






10、Flink join
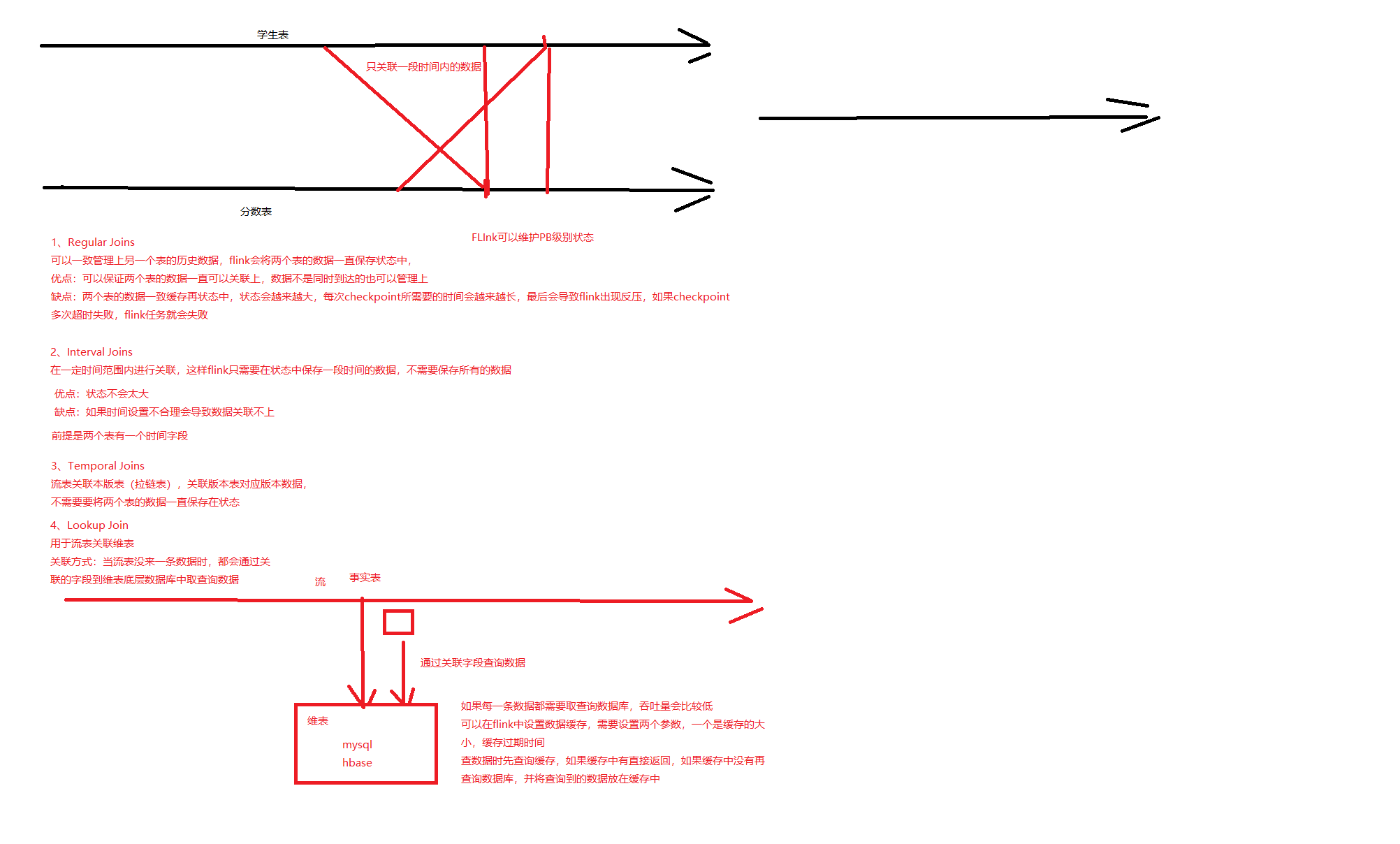
1、Regular Joins
将两个关联表长存再状态中,可以一直关联上
会导致状态越来越大
和批处理关联结果是一样的
-- 创建学生表流表,数据再kafka中
drop table student_join;
CREATE TABLE student_join (
id String,
name String,
age int,
gender STRING,
clazz STRING
) WITH (
'connector' = 'kafka',
'topic' = 'student_join',
'properties.bootstrap.servers' = 'master:9092,node1:9092,node2:9092',
'properties.group.id' = 'asdasdasd',
'format' = 'csv',
'scan.startup.mode' = 'latest-offset'
);
-- 分数表
drop table score_join;
CREATE TABLE score_join (
s_id String,
c_id String,
sco int
) WITH (
'connector' = 'kafka',
'topic' = 'score_join',
'properties.bootstrap.servers' = 'master:9092,node1:9092,node2:9092',
'properties.group.id' = 'asdasdasd',
'format' = 'csv',
'scan.startup.mode' = 'latest-offset'
);
--- inner join
select a.id,a.name,b.sco from
student_join as a
inner join
score_join as b
on a.id=b.s_id
-- left outer join
select a.id,a.name,b.sco from
student_join as a
left join
score_join as b
on a.id=b.s_id
-- full outer join
select a.id,a.name,b.sco from
student_join as a
full join
score_join as b
on a.id=b.s_id
-- 创建生产者向两个topic中生产数据
kafka-console-producer.sh --broker-list master:9092,node1:9092,node2:9092 --topic score_join
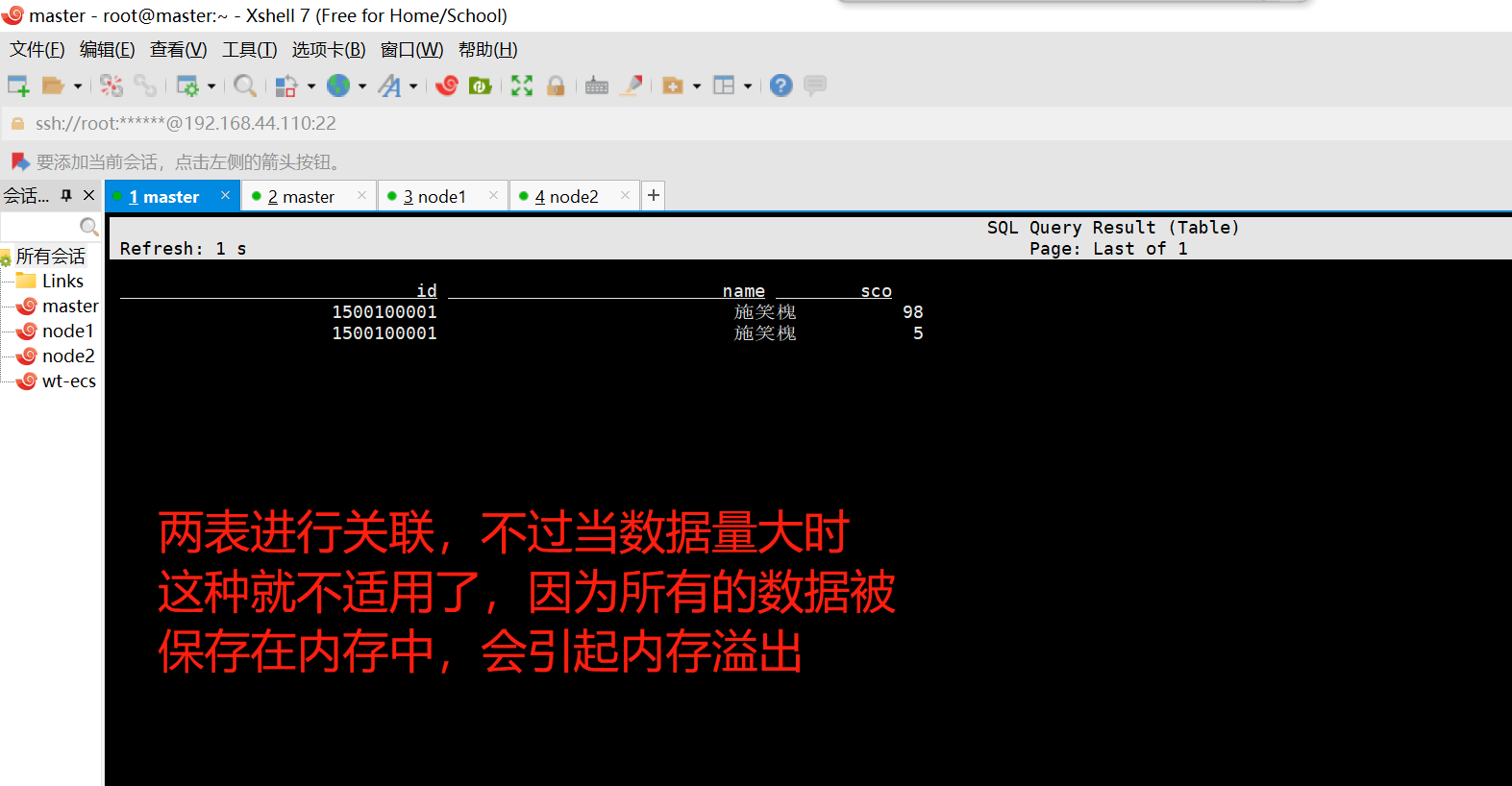
1500100001,1000001,98
1500100001,1000002,5
1500100001,1000003,0
kafka-console-producer.sh --broker-list master:9092,node1:9092,node2:9092 --topic student_join
1500100001,施笑槐,22,女,文科六班
1500100002,吕金鹏,24,男,文科七班inner join
left join

2、Interval Joins
-- 创建学生表流表,数据再kafka中
CREATE TABLE student_join_proc (
id String,
name String,
age int,
gender STRING,
clazz STRING,
stu_time as PROCTIME()
) WITH (
'connector' = 'kafka',
'topic' = 'student_join',
'properties.bootstrap.servers' = 'master:9092,node1:9092,node2:9092',
'properties.group.id' = 'asdasdasd',
'format' = 'csv',
'scan.startup.mode' = 'latest-offset'
);
-- 分数表
CREATE TABLE score_join_proc (
s_id String,
c_id String,
sco int,
sco_time as PROCTIME()
) WITH (
'connector' = 'kafka',
'topic' = 'score_join',
'properties.bootstrap.servers' = 'master:9092,node1:9092,node2:9092',
'properties.group.id' = 'asdasdasd',
'format' = 'csv',
'scan.startup.mode' = 'latest-offset'
);
-- Interval Joins
select a.id,a.name,b.sco from
student_join_proc as a, score_join_proc as b
where a.id=b.s_id
and a.stu_time BETWEEN b.sco_time - INTERVAL '15' SECOND AND b.sco_time
-- 创建生产者向两个topic中生产数据
kafka-console-producer.sh --broker-list master:9092,node1:9092,node2:9092 --topic score_join
1500100001,1000001,98
1500100001,1000002,5
1500100002,1000003,0
kafka-console-producer.sh --broker-list master:9092,node1:9092,node2:9092 --topic student_join
1500100001,施笑槐,22,女,文科六班
1500100002,吕金鹏,24,男,文科七班
-- 先键入学生信息,在15秒中之内键入成绩信息就会被录入到其中。如果超过15秒中之后再次键入可以关联的成绩信息,就不会被录入到其中3、Temporal Joins
-- 订单表
CREATE TABLE orders (
order_id STRING, -- 订单编号
price DECIMAL(32,2), --订单的价格
currency STRING, -- 汇率表主键
order_time TIMESTAMP(3), -- 订单发生的事件
WATERMARK FOR order_time AS order_time -- 设置事件时间和水位线
) WITH (
'connector' = 'kafka',
'topic' = 'orders',
'properties.bootstrap.servers' = 'master:9092,node1:9092,node2:9092',
'properties.group.id' = 'asdasdasd',
'format' = 'csv',
'scan.startup.mode' = 'latest-offset'
);
--汇率表
CREATE TABLE currency_rates (
currency STRING, -- 汇率表主键
conversion_rate DECIMAL(32, 2), -- 汇率
update_time TIMESTAMP(3) METADATA FROM 'value.ingestion-timestamp' VIRTUAL, --汇率更新时间
WATERMARK FOR update_time AS update_time,--时间字段和水位线
PRIMARY KEY(currency) NOT ENFORCED--设置主键
) WITH (
'connector' = 'kafka',
'topic' = 'bigdata17.currency_rates',
'properties.bootstrap.servers' = 'master:9092,node1:9092,node2:9092',
'properties.group.id' = 'asdasdasd',
'format' = 'canal-json',
'scan.startup.mode' = 'earliest-offset',
'canal-json.ignore-parse-errors' = 'true'
);
-- 查询汇率表
select
currency ,
conversion_rate,
update_time
from
currency_rates
-- Temporal Joins
SELECT
order_id,
price,
orders.currency,
conversion_rate,
order_time
FROM orders
LEFT JOIN currency_rates FOR SYSTEM_TIME AS OF orders.order_time
ON orders.currency = currency_rates.currency;
-- 订单表数据
kafka-console-producer.sh --broker-list master:9092,node1:9092,node2:9092 --topic orders
001,1000.0,1001,2022-08-02 23:13:52
001,1000.0,1001,2022-08-02 23:13:54
001,1000.0,1001,2022-08-02 23:33:36
001,1000.0,1001,2022-08-02 23:46:01mysql 中的表的变化如下:
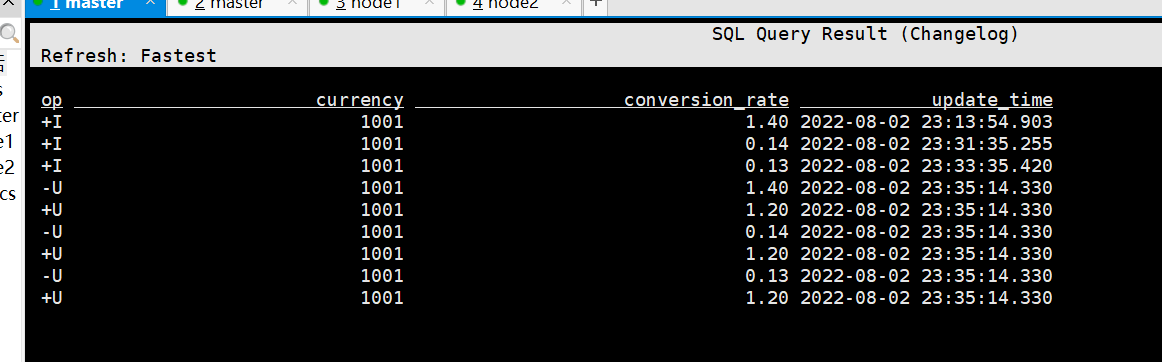
两表聚合之后的结果如下:

4、流表(kafka)关联维表(hbase,mysql)
1、常规的join
使用常规join做维表关联,会出现数据库中维表更新了,但是flink中无法捕获更新,只能关联到任务刚启动时读取的数据
-- 创建一个jdbc维表 -- 有界流
CREATE TABLE student_mysql (
id BIGINT,
name STRING,
age BIGINT,
gender STRING,
clazz STRING
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://master:3306/bigdata17',
'table-name' = 'students',
'username' = 'root',
'password' = '123456'
);
select
cast(id as STRING)
from
student_mysql
-- 分数表 -- 无界流
CREATE TABLE score_join (
s_id String,
c_id String,
sco int
) WITH (
'connector' = 'kafka',
'topic' = 'score_join',
'properties.bootstrap.servers' = 'master:9092,node1:9092,node2:9092',
'properties.group.id' = 'asdasdasd',
'format' = 'csv',
'scan.startup.mode' = 'latest-offset'
);
-- 无界流关联有界流
select b.id,b.name,a.sco from
score_join as a
join
student_mysql as b
on
a.s_id=cast(b.id as STRING)
-- 创建生产者向两个topic中生产数据
kafka-console-producer.sh --broker-list master:9092,node1:9092,node2:9092 --topic score_join
1500100003,1000001,98
1500100004,1000002,5
1500100001,1000003,0
1500101000,1000003,12
上述方法有不足点,如下:

2、Lookup Join
-- 创建一个jdbc维表 -- 有界流
CREATE TABLE student_mysql (
id BIGINT,
name STRING,
age BIGINT,
gender STRING,
clazz STRING
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://master:3306/bigdata17',
'table-name' = 'students',
'username' = 'root',
'password' = '123456',
'lookup.cache.max-rows' = '100' ,-- 开启缓存,指定缓存数据量,可以提高关联性能
'lookup.cache.ttl' = '30s' -- 缓存过期时间,一般会按照维表更新频率设置
);
-- 分数表 -- 无界流
CREATE TABLE score_join (
s_id String,
c_id String,
sco int,
pro_time as PROCTIME() -- Lookup Join关联方式,流表需要有一个时间字段
) WITH (
'connector' = 'kafka',
'topic' = 'score_join',
'properties.bootstrap.servers' = 'master:9092,node1:9092,node2:9092',
'properties.group.id' = 'asdasdasd',
'format' = 'csv',
'scan.startup.mode' = 'latest-offset'
);
SELECT
b.id,b.name,b.age,a.sco
FROM score_join as a
LEFT JOIN student_mysql FOR SYSTEM_TIME AS OF a.pro_time as b
ON cast(a.s_id as BIGINT)= b.id;
-- 创建生产者向两个topic中生产数据
kafka-console-producer.sh --broker-list master:9092,node1:9092,node2:9092 --topic score_join
1500100003,1000001,98
1500100004,1000002,5
1500100001,1000003,0
11、自定义函数
1、编写自定义函数
import org.apache.flink.table.functions.ScalarFunction
class SubstringFunction extends ScalarFunction{
/**
* eval 只能叫这个方法名
* @return
* 字符串切分
*/
def eval(s: String, begin: Integer, end: Integer): String = {
s.substring(begin, end)
}
}2、将项目打包上传到集群
3、启动sql-client,指定jar包
或者将包放在flink的lib目录
sql-client.sh -j flink-1.0-SNAPSHOT.jar4、创建自定义函数
CREATE TEMPORARY SYSTEM FUNCTION
substringFunction
AS 'com.wt.flink.sql.MyFunction'
LANGUAGE SCALA;12、Flink sql中保证数据处理的唯一一次
-- source表
CREATE TABLE words (
`word` STRING
) WITH (
'connector' = 'kafka',
'topic' = 'w_exactly_once',
'properties.bootstrap.servers' = 'master:9092,node1:9092,node2:9092',
'properties.group.id' = 'asdasd',
'scan.startup.mode' = 'earliest-offset',
'format' = 'csv'
);
-- 在mysql中创建表
CREATE TABLE `word_count` (
`word` varchar(255) NOT NULL,
`c` bigint(20) DEFAULT NULL,
PRIMARY KEY (`word`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- flink sql jdbc sink表
CREATE TABLE word_count (
word STRING,
c BIGINT,
PRIMARY KEY (word) NOT ENFORCED -- 按照主键更新数据
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://master:3306/bigdata17?useUnicode=true&characterEncoding=UTF-8',
'table-name' = 'word_count', -- 需要手动到数据库中创建表
'username' = 'root',
'password' = '123456'
);
-- 统计单词数量,将结果保存到数据库中
insert into word_count
select word,count(1) as c from words
group by word
--生产数据
kafka-console-producer.sh --broker-list master:9092,node1:9092,node2:9092 --topic w_exactly_once-
如果sql执行失败,直接重启sql,会出现反压,因为需要处理历史数据
-
开启checkpiint
- 可以在flink配置文件中统一开启
-
创建一个sql文件,把所有的sql放在sql文件
vim word_count.sql
CREATE TABLE words (
`word` STRING
) WITH (
'connector' = 'kafka',
'topic' = 'words_exactly_once',
'properties.bootstrap.servers' = 'master:9092,node1:9092,node2:9092',
'properties.group.id' = 'asdasd',
'scan.startup.mode' = 'earliest-offset',
'format' = 'csv'
);
-- flink sql jdbc sink表
CREATE TABLE word_count (
word STRING,
c BIGINT,
PRIMARY KEY (word) NOT ENFORCED -- 按照主键更新数据
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://master:3306/bigdata?useUnicode=true&characterEncoding=UTF-8',
'table-name' = 'word_count', -- 需要手动到数据库中创建表
'username' = 'root',
'password' = '123456'
);
-- 重启sql之前增加参数
SET 'execution.savepoint.path' = 'hdfs://master:9000/flink/checkpoint/8cbd9fb08bfbac13d3fd2dc58b1a6de7/chk-46';
-- 重启sql
insert into word_count
select word,count(1) as c from words
group by word;- 重启sql
sql-client.sql -f word_count.sql12、执行一组sql
CREATE TABLE print_table (
word STRING,
c BIGINT
)
WITH ('connector' = 'print');
-- 执行多个inert into 语句
-- 原表只需要读取一次就可以了
EXECUTE STATEMENT SET
BEGIN
insert into print_table
select word,count(1) as c from words
group by word;
insert into word_count
select word,count(1) as c from words
group by word;
END;













 1928
1928











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









