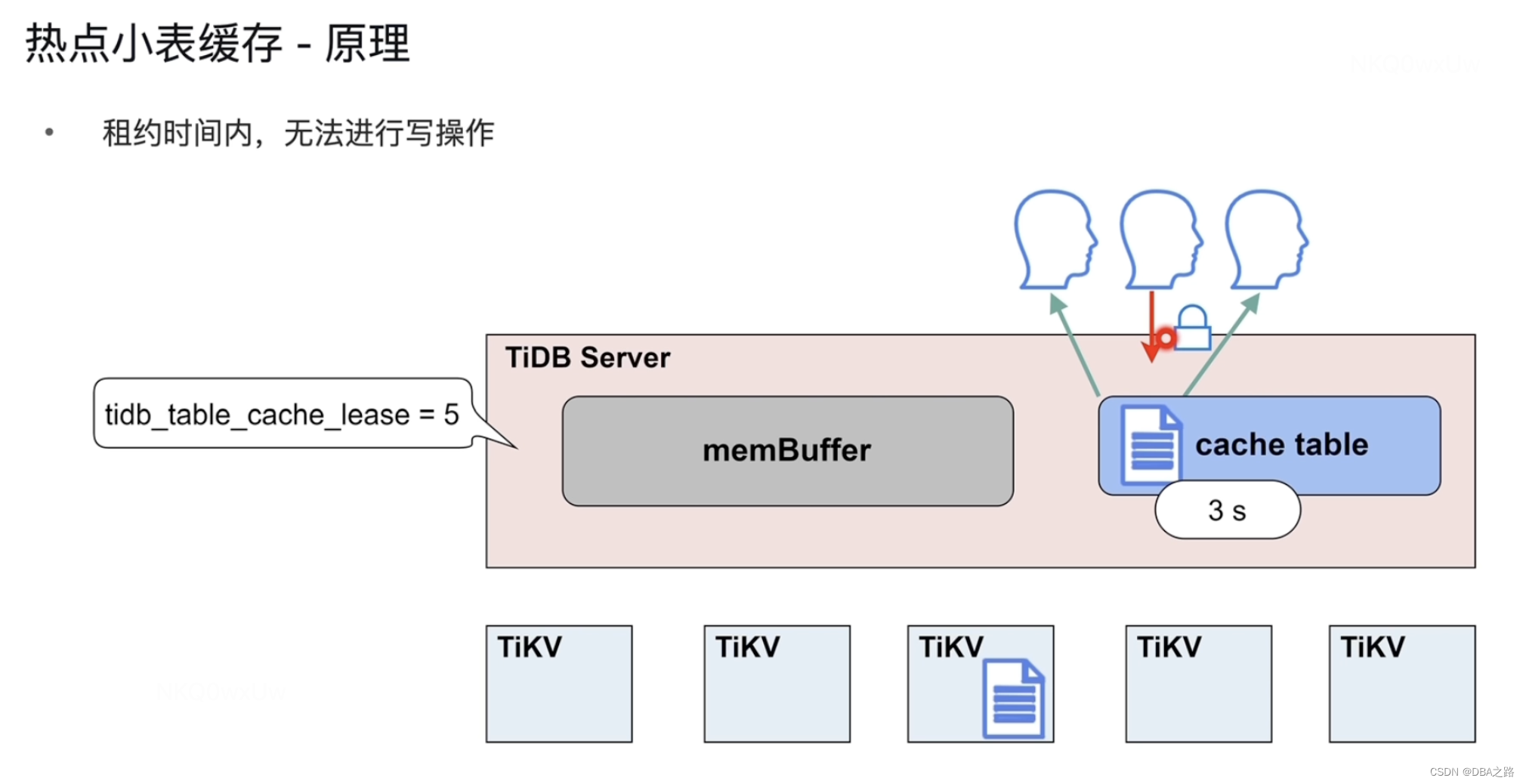
放进去后如何保证数据一致 tidb_table_cache_lease = 5 缓存的租约。这个参数模式5秒,这个小表到了缓存中有5秒的租约,在这5秒内可以读 ,但是不能写,阻塞了,要等待租约到期。



















 448
448











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











