










ElasticSearch的简单了解和使用
学习、参考链接:Elasticsearch入门,新手也能“开箱即用”
关于ElasticSearch
简介
ElasticSearch 是一个分布式的、开源的 全文搜索和分析引擎,可以存储、搜索、分析海量数据,速度非常快,可以说是 近乎于实时 的。通常作为底层的技术引擎,在应用需要复杂的搜索功能时提供强有力的支持。
ElasticSearch 适用于各种类型的数据,例如文本、数字、地理空间数据,结构化的、非结构化的都支持。
你可以把 ElasticSearch 理解为一个具有超强查询能力的 NoSQL 数据库,这个查询能力来自 Lucene,它是一个全功能的专业搜索引擎库。
最重要的是: ElasticSearch 是非常易用的,做了大量智能的默认配置,在简单的学习后,即便是新手也能轻松做到做到“开箱即用”。
ElasticSearch 的常用场景
MySQL的痛点
比如想要在地图软件或是外卖软件上搜索火锅店,常用"火锅" 作为搜索关键词,对于MySQL数据库来说,搜索的方式便类似为:
name like ‘%火锅%’,那么问题来了——
这类软件应用等程序的这类搜索功能,一定不同于管理系统一般那样“小巧”的数据量
而使用 “%火锅%” 这种形式,是无法使用索引的,而在一个大型平台中,商家的数据是海量的,全表扫描的话就形同于大海捞针,大大降低了查询效率
而这种时候,就可以通过ElasticSearch来实现这种场景下的高效查询了——
ElasticSearch倒排索引
ElasticSearch 会先对 “name” 字段的值进行分词:
{
"id": 1,
"name": "珍味海鲜火锅"
}
// 珍味、海鲜、火锅
然后把每个词都标识上它所在的文档ID,形成 词与文档 的对应关系表:
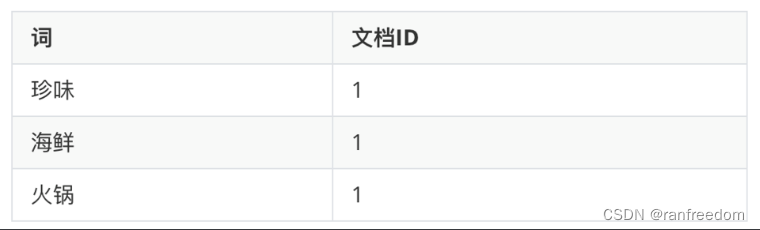
同样的道理,插入其他文档的时候也是同样的操作。
{
"id": 2,
"name": "云云打边炉"
}
{
"id": 3,
"name": "汕头海味牛肉火锅"
}
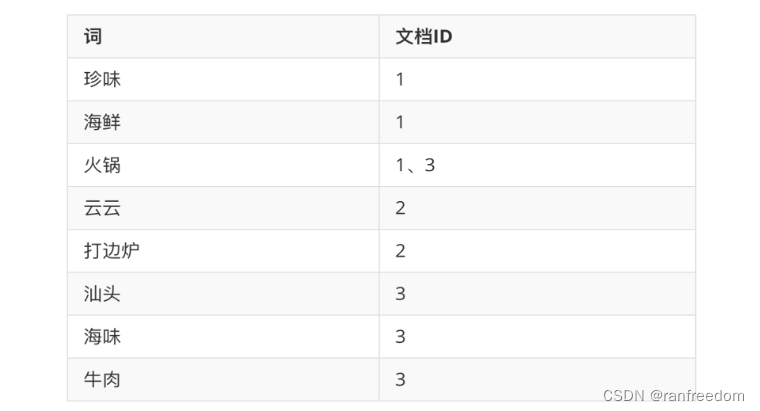
比如此时我要搜索“火锅”,ElasticSearch的搜索方式为:先用“火锅”匹配到分词“火锅”,然后获取到文档id,再用文档id获取到对应的数据返回就行了
对比MySQL的全局搜索,在关键词搜索这方面ElasticSearch的搜索方式可以说是极大的提升了查询效率
而这种检索方式,我们称之为——
倒排索引:正常情况下我们是在内容中找关键字,而这里,我们是根据关键字找到具体内容
ElasticSearch的数据类型
Document (文档)
你可以把 Document (文档)理解为 MySQL 表中的记录。
数据是以 JSON 结构存储在 Document 中。
一个 Document 之中存储的是键值对集合,值可以是很多种类型,包括但不限于 string, integer, float, boolean, array。
举个例子:
{
"id": 1,
"name": "sky",
"city": "beijing",
"qq": [
"2323892",
"9823829"
]
}
Mapping(映射)
Mapping (映射)就像是 MySQL 中的表。
Mapping 用来定义 schema,规范 Document 中的字段,例如类型、索引的方式。
Mapping 不是必须定义的,如果没有,在你插入 Document 之后,ElasticSearch 会自动决定各个字段的类型,对于数组,其中的第一个值决定了其类型。
Mapping 是定义类型的,与 Type 同义。
Index(索引)
Index (索引)就像是 MySQL 中的 database 数据库。
ElasticSearch 中包含 0 或多个 Index,一个 Index 中包含 0 或多个类型,一个类型中包含 0 或多个 Document。
下图是 ElasticSearch 官方文档中给出的关系图:
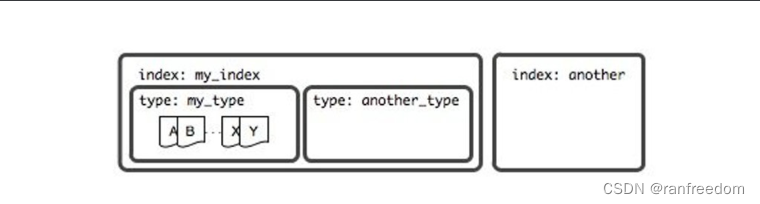
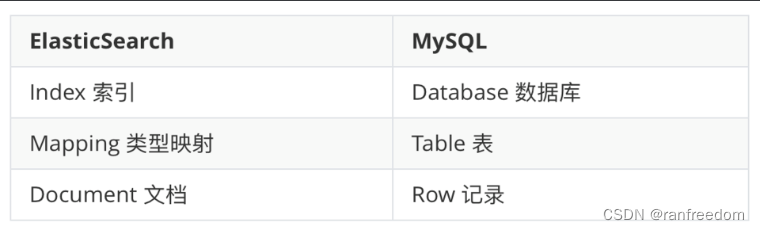
小结
Index、Mapping、Document 是 ElasticSearch 中非常基础的概念,一定要理解!你可以通过对照 MySQL 的概念来帮助记忆:
安装、配置ElasticSearch
ElasticSearch 是支持多平台的,Linux、Windows、Mac 都是可以安装的。
注意:因为 ElasticSearch 是基于 Java 的,所以系统中需要先安装好 Java 环境。
下面介绍的是 Linux 中的安装过程。
系统环境:
CentOS 7.8
JDK 11.0.7
ElasticSearch 版本选择的是当前最新版 7.8。
具体的搭建步骤:
(1)下载 ElasticSearch 安装包
(2)创建一个普通用户,因为 ElasticSearch 不允许使用 ROOT 用户安装
(3)修改配置
(4)启动 ElasticSearch
(5)常见问题处理
ElasticSearch 下载地址:
https://www.elastic.co/cn/downloads/elasticsearch
点击 “LINUX X86_64” 下载,如下图:
下载后,将其放到服务器(虚拟机)中。
// ElasticSearch 要求不能使用 ROOT 用户,所以需要创建一个普通用户,我们下面新建一个用户 "es"。
// 添加用户之前,新建一个组,组名也设置为 "es":
groupadd es
// 然后添加用户,并放入 "es" 组中:
useradd es -g es
// 切换到 "es" 用户:
su - es
// 解压:
tar zxf elasticsearch-7.8.0-linux-x86_64.tar.gz
// 解压后得到目录 "elasticsearch-7.8.0",进入此目录:
cd elasticsearch-7.8.0
// 配置文件位置:"conf/elasticsearch.yml"。
// 小提示:在修改配置文件之前,最好先复制一份原始的配置文件,以防改错了。
// 备份配置文件:
cp config/elasticsearch.yml config/elasticsearch.yml.bak
// 编辑:
vi config/elasticsearch.yml
// (1)搜索 "network.host",需要把前面的注释符号去掉,并指定地址 "0.0.0.0",
// 这样任何机器都可以访问这个 ElasticSearch 了:
// 实际环境中,为了安全,此处需设置为可信IP地址。
network.host: 0.0.0.0
// (2)搜索 "node.name",去掉注释即可:
node.name: node-1
// (3)搜索 "cluster.initial_master_nodes",去掉注释,修改为:
cluster.initial_master_nodes: ["node-1"]
// (4)搜索 "discovery.seed_hosts",同样把注释去掉,修改为:
discovery.seed_hosts: ["127.0.0.1", "localhost"]
修改这几项就可以了,保存退出。
现在 ElasticSearch 就安装配置好了,接下来就可以启动了。
启动非常简单,在 ElasticSearch 解压目录下执行:
bin/elasticsearch
启动成功后,会输出如下类似信息:

可以访问一下 ElasticSearch 的服务信息,来验证是否正常。
访问地址:
http://[ElasticSearch Server IP]:9200/
“9200” 是 ElasticSearch 默认端口,我们没有改动,所以直接使用即可。
访问后返回的信息:
{
"name": "localhost.localdomain",
"cluster_name": "elasticsearch",
"cluster_uuid": "_na_",
"version": {
"number": "7.8.0",
"build_flavor": "default",
"build_type": "tar",
"build_hash": "757314695644ea9a1dc2fecd26d1a43856725e65",
"build_date": "2020-06-14T19:35:50.234439Z",
"build_snapshot": false,
"lucene_version": "8.5.1",
"minimum_wire_compatibility_version": "6.8.0",
"minimum_index_compatibility_version": "6.0.0-beta1"
},
"tagline": "You Know, for Search"
}
后台启动之后,命令行窗口中就不会输出启动的日志信息了,那么去哪儿看日志呢?
在 “logs” 目录下的 “elasticsearch.log” 文件中,可以使用 “tail” 命令来查看实时的日志输出:
tail -f logs/elasticsearch.log
可能出现的问题
如果你是在虚拟机或者测试服务器上安装 ElasticSearch 的话,基本不会直接启动成功的,因为服务器的配置较低,会引起一些问题。
启动出现问题的话,会有错误提示,例如:
ERROR: [2] bootstrap checks failed
[1]: max file descriptors [4096] for elasticsearch process is too low, increase to at least [65535]
[2]: max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
这是2个最常见的问题,下面看如果解决。
(1)max file descriptors [4096] for elasticsearch process is too low, increase to at least [65535]
这是系统的文件描述符不足引起的,需要修改系统的配置。
首先退出当前的 “es” 用户,回到 ROOT 用户下。
编辑
vi /etc/security/limits.conf
在文件的末尾添加:
es soft nofile 65536
es hard nofile 65536
es memlock unlimited
前面的 “es” 就是我们创建的 “es” 用户。
添加后保存退出即可。
(2)max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
这是虚拟内存参数问题,也需要修改系统配置文件。
修改 /etc/sysctl.conf,文件末尾添加:
vm.max_map_count=262144
保存退出,执行如下命令使其生效:
sysctl -p
这样这两个问题就解决了,重新回到 “es” 用户下:
su - es
这样,上面 2 个问题就解决了,但是如果你的服务器内存不大,建议也改一下 ElasticSearch 中 JVM 内存的配置。
修改 “config/jvm.options”,默认的内存配置的是 “1g”,如下:
-Xms1g
-Xmx1g
可以改小一点,例如 512m:
-Xms512m
-Xmx512m
进入 ElasticSearch 安装目录,再次执行启动命令:
bin/elasticesrarch
这样就OK啦!
重点API
ElasticSearch 提供了 REST API,操作非常方便。
这一关咱们把其中一些重要的 API 都操练一遍,这样你就可以掌握 ElasticSearch 的使用思路了。
我们要实践以下这些 API:

索引
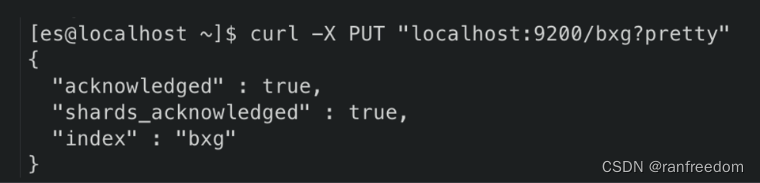
现在我们创建一个名为 “bxg” 的索引,发送请求:
curl -X PUT “localhost:9200/bxg?pretty”
返回结果:
{
“acknowledged” : true,
“shards_acknowledged” : true,
“index” : “bxg”
}
整体形式如下图:
接口的地址就是 ElasticSearch 服务器 IP 地址和端口,后面跟上索引名即可。
此时,安能老师提问了:最后的 “pretty” 是干什么的呢?“pretty” 是"漂亮" 的意思,在这是什么意思呢?
我们把 “pretty” 去掉试试,看是什么效果:
curl -X PUT “localhost:9200/bxg_test”
返回结果:
{“acknowledged”:true,“shards_acknowledged”:true,“index”:“bxg_test”}

看到和之前带有 “pretty” 的不同了吧,返回的结果内容一样,但格式不同,之前是格式化后的,而现在是全都堆在了一行。
所以,“pretty” 这个参数就是用来 格式化返回结果 用的。
创建完成之后,我们查询一下现在 ElasticSearch 中已有的索引列表:
curl -X GET “localhost:9200/_cat/indices?v&pretty”
返回结果比较长,直接看图:

可以看到新建的索引 “bxg” 了。
你可能已经注意到了 “bxg” 这个索引的 “health” 是 “yellow” 黄色的。
即使我们刚刚接触 ElasticSearch,不知道 “health” 具体有哪些情况,但是根据常识,也能知道 “yellow” 是有一点问题的,反正不是非常健康的状态。
在现在这个测试环境下,“yellow” 是正常的,因为我们只部署了一个 ElasticSearch 节点。
在创建索引的时候,默认会为这个索引创建一个副本的,但因为现在只有一个节点,那么副本的创建自然就不正常了,所以这里是 “yellow”,不用担心,是正常的。
索引可以创建,自然也可以删除,现在来看看如何删除。
把之前创建的索引 “bxg” 删除,发起删除索引的请求:
curl -X DELETE “localhost:9200/bxg?pretty”

返回信息显示删除成功了,我们再查看索引列表确认一下:
curl -X GET “localhost:9200/_cat/indices?v&pretty”

OK,“bxg_test” 这个索引已经没有了。
文档
插入一个最简单的文档到索引 “bxg” 中:
curl -X PUT "localhost:9200/bxg/doc/1?pretty" -H 'Content-Type: application/json' -d'
{
"name": "ElasticSearch"
}
'
这个请求有点复杂,咱们得仔细的看一下。
请求地址中 “bxg” 是目标索引名称,后面的 “doc” 是 type 类型的名称,之后的 “1” 是给要插入的文档指定的 ID。
“-H” 指定请求头中 “Content-Type” 属性值为 JSON 类型。
“-d” 指定的就是要插入的文档内容了。
返回结果:
{
"_index" : "bxg",
"_type" : "doc",
"_id" : "1",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1
}
“result” 这项的值为 “created”,说明插入成功了。
“_id” 项的值为 “1”,这是我们插入时指定的。
“_type” 的值为 “doc”,也是我们插入时指定的。
请求整体形式如下:
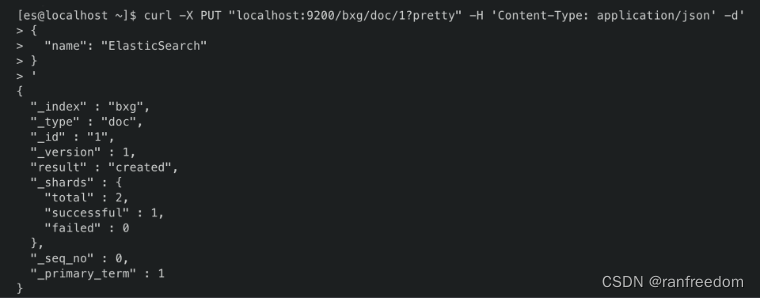 OK 插入成功了,但是,好像哪里不对劲!
OK 插入成功了,但是,好像哪里不对劲!
“bxg” 这个索引不存在啊,怎么就插入成功了?
之前实践删除索引的时候,我们已经把 “bxg” 这个索引删掉了啊。
其实,这是 ElasticSearch 的一个特性:
插入文档的时候,并不要求索引必须是存在的,如果不存在,ElasticSearch 会自动创建出来。
我们现在查看一下索引列表:
curl -X GET “localhost:9200/_cat/indices?v&pretty”

可以看到,已经有了 “bxg” 这个索引。
还有一点,插入文档的时候,也可以不指定ID,试一下:
curl -X POST "localhost:9200/bxg/doc?pretty" -H 'Content-Type: application/json' -d'
{
"name": "ES"
}
'
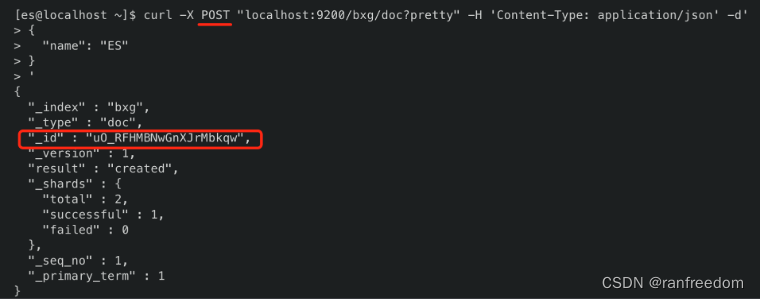
可以看到,ElasticSearch 给这个文档分配了一个随机的 ID。
这次请求使用的是 POST 方法,因为没有ID了,属于添加操作,在 REST 规范中就应该使用 POST。
之前插入了一个 ID 为 “1” 的文档,现在把他读取出来看看:
curl -X GET “localhost:9200/bxg/doc/1?pretty”

返回的内容还是很好理解的,“found” 值为 “true”,表示找到了目标文档,“_source” 字段的值就是我们插入文档时指定的内容。
目前 ID 为 “1” 的文档中 “name” 字段的值为 “ElasticSearch”:
{
“name”: “ElasticSearch”
}
现在我们修改一下 “name” 字段的值,将其改为 “A”:
{
“name”: “A”
}
发起修改文档的请求:
curl -X PUT “localhost:9200/bxg/doc/1?pretty” -H ‘Content-Type: application/json’ -d’
{
“name”: “A”
}
’
整体形式如下图:
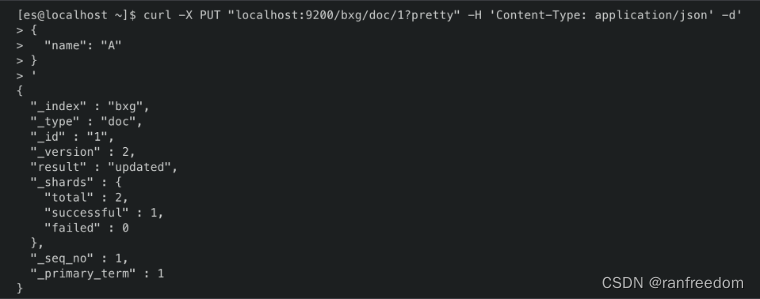
返回的结果信息中 “result” 值为 “updated”,说明修改成功了。
我们再查看一下文档的内容:
curl -X GET “localhost:9200/bxg/doc/1?pretty”
返回结果:
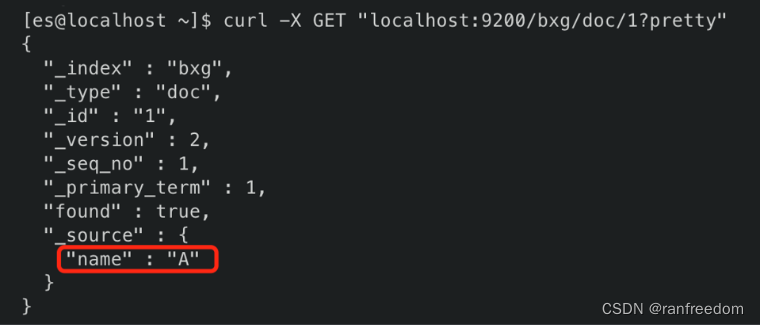
可以看到 “name” 的值已经变为了 “A”。
刚才是修改现有字段的值,那么 可以新添加字段吗?
完全没问题,下面就新添加一个字段 “age”,文档的内容变为:
{
“name”: “A”,
“age”: 10
}
发起修改文档的请求:
curl -X PUT “localhost:9200/bxg/doc/1?pretty” -H ‘Content-Type: application/json’ -d’
{
“name”: “A”,
“age”: 10
}
’
请求结果: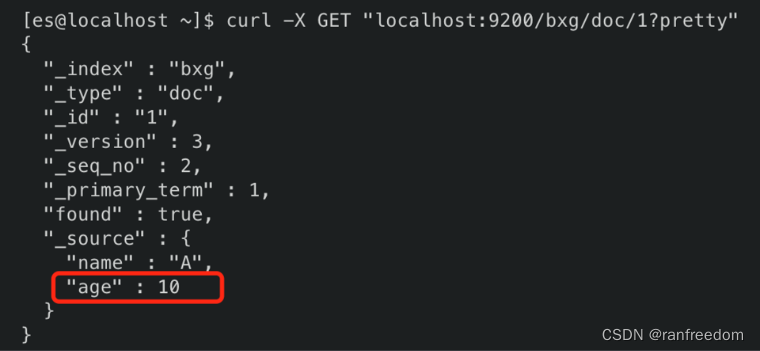 添加成功了。
添加成功了。
现在把 ID 为 “1” 的文档删除掉,发起请求:
curl -X DELETE “localhost:9200/bxg/doc/1?pretty”
返回结果: 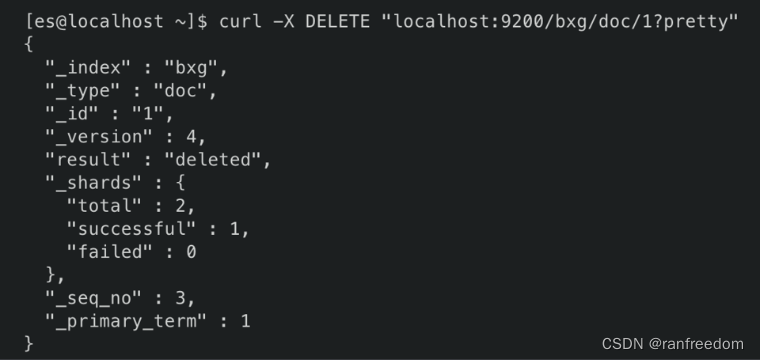
“result” 值为 “deleted”,说明删除成功了。
删除后再读取文档会怎么样呢?
我们试试:
curl -X GET “localhost:9200/bxg/doc/1?pretty”
返回结果:

返回信息中 “found” 值为 “false”,说明没有找到目标文档。
搜索
现在我们要实践 ElasticSearch 强大的数据搜索能力,既然是要搜索,那肯定要有大量的数据作为搜索目标。
咱们一条条自己插入是不现实的,幸好 ElasticSearch 官网已经给我们准备好了一个测试用的数据集,下载下来,然后倒入到我们自己的 ElasticSearch 就行了。
下载地址:
https://github.com/elastic/elasticsearch/blob/master/docs/src/test/resources/accounts.json?raw=true
打开页面后保存即可,得到的是一个 “accounts.json” 文件。
我在 ElasticSearch 服务器中创建了一个临时目录 “es”,然后把 “accounts.json” 文件拷贝到了这了目录下,你可以根据自己的喜欢放置 “accounts.json”。
然后开始倒入,在 “accounts.json” 所在位置执行:
curl -H “Content-Type: application/json”
-XPOST ‘localhost:9200/bank/account/_bulk?pretty&refresh’
–data-binary “@accounts.json”
请求地址中指定了目标索引为 “bank”,type 类型为 “account”,“–data-binary” 指定了 “accounts.json” 文件。
执行后会有很多的输出内容,太多了,就不贴出来了。
查看一下索引列表:
curl ‘localhost:9200/_cat/indices?v’
请求结果:

索引 “bank” 已经有了,“docs.count” 值为 1000,这意味着我们已经成功的创建了索引,并且添加了 1000 条文档。
只需要指定目标索引名称 “bank”,然后使用 “_search” 操作就可以了。
发送请求:
curl -X GET “localhost:9200/bank/_search?pretty”
请求结果: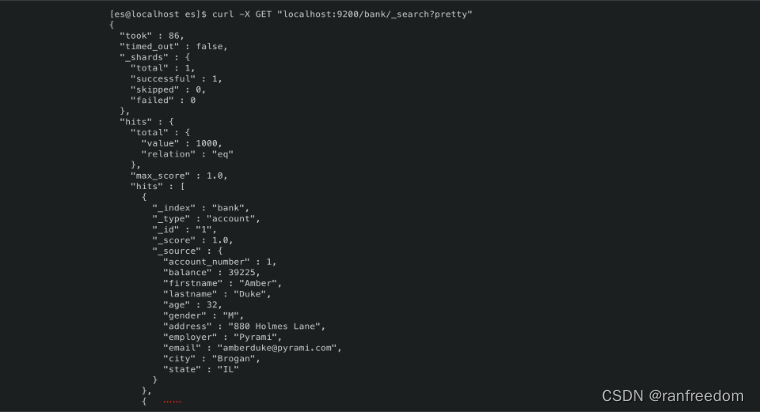
上图只是返回结果的开头部分,后边还有很多,太长了,没必要都贴出来,只看这些就可以了解查询结果的结构了。
我们分析一下其中关键信息的含义:
- took - 这次查询的耗时,单位为毫秒。
- timed_out - 表明查询是否超时了。
- _shards - 表示查询分片的情况,例如一共查询了几个分片、有几个是成功的。
- hits - 是查询结果部分。
- hits.total - 表示结果中文档的数量。
- hits.hits - 是结果数组,默认显示前10个文档。
- hits.max_score - 表示匹配度最高的文档的分值。
- hits.hits._score - 表示此文档匹配度的分值。
比如想查询出 “age = 32” 的所有文档,查询请求:
curl -X GET "localhost:9200/bank/_search?pretty" \
-H 'Content-Type: application/json' \
-d'
{
"query": { "match": { "age": 32 } }
}
'
咱们分析一下这个请求的结构,请求地址比较好理解,“bank” 是目标索引,“_search” 是指要执行搜索动作,重点是 “-d” 中的内容:
{
“query”: { “match”: { “age”: 32 } }
}
这是 ElasticSearch 的查询语言结构,“query” 部分就是指定义的查询内容,“match” 是指匹配操作,{ “age”: 32 } 就是匹配的条件。
执行结果如下图: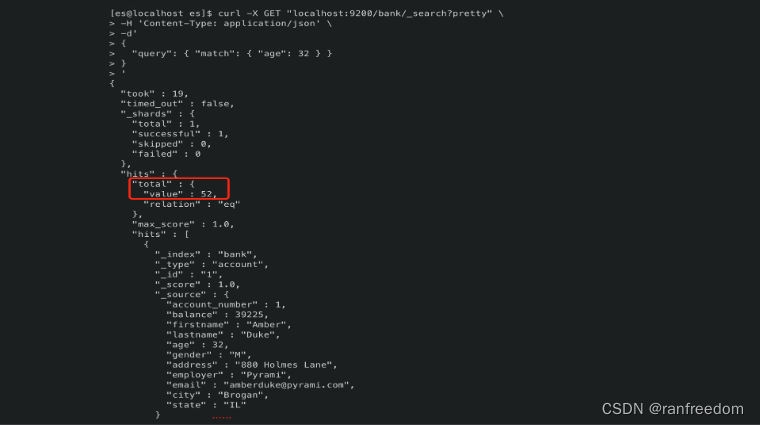
可以看到匹配到的记录一共有 “52” 条。
这个 “match” 是不是就类似 SQL 里面的 “where” 条件查询啊。
可以理解为如下的 SELECT 语句:
select …
where age = 32;
再看一个例子,例如查询 “address” 中包含 “Howard” 的记录,查询请求:
curl -X GET “localhost:9200/bank/_search?pretty”
-H ‘Content-Type: application/json’
-d’
{
“query”: { “match”: { “address”: “Howard” } }
}
’
查询结果:
上面是单条件查询,自然也可以指定多个匹配条件,写多个 “match” 即可。
需要注意的是,匹配条件多了以后,就要指定多个条件的关系了,是 “and”(并且) 呢?还是 “or”(或) 呢?
先看 “and”(并且) 的关系,查询 “address” 中同时含有 “Frost” 与 “Street” 的记录,查询请求:
curl -X GET "localhost:9200/bank/_search?pretty" \
-H 'Content-Type: application/json' \
-d'
{
"query": {
"bool": {
"must": [
{ "match": { "address": "Frost" } },
{ "match": { "address": "Street" } }
]
}
}
}
'
在 “query” 后面多了一级 “bool”,就是用来定义多个匹配条件的布尔关系的,“bool” 后面的 “must” 表示这 2 个 “match” 条件必须都满足,也就是 “and”(并且)的关系。
再看 “or”(或)的用法,查询 “address” 中含有 “Fuller” 或者 “Tapscott” 的记录,查询请求:
curl -X GET "localhost:9200/bank/_search?pretty" \
-H 'Content-Type: application/json' \
-d'
{
"query": {
"bool": {
"should": [
{ "match": { "address": "Fuller" } },
{ "match": { "address": "Tapscott" } }
]
}
}
}
'
可以看到使用 “should” 来表示多个条件的 “or”(或)关系。
我们再考虑一个稍微复杂点的需求:
查询出 “age” 等于 “32”,并且 “address” 不包含 “Tiffany” 的记录
这里多出了否定的查询方式,需要使用 “must_not” 来定义
查询请求:
curl -X GET "localhost:9200/bank/_search?pretty" \
-H 'Content-Type: application/json' \
-d'
{
"query": {
"bool": {
"must": [
{ "match": { "age": "32" } }
],
"must_not": [
{ "match": { "address": "Tiffany" } }
]
}
}
}
'
如何像 SQL 中 “limit” 一样限制查询结果的位置和数量呢?需要使用 “from” 和 “size”。
发送请求:
curl -X GET "localhost:9200/bank/_search?pretty" \
-H 'Content-Type: application/json' \
-d'
{
"query": { "match_all": {} },
"from": 10,
"size": 10
}
'
还有排序也是常用的,需要使用 “sort”。
发送请求:
curl -X GET "localhost:9200/bank/_search?pretty" \
-H 'Content-Type: application/json' \
-d'
{
"query": { "match_all": {} },
"sort": { "balance": { "order": "desc" } }
}
'
聚合
ElasticSearch Aggregation(聚合)可以对数据分组,并进行精准的统计。
ElasticSearch 中的聚合与 SQL 中的 “Group By ➕ 聚合函数” 是一个意思。
在 ElasticSearch 中有一个非常强大便利的功能,就是可以把查询结果数据与聚合结果数据在一个响应中返回。
做一个例子,根据 “state” 字段来分组,并根据组内记录数量倒序排序,返回前 10 个
查询请求:
curl -X GET "localhost:9200/bank/_search?pretty" \
-H 'Content-Type: application/json' \
-d'
{
"size": 0,
"aggs": {
"group_state": {
"terms": {
"field": "state.keyword"
}
}
}
}
'
“size” 表示我们这次不需要返回查询结果,只需要聚合结果的数据。
“aggs” 这部分是对聚合操作的定义,“group_state” 是自定义的一个分组名称,其内部 “terms” 部分指定了根据什么来分组
对于这个请求语句,你可能会有2个疑问:
(1)为什么没有指定排序的方式?
(2)为什么没有指定返回结果的数量?
这是因为这2项都是默认的,聚合的结果默认就是根据组内记录数量的倒叙排序的,而且默认返回前 10 项数据。
为了便于理解,我们把这个请求对应为熟悉的 SQL 语句:
SELECT state, COUNT(*)
FROM bank
GROUP BY state
ORDER BY COUNT(*) DESC
返回结果:
结果中 “hits” 部分是空的,就是因为指定了 “size” 为 0,不需要返回查询结果。
“buckets” 部分就是各个分组的数据,“key” 是分组字段 “state” 的值,“doc_count” 是当前分组内的记录数量。
再看一个例子,在上一个示例的基础之上,对组内的数据再次进行聚合,要计算出组内 “balance” 的平均值
查询请求:
curl -X GET "localhost:9200/bank/_search?pretty" \
-H 'Content-Type: application/json' \
-d'
{
"size": 0,
"aggs": {
"group_state": {
"terms": {
"field": "state.keyword"
},
"aggs": {
"avg_balance": {
"avg": {
"field": "balance"
}
}
}
}
}
}
'
这里使用了聚合嵌套的形式,内层的 “aggs” 定义了组内聚合操作,“avg_balance” 是自定义的聚合名称,“avg” 部分指定了对 “balance” 字段计算平均值。
查询结果:
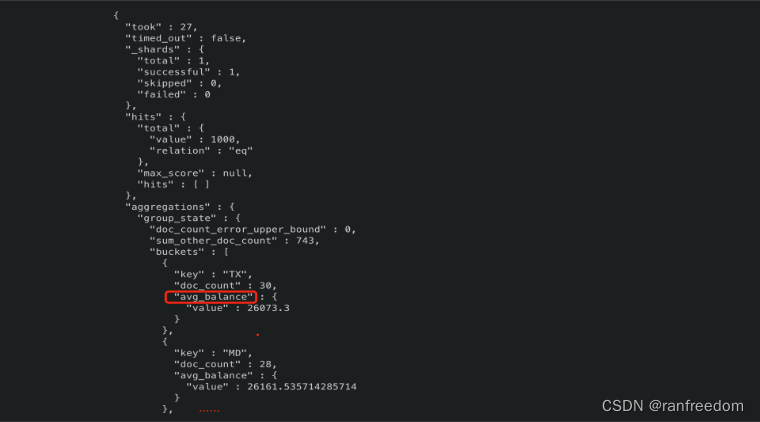
之前都是使用的默认排序方式,下面咱们自己定义排序规则:根据每组的 “avg_balance” 倒序排序
查询语句:
curl -X GET "localhost:9200/bank/_search?pretty" \
-H 'Content-Type: application/json' \
-d'
{
"size": 0,
"aggs": {
"group_by_state": {
"terms": {
"field": "state.keyword"
},
"aggs": {
"avg_balance": {
"avg": {
"field": "balance"
}
}
}
}
}
}
'
返回结果: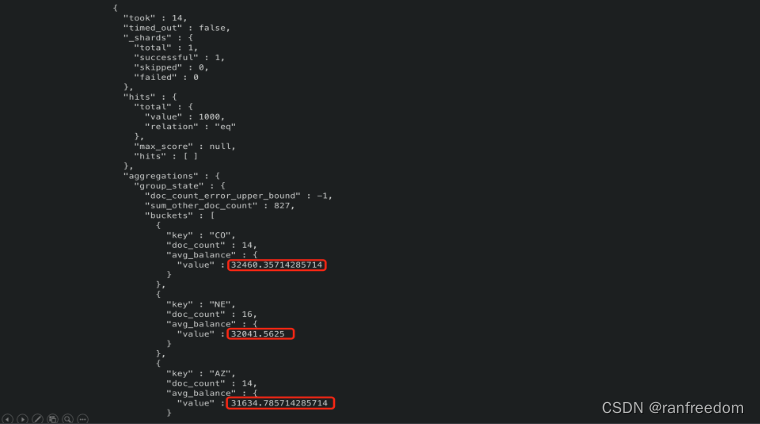
可以看到已经按照 “avg_balance” 倒序排序了。
下面做一个更复杂的聚合操作,先对 “age” 进行分组,分成几个年龄段(10-25, 25-35, 35-40),然后对各年龄段内的记录根据性别分组,这还没完,还要计算出性别分组内的 “balance” 平均值。
比较复杂是吧,看查询请求:
curl -X GET "localhost:9200/bank/_search?pretty" \
-H 'Content-Type: application/json' \
-d'
{
"size": 0,
"aggs": {
"group_age": {
"range": {
"field": "age",
"ranges": [
{
"from": 10,
"to": 25
},
{
"from": 25,
"to": 35
},
{
"from": 35,
"to": 40
}
]
},
"aggs": {
"group_gender": {
"terms": {
"field": "gender.keyword"
},
"aggs": {
"avg_balance": {
"avg": {
"field": "balance"
}
}
}
}
}
}
}
}
'
内容看起来虽然比较多,但还是比较好理解的。
通过 “range” 定义了各个范围的年龄段,然后再内层聚合中定义了 “gender” 分组,组内又定义了计算 “balance” 的平均值。
返回结果: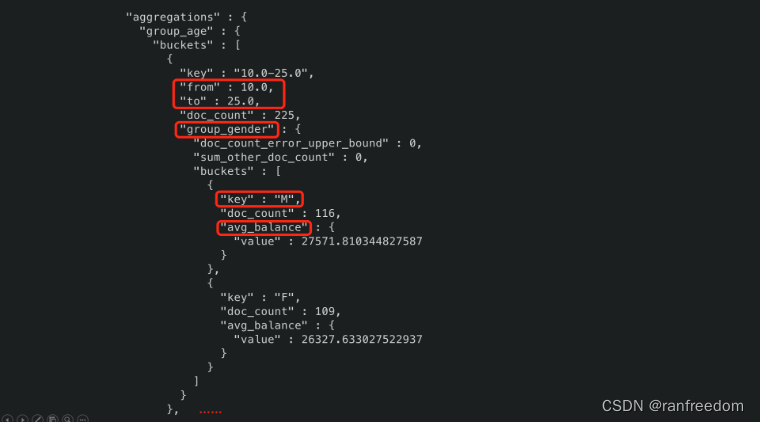
在Java中的使用
实践是检验真理的唯一标准!
所以这一关还是实践内容,我们要使用 Java 来操作 ElasticSearch,完成以下功能:
- 创建索引
- 插入文档
- 删除文档
- 查询文档
- 模板式查询
- 聚合查询
实践流程很简单,我们创建一个普通的 Maven 项目,添加好 Elasticsearch 相关依赖,然后就是一个功能一个功能的代码开发。
各个功能完全独立,在独立类中使用 main 方法开发即可。
pom.xml 文件中添加以下几个 Elasticsearch 即可:
<parent>
...
<!-- springboot 版本为 2.3.1 --->
<version>2.3.1.RELEASE</version>
<!-- elasticsearch 相关依赖 -->
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>7.8.0</version>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.8.0</version>
</dependency>
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-elasticsearch</artifactId>
<version>4.0.0.RELEASE</version>
</dependency>
</parent>
下面是创建索引的代码,很简单,先连接上 Elasticsearch,然后构建请求对象,发送请求即可。
代码中的注释已经说明得很清楚,不用多说,直接看代码。
后面其他步骤的实现代码中都有清晰的注释,同样也不用啰嗦,仔细看代码及注释即可。
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.client.indices.CreateIndexRequest;
import org.elasticsearch.client.indices.CreateIndexResponse;
import org.springframework.data.elasticsearch.client.ClientConfiguration;
import org.springframework.data.elasticsearch.client.RestClients;
public class DemoCreateIndex {
public static void main(String[] args) throws Exception{
// 创建 ElasticSearch 连接
ClientConfiguration clientConfiguration = ClientConfiguration.builder()
.connectedTo("192.168.31.210:9200")
.build();
RestHighLevelClient client = RestClients.create(clientConfiguration)
.rest();
// 构建创建索引的请求,索引名称为 "bxg_java"
CreateIndexRequest request = new CreateIndexRequest("bxg_java");
// 发起请求,创建索引
CreateIndexResponse indexResponse = client.indices().create(request, RequestOptions.DEFAULT);
// 输出返回信息
System.out.println("response id: "+indexResponse.index());
}
}
执行后查询索引列表:
curl -X GET “localhost:9200/_cat/indices?v&pretty”

import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.action.index.IndexResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.common.xcontent.XContentType;
import org.springframework.data.elasticsearch.client.ClientConfiguration;
import org.springframework.data.elasticsearch.client.RestClients;
public class DemoInsertDoc {
public static void main(String[] args) throws Exception{
// 创建 ElasticSearch 连接
ClientConfiguration clientConfiguration = ClientConfiguration.builder()
.connectedTo("192.168.31.210:9200")
.build();
RestHighLevelClient client = RestClients.create(clientConfiguration)
.rest();
// 构建请求,目标索引 "bxg_java"
IndexRequest request = new IndexRequest("bxg_java");
// 文档内容
String jsonObj = "{\"age\":20,\"birthday\":\"2020-01-02\",\"name\":\"John\"}";
// 文档设置到请求中
request.source(jsonObj, XContentType.JSON);
// 发送请求
IndexResponse indexResponse = client.index(request, RequestOptions.DEFAULT);
// 输出返回信息中的 ID
System.out.println("response id: "+indexResponse.getId());
}
}
执行后查看文档列表:
curl -X GET “localhost:9200/bxg_java/_search?pretty”
结果信息如下图: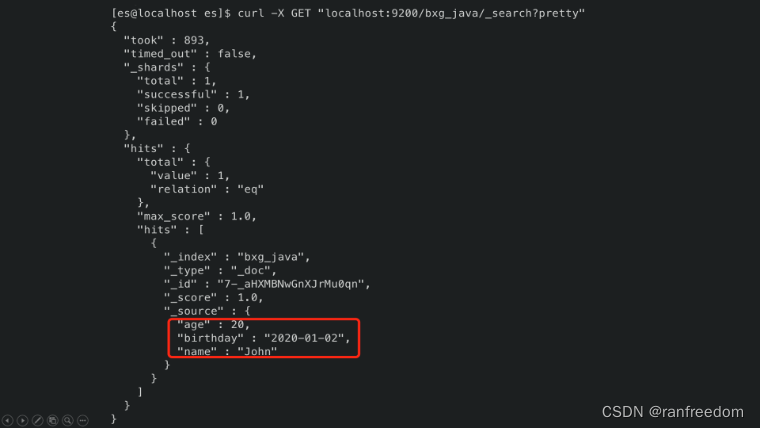
import org.elasticsearch.action.delete.DeleteRequest;
import org.elasticsearch.action.delete.DeleteResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.springframework.data.elasticsearch.client.ClientConfiguration;
import org.springframework.data.elasticsearch.client.RestClients;
public class DemoDeleteDoc {
public static void main(String[] args) throws Exception{
// 创建 ElasticSearch 连接
ClientConfiguration clientConfiguration = ClientConfiguration.builder()
.connectedTo("192.168.31.210:9200")
.build();
RestHighLevelClient client = RestClients.create(clientConfiguration)
.rest();
// 构建删除请求,目标索引 "bxg_java"
DeleteRequest deleteRequest = new DeleteRequest("bxg_java");
// 设置目标文档 ID
deleteRequest.id("7-_aHXMBNwGnXJrMu0qn");
// 发起删除请求
DeleteResponse deleteResponse = client.delete(deleteRequest, RequestOptions.DEFAULT);
// 输出返回信息
System.out.println(deleteResponse.getResult());
}
}
执行后查询文档列表:
curl -X GET “localhost:9200/bxg_java/_search?pretty”
执行结果如下图:
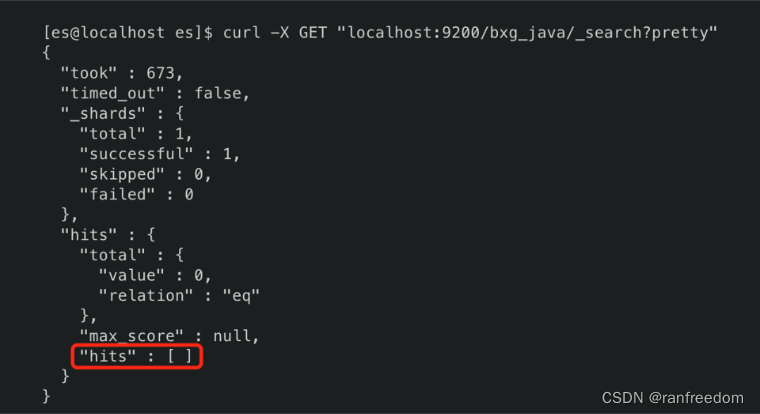
删除成功,文档列表空了。
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.index.query.QueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.springframework.data.elasticsearch.client.ClientConfiguration;
import org.springframework.data.elasticsearch.client.RestClients;
public class DemoMatchQuery {
public static void main(String[] args) throws Exception{
// 创建 ElasticSearch 连接
ClientConfiguration clientConfiguration = ClientConfiguration.builder()
.connectedTo("192.168.31.210:9200")
.build();
RestHighLevelClient client = RestClients.create(clientConfiguration)
.rest();
// 构建查询构造器,指定查询条件(age = 32)
QueryBuilder matchQueryBuilder = QueryBuilders.matchQuery("age", "32");
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
sourceBuilder.query(matchQueryBuilder);
// 构建查询请求,指定目标索引 "bank"
SearchRequest searchRequest = new SearchRequest("bank");
searchRequest.source(sourceBuilder);
// 发起查询请求
SearchResponse searchResponse = client.search(searchRequest,RequestOptions.DEFAULT);
// 输出查询结果
for(SearchHit searchHit : searchResponse.getHits().getHits()){
System.out.println(searchHit.getSourceAsString());
}
}
}
执行后返回的信息如下图:

上面的查询是构造查询对象,也可以定义一个 JSON 字符串模板,就像发送 REST 请求时一样。
使用模板的方式更容易理解,因为和我们熟悉的 REST API 很像。
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.client.indices.CreateIndexRequest;
import org.elasticsearch.client.indices.CreateIndexResponse;
import org.elasticsearch.script.ScriptType;
import org.elasticsearch.script.mustache.SearchTemplateRequest;
import org.elasticsearch.script.mustache.SearchTemplateResponse;
import org.elasticsearch.search.SearchHit;
import org.springframework.data.elasticsearch.client.ClientConfiguration;
import org.springframework.data.elasticsearch.client.RestClients;
import java.util.HashMap;
import java.util.Map;
public class DemoSearchTemplate {
public static void main(String[] args) throws Exception{
// 创建 ElasticSearch 连接
ClientConfiguration clientConfiguration = ClientConfiguration.builder()
.connectedTo("192.168.31.210:9200")
.build();
RestHighLevelClient client = RestClients.create(clientConfiguration)
.rest();
// 构建搜索模板
SearchTemplateRequest request = new SearchTemplateRequest();
// 目标索引 "bank"
request.setRequest(new SearchRequest("bank"));
// 设置查询模板
request.setScriptType(ScriptType.INLINE);
request.setScript(
"{" +
" \"query\": { \"match\" : { \"{{field}}\" : \"{{value}}\" } }" +
"}");
// 设置模板中参数的值
Map<String, Object> scriptParams = new HashMap<>();
scriptParams.put("field", "age");
scriptParams.put("value", "32");
request.setScriptParams(scriptParams);
// 发起请求
SearchTemplateResponse searchTemplateResponse = client.searchTemplate(request, RequestOptions.DEFAULT);
SearchResponse searchResponse = searchTemplateResponse.getResponse();
// 输出查询结果
for(SearchHit searchHit : searchResponse.getHits().getHits()){
System.out.println(searchHit.getSourceAsString());
}
}
}
执行后返回的信息: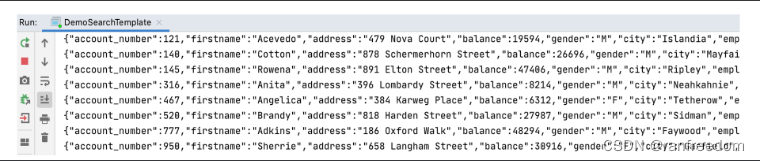
聚合需求:根据 “state” 分组,然后对组内计算 “age” 的平均值。
代码如下:
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.search.aggregations.AggregationBuilders;
import org.elasticsearch.search.aggregations.Aggregations;
import org.elasticsearch.search.aggregations.bucket.terms.Terms;
import org.elasticsearch.search.aggregations.bucket.terms.TermsAggregationBuilder;
import org.elasticsearch.search.aggregations.metrics.Avg;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.springframework.data.elasticsearch.client.ClientConfiguration;
import org.springframework.data.elasticsearch.client.RestClients;
import java.util.List;
public class DemoAggregation {
public static void main(String[] args) throws Exception{
// 创建 ElasticSearch 连接
ClientConfiguration clientConfiguration = ClientConfiguration.builder()
.connectedTo("192.168.31.210:9200")
.build();
RestHighLevelClient client = RestClients.create(clientConfiguration)
.rest();
// 构建查询构造器
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
// 创建聚合构造器,设置聚合名称 "by_state",指定聚合字段 "state"
TermsAggregationBuilder aggregation = AggregationBuilders.terms("by_state")
.field("state.keyword");
// 创建子聚合,名称 "avg_age", 聚合字段 "age"
aggregation.subAggregation(AggregationBuilders.avg("avg_age")
.field("age"));
searchSourceBuilder.aggregation(aggregation);
// 构建请求,目标索引 "bank"
SearchRequest searchRequest = new SearchRequest("bank");
searchRequest.source(searchSourceBuilder);
// 发起请求
SearchResponse searchResponse = client.search(searchRequest,RequestOptions.DEFAULT);
// 输出查询结果
Aggregations aggregations = searchResponse.getAggregations();
Terms by_state = aggregations.get("by_state");
List<? extends Terms.Bucket> buckets = by_state.getBuckets();
for (Terms.Bucket bucket : buckets){
Avg avg_age = bucket.getAggregations().get("avg_age");
System.out.println(bucket.getKey() + " - " + bucket.getDocCount() + " - " + avg_age.getValue());
}
}
}
执行后返回的信息如下图: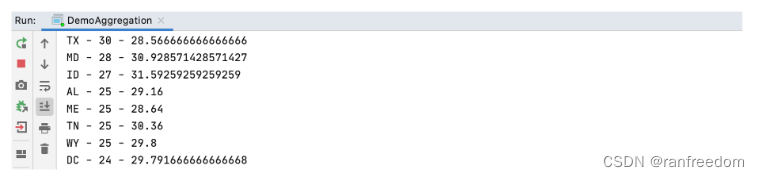
End
学习ElasticSearch,理解【倒排索引】是重中之重,最后再举个例子说明一下。
假设有 2 个文档:
1)文档1
“Shards divide data in index”
2)文档2
“ask for Shards in index”
ElasticSearch 在插入它们的时候,先分词,然后形成词与文档的对应关系: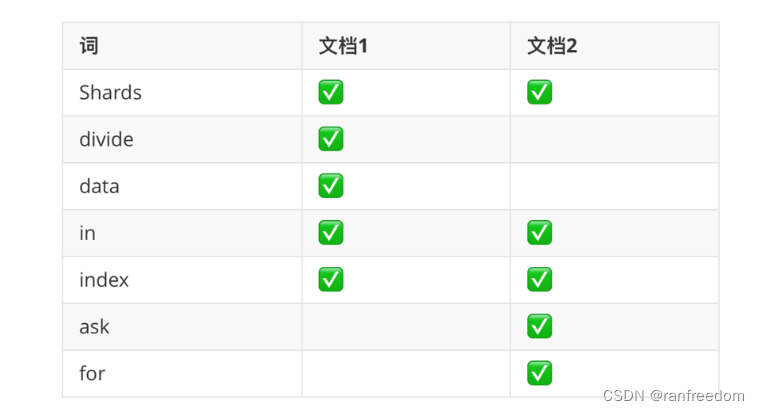
之后做关键词搜索的时候,到对应关系中找到哪些文档包含关键词;例如搜索 “index”,在表中就可以知道文档1和文档2包含它。
其余的内容都是实践操作了,需要你勤劳的双手动起来,实践 API 之后就明白了 ElasticSearch 的操作方式,实践 Java 操作 ElasticSearch 之后就明白了代码的开发方式。
如果你理解了倒排索引,并完成了实践,那么恭喜你,ElasticSearch 已经入门了
该篇文章博主是在博学谷的回车课堂中学习的,文章大量内容都是源自于其中,本来打算有空实际操作过后对文章加入个人的操作记录后再发布,但是今天回温课程的时候收到关闭通知——是的,就今天……
先发布出来,也供有需要的诸君共同学习,文章有不对或语句不通的地方也敬请指出,后续也会对文章进行修改,不胜感激















 411
411











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









