






文章目录
前言
上一节我们实现了客户交易行为的分析,接下来进行客户体系标签计算
客户体系标签计算
事实类标签计算
交易次数和交易总额
我们的标签是针对用户的,所以要提取标签。所以需要做到的是一行数据就是一个用户id的数据。
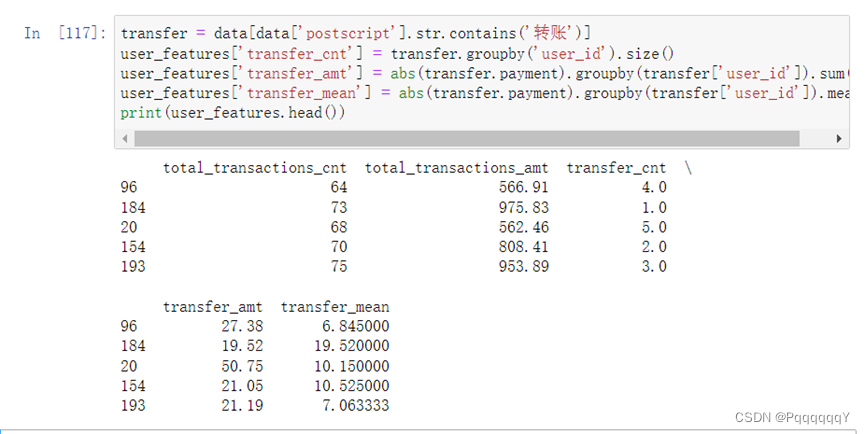
新建user_features表,用于存放客户的标签,表的索引为user_id。每提取一个标签,就在user_features表中新增一列进行存放。再使用groupby()函数对data根据user_id进行分组,计算客户的交易次数和交易总金额,并将其结果分别存储到user_features表的total_transactions_cnt和total_transactions_amt列中。最后计算交易流水总额时需要将每笔交易金额取绝对值,再使用sum()方法进行求和。

转账次数和转账总额
接下来提取客户的转账类标签。使用关键字转账进行匹配,将客户有转帐行为的流水记录提取出来,针对转账记录我们再对其进行分析,计算客户的转账次数、转账总金额和转账平均金额。
对某一列Series对象进行关键词匹配(即判断文本中有没有这个词),首先要将此列的文本数据转换为Pandas中的string类型( pandas .core.strings ),接着使用contains()函数带入关键词进行匹配。
可以进一步操作:比如短时间内转账次数多且数额大,那存在异常,进行风险提示。也可根据转账次数划分客户
其它标签
消费行为是金额流出的过程,我们首先选取交易金额大于0的交易记录。但是在金额流出的行为中,"转账"、"提现"、"转入"、“还款"等行为并不属于消费,我们需要将其剔除。在此部分我们同样使用关键词匹配的方法对客户交易数据进行筛选,接着提取出客户的单次最大消费金额、消费订单比例等标签。

规则类标签的计算
在完成事实类标签后,我们开始提取规则类标签。规则类标签是在事实类标签的基础上,结合人工经验,对客户的某项指标进行的计算或归类,如定义高端消费需要人为规定阈值。在项目中,我们提取的规则类标签包括有无高端消费、是否休眠、RFM类等9个标签。
有无高端消费
随着客户可支配收入水平的升高,客户的消费偏好会发生变化。对某些中、高档商品的购买和消费量会增加,对低档消费品的需求减少,因此在这里我们对是否有高端消费进行定义,作为客户的一个标签。
之前已经计算了客户的最大消费金额,我们取所有最大消费金额的上四分位数作为阈值,如果客户的最大消费金额有大于该阈值,则将该客户定义为有高端消费,反之则无高端消费。

从图中可以看出high_consumption这一列为是否高消费,即0为低消费,1为高消费。
是否休眠客户
精准营销的另一个目标是激活“休眠"客户。所谓“休眠"客户,是指那些已经了解企业和产品,却还在消费与不消费之间徘徊的客户。
“休眠"客户对于企业的发展具有重大作用,调查显示“休眠"客户的消费能力是普通客户消费能力的3一5倍,甚至更高,而企业挖掘新客户的花费是“休眠"客户的8倍,所以唤醒休眠客户对企业开展精准营销具有重大意义。
取出每个客户的交易记录,设定交易次数的下四分位数为阈值,交易次数total_transactions_cnt 小于阈值的客户则视为休眠客户(1) ,交易次数大于等于阈值的客户则视为活跃客户(O)。

从图中可以看出,sleep_customers这一列为是否休眠客户,即都不是休眠客户。
RFM模型
Recency计算:即距离观察点的时间差。
预处理的过程中,将数据集的时间限定在2027附近。在RFM模型中,观察点的时间设为2027.1.1。那由此可以根据每笔交易时间计算最近天数。RFM模型的前提是提取只属于消费类的数据。之前已经计算过该数据:从data中选取金额流出的交易记录,在剔除转账、提现、还款、转入等记录即可

R/F/M的值的计算
上一步设定了日期的观察点,并计算了每笔交易距离观察点的距离天数。现在需要将交易记录根据客户进行分组,计算每个客户的RFM值。

RFM总得分
上一步已经通过分组和聚合运算得到了每个客户RFM的具体值,根据这三个指标,又可以把客户分别进行四等分,得到不同指标的评分阶梯,根据阶梯计算客户RFM总得分。
理论上来说,同等的资源投入的情况下,一名优质客户带来的回报将会是一般客户的5倍,可以推出,在资源有限的前提下,满足客户的顺序应该也是自上而下的。

R分值越低越好,F,M分值越高越好,说明图中的RFM值都不错。
RFM可视化分析
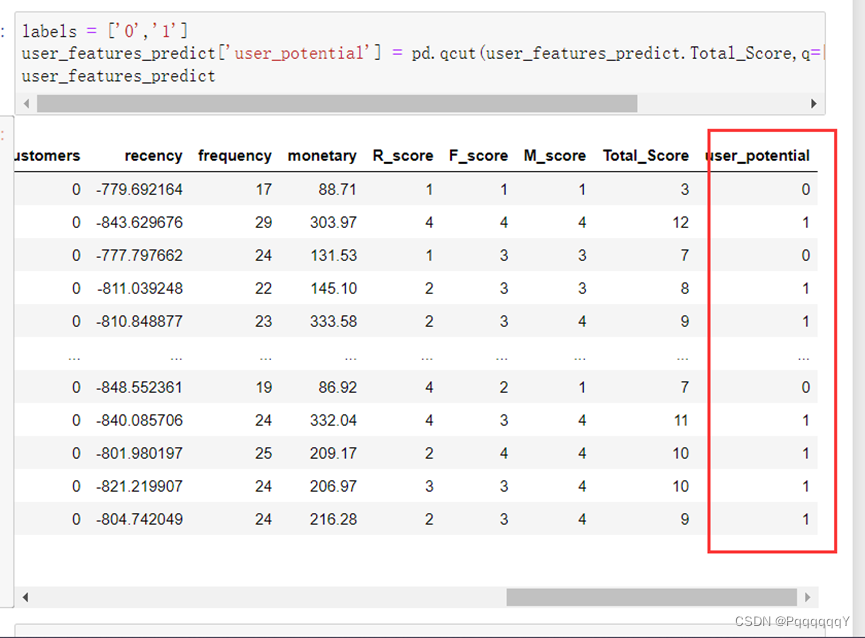
前面的步骤中,已经计算好了recency 、 frequency . monetary 以及其对应的得分,并得到了单个客户的RFM总得分Total_score,得分取值范围为3-12。现在我们可以将它们进行一些组合,可视化分析其中的一些规律。将每个Total_score的取值作为一个类别进行分组,统计不同Total_score下RFM的取值分布情况。

从图中可以看出,随着Total_Score的增大,recency的平均值逐渐减小,这也印证了较优质的客户群体,最近一次消费普遍较近,随着Total_Score的增大,frequency、monetary的平均值逐渐增大,这也印证了越优质的客户群体,消费频率和消费金额普遍越高。
预测类标签的计算
one-hot编码
在建立模型之前我们需要对已经提取的标签进行处理,对于有缺失的标签,我们需要进行填充。消费渠道consumption_channel列为离散型变量,我们统一将空值填充为othersPay ,代表其他消费渠道。其他为空值的列均为连续性变量,我们将这些空值填为0,代表客户不具有这部分的交易行为。缺失值的填充步骤为题目预先完成,接下来我们还要对标签做一些其他的处理,如字符型标签进行编码、连续性标签进行离散化等。标签处理完成后进行训练测试集划分,接着训练模型并通过模型预测客户价值等级。
以上所做的操作只是为了更好的建立模型来预测客户价值等级,原始客户标签表user_features中的数据应当保留,不进行性何的数据处理。客户等级标签预测完成后,将其合并作为user_featunes表的最后一列。
为了保持user_features中标签数据不变,我们在这里复制一份user_features,保存为表user_features_predict ,在建模过程中的操作均在user_features _predict表中.

连续性数值等频离散化
对数据进行离散化时,若每个区间的间隔是相等的,称作等距离散化。另外─种叫做等频离散化,它是指每个区间的样本数相同。可以发现对于该数据集,连续型数值多呈长尾分布,若用等距离散化会在分布较少的区域会分出很多无意义的区间,在这里需要对连续型数值进行等频离散化。
构建客户价值等级预测模型
训练测试集划分,使用score数据来进行测试集的划分。
查看缺失值

发现含有缺失值,需要将其填充

划分训练集和测试集并查看大小

构建模型:

可以看出构建模型的准确度为98.36065,可以说准确率较高,模型比较优质。
客户价值等级分布
上一步建立了逻辑回归模型,并在测试集上进行了检验,达到了98%的准确率,并将数据整体合并保存在user_features表中。接下来通过可视化的方式来观察一下客户价值等级的数量分布。

客户标签间的相关性
对客户价值等级进行预测后,,现在分析一下各标签之间的关联程度,使用皮尔森相关系数来计算不同标签之间的相关性。皮尔森相关系数是用来反映两个变量线性相关程度的统计量,是一种线性相关系数,一般用r表示。r的取值在-1与+1之间。
若r>0,表明两个变量是正相关,即一个变量的值越大,另一个变量的值也会越大。
若r<0,表明两个变量是负相关,即一个变量的值越大另一个变量的值反而会越小。
r的绝对值越大表明相关性越强。在标签数较多的情况下,选取其中明显的几个标签,计算其相关性并使用热力图表示:

交叉表
在上一步中发现是否拥有高端消费( high_consumption )与客户价值等级(user_potential )之间的相关性较高。接下来来观察一下在有高端消费和无高端消费的人群中,不同客户价值等级的人数分布。
对于这种多重分组计算个数的问题,我们通常使用交叉表来计算。交叉表是一种常用的分类汇总表格,用于频数分布统计。

从图中可以看出:清晰可见在无高端消费的人群中,高价值等级客户的占比较小;在有高端消费的人群中,高价值等级客户的占比更多;说明客户价值等级高的群体更倾向买贵的物品。
客户价值等级与月均消费频度可视化
月均消费频度可视化


通过结果我们可以看到不论客户等级,其月均消费频度都在[60,75]区间内占比较多。在月均消费频度较低的区间内,低价值客户占比相对较多;在月均消费频度较高的区间内,高价值客户占比逐渐提升,说明高价值客户偏向于有更多的消费需求。
文本类标签的计算
文本标签的提取方法
在前面的步骤中,已经根据客户的交易记录建立了事实类标签,根据一些设定的规则建立了规则类标签,同时也建立模型预测了客户价值等级。接下来,我们要从每个客户的交易附言中提取文本标签。
在之前已经进行了文本预处理,具体步骤如下:
中文文本分词:将中文的句子切分成有意义的词语。
去除停用词:根据事先设置好的停用词,规避掉一些特殊符号或者常用但无意义的词语。
交易附言合并
先找出交易附言

CountVectorizer词频矩阵计算
采用CountVectorizer模型提取词频矩阵。首先我们在原有停用词的基础上再引入一些其他停用词,将有限公司、交易、转账、消费、余额、提现等词语归于停用词,以便计算出的词能更好的反映用户真实的消费特征。停用词已预先读入,保存在变量stop_words_list中。

可以得到稀疏矩阵如上图所示
第0条,记录中索引为36的词在文本中出现1次,即词频为1
输出稀疏矩阵的关键词如下图所示:

TfidfVectorizer词频矩阵计算
接下来采用TfidfVectorizer模型提取词频矩阵。在TfidfVectorizer模型中,还是通过设置参数min_df . max_df来控制某个词最小/最大的出现次数,设置max_feates=100 代表最终输出的关键词为100个。和CountVectorizer模型类似,TfidfVectorizer模型也通过get_feature_names()查看所有文本的关键字,通过toarray()查看词频矩阵的结果。


将提取出来的文本标签的词频矩阵和features表合并

描绘用户画像
在提取完了客户标签之后,我们来深入分析一下客户的行为特点。
首先选取其中交易次数( total_transactions_cnt )最多的客户进行分析。
选出该典型客户后,可以通过绘制交易附言的词云图展示客户的大致画像。

绘制出来的词云图如下图所示:

从词云图中可以看出,出现了很多交方式易的慈云,如支付宝、微信、现金,分期付款等,可以大致推断客户经常接触此类商品,可能从事银行金融方面的工作。
客户文本标签的分析
对该客户的交易流水进行可视化分析以后,我们可以对其进行文本特征的分析。在前面我们已经使用TfidfVectorizer模型提取了文本标签的tf-idf值,保存在了user_features表中。我们可以取出该客户文本标签的tf-idf值,将文本标签按tf-idf值由大到小进行排序,分析其行为特点。
选取id为145的文本标签

接下来进行客户数值标签的分析:

从交易附言可以看出,支付宝和网银较多,推测出该用户大概率为银行员工。
总结
本节进行了各户标签体系的构建,下一节将进行精准营销的应用。














 1698
1698











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









