









最近看完一部小说《大奉打更人》,看得我热血沸腾。但是看完后,有选择困难症的我又不知道可以看什么了。
于是,我打算开发一个爬虫,爬取起点热榜。
一、导入所需库
我们使用 requests 来爬取网页,然后用 pyquery 解析出我们需要的信息。
import requests
from pyquery import PyQuery
二、爬取网页
起点网址:
- 电脑版:www.qidian.com
- 手机版:m.qidian.com
这里使用的是电脑版。
url = 'https://www.qidian.com/'
# 请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36 Edg/93.0.961.52'
}
html = requests.get(url=url, headers=headers)
html.encoding = 'utf-8' # utf-8 编码,否则会出现乱码
三、解析网页
html = PyQuery(html.text)
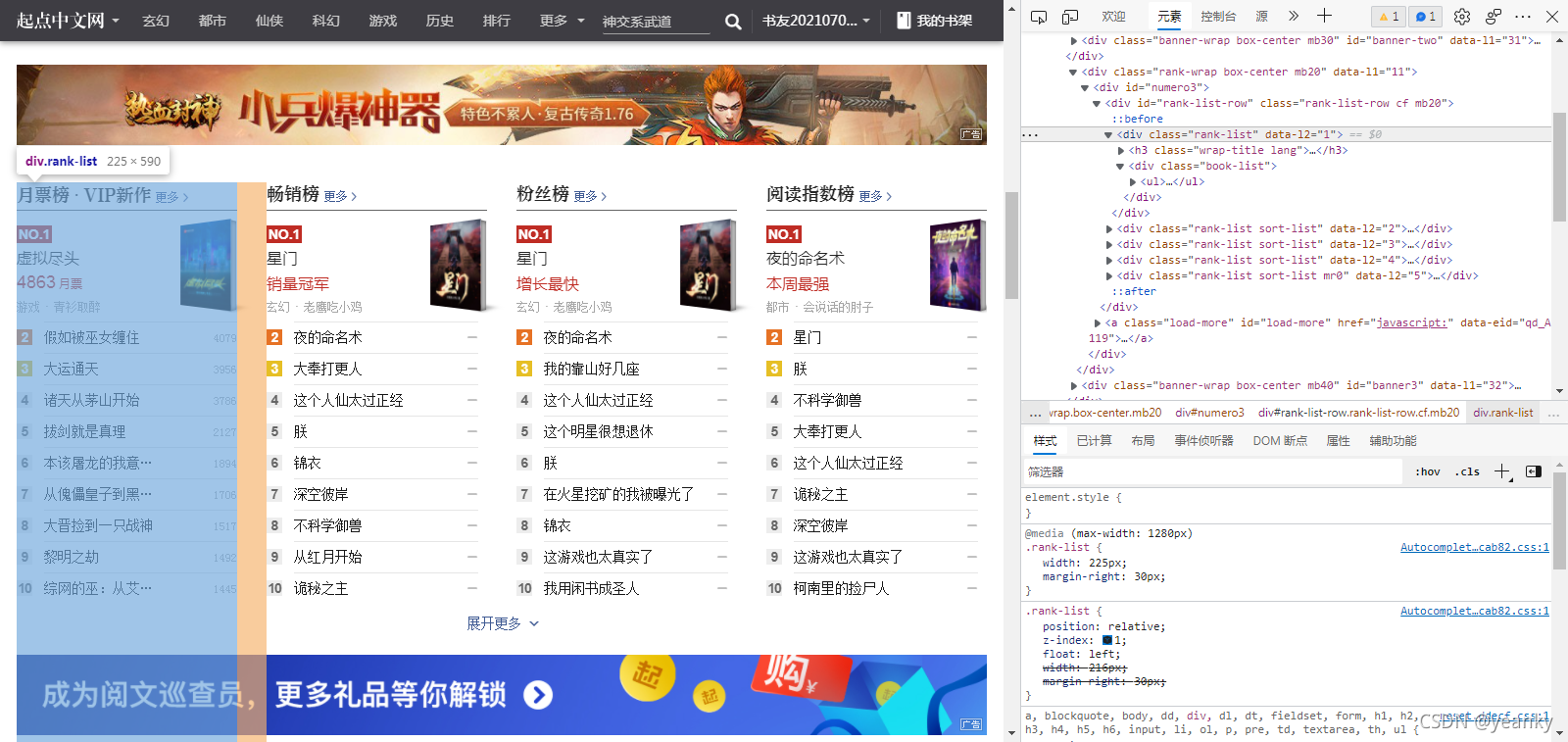
# 找到热榜节点
ranks = html.find('div#rank-list-row.rank-list-row.cf.mb20 div.rank-list').items()
books = dict()
# 遍历每一个热榜
for rank in ranks:
title = rank.find('h3 a.more').siblings().text()
books[title] = list()
# 遍历热榜的书
lis = rank.find('div.book-list ul li').items()
for li in lis:
# 排名第一的书是展开的,结构会稍有不同,我们找到我们需要的信息
if li.attr('class') == 'unfold':
books[title].append([
li.attr('data-rid'), # 序号
li.find('h4').text(), # 书名
li.find('p em').text() # 月票
])
else:
books[title].append([
li.attr('data-rid'), # 序号
li.find('div.name-box a.name').text(), # 书名
li.find('div.name-box i.total').text() # 月票
])
四、输出
# 遍历
for key, values in books.items():
print(key) # 输出榜名
for rank, name, total in values:
# 如果长度超出,则省略13位以后的
if len(name.encode('GBK')) > 30:
name = name[:13] + '...'
# 补全
name += ' ' * (30 - len(name.encode('GBK')))
print(rank.ljust(2), name, total)
print() # 空一行
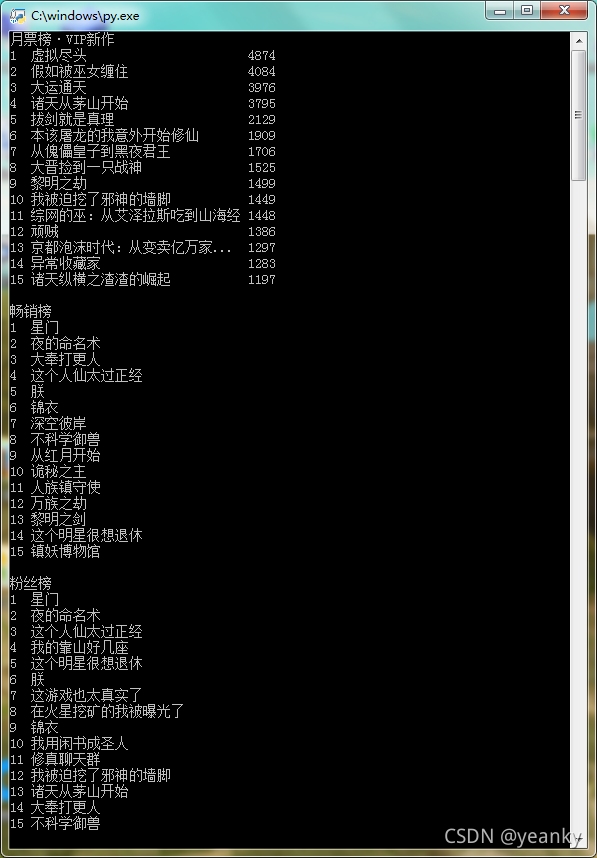
成果展示
完整代码
import requests
from pyquery import PyQuery
url = 'https://www.qidian.com/'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36 Edg/93.0.961.52'
}
# 主函数
def main():
html = requests.get(url=url, headers=headers)
html.encoding = 'utf-8'
html = PyQuery(html.text)
# 找到热榜节点
ranks = html.find('div#rank-list-row.rank-list-row.cf.mb20 div.rank-list').items()
books = dict()
# 遍历每一个热榜
for rank in ranks:
title = rank.find('h3 a.more').siblings().text()
books[title] = list()
# 遍历热榜的书
lis = rank.find('div.book-list ul li').items()
for li in lis:
# 排名第一的书是展开的,结构会稍有不同,我们找到我们需要的信息
if li.attr('class') == 'unfold':
books[title].append([
li.attr('data-rid'), # 序号
li.find('h4').text(), # 书名
li.find('p em').text() # 月票
])
else:
books[title].append([
li.attr('data-rid'), # 序号
li.find('div.name-box a.name').text(), # 书名
li.find('div.name-box i.total').text() # 月票
])
# 遍历
for key, values in books.items():
print(key) # 输出榜名
for rank, name, total in values:
# 如果长度超出,则省略13位以后的
if len(name.encode('GBK')) > 30:
name = name[:13] + '...'
# 补全
name += ' ' * (30 - len(name.encode('GBK')))
print(rank.ljust(2), name, total)
print() # 空一行
main() # 主函数
input() # 等待输入
— End —
感谢阅读!
原创不易,期待你的点赞、收藏与关注!
本文收录于专栏 Python 爬虫。
关注作者,互助交流,学习更多 Python 知识!
https://blog.csdn.net/weixin_48448842
推荐阅读















 6025
6025











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









