






前言:
服务推荐提供了一种有效的解决方案,可以从大量用户设备产生的巨大且不断增加的大数据中提取有价值的信息。然而,分布式和丰富的多源大数据资源在经济成本和有效的服务推荐方法方面对基于云的集中式数据存储和价值挖掘方法提出了挑战。鉴于这些挑战,我们提出了一种基于深度神经协同过滤的多源数据服务推荐方法(即,NCF-MS),采用云边缘协作计算范式构建推荐模型。
出处:《Tsinghua Science and Technology》期刊上,卷号为29,第3期,发表日期为2024年6月
源代码:未找到
一.简要介绍
这篇文章提出了一个名为NCF-MS(Neural Collaborative Filtering with Multi-Source data)的深度神经协同过滤服务推荐模型,该模型是为了解决大数据环境下的服务推荐问题而设计的。下面是对模型的简要介绍:
**问题背景**:随着物联网(IoT)设备的增多,用户设备产生的数据量急剧增加,导致“信息过载”问题。服务推荐系统可以帮助用户从大量数据中提取有价值的信息。
**挑战**:在分布式和丰富的多源大数据资源环境下,传统的集中式云服务推荐方法面临经济成本高和推荐方法效率低的挑战。
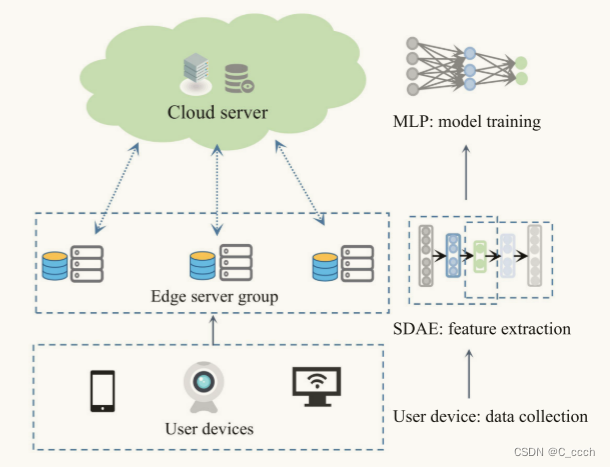
**云-边缘协作计算范式**:为了解决这些挑战,文章提出了利用云-边缘协作计算范式,该范式允许部分计算和存储资源更接近用户设备,从而节省成本。
**NCF-MS模型组成**:
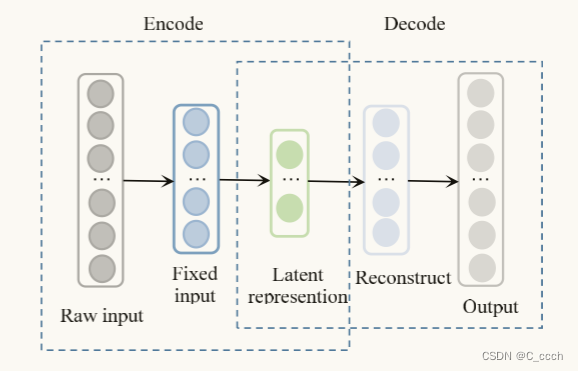
- **SDAE(Stacked Denoising Auto Encoder)模块**:用于从辅助用户档案和服务属性中提取用户和服务的潜在特征。
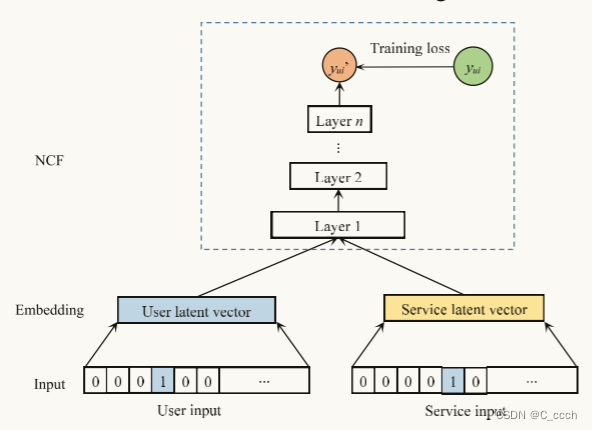
- **MLP(Multiple Layer Perceptron)模块**:用于整合辅助用户/服务特征,并训练推荐模型。
**模型工作流程**:
- **特征提取阶段**:利用SDAE模块在边缘服务器上提取用户和服务的潜在特征。
- **模型训练阶段**:云服务器接收来自边缘服务器的用户和服务潜在特征,并使用MLP网络训练推荐模型。
- **推荐预测阶段**:使用训练好的模型计算用户/服务对的预测评分,并为每个目标用户推荐未调用过的服务。
NCF-MS模型的核心在于结合深度学习和云-边缘计算的优势,通过协同过滤和多源数据融合来提高服务推荐的准确性和效率。
二.主要贡献
第一,NCF-MS模型的创新:提出了一种融合多源数据的深度神经协同过滤(NCF-MS)服务推荐方法,该方法通过结合用户档案和服务属性来提高推荐系统的准确性,并解决数据稀疏性问题。第二,云-边缘协作计算范式的实现:采用云-边缘协作计算范式,通过在边缘服务器上执行特征提取和在云服务器上进行模型训练,优化了资源使用效率并降低了数据传输成本。第三,实验验证与性能比较:在三个公共数据集上对NCF-MS模型进行了广泛的实验评估,并与现有推荐方法进行了比较,验证了其在推荐性能上的优势。
三.论文模型
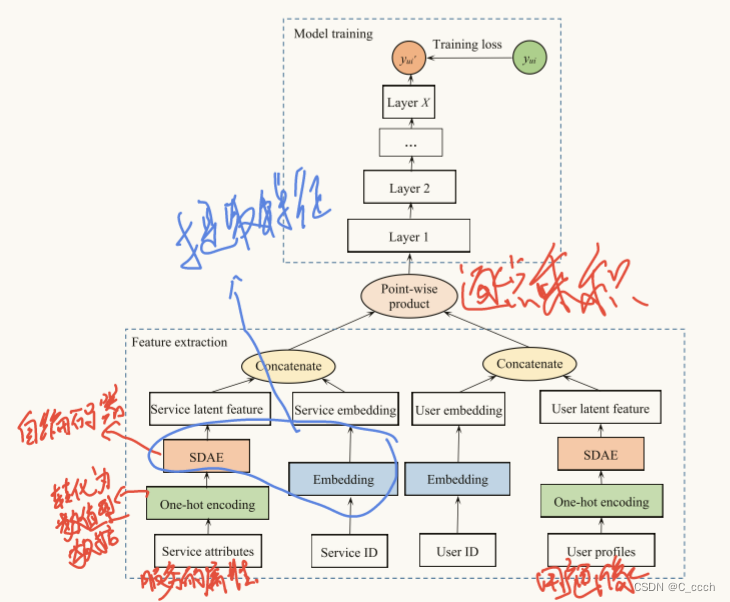
NCF-MS模型的工作流程大致可以分为三个主要阶段:特征提取、模型训练和推荐预测。以下是每个阶段的详细介绍,包括相关公式:
1.特征提取(Feature Extraction)
**目标**:从用户-服务交互记录、用户档案和服务属性中提取潜在的、有用的特征。
**步骤**:
- **用户-服务交互记录特征提取**:
定义用户-服务交互矩阵 \( Y \),其中 \( y_{ui} \) 表示用户 \( u \) 是否与服务 \( i \) 交互过。
\[ y_{ui} = \begin{cases}
1, & \text{if user \( u \) invoked service \( i \)} \\
0, & \text{otherwise}
\end{cases} \]
使用嵌入技术对用户和服务机构进行编码,得到 \( P_u \) 和 \( P_i \)。
- **用户档案特征提取**:
定义用户档案,使用独热编码(one-hot encoding)将用户档案的每个属性编码为数值向量,然后通过SDAE模块提取潜在用户特征 \( V_u \)。
- **服务属性特征提取**:
与用户档案类似,服务属性也通过独热编码和SDAE模块提取潜在服务特征 \( V_i \)。
2. 模型训练(Model Training)
在模型训练阶段,MLP用于学习用户和服务质量之间的复杂关系。以下是MLP模型训练的扩展步骤和公式:
特征融合
首先,将从SDAE中提取的潜在特征与原始特征进行融合,形成完整的用户和商品特征向量。
对于用户 𝑢u 和服务 𝑖i,特征融合可以表示为: 𝑈𝑢=𝑐𝑜𝑛𝑐𝑎𝑡𝑒𝑛𝑎𝑡𝑒(𝑃𝑢,𝑉𝑢)Uu=concatenate(Pu,Vu) 𝐼𝑖=𝑐𝑜𝑛𝑐𝑎𝑡𝑒𝑛𝑎𝑡𝑒(𝑃𝑖,𝑉𝑖)Ii=concatenate(Pi,Vi)
其中,𝑃𝑢Pu 和 𝑃𝑖Pi 是通过嵌入层得到的特征,𝑉𝑢Vu 和 𝑉𝑖Vi 是通过SDAE提取的潜在特征。
MLP模型参数初始化
在训练开始之前,需要初始化MLP模型的权重 𝑊W 和偏置 𝑏b。
模型训练迭代
在每个训练周期(epoch)中,执行以下步骤:
-
通过MLP网络计算预测的用户-服务评分 𝑦𝑢𝑖′yui′: 𝑦𝑢𝑖′=𝑓(𝑈𝑢,𝐼𝑖∣𝑊,𝑏)yui′=f(Uu,Ii∣W,b) 其中,𝑓f 是激活函数,可以是ReLU或其他非线性激活函数。
-
计算损失函数 𝐿L,该函数衡量预测评分 𝑦𝑢𝑖′yui′ 和实际评分 𝑦𝑢𝑖yui 之间的差异。对于二元分类问题,可以使用交叉熵损失: 𝐿=−∑(𝑢,𝑖)∈𝑌𝑦𝑢𝑖log𝑦𝑢𝑖′+(1−𝑦𝑢𝑖)log(1−𝑦𝑢𝑖′)L=−∑(u,i)∈Yyuilogyui′+(1−yui)log(1−yui′)
-
使用随机梯度下降(SGD)或其他优化算法来更新MLP模型的权重 𝑊W 和偏置 𝑏b,以最小化损失函数 𝐿L。
损失函数的优化
损失函数的优化可以使用以下形式的梯度下降: 𝑊𝑛𝑒𝑤=𝑊𝑜𝑙𝑑−𝛼⋅∇𝑊𝐿Wnew=Wold−α⋅∇WL 𝑏𝑛𝑒𝑤=𝑏𝑜𝑙𝑑−𝛼⋅∇𝑏𝐿bnew=bold−α⋅∇bL 其中,𝛼α 是学习率,∇𝑊𝐿∇WL 和 ∇𝑏𝐿∇bL 是损失函数相对于权重和偏置的梯度。
3. 推荐预测(Recommendation Prediction)
在模型训练完成后,可以进行推荐预测:
-
评分计算:使用训练好的MLP模型计算每个用户-服务对的预测评分 𝑦𝑢𝑖′yui′。
-
服务排序:根据预测评分对服务进行排序,得到每个用户的推荐列表。
-
推荐生成:为每个用户推荐评分最高的服务,生成最终的推荐结果。
通过这个过程,NCF-MS模型能够结合多源数据和深度学习的能力,为用户提供个性化的服务推荐。
四.输入和输出的维度
在NCF-MS模型中,输入和输出的维度取决于几个关键组件:用户-服务交互矩阵的维度、嵌入层的维度、以及MLP网络中隐藏层的维度。以下是各个阶段的输入和输出维度的描述:
1. 特征提取阶段
**用户-服务交互记录特征提取**:
- 输入:用户-服务交互矩阵 \( Y \),其维度为 \( M \times N \),其中 \( M \) 是用户的数量,\( N \) 是服务的数量。
- 输出:每个用户 \( u \) 和服务 \( i \) 的嵌入表示 \( P_u \) 和 \( P_i \),它们的维度通常是预先设定的,比如 \( d \) 维。
**用户档案特征提取**:
- 输入:用户档案数据,通常是类别型数据,比如用户的年龄、性别、职业等。
- 输出:经过独热编码和SDAE处理后的潜在用户特征向量 \( V_u \),维度为 \( d' \)。
**服务属性特征提取**:
- 输入:服务属性数据,如服务类型、功能等。
- 输出:潜在服务特征向量 \( V_i \),维度同样为 \( d' \)。
### 2. 模型训练阶段
**特征融合**:
- 输入:用户特征 \( U_u \) 和服务特征 \( I_i \),每个都是融合后的向量,维度为 \( d + d' \)。
- 输出:融合后的用户-服务特征对,用于MLP模型训练。
**MLP模型训练**:
- 输入:用户-服务特征对,维度为 \( (d + d') \times 1 \)。
- 输出:预测的用户-服务评分 \( y'_{ui} \),是一个标量值,表示用户对服务的偏好程度。
### 3. 推荐预测阶段
**评分计算**:
- 输入:用户-服务特征对,维度与MLP模型训练阶段相同,即 \( (d + d') \times 1 \)。
- 输出:每个用户-服务对的预测评分 \( y'_{ui} \),维度为 \( 1 \times 1 \)。
**服务排序和推荐生成**:
- 输入:所有用户-服务对的预测评分矩阵。
- 输出:为每个用户生成的推荐服务列表,列表的长度可以根据需要进行设定,比如取前 \( K \) 个服务。
模型伪代码

五.论文的实验
实验设置
-
数据集:实验使用了三个公共数据集进行模拟,分别是:
- Santander Bank 数据集
- Amazon AToys 数据集
- Amazon AMusic 数据集
-
数据集预处理:为了提高推荐准确性并考虑到设备内存限制,原始数据集经过筛选,选择用户数量少于5000的记录,并且每个用户至少与5个服务交互,每个服务至少被20个用户调用。
-
基线方法:NCF-MS方法与以下三种现有的基线方法进行比较:
- ItemKNN:基于项目的协同过滤方法。
- NCF:采用神经网络计算用户和服务之间交互的推荐模型。
- BPR:使用隐式反馈进行推荐的矩阵分解方法。
-
实验环境:
- CPU:Intel(R) Core(TM) i7-10870H CPU @ 2.20GHz
- 内存:8 GB
- 开发工具:Python (Tensorflow)
- 系统环境:Windows 10 64 bits
-
模型参数:
- 模型参数初始化遵循随机高斯分布。
- 学习率设置为0.001。
- MLP模块的数量设置为3层。
-
评估指标:使用以下两个指标评估推荐模型的性能:
- HR@K(Hit Rate):前K个推荐结果的召回率。
- NDCG@K(Normalized Discounted Cumulative Gain):推荐列表中服务的排序质量。
实验结果
-
性能比较:通过比较HR@10和NDCG@10指标,NCF-MS方法在所有三个数据集上均优于ItemKNN、BPR和NCF方法。

-
迭代性能:随着迭代次数的增加,所有方法的性能都在提高,但NCF-MS始终保持最佳性能。
-
数据稀疏性影响:由于数据集的高稀疏性(超过99%),仅使用用户-服务交互记录的方法(ItemKNN、BPR和NCF)受到限制。通过融合多源数据,NCF-MS能够有效提高推荐准确性。
-
与NCF方法的比较:NCF-MS在所有数据集上的性能均优于原生的NCF方法,表明多源数据融合可以捕捉更准确的用户偏好。
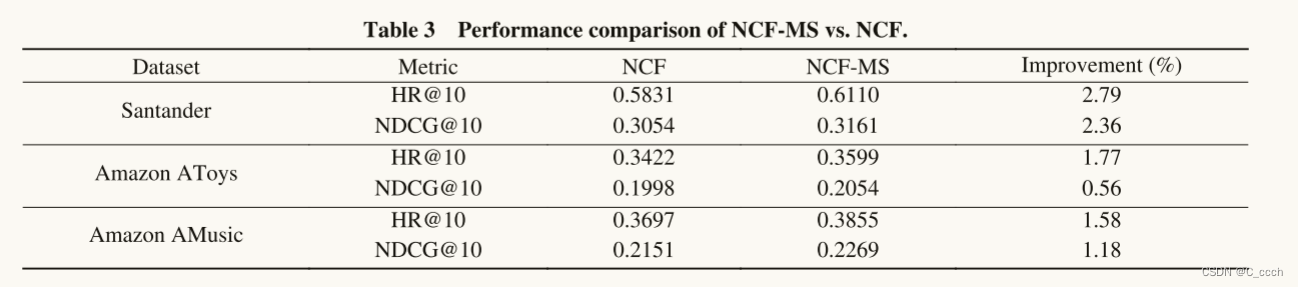
-
改进空间:尽管NCF-MS的性能有所提升,但与NCF方法相比并没有显著优势,表明用户档案和服务属性可能包含有限的潜在用户偏好信息。未来的工作可以通过融合更多准确的辅助信息,如用户-服务评论,来提取更准确的用户/服务潜在特征
六.总结
文章提出的NCF-MS模型通过融合多源数据并采用云-边缘计算范式,有效地提升了服务推荐系统的准确性。在特征提取阶段,模型利用SDAE从用户档案和服务属性中提取潜在特征;在模型训练阶段,通过MLP网络整合特征并优化参数;最后,在推荐预测阶段,模型为用户生成个性化的服务推荐。实验结果表明,NCF-MS在三个公共数据集上的性能均优于现有基线方法,尤其是在处理高数据稀疏性问题时。尽管如此,模型仍有改进空间,未来的工作将考虑融合更多类型的辅助信息,如用户评论,以进一步提升推荐结果的灵活性和准确性。















 182
182

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









