







 本文围绕Java线程展开,介绍了线程的实现方式,如继承Thread类、实现Runnable和Callable接口、使用线程池等;阐述了守护线程和非守护线程的区别;讲解了ThreadLocal的使用和内部结构;对比了wait、sleep等方法;还提及线程状态、调度模型以及内核线程与用户线程的关系,并与Go语言协程作了对比。
本文围绕Java线程展开,介绍了线程的实现方式,如继承Thread类、实现Runnable和Callable接口、使用线程池等;阐述了守护线程和非守护线程的区别;讲解了ThreadLocal的使用和内部结构;对比了wait、sleep等方法;还提及线程状态、调度模型以及内核线程与用户线程的关系,并与Go语言协程作了对比。
一、java线程实现方式
1、继承Thread类
Thread类是实现了Runnable接口的类,继承它的子类就会继承Thread的方法。我们需要重写run方法,新建线程对象,并通过start方法开启线程:
class MyThread1 extends Thread {
@Override
public void run() {
System.out.println("继承Thread的run");
}
public static void main(String[] args) {
MyThread1 t1 = new MyThread1();
t1.start(); // 通过start()调用
}
}
可以使用函数式编程方法,减少代码量,简化开发:
new Thread() {
public void run() {
System.out.println("继承Thread的run");
}
}.start();
2、实现Runnable接口
java是单继承的,如果我们自己定义的线程类已经继承了别的父类,就不能再继承Thread,这时就可以通过实现Runnable接口,来创建线程。但我们又想用Thread里面已经写好的各种方法,所以使用Thread的构造函数创建线程,其中要传入我们自定义实现的Runnable类实例。
class MyThread implements Runnable {
@Override
public void run() {
System.out.println("实现Runnable接口");
System.out.println(Thread.currentThread().getName());
}
public static void main(String[] args) {
MyThread run = new MyThread();
Thread t1 = new Thread(run, "线程1"); // 传入实现类对象,第二个参数是设置线程的名字
Thread t2 = new Thread(run,"线程2");
t1.start();
t2.start();
}
}
3、实现Callable接口
前面两种实现线程的方法,主要的局限在于对多线程运行的本身缺少监督。通过使用Callable接口和Futrue接口的实现类,可以实现对线程执行过程的控制和对计算结果(计算任务返回值)的获取。
实现步骤:
- 编写任务实现类,去实现Callable接口,注意接口的泛型为call方法的返回值类型;
- 重写call方法,此方法可以有返回值,注意:1)前面两种实现线程的方法,重写run方法时不可有返回值,因为Runnable接口中的run方法返回值为void;2)call方法可以抛出异常,异常可以被捕获,但Runnable接口的run方法只能抛出运行时异常,且无法被捕获处理;
- 创建任务对象;
- 创建Futrue对象,构造函数传入任务对象实例;
- 创建Thread对象,传入Futrue对象;
- 调用Thread对象的start方法,开启线程。
class MyThread implements Callable<Integer> { // 创建任务类,实现Callable接口
@Override
public Integer call() throws Exception { // 重写call方法
return null;
}
public static void main(String[] args) {
MyThread t = new MyThread(); // 创建任务对象
FutureTask<Integer> res = new FutureTask<>(t); // 创建Futrue对象,用于接收任务的计算结果
new Thread(res).start(); // 创建线程对象,调用其start方法,开启线程
}
}
5、使用线程池创建对象
在我另一篇文章里:java线程池ThreadPollExecutor详解
二、java线程类型
java 中线程一共有两种类型:守护线程( daemon thread)和用户线程( user thread),又叫非守护线程
1、守护线程
可以通过thread.setDaemon(true)方法设置当前线程为守护线程,thread.setDaemon(true)必须在thread.start()之前设置,否则会抛出一个IllegalThreadStateException异常。
在守护线程中开启的新线程也将是守护线程。守护线程顾名思义是用来守护非守护线程的,是给所有非守护进程提供服务的,所以在 jvm 执行完所有的非守护进程之后,守护线程才停止运行,然后jvm才退出,最典型的守护线程就是 java 的垃圾回收线程。
jvm不关心守护线程的运行状态,当所有非守护线程执行完毕,直接停止守护线程。
2、非守护线程
java 线程默认是非守护线程,当主线程运行完之后,只要主线程里面有非守护线程,jvm 就不会退出,直到所有的非守护线程执行完之后,jvm 才会停止守护线程,然后退出。
三、ThreadLocal
1、一个栗子
提供线程级别变量,变量只对当前线程可见。一个例子:
public class ThreadLocalTest {
static ThreadLocal<Person> tl = new ThreadLocal<>(); // 看上去只有一个tl,实际上它的get和set时是与当前线程关联的
public static void main(String[] args) {
new Thread(() -> { // 第一个线程,尝试获取第2个线程设置的Person对象
try {
TimeUnit.SECONDS.sleep(2);
} catch (Exception e) {
e.printStackTrace();
}
System.out.println(tl.get()); // 输出为null,因为第1个线程没有在ThreadLocal中设置任何东西
}).start();
new Thread(() -> { // 第2个线程,在ThreadLocal中设置Person对象
try {
TimeUnit.SECONDS.sleep(1);
} catch (Exception e) {
e.printStackTrace();
}
tl.set(new Person()); // 设置Person对象,此对象只属于这个线程,别的线程获取不到
}).start();
}
}
class Person {
String name;
int age;
}
2、内部结构
set方法:
public void set(T value) {
Thread t = Thread.currentThread();
ThreadLocal.ThreadLocalMap map = getMap(t); // 通过当前线程获得相应的专属该线程的变量
if (map != null)
map.set(this, value);
else
createMap(t, value); // 初始化map
}
ThreadLocalMap getMap(Thread t) {
return t.threadLocals; // 发现线程当前线程t的一个threadLocals属性,其实就是当前线程对应的一个ThreadLocalMap
}
void createMap(Thread t, T firstValue) { // 初始化map
t.threadLocals = new ThreadLocalMap(this, firstValue);
}
相比于“使用锁控制共享变量访问顺序”的解决方案,ThreadLocal是用空间换时间的方案,规避了竞争问题,因为每个线程都有属于自己的变量。
再看看map的set方法:
private void set(ThreadLocal<?> key, Object value) {
Entry[] tab = table;
int len = tab.length;
int i = key.threadLocalHashCode & (len-1);
for (Entry e = tab[i];
e != null;
e = tab[i = nextIndex(i, len)]) {
ThreadLocal<?> k = e.get();
if (k == key) {
e.value = value;
return;
}
if (k == null) {
replaceStaleEntry(key, value, i);
return;
}
}
tab[i] = new Entry(key, value); // kv对被放在了Entry中
int sz = ++size;
if (!cleanSomeSlots(i, sz) && sz >= threshold)
rehash();
}
这个Entry是ThreadLocal的内部类,继承了弱引用:
static class Entry extends WeakReference<ThreadLocal<?>> {
Object value;
Entry(ThreadLocal<?> k, Object v) {
super(k); // 调用父类弱引用的构造函数,创建一个弱引用,这个弱引用指向当前线程
value = v;
}
}
为什么要给key创建弱引用?答:防止内存泄漏。当tl不再被使用,对ThreadLocal对象的强引用一消失,当前线程也不会再使用自己的ThreadLocalMap对象,Entry中的key这个弱引用也会消失。
还有一件事,tl还在使用中,但某进程的ThreadLocalMap不再使用,一定要remove掉,不然还是会发生内存泄露:
tl.set(new Person());
tl.remove();
四、wait与sleep
1、wait
wait是Object中的方法,调用wait方法会使得当前线程释放已持有的资源,并加入到等待队列中。所以调用某资源的wait方法的线程必须已经持有该锁,不然就会报错。可以通过传入参数,设置调用wait方法后,阻塞线程的唤醒方式,如果传一个时间参数进去的,那么在指定时间内,如果没有其他线程唤醒自己,则主动唤醒自己。如果传0或者不传,则表示永久等待,直到外界,即其他线程的唤醒或这个等待中线程被中断,才会脱离阻塞状态。注意:中断只是唤醒线程的另一种方式,即中断与阻塞没有必然联系。
public static void main(String[] args) {
Object lock = new Object(); // 互斥资源
Thread t1 = new Thread(() -> {
synchronized (lock) { // 获取资源,也叫获取锁
System.out.println("t1获取到了锁");
try {
System.out.println("t1休眠1秒");
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("调用wait");
try {
lock.wait(); // 前面t1已经获取到了这个锁,所以调用wait不会报错
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("被唤醒");
}
}, "thread1");
t1.start();
Thread t2 = new Thread(() -> {
synchronized (lock) { // t2获取锁
System.out.println("t2获得锁");
System.out.println("唤醒t1");
lock.notify();
}
}, "t2");
t2.start();
}
wait底层调用了本地方法,java源码看不到。
查看一下调用wait前后,线程的状态:
public static void main(String[] args) {
Object lock = new Object(); // 互斥资源
Thread t1 = new Thread(() -> {
synchronized (lock) { // 获取资源=获取锁
System.out.println("t1获取到了锁");
try {
System.out.println("t1休眠1秒");
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("t1调用wait前的状态:"+Thread.currentThread().getState());
System.out.println("调用wait");
try {
lock.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("被唤醒");
}
}, "thread1");
t1.start();
try{
TimeUnit.SECONDS.sleep(2);
System.out.println("调用wait后t1的状态:"+t1.getState());
} catch(Exception e) {
e.printStackTrace();
}
}
实际再多线程并发场景下,wait方法需要用在while循环内,即:
while(条件不满足) { // 此处的条件往往是当前线程能够继续运行的一系列条件,无法满足这些条件时,线程会阻塞,即调用wait方法,若满足就会跳出while循环,执行当前线程的逻辑
wait();
}
如果不用在循环中,而是简单的if中,会出现什么情况?
if(条件不满足) {
wait();
}
在多线程并发场景中,如果多个线程都被唤醒,但只有一个线程拿到了锁资源,别的线程就不可以使用这个锁资源,否则会出现超额消费等不符合预期的运行结果。这些未取得锁资源的线程就需要继续阻塞等待,即需要再调用wait使其进入等待队列,所以需要再进入循环判断。
2、notify与notifyAll
也在Object中,调用了某对象的wait方法后,相应线程会进入该对象的等待队列,状态变成阻塞。当别的线程获取到该对象的锁后,调用该对象的notify方法,JVM会随机选取该对象的线程等待池中的一个线程去唤醒,被唤醒线程再次成为可运行线程。
notifyAll会将全部阻塞线程由等待池移到锁池,让这些线程参与相应锁的竞争,竞争成功则继续执行,如果不成功则留在锁池等待锁被释放后再次参与竞争。
只有执行notify的线程执行完毕了,持有锁的线程才会释放锁,被唤醒的线程才会拿到锁。
3、sleep
sleep是线程中的方法,不会导致当前线程释放已经获得的资源,只会让当前线程休眠一段时间,之后会自己苏醒过来,无需其他线程唤醒它。底层也是本地方法实现。
4、为什么要把wait、notify、notifyAll定义在Object类中?
答:因为Java的所有类都继承了Object,Java想让任何对象都可以作为锁。既然是线程放弃对象锁,那为什么不把wait()定义在Thread类里面呢,新定义的线程继承于Thread类,也不需要重新定义wait()方法的实现。因为,一个线程可以持有很多锁,一个线程放弃锁的时候,到底要放弃哪个锁?这种设计并不是不能实现,只是管理起来更加复杂。
5、yield
Thread类的静态方法,可以将线程从运行态转为就绪态。注意sleep是将线程从运行态转为阻塞态,它们都是Thread类的静态方法,都不会放弃锁资源。
yeild不被建议使用在线程并发管理上,因为yield只是让出CPU的控制权,使当前的线程处于可运行(就绪)状态,说明它让出控制权之后有可能还是会立即执行的。用这个方法的话,线程的运行是处于不可控状态的。
yeild让出的cpu执行机会,只可以给到与它优先级相同的其他线程,但sleep就可以给到任意优先级的线程。
6、同步方法和同步块,哪个是更好的选择?
原则:同步的范围越小越好。所以同步代码块是更好的选择,因为它不会锁住整个对象(当然,你也可以让它锁住整个对象);同步方法会锁住整个对象,哪怕这个类中有多个不相关联的同步块,这通常会导致他们停止执行并且需要等待获得这个对象上的锁。
同步块更要符合开放调用的原则,只在需要锁住的代码块锁住相应的对象,这样从侧面来说也可以避免死锁。
synchronized(this)以及非static的synchronized方法(至于static synchronized方法请往下看),只能防止多个线程同时执行同一个对象的同步代码段。
六、线程状态与调度
新建(尚未获得资源的新线程)、就绪(可运行,拿到了所有资源,只差CPU)、运行中、阻塞、死亡
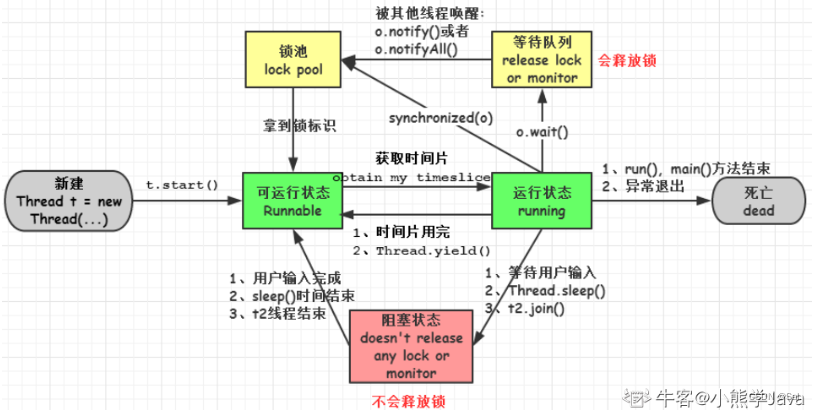
注:stop会终止线程,使其进入死亡状态
主要有两种调度模型:分时调度模型和抢占式调度模型。
- 分时调度模型是指让所有的线程轮流获得 cpu 的使用权,并且平均分配每个线程占用的 CPU的时间片;
- JVM采用抢占式调度模型,是指优先让可运行池中优先级高的线程占用CPU,如果可运行池中的线程优先级相同,那么就随机选择一个线程,使其占用CPU。处于运行状态的线程会一直运行,直至它不得不放弃 CPU。
但是,线程调度整体来看是无法受到 Java 虚拟机控制的,最终是由OS负责调度,OS又是时间片调度的,所以由应用程序来控制它是更好的选择,也就是说不要让应用程序依赖于操作系统来调度线程。
七、内核线程与用户线程
用户线程就是应用程序通过JVM创建的线程,内核线程是CPU中真正运行的线程。它们不一定是一一对应的。
由c语言编写的程序,通过直接调用内核接口来创建的线程,都是内核中的线程。但JVM是个虚拟机,java程序创建的一个线程只在jvm中有实体存在,但会相应地创建一个内核级别的线程,运行在内核中,它们是1:1的关系。
但在go语言中,执行单个任务的是协程,它和内核线程是多对一的关系。在go程序启动时,会在内核中提前创建多个内核线程,当程序中使用了go关键字启动协程时,这些任务就直接交由内核线程处理。具体形式就是,多个协程任务会放在一个队列中,形成多个任务队列,由多个内核线程协调地去完成。
java中用户线程和内核线程的1:1关系,导致在编写java程序时,需要额外考虑线程切换对系统运行效率造成的影响,若线程数量过多,会导致很多的资源都花在了线程切换上,因此需要程序员考虑用户线程的数量情况。但go语言的协程使得程序员不用再考虑这一点,即使创建很多协程,也不会增加太多线程切换消耗,一般创建20000个协程是没有问题的。当然了,凡事都有一个限度,如果协程过多,也会导致内核线程的频繁切换。协程与内核线程的模型大致为这样:
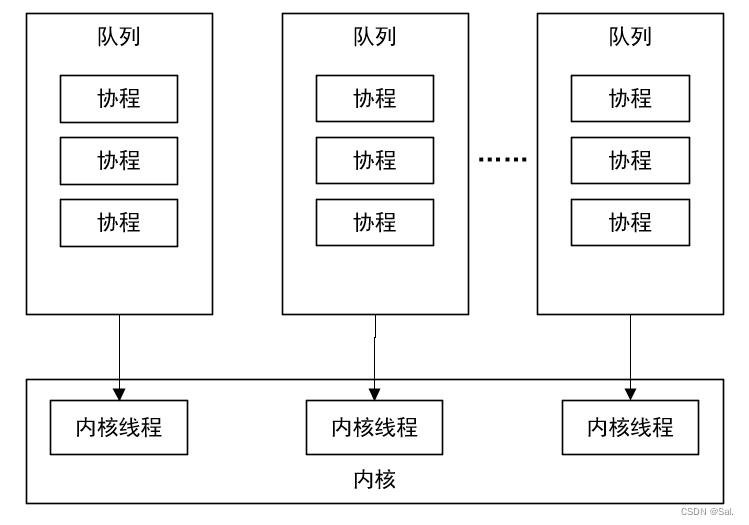
这样看起来,协程的处理流程有些线程池的思想,但不完全一样。在java中,有一种线程池的实现叫做ForkJoinPool,他的模式与上面go语言的协程很像,但不同的是,java做不到不同队列中的用户线程之间的同步。go语言却可以做到不同队列中协程之间的同步,怎么做到的呢?其实是在用户空间模拟了cpu的执行流程。当某协程执行到某个位置时,需要切换到别的协程,以进行协程同步,go就会将当前协程的上下文进行存储,然后切换到别的协程上去,实际上用到了栈,这里不做过多解释,有兴趣可以去了解go底层实现。
java中没有原生的协程(其实就是队列+同步),但可以使用java的类库扩展出协程的执行模式,例如Quaser、Kilim等都是已经实现的扩展库,如果java后面版本添加这样的原生设计,那么go相对于java在执行上的优势就没有了。

















 16万+
16万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









