






前言:
在线电商平台中,用户评论对购买决策至关重要,但评论的有用性参差不齐。文章指出,不太有用的评论不仅对推荐系统的性能有负面影响,对用户参考价值也较低。在本文中,引入了一种新的注意力机制来探索评论的有用性,并提出了一个神经注意力回归模型与评论水平的解释(NARRE)的建议。具体来说,NARRE不仅可以预测精确的评级,还可以同时学习每个评论的有用性。
源代码:https://github.com/chenchongthu/NARRE
出处:2018年4月23日至27日在法国里昂举行的“WWW 2018”会议
一.简要介绍
NARRE模型,即Neural Attentional Regression model with Review-level Explanations(神经注意力回归模型与评论级解释),是一个旨在提高推荐系统性能和解释能力的研究工作。以下是对NARRE模型的简要介绍:
目标:NARRE模型旨在预测用户对商品的评分,并同时评估每条用户评论的有用性,以便选择对其他用户决策有帮助的评论。
注意力机制:模型利用神经网络中的注意力机制来自动为每条评论分配权重,这些权重反映了评论对预测用户评分和商品特征表示的贡献。
评论处理:使用CNN(卷积神经网络)文本处理器来处理评论文本,将文本转换为数值型特征表示。
用户和商品建模:模型包含两个并行的神经网络,分别对用户和商品进行建模。用户网络利用用户撰写的评论来学习用户偏好,而商品网络则利用商品的评论来学习商品特征。
预测层:在最后一层,模型结合了传统的潜在因子模型,并将其扩展到神经网络中,以预测用户对商品的评分。
优化:使用平方损失函数作为目标函数,并采用Adam优化器进行训练,同时使用dropout技术来防止过拟合。
性能:在多个真实世界的电子商务数据集上的实验结果表明,NARRE模型在评分预测方面一致优于现有的推荐方法,如PMF、NMF、SVD++、HFT和DeepCoNN。
解释能力:NARRE模型能够提供评论级的解释,帮助用户理解为什么推荐某个商品,从而提高推荐系统的透明度和用户信任。
实用性:模型通过众包评估验证了其在实际电子商务场景中的有效性,尤其在系统没有评论有用性评分时,NARRE模型能提供极大的帮助。
二.主要贡献
第一,注意力机制的应用:NARRE模型创新性地将注意力机制应用于推荐系统,通过自动为每条评论分配权重来识别和强调对用户决策更有价值的评论。第二,提高推荐性能:在多个真实世界的电子商务数据集上,NARRE模型在评分预测任务上超越了现有的推荐方法,包括传统的矩阵分解技术和基于深度学习的模型。第三,增强推荐解释性:NARRE模型能够提供评论级别的解释,帮助用户理解推荐的原因,从而提升推荐系统的透明度和用户信任度,尤其在缺乏评论有用性评分的实际情况下,这一点显得尤为重要。
三.论文模型
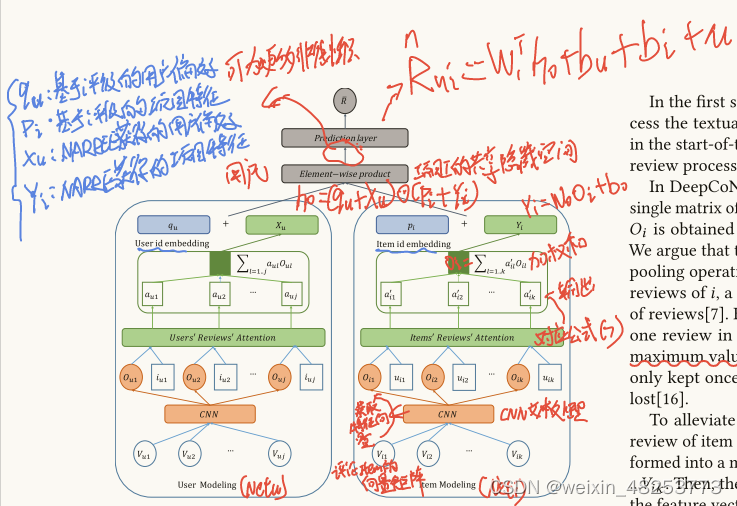
**词嵌入层**:将评论中的每个单词转换为一个\( d \)维的向量。
\[ f: \text{word} \rightarrow \mathbb{R}^d \]
其中,\( f \)是一个词嵌入函数,将每个单词映射到一个\( d \)维的向量空间。
**构建嵌入式矩阵**:将一系列词向量形成一个矩阵,以处理不同长度的文本评论。
\[ V_{1:T} = [v_1, v_2, ..., v_T] \]
其中,\( V_{1:T} \)是一个大小为 \( T \times d \) 的矩阵,\( v_t \)是第\( t \)个单词的向量表示。
**卷积层**:通过卷积操作提取特征,其中每个卷积神经元应用滤波器并产生特征。
\[ z_j = \text{ReLU} \left( \sum_{t=1}^{T} K_j \cdot v_t + b_j \right) \]
其中,\( z_j \)是第\( j \)个神经元的特征,\( K_j \)是滤波器权重,\( b_j \)是偏置项,ReLU是激活函数。
**最大池化层**:从卷积层的特征中选择每个神经元的最大值,以获得最重要的特征。
\[ o_j = \max(z_{j,1}, z_{j,2}, ..., z_{j,T-t+1}) \]
其中,\( o_j \)是经过最大池化后的特征。
**特征向量聚合**:将卷积层的所有神经元输出连接起来形成最终的文本特征表示。
\[ O = [o_1, o_2, ..., o_m] \]
其中,\( O \)是一个大小为 \( m \) 的向量,\( m \)是卷积层神经元的数量。
**注意力权重计算**:计算每条评论的注意力权重,反映了评论对用户偏好和商品特征建模的贡献。
\[ a^*_{il} = h^T \text{ReLU} (W_O O_{il} + W_u u_{il} + b_1) + b_2 \]
其中,\( a^*_{il} \)是未归一化的注意力权重,\( O_{il} \)是评论\( l \)的文本特征,\( u_{il} \)是用户\( i \)的ID嵌入,\( W_O \)和\( W_u \)是权重矩阵,\( b_1 \)和\( b_2 \)是偏置项。
**归一化注意力权重**:通过softmax函数对注意力分数进行归一化,得到每条评论的最终注意力权重。
\[ a_{il} = \frac{\exp(a^*_{il})}{\sum_{l'=1}^{k} \exp(a^*_{il'})} \]
**加权特征向量**:利用注意力权重对评论的特征向量进行加权求和,得到商品的聚合特征表示。
\[ O_i = \sum_{l=1}^{k} a_{il} O_{il} \]
**用户和商品特征交互**:在预测层,用户和商品的潜在特征进行交互,以预测评分。
\[ h_0 = (q_u + X_u) \odot (p_i + Y_i) \]
其中,\( q_u \)和\( p_i \)分别是用户和商品基于评分的潜在因子,\( X_u \)和\( Y_i \)是基于评论的潜在因子,\( \odot \)表示元素级乘积。
**评分预测**:通过全连接层和线性变换预测用户对商品的评分。
\[ \hat{R}_{u,i} = W_1^T h_0 + b_u + b_i + \mu \]
其中,\( \hat{R}_{u,i} \)是预测评分,\( W_1 \)是权重矩阵,\( b_u \)和\( b_i \)分别是用户和商品的偏差项,\( \mu \)是全局偏差项。
**损失函数优化**:使用平方损失函数作为目标函数,并采用Adam优化器进行训练。
\[ L_r = \sum_{(u,i) \in T} (\hat{R}_{u,i} - R_{u,i})^2 \]
其中,\( T \)是训练集中的用户-商品对集合,\( R_{u,i} \)是用户\( u \)对商品\( i \)的实际评分。
**dropout正则化**:在训练过程中应用dropout技术,以随机地关闭一些神经元,从而防止过拟合。
这些步骤和公式共同构成了NARRE模型的核心,使其能够处理文本数据,学习用户和商品的特征,并进行评分预测。通过这种方式,NARRE模型不仅能够预测用户评分,还能识别出对其他用户决策有帮助的有用评论。
四.NARRE的模型核心代码
代码注释见每一句代码的后面.
class NARRE(object):
def __init__(
self, review_num_u, review_num_i, review_len_u, review_len_i, user_num, item_num, num_classes,
user_vocab_size, item_vocab_size, n_latent, embedding_id, attention_size,
embedding_size, filter_sizes, num_filters, l2_reg_lambda=0.0):
self.input_u = tf.placeholder(tf.int32, [None, review_num_u, review_len_u], name="input_u")#创建一个占位符self.input_u,用于输入用户评论的序列
self.input_i = tf.placeholder(tf.int32, [None, review_num_i, review_len_i], name="input_i")#创建一个占位符self.input_i,用于输入物品评论的序列
self.input_reuid = tf.placeholder(tf.int32, [None, review_num_u], name='input_reuid')#创建一个占位符self.input_reuid,用于输入用户评论的唯一标识符
self.input_reiid = tf.placeholder(tf.int32, [None, review_num_i], name='input_reuid')#创建一个占位符self.input_reiid,用于输入物品评论的唯一标识符
self.input_y = tf.placeholder(tf.float32, [None, 1], name="input_y")#表示每个样本的标签或目标值。
self.input_uid = tf.placeholder(tf.int32, [None, 1], name="input_uid")#创建一个占位符self.input_uid,用于输入用户的ID
self.input_iid = tf.placeholder(tf.int32, [None, 1], name="input_iid")#创建一个占位符self.input_iid,用于输入物品的ID
self.dropout_keep_prob = tf.placeholder(tf.float32, name="dropout_keep_prob")#用于设置训练过程中的dropout比例
self.drop0 = tf.placeholder(tf.float32, name="dropout0")#用于设置另一种形式的dropout比例或其他正则化参数
iidW = tf.Variable(tf.random_uniform([item_num + 2, embedding_id], -0.1, 0.1), name="iidW")#创建一个变量iidW,用于物品ID的嵌入权重。它通过在一个均匀分布中随机采样来初始化,分布的范围是从-0.1到0.1
uidW = tf.Variable(tf.random_uniform([user_num + 2, embedding_id], -0.1, 0.1), name="uidW")#创建一个变量uidW,用于用户ID的嵌入权重
l2_loss = tf.constant(0.0)#初始化一个名为l2_loss的变量,并将其设置为0.0。这个变量将用于跟踪L2正则化项的损失,L2正则化是一种避免模型过拟合的技术。
# with tf.name_scope("user_embedding"):
# self.W1 = tf.Variable(#创建一个变量self.W1,它是一个随机初始化的矩阵,用于用户嵌入
# tf.random_uniform([user_vocab_size, embedding_size], -1.0, 1.0),#tf.random_uniform函数生成一个在[-1.0, 1.0)区间内均匀分布的随机矩阵,其形状是[user_vocab_size, embedding_size],其中user_vocab_size是用户词汇表的大小,embedding_size是嵌入向量的维度。
# name="W1")
# self.embedded_user = tf.nn.embedding_lookup(self.W1, self.input_u)#使用tf.nn.embedding_lookup函数查找self.W1中与self.input_u中每个元素对应的嵌入向量
# # self.embedded_users = tf.expand_dims(self.embedded_user, -1)#通过tf.expand_dims函数增加self.embedded_user张量的维度。这样做是为了保持张量的形状与模型的其他部分兼容,具体来说是为了在后续的卷积层操作中添加一个额外的空间维度
with tf.name_scope("user_embedding"):
self.W1 = tf.Variable(
tf.random_uniform([user_vocab_size, embedding_size], -1.0, 1.0),
name="W1")
# 使用tf.nn.embedding_lookup函数查找self.W1中与self.input_u中每个元素对应的嵌入向量
# 形状为 [batch_size, review_num_u, review_len_u, embedding_size]
self.embedded_user = tf.nn.embedding_lookup(self.W1, self.input_u)
# 由于self.input_u的形状是[batch_size, review_num_u, review_len_u],
# tf.nn.embedding_lookup后self.embedded_user的形状应该是[batch_size, review_num_u, review_len_u, embedding_size]
# 我们不需要使用tf.expand_dims,因为self.embedded_user已经有了正确的形状
# 接下来,在构建卷积层之前,我们需要确保self.embedded_user的形状适合卷积操作
# 通常,这意味着我们需要调整self.embedded_user的形状为[batch_size, review_len_u, 1, embedding_size]
# 这可以通过转置和重塑操作来完成
self.embedded_user_reshaped = tf.reshape(self.embedded_user,
[-1 * review_num_u, review_len_u, 1, embedding_size])
# 现在self.embedded_user_reshaped的形状是[batch_size * review_num_u, review_len_u, 1, embedding_size]
# 我们可以在卷积层中使用self.embedded_user_reshaped
pooled_outputs_u = []
for i, filter_size in enumerate(filter_sizes):
with tf.name_scope("user_conv-maxpool-%s" % filter_size):
# 定义卷积核的形状
filter_shape = [filter_size, 1, embedding_size, num_filters]
W = tf.Variable(tf.truncated_normal(filter_shape, stddev=0.1), name="W")
b = tf.Variable(tf.constant(0.1, shape=[num_filters]), name="b")
# 执行二维卷积操作
conv = tf.nn.conv2d(
self.embedded_user_reshaped, # 使用重塑后的 self.embedded_user_reshaped
W,
strides=[1, 1, 1, 1],
padding="VALID",
name="conv")
# ... 后续的ReLU和池化操作 ...
# Apply nonlinearity
h = tf.nn.relu(tf.nn.bias_add(conv, b), name="relu")
# Maxpooling over the outputs
pooled = tf.nn.max_pool(
h,
ksize=[1, review_len_u - filter_size + 1, 1, 1],
strides=[1, 1, 1, 1],
padding='VALID',
name="pool")
pooled_outputs_u.append(pooled)
num_filters_total = num_filters * len(filter_sizes)#计算总的过滤器数量,这是所有卷积层输出通道数的总和。
self.h_pool_u = tf.concat(3,pooled_outputs_u)#沿着第四个维度(通道维度)连接所有池化层的输出,得到self.h_pool_u。
self.h_pool_flat_u = tf.reshape(self.h_pool_u, [-1, review_num_u, num_filters_total])#将连接后的池化输出重塑为三维张量,以便后续处理。-1表示自动计算批次大小和评论数量的乘积
pooled_outputs_i = []#这行代码初始化了一个空列表pooled_outputs_i,用于存储后续卷积层和池化层的输出结果。
for i, filter_size in enumerate(filter_sizes):
with tf.name_scope("item_conv-maxpool-%s" % filter_size):#这是一个上下文管理器,用于设置当前操作的名称空间
# Convolution Layer
filter_shape = [filter_size, embedding_size, 1, num_filters]#定义了卷积核的形状,它是一个四维数组,分别代表卷积核的高度、宽度、输入深度和输出深度
W = tf.Variable(tf.truncated_normal(filter_shape, stddev=0.1), name="W")#创建一个权重变量W,
b = tf.Variable(tf.constant(0.1, shape=[num_filters]), name="b")#创建一个偏置变量b,它的初始值是0.1,形状为[num_filters]
self.embedded_items = tf.reshape(self.embedded_items, [-1, review_len_i, embedding_size, 1])#将输入数据self.embedded_items重塑为四维张量,以适应卷积层的输入要求
conv = tf.nn.conv2d(#执行二维卷积操作,输入是重塑后的self.embedded_items,卷积核是W,输出是卷积结果。
self.embedded_items,
W,
strides=[1, 1, 1, 1],
padding="VALID",
name="conv")
# Apply nonlinearity
h = tf.nn.relu(tf.nn.bias_add(conv, b), name="relu")#对卷积结果应用偏置,然后通过ReLU激活函数进行非线性转换
# Maxpooling over the outputs
pooled = tf.nn.max_pool(#将池化层的输出结果添加到pooled_outputs_i列表中。
h,
ksize=[1, review_len_i - filter_size + 1, 1, 1],
strides=[1, 1, 1, 1],
padding='VALID',
name="pool")
pooled_outputs_i.append(pooled)
num_filters_total = num_filters * len(filter_sizes)#计算总共的卷积核数量,它是每个filter_size对应的卷积核数量的总和
self.h_pool_i = tf.concat(3,pooled_outputs_i)#池化层的输出结果在第三维度上进行拼接,得到self.h_pool_i
self.h_pool_flat_i = tf.reshape(self.h_pool_i, [-1, review_num_i, num_filters_total])#将拼接后的张量重塑为二维张量,以便后续的处理。第一维是样本数量,第二维是每个样本的特征数量
with tf.name_scope("dropout"):#这是一个上下文管理器,用于设置当前操作的名称空间为"dropout",有助于在TensorFlow的可视化工具中更好地组织和识别操作
self.h_drop_u = tf.nn.dropout(self.h_pool_flat_u, 1.0)#应用dropout技术到上一层的输出self.h_pool_flat_u上,丢弃概率为1.0,即在训练过程中将所有的神经元输出置为0,这样做可以防止过拟合。
self.h_drop_i = tf.nn.dropout(self.h_pool_flat_i, 1.0)
with tf.name_scope("attention"):#这是另一个上下文管理器,用于设置当前操作的名称空间为"attention"
Wau = tf.Variable(
tf.random_uniform([num_filters_total, attention_size], -0.1, 0.1), name='Wau')#创建一个权重变量Wau,用于注意力机制中的用户嵌入和注意力分数的计算。
Wru = tf.Variable(
tf.random_uniform([embedding_id, attention_size], -0.1, 0.1), name='Wru')#创建一个权重变量Wru,用于计算输入嵌入和注意力分数的关系。
Wpu = tf.Variable(
tf.random_uniform([attention_size, 1], -0.1, 0.1), name='Wpu')#创建一个权重变量Wpu,用于最终的注意力分数的计算。
bau = tf.Variable(tf.constant(0.1, shape=[attention_size]), name="bau")#创建一个偏置变量bau,用于注意力分数的计算。
bbu = tf.Variable(tf.constant(0.1, shape=[1]), name="bbu")#创建一个偏置变量bbu,用于最终的注意力分数的计算
self.iid_a = tf.nn.relu(tf.nn.embedding_lookup(iidW, self.input_reuid))#通过查找表操作和ReLU激活函数,计算输入ID的嵌入表示。
self.u_j = tf.einsum('ajk,kl->ajl', tf.nn.relu(#使用爱因斯坦求和约定(einsum)来计算每个用户的注意力分数。这个分数是通过用户嵌入和项目嵌入的加权和,再加上偏置项,最后通过激活函数得到的
tf.einsum('ajk,kl->ajl', self.h_drop_u, Wau) + tf.einsum('ajk,kl->ajl', self.iid_a, Wru) + bau),
Wpu)+bbu # None*u_len*1
self.u_a = tf.nn.softmax(self.u_j,1) # none*u_len*1#使用softmax函数对注意力分数进行归一化,使得每一行的分数和为1,这样得到的是注意力权重
print(self.u_a)
Wai = tf.Variable(
tf.random_uniform([num_filters_total, attention_size], -0.1, 0.1), name='Wai')
Wri = tf.Variable(
tf.random_uniform([embedding_id, attention_size], -0.1, 0.1), name='Wri')
Wpi = tf.Variable(
tf.random_uniform([attention_size, 1], -0.1, 0.1), name='Wpi')
bai = tf.Variable(tf.constant(0.1, shape=[attention_size]), name="bai")
bbi = tf.Variable(tf.constant(0.1, shape=[1]), name="bbi")
self.uid_a = tf.nn.relu(tf.nn.embedding_lookup(uidW, self.input_reiid))
self.i_j =tf.einsum('ajk,kl->ajl', tf.nn.relu(
tf.einsum('ajk,kl->ajl', self.h_drop_i, Wai) + tf.einsum('ajk,kl->ajl', self.uid_a, Wri) + bai),
Wpi)+bbi
self.i_a = tf.nn.softmax(self.i_j,1) # none*len*1
l2_loss += tf.nn.l2_loss(Wau)#计算权重变量Wau的L2正则化损失,并将其累加到l2_loss中
l2_loss += tf.nn.l2_loss(Wru)
l2_loss += tf.nn.l2_loss(Wri)
l2_loss += tf.nn.l2_loss(Wai)
with tf.name_scope("add_reviews"):
self.u_feas = tf.reduce_sum(tf.multiply(self.u_a, self.h_drop_u), 1)#使用加权求和操作,将用户的注意力权重self.u_a和对应的隐藏状态self.h_drop_u相乘,然后对结果进行求和,得到用户的最终特征表示
self.u_feas = tf.nn.dropout(self.u_feas, self.dropout_keep_prob)#应用dropout技术到用户的最终特征表示self.u_feas上,以防止过拟合。self.dropout_keep_prob是dropout的保留概率。
self.i_feas = tf.reduce_sum(tf.multiply(self.i_a, self.h_drop_i), 1)
self.i_feas = tf.nn.dropout(self.i_feas, self.dropout_keep_prob)
with tf.name_scope("get_fea"):
#tf.Variable: 这是TensorFlow中的一个类,用于创建可以被训练和更新的变量。在神经网络中,变量通常用来存储模型的参数,如权重和偏置。
#tf.random_uniform([...], -0.1, 0.1): 这是一个函数,用于生成一个随机的均匀分布的张量
iidmf = tf.Variable(tf.random_uniform([item_num + 2, embedding_id], -0.1, 0.1), name="iidmf")#创建一个矩阵分解中的项嵌入权重变量iidmf,用于生成输入项的嵌入向量
uidmf = tf.Variable(tf.random_uniform([user_num + 2, embedding_id], -0.1, 0.1), name="uidmf")#创建一个矩阵分解中的用户嵌入权重变量uidmf,用于生成用户的嵌入向量
self.uid = tf.nn.embedding_lookup(uidmf,self.input_uid)#使用查找表操作,根据用户ID从uidmf中获取用户的嵌入向量
self.iid = tf.nn.embedding_lookup(iidmf,self.input_iid)#使用查找表操作,根据输入项ID从iidmf中获取输入项的嵌入向量。
self.uid = tf.reshape(self.uid,[-1,embedding_id])#将用户的嵌入向量重塑为二维张量,以便后续的矩阵运算
self.iid = tf.reshape(self.iid,[-1,embedding_id])#将输入项的嵌入向量重塑为二维张量
Wu = tf.Variable(#这个函数生成一个形状为[num_filters_total, n_latent]的张量,其中num_filters_total是卷积层输出的总过滤器数量,n_latent是潜在空间的维度
tf.random_uniform([num_filters_total, n_latent], -0.1, 0.1), name='Wu')
bu = tf.Variable(tf.constant(0.1, shape=[n_latent]), name="bu")
self.u_feas = tf.matmul(self.u_feas, Wu)+self.uid + bu#执行了线性变换操作。tf.matmul函数用于计算两个张量的矩阵乘法,这里将用户的注意力加权特征表示self.u_feas与权重矩阵Wu相乘
Wi = tf.Variable(
tf.random_uniform([num_filters_total, n_latent], -0.1, 0.1), name='Wi')
bi = tf.Variable(tf.constant(0.1, shape=[n_latent]), name="bi")
self.i_feas = tf.matmul(self.i_feas, Wi) +self.iid+ bi
with tf.name_scope('ncf'):
self.FM = tf.multiply(self.u_feas, self.i_feas)#执行一个逐元素的乘法操作,将用户特征表示self.u_feas和物品特征表示self.i_feas相乘
self.FM = tf.nn.relu(self.FM)#使用ReLU激活函数对乘法结果进行非线性转换
self.FM=tf.nn.dropout(self.FM,self.dropout_keep_prob)#应用dropout技术到FM的结果上,以防止过拟合
Wmul=tf.Variable(
tf.random_uniform([n_latent, 1], -0.1, 0.1), name='wmul')
self.mul=tf.matmul(self.FM,Wmul)
#用于计算张量(Tensor)在指定维度上的元素总和。在这个上下文中,它将计算self.mul中每个样本的得分
#tf.reduce_sum: 这是一个TensorFlow函数,用于计算张量(Tensor)在指定维度上的元素总和
self.score=tf.reduce_sum(self.mul,1,keep_dims=True)#对乘法结果进行求和操作,得到每个样本的预测评分。keep_dims=True保持了原始张量的维度
self.uidW2 = tf.Variable(tf.constant(0.1, shape=[user_num + 2]), name="uidW2")#创建一个包含用户偏差的变量uidW2,它是一个初始化为0.1的向量,长度为用户数量加2。
self.iidW2 = tf.Variable(tf.constant(0.1, shape=[item_num + 2]), name="iidW2")#创建一个包含物品偏差的变量iidW2,它是一个初始化为0.1的向量,长度为物品数量加2。
self.u_bias = tf.gather(self.uidW2, self.input_uid)#使用tf.gather函数从用户偏差向量uidW2中提取用户对应的偏差值
self.i_bias = tf.gather(self.iidW2, self.input_iid)#从物品偏差向量iidW2中提取物品对应的偏差值
self.Feature_bias = self.u_bias + self.i_bias#将用户偏差和物品偏差相加,得到特征偏差
self.bised = tf.Variable(tf.constant(0.1), name='bias')
#tf.constant(0.1): 这是一个TensorFlow函数,用于创建一个常数张
#创建一个全局偏差变量bised,它是一个初始化为0.1的标量
self.predictions = self.score + self.Feature_bias + self.bised#将预测评分score、特征偏差Feature_bias和全局偏差bised相加,得到最终的预测值。
with tf.name_scope("loss"):
#tf.subtract(self.predictions, self.input_y): 这是一个TensorFlow操作,用于计算预测值self.predictions和真实值self.input_y之间的逐元素差
#self.predictions是模型的预测输出,而self.input_y是实际的目标值或标签。
losses = tf.nn.l2_loss(tf.subtract(self.predictions, self.input_y))
#将L2损失与正则化项相加,得到总损失。l2_reg_lambda是正则化系数,l2_loss是在之前代码中累积的L2正则化损失。
self.loss = losses + l2_reg_lambda * l2_loss
with tf.name_scope("accuracy"):
#tf.reduce_mean(...)函数计算所有绝对差值的平均值
#tf.sqrt(...)函数计算这个平均平方差值的平方根。
#tf.subtract(self.predictions, self.input_y)计算两者之间的逐元素差值
self.mae = tf.reduce_mean(tf.abs(tf.subtract(self.predictions, self.input_y)))#计算预测值和真实值之间的平均绝对误差(Mean Absolute Error, MAE),作为模型的一个评估指标。
self.accuracy =tf.sqrt(tf.reduce_mean(tf.square(tf.subtract(self.predictions, self.input_y))))#计算预测值和真实值之间的平均平方根误差(Root Mean Squared Error, RMSE),作为模型的另一个评估指标。训练步骤 (train_step)
-
输入张量维度:
self.input_u: [batch_size, review_num_u, review_len_u] - 用户评论序列。self.input_i: [batch_size, review_num_i, review_len_i] - 商品评论序列。self.input_reuid: [batch_size, review_num_u] - 用户评论ID。self.input_reiid: [batch_size, review_num_i] - 商品评论ID。self.input_y: [batch_size, 1] - 真实评分。self.input_uid: [batch_size, 1] - 用户ID。self.input_iid: [batch_size, 1] - 商品ID。self.dropout_keep_prob: [] - dropout保留概率。
-
输出张量维度:
self.embedded_user: [batch_size, review_num_u, review_len_u, embedding_size] - 用户评论的嵌入表示。self.embedded_item: [batch_size, review_num_i, review_len_i, embedding_size] - 商品评论的嵌入表示。self.h_pool_u: [batch_size, 1, 1, num_filters_total] - 用户评论池化后的特征。self.h_pool_i: [batch_size, 1, 1, num_filters_total] - 商品评论池化后的特征。self.u_a: [batch_size, review_num_u, 1] - 用户评论的注意力权重。self.i_a: [batch_size, review_num_i, 1] - 商品评论的注意力权重。self.u_feas: [batch_size, n_latent] - 用户的聚合特征。self.i_feas: [batch_size, n_latent] - 商品的聚合特征。self.predictions: [batch_size, 1] - 预测评分。
-
输入张量维度:
- 同
__init__方法中的输入占位符。
- 同
-
输出张量维度:
accuracy: [] - 当前批次的准确度。mae: [] - 当前批次的平均绝对误差。u_a: [batch_size, review_num_u, 1] - 用户评论的注意力权重。i_a: [batch_size, review_num_i, 1] - 商品评论的注意力权重。fm: [batch_size, n_latent] - 用户和商品特征交互的结果。
-
输入张量维度:
- 同
__init__方法中的输入占位符,但通常不包括dropout相关的占位符。
- 同
-
输出张量维度:
step: [] - 当前步骤编号。loss: [] - 当前批次的损失。accuracy: [] - 当前批次的准确度。mae: [] - 当前批次的平均绝对误差。
主执行流程
-
参数解析:
- 解析命令行参数,如
embedding_dim,filter_sizes等。
- 解析命令行参数,如
-
数据加载:
- 加载用户和商品的评论文本、训练和测试数据集。
-
模型构建:
- 使用
NARRE类初始化模型。
- 使用
-
训练:
- 使用
train_step函数在训练集上执行多个训练步骤。
- 使用
-
评估:
- 在每个epoch后,使用
dev_step函数在验证集上评估模型性能。
- 在每个epoch后,使用
-
保存和恢复:
- 使用
tf.train.Saver保存和恢复模型状态。
- 使用
-
优化器:
- 使用
tf.train.AdamOptimizer作为优化器。
- 使用
-
全局步骤:
- 使用
tf.Variable来跟踪全局步骤。
- 使用
-
损失和准确度:
- 计算模型的损失和准确度指标。
五.论文的实验
基准数据集上的实验:作者在Amazon和Yelp的不同领域的基准数据集上进行了广泛的实验。这些数据集覆盖了不同的电子商务类别,包括玩具和游戏、Kindle商店、电影和电视以及Yelp上的餐厅评价。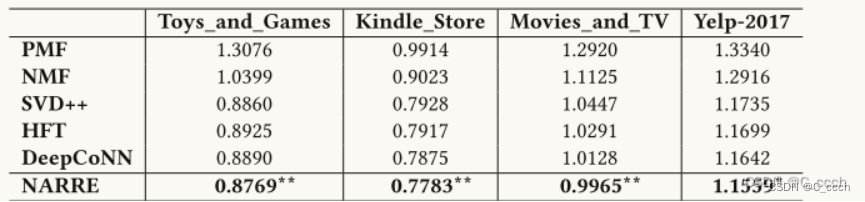
性能比较:NARRE模型与现有的推荐系统方法进行了比较,包括PMF(概率矩阵分解)、NMF(非负矩阵分解)、SVD++(奇异值分解的扩展模型)、HFT(结合评论和评分的模型)和DeepCoNN(利用深度学习技术处理评论的模型)。比较的指标是评分预测的准确性 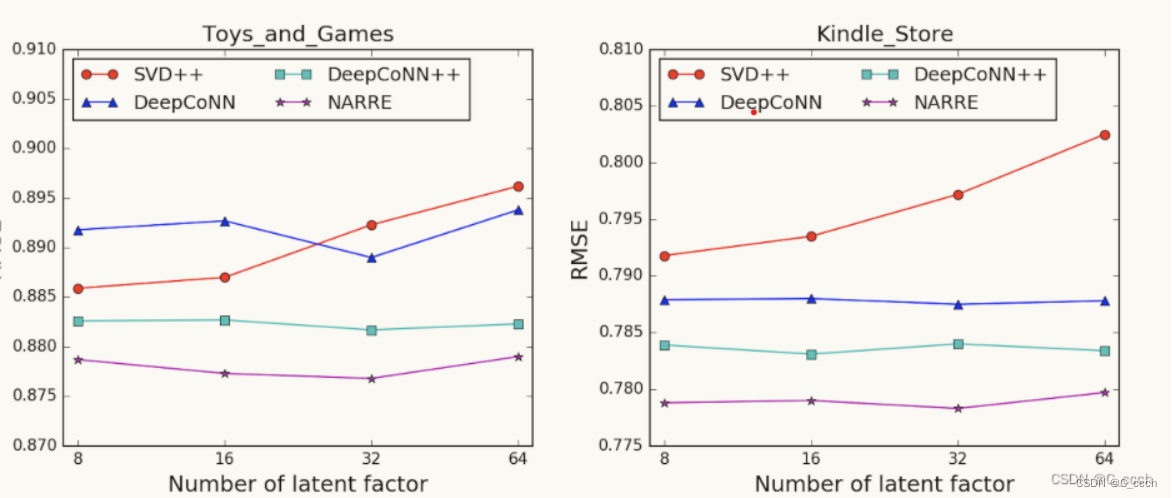
众包评估:通过众包平台进行的评估,以确定NARRE模型选择的评论与用户认为有用的评论之间的一致性。众包评估包括两方面的任务:
评论级别的有用性分析(Ua):评估器对每个商品的前10个评论进行有用性标注。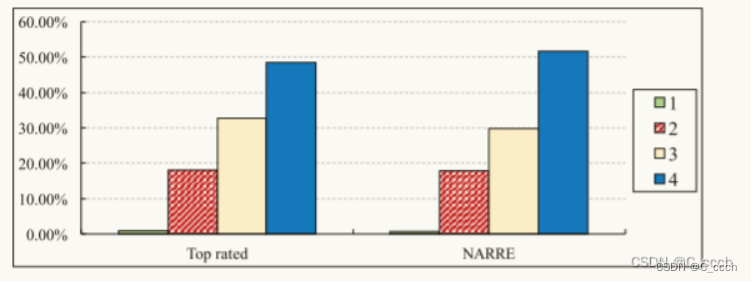
成对有用性分析(Ub):评估器对由NARRE和基于评分的有用性方法(Top_Rated_Useful)选择评论进行成对比较。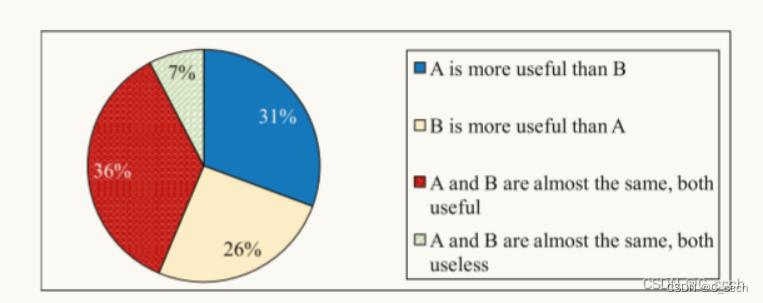
参数敏感性分析:研究了模型中不同参数对性能的影响,如dropout比例。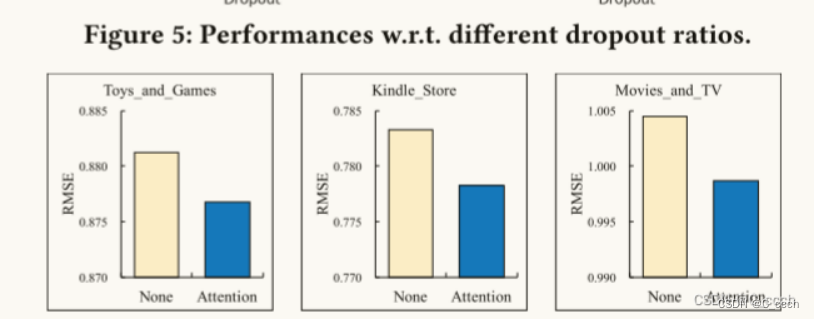
六.总结
这篇论文介绍了NARRE模型,这是一个基于神经网络的注意力机制模型,用于改进电子商务推荐系统中的评分预测并自动选择有用的用户评论以提供决策支持。NARRE通过分析评论内容和用户行为,能够同时预测商品评分并识别出对其他用户决策有帮助的评论,从而增强了推荐系统的准确性和透明度。在多个真实世界数据集上的实验结果表明,NARRE在评分预测方面超越了现有的推荐方法,并且在没有用户评分的情况下也能有效地识别有用评论,为构建更高效和可解释的推荐系统提供了新的可能性。















 3850
3850

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









