






HBase学习(四)
一、HBase的读写流程
画出架构
1.1 HBase读流程
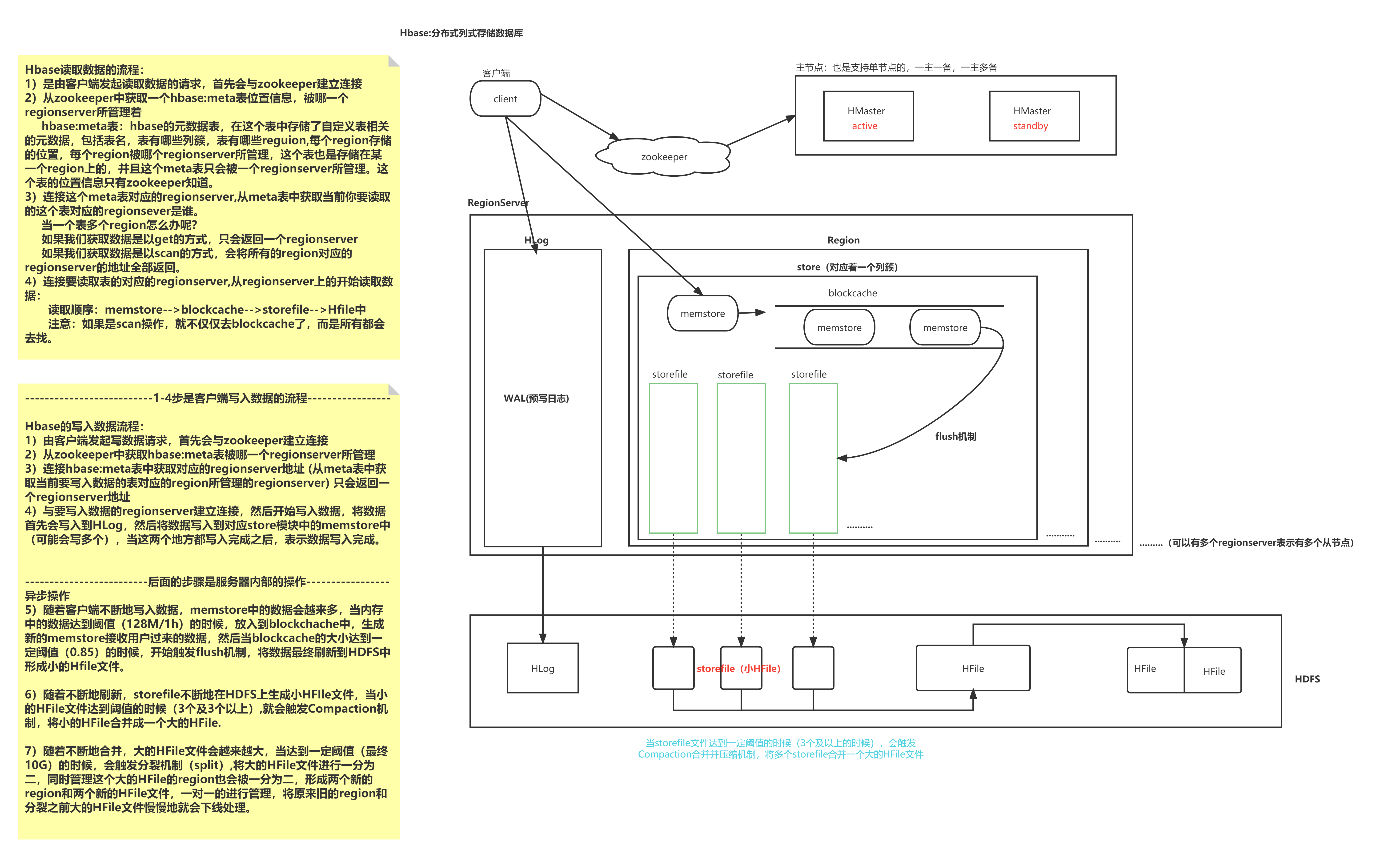
Hbase读取数据的流程:
1)是由客户端发起读取数据的请求,首先会与zookeeper建立连接
2)从zookeeper中获取一个hbase:meta表位置信息,被哪一个regionserver所管理着
hbase:meta表:hbase的元数据表,在这个表中存储了自定义表相关的元数据,包括表名,表有哪些列簇,表有哪些reguion,每个region存储的位置,每个region被哪个regionserver所管理,这个表也是存储在某一个region上的,并且这个meta表只会被一个regionserver所管理。这个表的位置信息只有zookeeper知道。
3)连接这个meta表对应的regionserver,从meta表中获取当前你要读取的这个表对应的regionsever是谁。
当一个表多个region怎么办呢?
如果我们获取数据是以get的方式,只会返回一个regionserver
如果我们获取数据是以scan的方式,会将所有的region对应的regionserver的地址全部返回。
4)连接要读取表的对应的regionserver,从regionserver上的开始读取数据:
读取顺序:memstore-->blockcache-->storefile-->Hfile中
注意:如果是scan操作,就不仅仅去blockcache了,而是所有都会去找。1.2 HBase写流程
--------------------------1-4步是客户端写入数据的流程-----------------
Hbase的写入数据流程:
1)由客户端发起写数据请求,首先会与zookeeper建立连接
2)从zookeeper中获取hbase:meta表被哪一个regionserver所管理
3)连接hbase:meta表中获取对应的regionserver地址 (从meta表中获取当前要写入数据的表对应的region所管理的regionserver) 只会返回一个regionserver地址
4)与要写入数据的regionserver建立连接,然后开始写入数据,将数据首先会写入到HLog,然后将数据写入到对应store模块中的memstore中
(可能会写多个),当这两个地方都写入完成之后,表示数据写入完成。
-------------------------后面的步骤是服务器内部的操作-----------------
异步操作
5)随着客户端不断地写入数据,memstore中的数据会越来多,当内存中的数据达到阈值(128M/1h)的时候,放入到blockchache中,生成新的memstore接收用户过来的数据,然后当blockcache的大小达到一定阈值(0.85)的时候,开始触发flush机制,将数据最终刷新到HDFS中形成小的Hfile文件。
6)随着不断地刷新,storefile不断地在HDFS上生成小HFIle文件,当小的HFile文件达到阈值的时候(3个及3个以上),就会触发Compaction机制,将小的HFile合并成一个大的HFile.
7)随着不断地合并,大的HFile文件会越来越大,当达到一定阈值(最终10G)的时候,会触发分裂机制(split),将大的HFile文件进行一分为二,同时管理这个大的HFile的region也会被一分为二,形成两个新的region和两个新的HFile文件,一对一的进行管理,将原来旧的region和分裂之前大的HFile文件慢慢地就会下线处理。二、Region的分裂策略
region中存储的是一张表的数据,当region中的数据条数过多的时候,会直接影响查询效率。当region过大的时候,region会被拆分为两个region,HMaster会将分裂的region分配到不同的regionserver上,这样可以让请求分散到不同的RegionServer上,已达到负载均衡 , 这也是HBase的一个优点 。
-
ConstantSizeRegionSplitPolicy
0.94版本前,HBase region的默认切分策略
当region中最大的store大小超过某个阈值(hbase.hregion.max.filesize=10G)之后就会触发切分,一个region等分为2个region。
但是在生产线上这种切分策略却有相当大的弊端(切分策略对于大表和小表没有明显的区分):
- 阈值(hbase.hregion.max.filesize)设置较大对大表比较友好,但是小表就有可能不会触发分裂,极端情况下可能就1个,形成热点,这对业务来说并不是什么好事。
- 如果设置较小则对小表友好,但一个大表就会在整个集群产生大量的region,这对于集群的管理、资源使用、failover来说都不是一件好事。
-
IncreasingToUpperBoundRegionSplitPolicy
0.94版本~2.0版本默认切分策略
总体看和ConstantSizeRegionSplitPolicy思路相同,一个region中最大的store大小大于设置阈值就会触发切分。
但是这个阈值并不像ConstantSizeRegionSplitPolicy是一个固定的值,而是会在一定条件下不断调整,调整规则和region所属表在当前regionserver上的region个数有关系.region split阈值的计算公式是:
-
设regioncount:是region所属表在当前regionserver上的region的个数
-
阈值 = regioncount^3 * 128M * 2,当然阈值并不会无限增长,最大不超过MaxRegionFileSize(10G),当region中最大的store的大小达到该阈值的时候进行region split
例如:
- 第一次split阈值 = 1^3 * 256 = 256MB
- 第二次split阈值 = 2^3 * 256 = 2048MB
- 第三次split阈值 = 3^3 * 256 = 6912MB
- 第四次split阈值 = 4^3 * 256 = 16384MB > 10GB,因此取较小的值10GB
- 后面每次split的size都是10GB了
特点
- 相比ConstantSizeRegionSplitPolicy,可以自适应大表、小表;
- 在集群规模比较大的情况下,对大表的表现比较优秀
- 对小表不友好,小表可能产生大量的小region,分散在各regionserver上
- 小表达不到多次切分条件,导致每个split都很小,所以分散在各个regionServer上
-
-
SteppingSplitPolicy
2.0版本默认切分策略
相比 IncreasingToUpperBoundRegionSplitPolicy 简单了一些
region切分的阈值依然和待分裂region所属表在当前regionserver上的region个数有关系- 如果region个数等于1,切分阈值为flush size 128M * 2
- 否则为MaxRegionFileSize。
这种切分策略对于大集群中的大表、小表会比 IncreasingToUpperBoundRegionSplitPolicy 更加友好,小表不会再产生大量的小region,而是适可而止。
-
KeyPrefixRegionSplitPolicy
根据rowKey的前缀对数据进行分区,这里是指定rowKey的前多少位作为前缀,比如rowKey都是16位的,指定前5位是前缀,那么前5位相同的rowKey在相同的region中。
-
DelimitedKeyPrefixRegionSplitPolicy
保证相同前缀的数据在同一个region中,例如rowKey的格式为:userid_eventtype_eventid,指定的delimiter为 _ ,则split的的时候会确保userid相同的数据在同一个region中。
按照分隔符进行切分,而KeyPrefixRegionSplitPolicy是按照指定位数切分。 -
BusyRegionSplitPolicy
按照一定的策略判断Region是不是Busy状态,如果是即进行切分
如果你的系统常常会出现热点Region,而你对性能有很高的追求,那么这种策略可能会比较适合你。它会通过拆分热点Region来缓解热点Region的压力,但是根据热点来拆分Region也会带来很多不确定性因素,因为你也不知道下一个被拆分的Region是哪个。
-
DisabledRegionSplitPolicy
不启用自动拆分, 需要指定手动拆分
三、Compaction操作(小的Hfile和并成大的Hfile才会触发下面两个机制)
Minor Compaction:
- 指选取一些小的、相邻的StoreFile将他们合并成一个更大的StoreFile,在这个过程中不会处理已经Deleted或Expired的Cell。一次 Minor Compaction 的结果是更少并且更大的StoreFile。
Major Compaction:
- 指将所有的StoreFile合并成一个StoreFile,这个过程会清理三类没有意义的数据:被删除的数据、TTL过期数据、版本号超过设定版本号的数据。另外,一般情况下,major compaction时间会持续比较长,整个过程会消耗大量系统资源,对上层业务有比较大的影响。因此线上业务都会将关闭自动触发major compaction功能,改为手动在业务低峰期触发。
四、面对百亿数据,HBase为什么查询速度依然非常快?
HBase适合存储PB级别的海量数据(百亿千亿量级条记录),如果根据记录主键Rowkey来查询,能在几十到百毫秒内返回数据。
那么HBase是如何做到的呢?
接下来,简单阐述一下数据的查询思路和过程。
查询过程
第1步:
项目有100亿业务数据,存储在一个HBase集群上(由多个服务器数据节点构成),每个数据节点上有若干个Region(区域),每个Region实际上就是HBase中一批数据的集合(一段连续范围rowkey的数据)。
我们现在开始根据主键RowKey来查询对应的记录,通过meta表可以帮我们迅速定位到该记录所在的数据节点,以及数据节点中的Region,目前我们有100亿条记录,占空间10TB。所有记录被切分成5000个Region,那么现在,每个Region就是2G。
由于记录在1个Region中,所以现在我们只要查询这2G的记录文件,就能找到对应记录。
第2步:
由于HBase存储数据是按照列族存储的。比如一条记录有400个字段,前100个字段是人员信息相关,这是一个列簇(列的集合);中间100个字段是公司信息相关,是一个列簇。另外100个字段是人员交易信息相关,也是一个列簇;最后还有100个字段是其他信息,也是一个列簇
这四个列簇是分开存储的,这时,假设2G的Region文件中,分为4个列族,那么每个列族就是500M。
到这里,我们只需要遍历这500M的列簇就可以找到对应的记录。
第3步:
如果要查询的记录在其中1个列族上,1个列族在HDFS中会包含1个或者多个HFile。
如果一个HFile一般的大小为100M,那么该列族包含5个HFile在磁盘上或内存中。
由于HBase的内存进而磁盘中的数据是排好序的,要查询的记录有可能在最前面,也有可能在最后面,按平均来算,我们只需遍历2.5个HFile共250M,即可找到对应的记录。
第4步:
每个HFile中,是以键值对(key/value)方式存储,只要遍历文件中的key位置并判断符合条件即可
一般key是有限的长度,假设key/value比是1:24,最终只需要10M的数据量,就可获取的对应的记录。
如果数据在机械磁盘上,按其访问速度100M/S,只需0.1秒即可查到。
如果是SSD的话,0.01秒即可查到。
当然,扫描HFile时还可以通过布隆过滤器快速定位到对应的HFile,以及HBase是有内存缓存机制的,如果数据在内存中,效率会更高。
总结
正因为以上大致的查询思路,保证了HBase即使随着数据量的剧增,也不会导致查询性能的下降。
同时,HBase是一个面向列存储的数据库(列簇机制),当表字段非常多时,可以把其中一些字段独立出来放在一部分机器上,而另外一些字段放到另一部分机器上,分散存储,分散列查询。
正由于这样复杂的存储结构和分布式的存储方式,保证了HBase海量数据下的查询效率。
五、HBase与Hive的集成
HBase与Hive的对比
hive:
数据仓库:Hive的本质其实就相当于将HDFS中已经存储的文件在Mysql中做了一个双射关系,以方便使用HQL去管理查询。
用于数据分析、清洗:Hive适用于离线的数据分析和清洗,延迟较高。
基于HDFS、MapReduce:Hive存储的数据依旧在DataNode上,编写的HQL语句终将是转换为MapReduce代码执行。
HBase
数据库:是一种面向列族存储的非关系型数据库。
用于存储结构化和非结构化的数据:适用于单表非关系型数据的存储,不适合做关联查询,类似JOIN等操作。
基于HDFS:数据持久化存储的体现形式是HFile,存放于DataNode中,被ResionServer以region的形式进行管理。
延迟较低,接入在线业务使用:面对大量的企业数据,HBase可以直线单表大量数据的存储,同时提供了高效的数据访问速度。
在
hive-site.xml中添加zookeeper的属性
<property>
<name>hive.zookeeper.quorum</name>
<value>master,node1,node2</value>
</property>
<property>
<name>hive.zookeeper.client.port</name>
<value>2181</value>
</property>HBase中已经存储了某一张表,在Hive中创建一个外部表来关联HBase中的这张表
建立外部表的字段名要和hbase中的列名一致
前提是hbase中已经有表了
create external table students_hbase1
(
id string,
name string,
age string,
gender string,
clazz string
)
stored by 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
with serdeproperties ("hbase.columns.mapping" = "
:key,
info:name,
info:age,
info:gender,
info:clazz
")
tblproperties("hbase.table.name" = "default:students");
create external table score_hbase3
(
id string,
score_part string
)
stored by 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
with serdeproperties ("hbase.columns.mapping" = "
:key,
info:score_part
")
tblproperties("hbase.table.name" = "default:score");关联后就可以使用Hive函数进行一些分析操作了
六、Phoenix
Hbase适合存储大量的对关系运算要求低的NOSQL数据,受Hbase 设计上的限制不能直接使用原生的API执行在关系数据库中普遍使用的条件判断和聚合等操作。Hbase很优秀,一些团队寻求在Hbase之上提供一种更面向普通开发人员的操作方式,Apache Phoenix即是。
Phoenix 基于Hbase给面向业务的开发人员提供了以标准SQL的方式对Hbase进行查询操作,并支持标准SQL中大部分特性:条件运算,分组,分页,等高级查询语法。
1、Phoenix搭建
Phoenix 4.15 HBase 1.4.6 hadoop 2.7.6
1、关闭hbase集群,在master中执行
stop-hbase.sh2、上传解压配置环境变量
解压
tar -xvf apache-phoenix-4.15.0-HBase-1.4-bin.tar.gz -C /usr/local/soft/
改名
mv apache-phoenix-4.15.0-HBase-1.4-bin phoenix-4.15.0
3、将phoenix-4.15.0-HBase-1.4-server.jar复制到所有节点的hbase lib目录下
scp /usr/local/soft/phoenix-4.15.0/phoenix-4.15.0-HBase-1.4-server.jar master:/usr/local/soft/hbase-1.4.6/lib/
scp /usr/local/soft/phoenix-4.15.0/phoenix-4.15.0-HBase-1.4-server.jar node1:/usr/local/soft/hbase-1.4.6/lib/
scp /usr/local/soft/phoenix-4.15.0/phoenix-4.15.0-HBase-1.4-server.jar node2:/usr/local/soft/hbase-1.4.6/lib/4、启动hbase , 在master中执行
start-hbase.sh5、配置环境变量
vim /etc/profile2、Phoenix使用
1、连接sqlline
sqlline.py master,node1,node2
# 出现
163/163 (100%) Done
Done
sqlline version 1.5.0
0: jdbc:phoenix:master,node1,node2>2、常用命令
# 1、创建表
CREATE TABLE IF NOT EXISTS student (
id VARCHAR NOT NULL PRIMARY KEY,
name VARCHAR,
age BIGINT,
gender VARCHAR ,
clazz VARCHAR
);
# 2、显示所有表
!table
# 3、插入数据
upsert into STUDENT values('1500100004','葛德曜',24,'男','理科三班');
upsert into STUDENT values('1500100005','宣谷芹',24,'男','理科六班');
upsert into STUDENT values('1500100006','羿彦昌',24,'女','理科三班');
# 4、查询数据,支持大部分sql语法,
select * from STUDENT ;
select * from STUDENT where age=24;
select gender ,count(*) from STUDENT group by gender;
select * from student order by gender;
# 5、删除数据
delete from STUDENT where id='1500100004';
# 6、删除表
drop table STUDENT;
# 7、退出命令行
!quit
更多语法参照官网
https://phoenix.apache.org/language/index.html#upsert_select3、phoenix表映射
默认情况下,直接在hbase中创建的表,通过phoenix是查看不到的
如果需要在phoenix中操作直接在hbase中创建的表,则需要在phoenix中进行表的映射。映射方式有两种:视图映射和表映射
3.1、视图映射
Phoenix创建的视图是只读的,所以只能用来做查询,无法通过视图对源数据进行修改等操作
# hbase shell 进入hbase命令行
hbase shell
# 创建hbase表
create 'test','name','company'
# 插入数据
put 'test','001','name:firstname','zhangsan1'
put 'test','001','name:lastname','zhangsan2'
put 'test','001','company:name','数加'
put 'test','001','company:address','合肥'
upsert into TEST values('002','xiaohu','xiaoxiao','数加','合肥');
# 在phoenix创建视图, primary key 对应到hbase中的rowkey
create view "test"(
empid varchar primary key,
"name"."firstname" varchar,
"name"."lastname" varchar,
"company"."name" varchar,
"company"."address" varchar
);
CREATE view "students" (
id VARCHAR NOT NULL PRIMARY KEY,
"info"."name" VARCHAR,
"info"."age" VARCHAR,
"info"."gender" VARCHAR ,
"info"."clazz" VARCHAR
) column_encoded_bytes=0;
# 在phoenix查询数据,表名通过双引号引起来
select * from "test";
# 删除视图
drop view "test";3.2、表映射
使用Apache Phoenix创建对HBase的表映射,有两类:
1) 当HBase中已经存在表时,可以以类似创建视图的方式创建关联表,只需要将create view改为create table即可。
2)当HBase中不存在表时,可以直接使用create table指令创建需要的表,并且在创建指令中可以根据需要对HBase表结构进行显示的说明。
第1)种情况下,如在之前的基础上已经存在了test表,则表映射的语句如下:
create table "test" (
empid varchar primary key,
"name"."firstname" varchar,
"name"."lastname"varchar,
"company"."name" varchar,
"company"."address" varchar
)column_encoded_bytes=0;
upsert into "students" values('150011000100','xiaohu','24','男','理科三班');
upsert into "test" values('1001','xiaohu','xiaoxiao','数加','合肥');
CREATE table "students" (
id VARCHAR NOT NULL PRIMARY KEY,
"info"."name" VARCHAR,
"info"."age" VARCHAR,
"info"."gender" VARCHAR ,
"info"."clazz" VARCHAR
) column_encoded_bytes=0;
upsert into "students" values('150011000100','xiaohu','24','男','理科三班');
CREATE table "score" (
id VARCHAR NOT NULL PRIMARY KEY,
"info"."score_dan" VARCHAR
) column_encoded_bytes=0;使用create table创建的关联表,如果对表进行了修改,源数据也会改变,同时如果关联表被删除,源表也会被删除。但是视图就不会,如果删除视图,源数据不会发生改变。















 3293
3293











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









