







14.1 引言
14.1.3 科学理念
1.数据科学
数据科学将数据挖掘、统计分析和机器学习与数据集成整合,结合数据建模能力,去构建预测模型、探索数据内容模式。
数据科学依赖于:
1)丰富的数据源。具有能够展示隐藏在组织或客户行为中不可见模式的潜力。
2)信息组织和分析。用来领会数据内容,结合数据集针对有意义模式进行假设和测试的技术。
3)信息交付。针对数据运行模型和数学算法,进行可视化展示及其他方式输出,以此加强对行为的深入洞察。
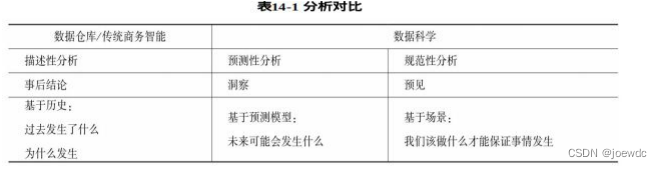
4)展示发现和数据洞察。分析和揭示结果,分享洞察观点(表 14-1)对比了传统的数据仓库/商务智能与基于数据科学技术实现的预测性分析和规范性分析的作用。
2.数据科学的过程
在数据科学的过程中 获得和接收数据源工作量最大
3.大数据
早 期 ,人 们 通 过 3V 来 定 义 大 数 据 含 义 的 特 征 :数 据 量 大(Volume)、数据更新快(Velocity)、数据类型多样/可变(Variety)(Laney,2001)。随着越来越多的组织开始深挖大数据的潜力,已经不止于以上三个 V。V 列表有了更多的扩展:
1)数据量大(Volume)。大数据通常拥有上千个实体或数十亿个记录中的元素。
2)数据更新快(Velocity)。指数据被捕获、生成或共享的速度。大数据通常实时地生成、分发及进行分析。
3)数据类型多样/可变(Variety/Variability)。指抓取或传递数据的形式。大数据需要多种格式储存。通常,数据集内或跨数据集的数据结构是不一致的。
4)数据黏度大(Viscosity)。指数据使用或集成的难度比较高。
5)数据波动性大(Volatility)。指数据更改的频率,以及由此导致的数据有效时间短。
6) 数据准确性低。指数据的可靠程度不高。
5.大数据来源
结构化数据+非结构化数据
6.数据湖
数据湖是一种可以 提取、存储、评估和分析不同类型和结构海量数据的环境,可供多种场景使用。如可以提供:
1)数据科学家可以挖掘和分析数据的环境。
2)原始数据的集中存储区域,只需很少量的转换(如果需要的话)。
3)数据仓库明细历史数据的备用存储区域。
4)信息记录的在线归档。
5)可以通过自动化的模型识别提取流数据的环境。
数据湖的风险在于,它可能很快会变成 数据沼泽 ——杂乱、不干净、不一致。为了建立数据湖中的内容清单,在数据被摄取时对元数据进行管理至关重要。
Q:数据湖管理不好会变成?
A 池塘 B 沼泽 C 大海A:不是池塘,是沼泽。
Q:数据湖是否管理好表示什么?
A 元数据是否管理好?B 数据质量得到保证A:元数据是否管理好
7.基于服务的架构
基于服务的体系结构(Services-Based Architecture,SBA)
1)批处理层
2)加速层
3)服务层
8.机器学习
机器学习探索了学习算法的构建和研究。这些算法一般分为三种类型:
1)监督学习(Supervised learning)。基于通用规则(如将 SPAM 邮件与非 SPAM 邮件分开)。
2)无监督学习(Unsupervised learning)。基于找到的那些隐藏的规律(数据挖掘)。
3)强化学习(Reinforcement learning)。基于目标的实现(如在国际象棋中击败对手)。
Q:预测明天销售额是多少?A:有无限可能性,
无监督学习
Q:预测明年销售额是否笔今年多?A 多 B 少 C 一样 D 不知道
监督学习
12.规范分析
规范分析(Prescriptive Analytics)比预测分析更进一步,它对将会影响结果的动作进行定义,而不仅仅是根据已发生的动作预测结果。 规范分析预计将会发生什么,何时会发生,并暗示它将会发生的原因。由于规范分析可以显示各种决策的含义,因此可以建议如何利用机会或避免风险。规范分析可以不断接收新数据以重新预测和重新规定。该过程可以提高预测准确性,并提供更好的方案。















 429
429











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









