






目录
参考教材:

课程网站:
https://www.bilibili.com/video/BV1xB4y1m7f4/?spm_id_from=333.1007.top_right_bar_window_custom_collection.content.click
第四课 手写数字体识别问题(举例+实战,对应视频课时6-13)
认识mnist数据集:
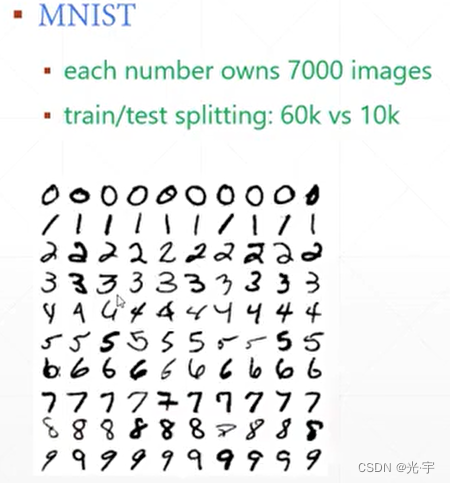
Mnist数据集叫做手写数字数据集,它的训练集有6万个,测试集有一万个。每个图片的像素28*28,每个图片的像素是由0,1组成的,0表示白色,1表示黑色。
解决识别手写数字的方法(理论部分):
1、把28*28的图片“打平”,也就是把二维图片弄成一维(784位的一维0,1数组,设为X)。
2、对一维数组进行线性变换,此处要进行多次线性变换,不能只变换一次。使用y=wx+b的形式进行变换。

计算H1的过程:
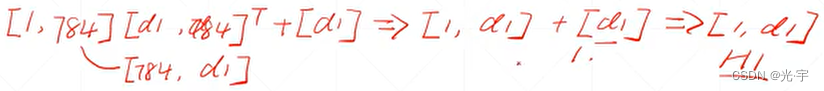
计算H2的过程:

其中“@”表示矩阵乘法。
计算H3的过程:
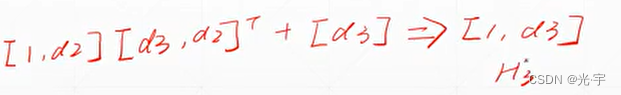
以上中括号中,前面的“1”表示维度,后面的数据表示多少个。
3、然后要选择一种合适的编码方式
这里使用的编码方式是“one-hot”编码方式。

进行手写数字识别任务时,我需要对图片的labor进行编码
如上图所示,如果是1的话就对第二个位置写1,如果是3的话就对第4个位置写3。
4、计算loss
使用欧氏距离的算法计算loss,也就是将10维以内的向量先相减在求平方和,结果越小说明差距越少。
5、非线性处理
其实手写字体里面有好多千奇百怪的字体,但是这些对于人脑来讲是很容易就能识别的,其原因就是人脑有很强的非线性能力,因此对于神经网络来说,也不能光进行线性变换,也要有一个非线性的过程。采用下图所示的非线性激活函数——relu函数。

加入激活函数:

6、利用梯度下降算法,计算出三组W和b

7、算好预测值后

使用argmax算出预测值最接近的真实值的labor。
解决识别手写数字的方法(实践部分):
0、准备工作
在另一个.py文件中写入画loss曲线的函数、画图片的函数以及one-hot编码函数。

先导入库

1、加载图片

2、搭建模型

3、训练


到此为止我们已经得到了一组比较不错的【w1,b1,w2,b2,w3,b3】
此时运行程序时,可以看到loss在很稳定的下降。
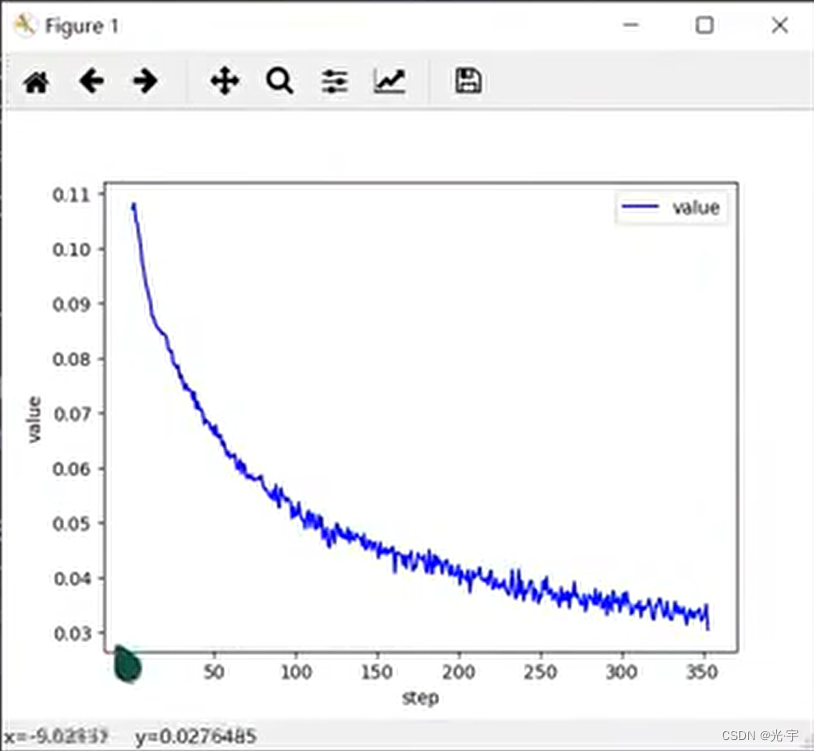
4、准确度测试


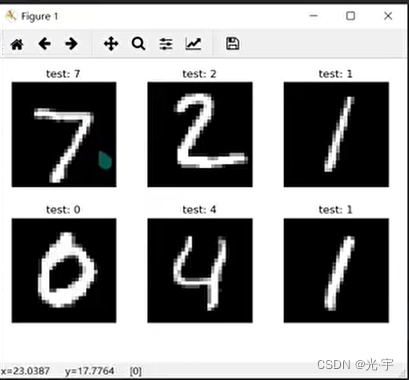

可以看出,预测的结果正确率还是比较可观的。
PS:
由于我发现本课程的课程视频到不完整,再加上没有现成的代码,所以我决定下次更新李沐大神的《动手学深度学习》这门课,也是用的pytorch架构的,我还是非常期待李沐大神的课的!
















 1104
1104











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











