







目录
.go/cmd/orchestrator/main() - 函数入口
ReadTopologyInstanceBufferable
last_attempted_check,last_check ,last_seen如何更新的
last_attempted_check:最后一次尝试检查该该实例的时间
DiscoverInstance(instanceKey inst.InstanceKey)
前言
Orchestrator最重要的功能之一是拓扑结构发现,相比于MHA将实例信息配置到配置文件,Orchestrator可以通过集群中某一个实例的instanceKey(ip:port)发现整个集群的拓扑结构。本篇文章通过源码层次解读Orchestrator 是如何进行实例发现的。后面的文章还会通过源码层次讲解实例的故障或失败的发现和探测, 故障的恢复。
发现MySQL集群拓扑的方式
使用OC管理过MySQL集群的大概都知道,Orchestrator发现实例大概有下面三种方式
1 自动发现
2 手动发现 - 通过Web 控制台发现实例
3 手动发现 - 通过命令行接口发现实例
实例发现函数调用流程
.go/cmd/orchestrator/main() // 主函数 函数入口
--> func Http(continuousDiscovery bool) // 启动http 服务
--> func standardHttp(continuousDiscovery bool) // 开启 HTTP 或 HTTPS (api/web) 的服务请求,供客户端使用
--> go logic.ContinuousDiscovery() //负责启动一个异步的、无限循环的发现过程。在这个过程中,创建多种定时器,实例会定期进行被检查,捕获它们的状态,而长时间未见的实例会被清除和遗忘。
--> go handleDiscoveryRequests // 消费 discoveryQueue 通道,对于通道的每个实例进行发现,
--> DiscoverInstance(instanceKey) // 尝试发现一个实例,也会通过该实例检查他的主或者所有的从副本,并将该实例的主或从添加到discoveryQueue通道
--> ReadTopologyInstanceBufferable // 连接到 MySQL拓扑中的一个实例,在该实例上收集信息 和 复制状态。也会写到OC的后端数据库。实例拓扑发现核心流程图
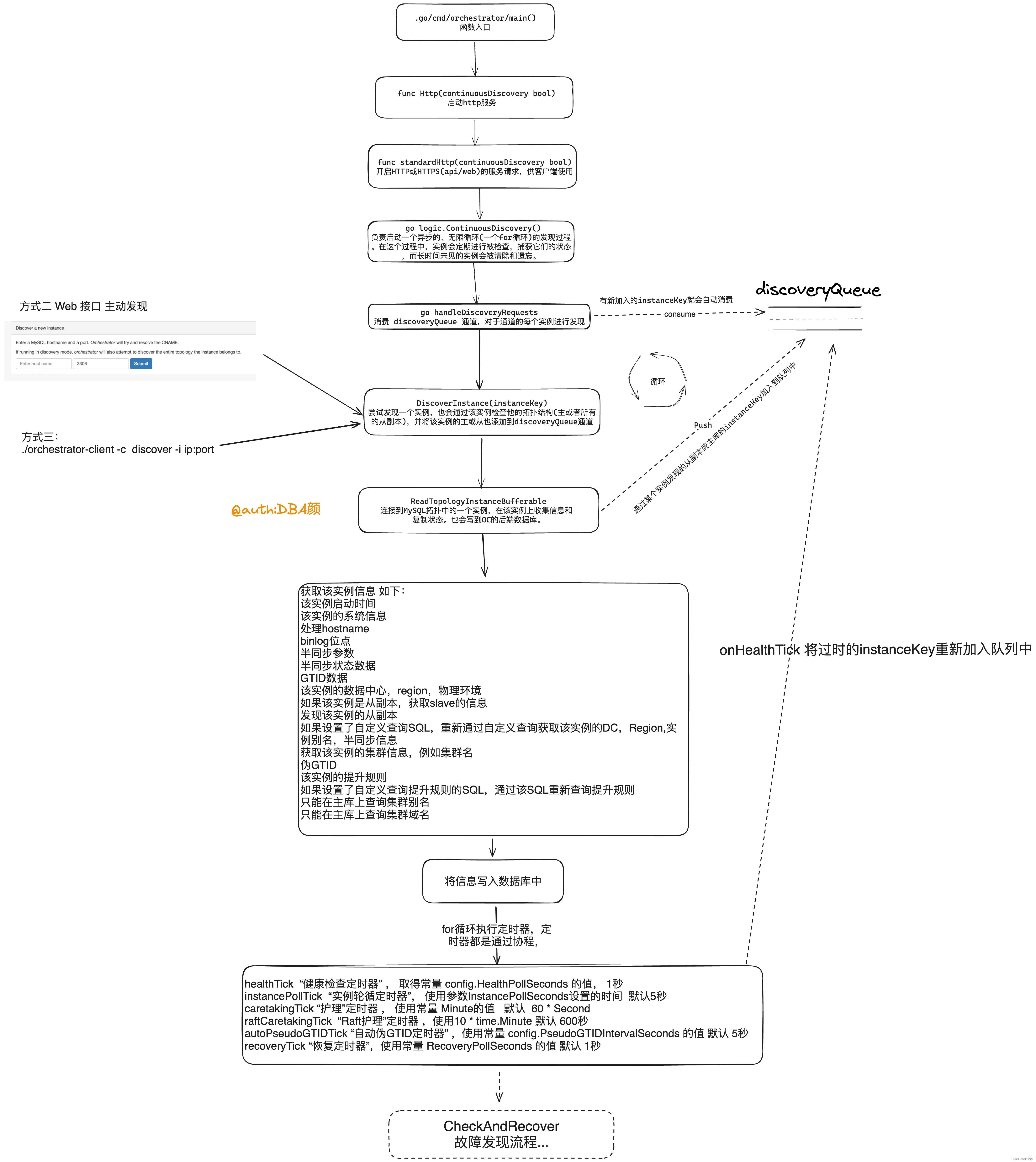
核心函数详细解读
.go/cmd/orchestrator/main() - 函数入口
该函数的主要作用 :接受命令行传入的参数 ,并进行校验参数。
- 参数 destination 与 sibling 不能一起使用
- PromotionRule 主库提升规则只能是下面四个值中之一 : " prefer", "neutral", "prefer_not", "must_not"
- 设置日志级别其中之一 :quiet, verbose ,debug, stack
- 如果使用了参数 Version ,打印版本并退出
- 如果设置了参数 configFile,则重新读取该配置文件中的参数 ;如果没有设置参数 configFile,则从配置文件中的默认路径读取 :
- /etc/orchestrator.conf.json
- 当前路径下的 "conf/orchestrator.conf.json"
- 当前路径下的 "orchestrator.conf.json
- 读取完配置文件重新设置日志输出级别
- 是否开启Syslog,如果开启了Syslog ,是否将审计日志记录到Syslog
- 如果不指定任何参数 ,则提示用法 ,并退出。
- 最后会根据判断 启动Http服务
ReadTopologyInstanceBufferable
该函数具体的功能
如何处理MySQL的hostname(主机名)
根据参数MySQLHostnameResolveMethod
有三种方式
- none : 则取你填写的实例的IP
- "default", "hostname", "@@hostname": 通过SQL select @@global.hostname获取
- "report_host", "@@report_host": 则通过 select ifnull(@@global.report_host, ''), 获取,
- 如果为空的用你填的值
如何获取实例的MySQL信息
# 获取启动时间
show global status like 'Uptime';
# 系统参数
select @@global.hostname, ifnull(@@global.report_host, ''), @@global.server_id, @@global.version, @@global.version_comment, @@global.read_only, @@global.binlog_format, @@global.log_bin, @@global.log_slave_updates
# 获取binlog的文件和位点
show master status
# 半同步复制相关参数
show global variables like 'rpl_semi_sync_%' ;
rpl_semi_sync_master_enabled
rpl_semi_sync_master_timeout
rpl_semi_sync_master_wait_for_slave_count
rpl_semi_sync_slave_enabled
# 半同步复制相关状态
show global status like 'rpl_semi_sync_%';
Rpl_semi_sync_master_status
Rpl_semi_sync_master_clients
Rpl_semi_sync_slave_status
# GTID相关
如果 是 OracleMysql 或 Percona 且 数据库主版本> 5.6
select @@global.gtid_mode, @@global.server_uuid, @@global.gtid_executed, @@global.gtid_purged, @@global.master_info_repository = 'TABLE', @@global.binlog_row_image;
# 从库信息相关
如果该实例是从副本 ,在该实例上执行SQL
show slave status;
比如
读取到binlog坐标 (IO thread)
instance.ReadBinlogCoordinates.LogFile = m.GetString("Master_Log_File")
instance.ReadBinlogCoordinates.LogPos = m.GetInt64("Read_Master_Log_Pos")
执行过的binlog坐标 (SQL Thread)
instance.ExecBinlogCoordinates.LogFile = m.GetString("Relay_Master_Log_File")
instance.ExecBinlogCoordinates.LogPos = m.GetInt64("Exec_Master_Log_Pos")
instance.IsDetached, _ = instance.ExecBinlogCoordinates.ExtractDetachedCoordinates()
中级日志的坐标 (SQL Thread)
instance.RelaylogCoordinates.LogFile = m.GetString("Relay_Log_File")
instance.RelaylogCoordinates.LogPos = m.GetInt64("Relay_Log_Pos")
如何通过实例发现其从副本
OC相关参数DiscoverByShowSlaveHosts :在通过show PROCESSLISTs 获取从副本的host之前尝试使用 SHOW SLAVE HOSTS 来获取
首先通过 :SHOW SLAVE HOSTS; 获取
如果不配置 report-host参数 ,使用该命令从副本的host列为空。
如果获取不到则通过 PROCESSLIST;
command 为 Binlog Dump 或者 Binlog Dump GTID,
select substring_index(host, ':', 1) as slave_hostname from information_schema.processlist where command IN ('Binlog Dump', 'Binlog Dump GTID');通过这种方式需要注意:主从的端口需要保持一致,否则从副本不会被发现 ,具体原因见下面代码
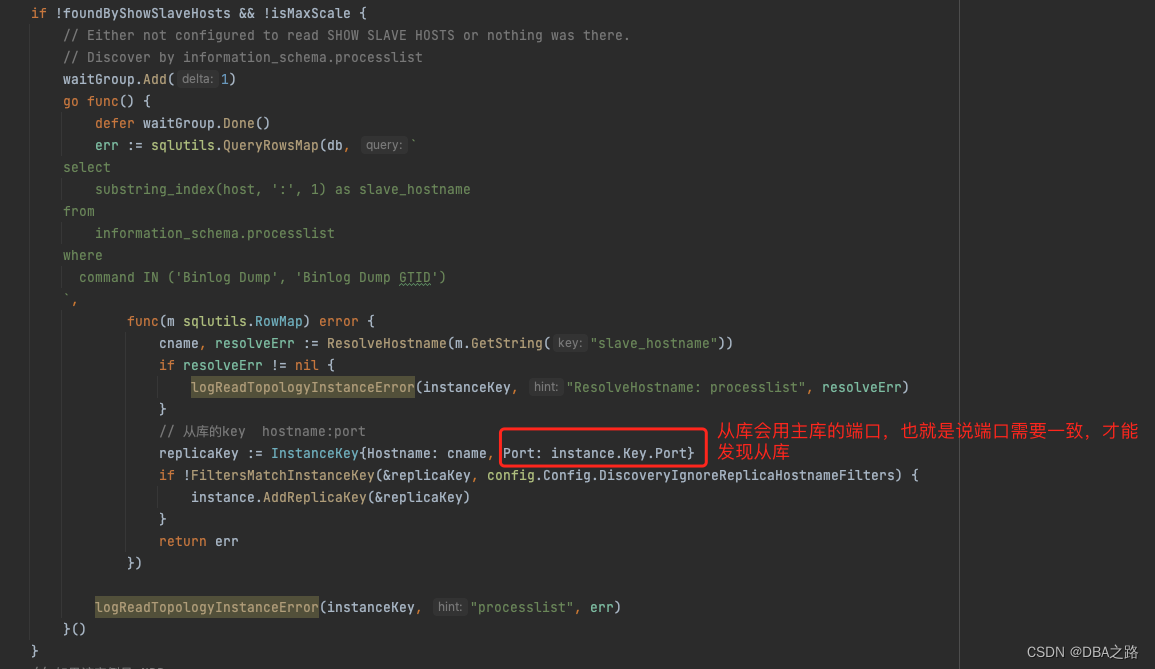
使用这种方式会不会把canal的客户端监听进去?? 一会看下
如何通过实例发现其主库
通过 show slave status 获取到该实例的主库信息
如何获取实例的机房,地域等信息
通过自定义SQL或者正则表达式获取
注意 自定义SQL优先级比正则表达式高,在源码中表现就是自定义SQL的结果会覆盖正则表达式结果,相关参数如下
DetectDataCenterQuery > DataCenterPattern // 数据中心
DetectRegionQuery > RegionPattern // 地域
DetectPhysicalEnvironmentQuery > PhysicalEnvironmentPattern
DetectInstanceAliasQuery // 实例别名
DetectSemiSyncEnforcedQuery // 半同步如何获取实例的实例的提升规则
1 首先通过SQL查询表 candidate_database_instance 中的提升规则
如果没有设置提升规则 ,则用默认为 neutral
select ifnull(nullif(promotion_rule, ''), 'neutral') as promotion_rule from candidate_database_instance where hostname=? and port=?2 然后会通过DetectPromotionRuleQuery 参数定义的SQL查询该实例的提升规则,然后更新表 candidate_database_instance
如何获取该实例所在集群的别名
三种优先级
1 首先查看 instance.SuggestedClusterAlias 是否为空
2 如果SuggestedClusterAlias为空 ,使用 DetectClusterAliasQuery 自定义查询,必须在主库上进行查询
3 如果DetectClusterAliasQuery 也没有定义查询,mappedClusterNameToAlias ,则使用参数 ClusterNameToAlias ,将正则表达式匹配到集群名称映射为易读的别名
如何获取该实例所在集群的域名 domain
通过 DetectClusterDomainQuery 参数设置的自定义查询在主库上进行查询
如何将获取的信息写入到后台管理数据库中?
WriteInstance-->writeManyInstances-->mkInsertOdkuForInstances-->mkInsertOdku
具体SQL
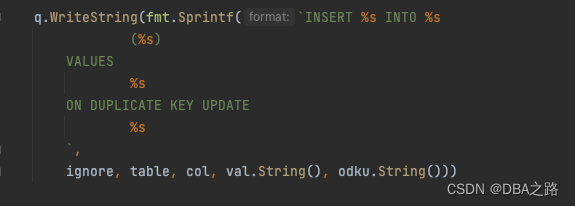
INSERT INTO database_instance
(hostname, port, last_checked, last_attempted_check, last_check_partial_success, uptime, server_id, server_uuid, version, major_version, version_comment, binlog_server, read_only, binlog_format, binlog_row_image, log_bin, log_slave_updates, binary_log_file
, binary_log_pos, master_host, master_port, slave_sql_running, slave_io_running, replication_sql_thread_state, replication_io_thread_state, has_replication_filters, supports_oracle_gtid, oracle_gtid, master_uuid, ancestry_uuid, executed_gtid_set, gtid_mode, gtid_purged, g
tid_errant, mariadb_gtid, pseudo_gtid, master_log_file, read_master_log_pos, relay_master_log_file, exec_master_log_pos, relay_log_file, relay_log_pos, last_sql_error, last_io_error, seconds_behind_master, slave_lag_seconds, sql_delay, num_slave_hosts, slave_hosts, cluste
r_name, suggested_cluster_alias, data_center, region, physical_environment, replication_depth, is_co_master, replication_credentials_available, has_replication_credentials, allow_tls, semi_sync_enforced, semi_sync_available, semi_sync_master_enabled, semi_sync_master_time
out, semi_sync_master_wait_for_slave_count, semi_sync_replica_enabled, semi_sync_master_status, semi_sync_master_clients, semi_sync_replica_status, instance_alias, last_discovery_latency, replication_group_name, replication_group_is_single_primary_mode, replication_group_
member_state, replication_group_member_role, replication_group_members, replication_group_primary_host, replication_group_primary_port, last_seen)
VALUES
('10.10.10.10', 5306, NOW(), NOW(), 1, 9243821, 49445306, '3d9b015e-4ca6-11ee-bfc0-246e962c99a0', '5.7.28-log', '5.7', 'MySQL Community Server (GPL)', 0, 0, 'ROW', 'FULL', 1, 1, 'mysql-bin.000058', 47362807, '', 0, 0, 0, -1, -1, 0, 1, 0, '', '3d9b015e-4ca6
-11ee-bfc0-246e962c99a0', '33e4660c-4ca5-11ee-abbd-246e962c9d50:1-2895,\n3d9b015e-4ca6-11ee-bfc0-246e962c99a0:1-13', 'ON', '3d9b015e-4ca6-11ee-bfc0-246e962c99a0:1-13', '', 0, 0, '', 0, '', 0, '', 0, '', '', NULL, NULL, 0, 1, '[{\"Hostname\":\"10.10.10.12\",\"Port\":5306}]
', '10.10.10.11:5306', 'ehr_oc_stage', 'ys', '', '', 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, '', 3590008, '', 0, '', '', '[]', '', 0, NOW())
ON DUPLICATE KEY UPDATE
hostname=VALUES(hostname), port=VALUES(port), last_checked=VALUES(last_checked), last_attempted_check=VALUES(last_attempted_check), last_check_partial_success=VALUES(last_check_partial_success), uptime=VALUES(uptime), server_id=VALUES(server_id), server_uu
id=VALUES(server_uuid), version=VALUES(version), major_version=VALUES(major_version), version_comment=VALUES(version_comment), binlog_server=VALUES(binlog_server), read_only=VALUES(read_only), binlog_format=VALUES(binlog_format), binlog_row_image=VALUES(binlog_row_image),
log_bin=VALUES(log_bin), log_slave_updates=VALUES(log_slave_updates), binary_log_file=VALUES(binary_log_file), binary_log_pos=VALUES(binary_log_pos), master_host=VALUES(master_host), master_port=VALUES(master_port), slave_sql_running=VALUES(slave_sql_running), slave_io_r
unning=VALUES(slave_io_running), replication_sql_thread_state=VALUES(replication_sql_thread_state), replication_io_thread_state=VALUES(replication_io_thread_state), has_replication_filters=VALUES(has_replication_filters), supports_oracle_gtid=VALUES(supports_oracle_gtid),
oracle_gtid=VALUES(oracle_gtid), master_uuid=VALUES(master_uuid), ancestry_uuid=VALUES(ancestry_uuid), executed_gtid_set=VALUES(executed_gtid_set), gtid_mode=VALUES(gtid_mode), gtid_purged=VALUES(gtid_purged), gtid_errant=VALUES(gtid_errant), mariadb_gtid=VALUES(mariadb_
gtid), pseudo_gtid=VALUES(pseudo_gtid), master_log_file=VALUES(master_log_file), read_master_log_pos=VALUES(read_master_log_pos), relay_master_log_file=VALUES(relay_master_log_file), exec_master_log_pos=VALUES(exec_master_log_pos), relay_log_file=VALUES(relay_log_file), r
elay_log_pos=VALUES(relay_log_pos), last_sql_error=VALUES(last_sql_error), last_io_error=VALUES(last_io_error), seconds_behind_master=VALUES(seconds_behind_master), slave_lag_seconds=VALUES(slave_lag_seconds), sql_delay=VALUES(sql_delay), num_slave_hosts=VALUES(num_slave_
hosts), slave_hosts=VALUES(slave_hosts), cluster_name=VALUES(cluster_name), suggested_cluster_alias=VALUES(suggested_cluster_alias), data_center=VALUES(data_center), region=VALUES(region), physical_environment=VALUES(physical_environment), replication_depth=VALUES(replica
tion_depth), is_co_master=VALUES(is_co_master), replication_credentials_available=VALUES(replication_credentials_available), has_replication_credentials=VALUES(has_replication_credentials), allow_tls=VALUES(allow_tls), semi_sync_enforced=VALUES(semi_sync_enforced), semi_s
ync_available=VALUES(semi_sync_available), semi_sync_master_enabled=VALUES(semi_sync_master_enabled), semi_sync_master_timeout=VALUES(semi_sync_master_timeout), semi_sync_master_wait_for_slave_count=VALUES(semi_sync_master_wait_for_slave_count), semi_sync_replica_enabled=
VALUES(semi_sync_replica_enabled), semi_sync_master_status=VALUES(semi_sync_master_status), semi_sync_master_clients=VALUES(semi_sync_master_clients), semi_sync_replica_status=VALUES(semi_sync_replica_status), instance_alias=VALUES(instance_alias), last_discovery_latency=
VALUES(last_discovery_latency), replication_group_name=VALUES(replication_group_name), replication_group_is_single_primary_mode=VALUES(replication_group_is_single_primary_mode), replication_group_member_state=VALUES(replication_group_member_state), replication_group_membe
r_role=VALUES(replication_group_member_role), replication_group_members=VALUES(replication_group_members), replication_group_primary_host=VALUES(replication_group_primary_host), replication_group_primary_port=VALUES(replication_group_primary_port), last_seen=VALUES(last_s
een)last_attempted_check,last_check ,last_seen如何更新的
在database_instance表中有很多时间戳字段,都比较重要,例如通过比较字段来确定实例是否存活,该函数中会更新几个重要的时间戳字段。
last_attempted_check:最后一次尝试检查该该实例的时间
该函数执行期间 每1秒执行一次 UpdateInstanceLastAttemptedCheck 更新 last_attempted_check 字段。
每秒执行一次该函数:
访问给定实例之前更新数据库中的last_attempted_check时间戳。这是一种防范机制,用于处理访问实例时发生挂起的情况。如果last_attempted_check时间戳新于last_checked,则表示出现了问题,可能是由于实例访问挂起导致的。
lastAttemptedCheckTimer := time.AfterFunc(time.Second, func() {
go UpdateInstanceLastAttemptedCheck(instanceKey)
}) update
database_instance
set
last_attempted_check = NOW()
where
hostname = ?
and port = ?`,last_check : 最后一次真正检查实例的时间
函数结束的时候执行 UpdateInstanceLastChecked 更新该实例的 last_check 字段
UpdateInstanceLastChecked 这个函数的作用是更新 Orchestrator 后端数据库中给定实例的 last_check 时间戳。last_check 时间戳通常用于跟踪实例的最后一次检查时间,以便了解实例的健康状态和最新的状态。
update
database_instance
set
last_checked = NOW(),
last_check_partial_success = ?
where
hostname = ?
and port = ?`last_seen
只有实例被真正的发现的时候,才会更新该字段
if updateLastSeen {
columns = append(columns, "last_seen")
values = append(values, "NOW()")
}看数据库中这三个字段都是每6秒更新一次。
DiscoverInstance(instanceKey inst.InstanceKey)
如何确定该实例是否被forgoteen
TODO
如何过滤发现某些实例
可以通过参数 DiscoveryIgnoreHostnameFilters
如何确定实例最近一次检查有效,是最新数据
is_last_check_valid ,是通过比较 last_seen 和 last_checked 两个时间戳。last_seen时间要等于或 新于 last_checked
ifnull(last_checked <= last_seen, 0) as is_last_check_valid,
执行函数 ReadInstance 如果没有报错 is_up_to_date 则为true
如何实现持续发现实例
利用for 循环 和 channel ,读取实例的时候还会发现其主库和从副本,将读取到实例都加入队列中,for循环会消费加入队列中的新实例,从而感知拓扑结构的变化 例如新实例的加入 或 拓扑结构的改变。具体见上面的路程图。
该函数会将新发现的实例加入到队列中等待消费
// Investigate replicas and members of the same replication group: 将该实例的从副本加入到discoveryQueue 通道,在自动消费。
for _, replicaKey := range append(instance.ReplicationGroupMembers.GetInstanceKeys(), instance.Replicas.GetInstanceKeys()...) {
replicaKey := replicaKey // not needed? no concurrency here?
// Avoid noticing some hosts we would otherwise discover
if inst.FiltersMatchInstanceKey(&replicaKey, config.Config.DiscoveryIgnoreReplicaHostnameFilters) {
continue
}
if replicaKey.IsValid() {
discoveryQueue.Push(replicaKey)
}
}
// Investigate master: 将该实例的masterKey加入到discoveryQueue 通道,在自动消费。
if instance.MasterKey.IsValid() {
if !inst.FiltersMatchInstanceKey(&instance.MasterKey, config.Config.DiscoveryIgnoreMasterHostnameFilters) {
discoveryQueue.Push(instance.MasterKey)
}
}handleDiscoveryRequests
在函数 handleDiscoveryRequests 会监听和消费discoveryQueue 队列。重复发现实例的流程
// handleDiscoveryRequests iterates the discoveryQueue channel and calls upon
// instance discovery per entry. 迭代消费 discoveryQueue 通道,对于通道的每个实例条目进行发现,
func handleDiscoveryRequests() {
discoveryQueue = discovery.CreateOrReturnQueue("DEFAULT")
// create a pool of discovery workers 创建了一个发现工作者池。工作者池通常用于并行地执行一些任务,以提高系统的性能和效率
for i := uint(0); i < config.Config.DiscoveryMaxConcurrency; i++ {
go func() { // 匿名函数
for {
instanceKey := discoveryQueue.Consume()
// Possibly this used to be the elected node, but has
// been demoted, while still the queue is full.
if !IsLeaderOrActive() {
log.Debugf("Node apparently demoted. Skipping discovery of %+v. "+
"Remaining queue size: %+v", instanceKey, discoveryQueue.QueueLen())
discoveryQueue.Release(instanceKey)
continue
}
DiscoverInstance(instanceKey)
discoveryQueue.Release(instanceKey)
}
}() // 匿名函数会被调用
}
}ContinuousDiscovery
该函数 负责启动一个异步的、无限循环的发现过程。在这个过程中,实例会定期进行被检查,捕获它们的状态,而长时间未见的实例会被清除和遗忘。
定时器
- healthTick “健康检查定时器” 取得常量 config.HealthPollSeconds 的值, 1秒
- instancePollTick “实例轮循定时器” -- 使用参数InstancePollSeconds设置的时间 默认5秒
- caretakingTick “护理”定时器 使用常量 Minute的值 默认 60 * Second
- raftCaretakingTick “Raft护理”定时器 使用10 * time.Minute 默认 600秒
- autoPseudoGTIDTick “自动伪GTID定时器” 使用常量 config.PseudoGTIDIntervalSeconds 的值 默认 5秒
- recoveryTick “恢复定时器”,使用常量 RecoveryPollSeconds 的值 默认 1秒
healthTick 定时器
onHealthTick() // 处理发现/轮询实例所需采取的操作
--> ReadOutdatedInstanceKeys // 读出所有不是最新的instanceKey (即自上次检查以来已经过了预配置的时间)
--> discoveryQueue.Push(instanceKey) // 将通过SQL发现的key 加入到 discoveryQueue 通道
SQL:
select
hostname, port
from
database_instance
where
case
when last_attempted_check <= last_checked -- 尝试检查实例的实例 与 真正检查实例比较
then last_checked < now() - interval 5 second -- 尝试检查实例的实例 小于 真正检查实例时间减去5秒
else last_checked < now() - interval 10 second -- 尝试检查实例的实例 小于 真正检查实例时间减去10秒
endinstancePollTick 定时器
这个定时器不进行实例轮循,(这些由 discoveryTick 处理),但是需要和实例轮循 一样的频率
- go inst.UpdateClusterAliases() // UpdateClusterAliases 根据从database_instance获取的信息更新cluster_alias表
- go inst.ExpireDowntime() // 移除 Downtime的过期的实例的维护状态
- go injectSeeds(&seedOnce) --> InjectSeed --> WriteInstance --> writeManyInstances --> 生成插入SQL
autoPseudoGTIDTick 定时器
InjectPseudoGTIDOnWriters()
caretakingTick
各种定期的内部维护
- go inst.RecordInstanceCoordinatesHistory() // 记录实例binlog坐标快照 在表database_instance_coordinates_history 中,
- go inst.ReviewUnseenInstances() // 重新检查 那些不再可见的实例 然后更新数据
- go inst.InjectUnseenMasters() // 和参数 DiscoveryIgnoreMasterHostnameFilters 和 DiscoveryIgnoreHostnameFilters 相关,那些匹配到 发现过滤规则的 实例
- go inst.ForgetLongUnseenInstances() // 会删除instance的信息 ,当 NOW - UnseenInstanceForgetHours > last_seen,会把instance的信息 从 database_instance 表中删除
- go inst.ForgetLongUnseenClusterAliases() // 从 cluster_alias表中 删除信息 ,当该实 最后一次被发现的时间已经超过了 UnseenInstanceForgetHours 小时后,默认是10天
- go inst.ForgetUnseenInstancesDifferentlyResolved()
- go inst.ForgetExpiredHostnameResolves() // 从 hostname_resolve 内删除超过过期的记录 和参数有关 ExpiryHostnameResolvesMinutes
- go inst.DeleteInvalidHostnameResolves() // 删除非法的 主机名 解析 ,
- go inst.ResolveUnknownMasterHostnameResolves()
- go inst.ExpireMaintenance() // 删除过期的维护状态
- go inst.ExpireCandidateInstances() // 从表 candidate_database_instance 中删除过期的候选实例,和参数 CandidateInstanceExpireMinutes 有关。
- go inst.ExpireHostnameUnresolve() // 从表中 hostname_unresolve 删除最近不再更新的记录 ,和参数 ExpiryHostnameResolvesMinutes 有关
- go inst.ExpireClusterDomainName() // 写入或者覆盖表 cluster_domain_name 中 集群域名
- go inst.ExpireAudit() // 从表 audit中 删除过期的审计日志 ,日志过期天数参数 AuditPurgeDays
- go inst.ExpireMasterPositionEquivalence() // 从表中master_position_equivalence删除过期的 主库位置 (master_position_equivalence)??,过期时间 UnseenInstanceForgetHours
- go inst.ExpirePoolInstances() // 删除database_instance_pool表中 过期数据 ,过期时间 InstancePoolExpiryMinutes
- go inst.FlushNontrivialResolveCacheToDatabase() //
- go inst.ExpireInjectedPseudoGTID() // 删除 cluster_injected_pseudo_gtid 表中过期数据 ,参数 PseudoGTIDExpireMinutes
- go inst.ExpireStaleInstanceBinlogCoordinates() // 从表中 database_instance_stale_binlog_coordinates 删除过期数据
- go process.ExpireNodesHistory() // 从表node_health_history 删除过期数据,过期参数 UnseenInstanceForgetHours
- go process.ExpireAccessTokens() // 从表access_token中删除老的非法的Token ,过期时间AccessTokenExpiryMinutes
- go process.ExpireAvailableNodes() // 从表中 node_health 删除
- go ExpireFailureDetectionHistory() // 从表中 topology_failure_detection 删除过期的故障/失败探测 历史记录
- go ExpireTopologyRecoveryHistory() // 从表中 topology_recovery 删除过期的 拓扑恢复 历史记录
- go ExpireTopologyRecoveryStepsHistory() // 从表中 topology_recovery_steps 删除过期的 拓扑恢复具体步骤 历史记录
recoveryTick 定时器
- go ClearActiveFailureDetections() //
- go ClearActiveRecoveries() // 删除过期的 in_active_period 标志,这样该实例就可以进行恢复,和参数RecoveryPeriodBlockSeconds 有关,默认 3600 秒 ,1小时内该实例不会进行多次恢复
- go ExpireBlockedRecoveries() //清除实际不再被阻止的被阻止恢复的列表。
- go AcknowledgeCrashedRecoveries() // 确认那些故障恢复
- go inst.ExpireInstanceAnalysisChangelog() // 从database_instance_analysis_changelog 表中删除足够旧的分析数据
- 和参数 UnseenInstanceForgetHours 相关,默认是10天
snapshotTopologiesTick 定时器
go inst.SnapshotTopologies()
与MHA相比
MHA在拓扑管理的功能比较弱,MHA通过配置文件发现实例,但不会感知拓扑结构的变化?
| MHA | OC | |
| 实例发现 | 无 | 多种方式 |
| 拓扑管理 | 无 | 可以感知拓扑结构的变化 |

















 449
449











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











