







Python
文章目录
| 资料 |
|---|
| 视频:尚硅谷Python爬虫教程小白零基础速通(含python基础+爬虫案例) |
| 视频笔记:笔记.exe |
| 视频代码:代码.exe |
| 视频资源:资源.exe |
一 Python 基础
1.Python 环境的安装
- 下载 Python
- 安装 Python
- 测试是否安装成功
- 点击电脑左下角开始按钮,输入 cmd 进入到 windows 的命令行模式
- 在命令行中输入 Python,正确显示 Python 版本,即表示 Python 安装成功
- 手动配置 Python 环境变量
- 如果在安装过程中,已经勾选了 Add Python 3.7 to PATH 选项,并且在 cmd 命令模式下输入 python 指令不报错,就不需要再手动的配置 Python
- 此处设置的是使用 python.exe 的环境变量
2.pip 的使用
- pip
- 是一个现代的,通用的 Python 包管理工具。提供了对 Python 包的查找、下载、安装、卸载的功能,便于我们对 Python 的资源包进行管理
- 安装
- 在安装 Python 时,会自动下载并且安装 pip
- 配置
- 在 windows 命令行里,输入 pip -V 可以查看 pip 的版本
- 如果在命令行里,运行 pip -V ,出现如下提示:'pip’不是内部或外部命令,也不是可运行的程序或批处理文件。可能是因为在安装python的过程中未勾选 Add Python 3.7 to PATH 选项,需要手动的配置 pip 的环境变量(在 Scripts 的文件夹下)
- 使用 pip 管理 Python 包
- pip install <包名>:安装指定的包
- pip uninstall <包名>:删除指定的包
- pip list:显示已经安装的包
- pip freeze:显示已经安装的包,并且以指定的格式显示
- 修改 pip 下载源
- 运行 pip install 命令会从网站上下载指定的 python 包,默认是从https://files.pythonhosted.org/ 网站上下载。这是个国外的网站,遇到网络情况不好的时候,可能会下载失败,我们可以通过命令,修改pip现在软件时的源
- 格式:pip install 包名 -i 国内源地址
- 示例:pip install ipython -i https://pypi.mirrors.ustc.edu.cn/simple/ ,就是从中国科技大学(ustc)的服务器上下载 requests(基于 python 的第三方 web 框架)
- 国内常用的pip下载源列表:
- 阿里云:http://mirrors.aliyun.com/pypi/simple/
- 中国科技大学:https://pypi.mirrors.ustc.edu.cn/simple/
- 豆瓣(douban):http://pypi.douban.com/simple/
- 清华大学:https://pypi.tuna.tsinghua.edu.cn/simple/
- 中国科学技术大学:http://pypi.mirrors.ustc.edu.cn/simple/
3.运行 Python 程序
- 终端运行
- 直接在python解释器中书写代码
- 退出python环境
- exit()
- ctrl + z ==> enter
- 使用 ipython 解释器编写代码
- 使用pip命令,可以快速的安装 IPython:pip install ipython
- . 运行 python 文件
- 使用python指令运行后缀为.py的python文件
- Pycharm
- IDE 的概念
- IDE(Integrated Development Environment)又被称为集成开发环境。说白了,就是有一款图形化界面的软件,它集成了编辑代码,编译代码,分析代码,执行代码以及调试代码等功能。在我们Python开发中,最常用的IDE是Pycharm
- pycharm由捷克公司JetBrains开发的一款IDE,提供代码分析、图形化调试器,集成测试器、集成版本控制系统等,主要用来编写Python代码
- 下载地址
- IDE 的概念
4.Python
-
注释
- 注释介绍
- 在我们工作编码的过程中,如果一段代码的逻辑比较复杂,不是特别容易理解,可以适当的添加注释,以辅助自己或者其他编码人员解读代码
- 注意:注释是给程序员看的,为了让程序员方便阅读代码,解释器会忽略注释。使用自己熟悉的语言,适当的对代码进行注释说明是一种良好的编码习惯
- 注释的分类
- 单行注释:以 # 开头,# 右边的所有东西当做说明,而不是真正要执行的程序,起辅助说明作用
- 多行注释:以 ‘’’ 开始,并以 ‘’’ 结束,我们称之为多行注释
- 注释介绍
-
变量以及数据类型
-
变量的定义
- 对于重复使用,并且经常需要修改的数据,可以定义为变量,来提高编程效率
- 定义变量的语法为: 变量名 = 变量值 。(这里的 = 作用是赋值)
- 定义变量后可以使用变量名来访问变量值
- 说明:①变量即是可以变化的量,可以随时进行修改 ②程序就是用来处理数据的,而变量就是用来存储数据的
a=1 b=1.1 c=True d=False e='例子' f="例子" g=['列表'] # 也可以双引号 h=('元组') #也可以双引号 i={'name':'字典'} #也可以双引号 -
变量的类型

-
查看数据类型
- 在python中,只要定义了一个变量,而且它有数据,那么它的类型就已经确定了,不需要咱们开发者主动的去说明它的类型,系统会自动辨别。也就是说在使用的时候 “变量没有类型,数据才有类型”
- 如果临时想要查看一个变量存储的数据类型,可以使用 type(变量的名字),来查看变量存储的数据类型
type(a)
-
-
标识符和关键字
- 计算机编程语言中,标识符是用户编程时使用的名字,用于给变量、常量、函数、语句块等命名,以建立起名称与使用之间的关系
- 标识符由字母、下划线和数字组成,且数字不能开头
- 严格区分大小写
- 不能使用关键字
- 命名规范
- 标识符命名要做到顾名思义
- 遵守一定的命名规范:驼峰命名法(大驼峰命名法和小驼峰命名法)
- 大驼峰式命名法(upper camel case): 每一个单字的首字母都采用大写字母,例如:
FirstName、LastName - 小驼峰式命名法(lower camel case): 第一个单词以小写字母开始;第二个单词的首字母大写,例如:myName、aDog
- 还有一种命名法是用下划线“_”来连接所有的单词,比如 send_buf.Python 的命令规则遵循 PEP8 标准
- 关键字
- 一些具有特殊功能的标识符,这就是所谓的关键字
- 关键字,已经被 Python 官方使用了,所以不允许开发者自己定义和关键字相同名字的标识符
- 计算机编程语言中,标识符是用户编程时使用的名字,用于给变量、常量、函数、语句块等命名,以建立起名称与使用之间的关系
-
类型转换
函数 说明 int(x) 将 x 转换为一个整数 float(x) 将 x 转换为一个浮点数 str(x) 将对象 x 转换为字符串 bool(x) 将对象 x 转换成为布尔值 - 转换成为整数
print(int("123")) # 123 将字符串转换成为整数 print(int(123.78)) # 123 将浮点数转换成为整数 print(int(True)) # 1 布尔值True转换成为整数是 1 print(int(False)) # 0 布尔值False转换成为整数是 0 # 以下两种情况将会转换失败 ''' 123.456 和 12ab 字符串,都包含非法字符,不能被转换成为整数,会报错 print(int("123.456")) print(int("12ab")) ''' - 转换成为浮点数
f1 = float("12.34") print(f1) # 12.34 print(type(f1)) # float 将字符串的 "12.34" 转换成为浮点数 12.34 f2 = float(23) print(f2) # 23.0 print(type(f2)) # float 将整数转换成为了浮点数 - 转换成为字符串
str1 = str(45) str2 = str(34.56) str3 = str(True) print(type(str1),type(str2),type(str3)) - 转换成为布尔值
''' 除了以下的将强转为 False ,其他的都将会转为 True ''' print(bool('')) print(bool("")) print(bool(0)) print(bool({})) print(bool([])) print(bool(()))
- 转换成为整数
-
运算符
-
算数运算符
下面以a=10 ,b=20为例进行计算运算符 描述 实例 + 加 两个对象相加 a + b 输出结果 30 - 减 得到负数或是一个数减去另一个数 a - b 输出结果 -10 * 乘 两个数相乘或是返回一个被重复若干次的字符串 a * b 输出结果 200 / 除 b / a 输出结果 2 // 取整数 返回商的整数部分 9//2 输出结果 4 , 9.0//2.0 输出结果 4.0 % 取余 返回除法的余数 b % a 输出结果 0 ** 指数 a**b 为10的20次方 () 小括号 提高运算优先级,比如: (1+2) * 3 注意:混合运算时,优先级顺序为: ** 高于 * / % // 高于 + - ,为了避免歧义,建议使用 () 来处理运算符优先级。 并且,不同类型的数字在进行混合运算时,整数将会转换成浮点数进行运算
算数运算符在字符串里的使用:
- 如果是两个字符串做加法运算,会直接把这两个字符串拼接成一个字符串
str1 ='hello' str2 = 'world' print(str1+str2) # 'helloworld' - 如果是数字和字符串做加法运算,会直接报错
str1 = 'hello' a = 2 print(str1+a) ''' Traceback (most recent call last): File "D:\我的下载2 代码和电路有关的\python\pyCharm\code\01.HelloWord\com\xc\HelloWord.py", line 3, in <module> print(str1+a) ~~~~^~ TypeError: can only concatenate str (not "int") to str ''' - 如果是数字和字符串做乘法运算,会将这个字符串重复多次
str1 = 'hello' print(str1*10) # hellohellohellohellohellohellohellohellohellohello
- 如果是两个字符串做加法运算,会直接把这两个字符串拼接成一个字符串
-
赋值运算符
运算符 描述 实例 = 赋值运算符 把 = 号右边的结果 赋给 左边的变量,如 num = 1 + 2 * 3,结果num的值为7 # 单个变量赋值 num = 10 print(num) # 10 # 同时为多个变量赋值(使用等号连接) a = b = 4 print(a) # 4 print(b) #4 # 多个变量赋值(使用逗号分隔) num1, f1, str1 = 100, 3.14, "hello" print(num1) # 100 print(f1) # 3.14 print(str1) # hello -
复合赋值运算符
运算符 描述 实例 += 加法赋值运算符 c += a 等效于 c = c + a -= 减法赋值运算符 c -= a 等效于 c = c - a *= 乘法赋值运算符 c *= a 等效于 c = c * a /= 除法赋值运算符 c /= a 等效于 c = c / a //= 取整除赋值运算符 c //= a 等效于 c = c // a %= 取模赋值运算符 c %= a 等效于 c = c % a **= 幂赋值运算符 c **= a 等效于 c = c ** a # 示例:*=,运算时,符号右侧的表达式先计算出结果,再与左边变量的值运算 a=100 a *= 1+2 print(a) # 300 -
比较运算符
以下假设变量a为10,变量b为20运算符 描述 实例 == 等于:比较对象是否相等 (a==b) 返回 False != 不等于:比较两个对象是否不相等 (a!=b) 返回 True > 大于:返回x是否大于y (a>b) 返回 False >= 大于等于:返回x是否大于等于y (a>=b) 返回 False < 小于:返回x是否小于y。所有比较运算符返回1表示真,返回0表示假。这分别与特殊的变量True和False等价 (a<b) 返回 True <= 小于等于:返回x是否小于等于y (a<=b) 返回 True -
逻辑运算符
运算符 逻辑表达式 描述 实例 and x and y 只要有一个运算数是 False,结果就是 False ;只有所有的运算数都为 True 时结果才是 True ,做取值运算时,取第一个为 False 的值,如果所有的值都为 True ,取最后一个值 True and True and False–>结果为 False ;True and True and True–>结果为 True or x or y 只要有一个运算数是 True ,结果就是 True ;只有所有的运算数都为 False 时,结果才是 False ,做取值运算时,取第一个为 True 的值,如果所有的值都为 False ,取最后一个值 False or False or True–>结果为 True ;False or False or False–>结果为 False not not x 布尔"非" - 如果 x 为 True,返回 False 。如果 x 为 False,它返回 True not True --> False
-
-
输入输出
- 输出
- 普通输出
print('普通输出') - 格式化输出
print("我的姓名是%s, 年龄是%d" % (name, age))
- 普通输出
- 输出
- 在 Python 中,获取键盘输入的数据的方法是采用 input 函数
password = input("请输入密码:") print('您刚刚输入的密码是:%s' % password) - input() 的小括号中放入的是提示信息,用来在获取数据之前给用户的一个简单提示
- input() 在从键盘获取了数据以后,会存放到等号右边的变量中
- input() 会把用户输入的任何值都作为字符串来对待
- 在 Python 中,获取键盘输入的数据的方法是采用 input 函数
- 输出
-
流程控制语句
- if 判断语句
if 语句是用来进行判断的if 要判断的条件: 条件成立时,要做的事情 - if else
if 条件: 满足条件时的操作 else: 不满足条件时的操作 - elif
if xxx1: 事情1 elif xxx2: 事情2 elif xxx3: 事情3 - for
在 Python 中 for 循环可以遍历任何序列的项目,如一个列表或者一个字符串等
for循环的使用for 临时变量 in 列表或者字符串等可迭代对象: 循环满足条件时执行的代码- 遍历字符串
for s in "hello": print(s) # h e l l o - 打印数字
for i in range(5): print(i) # 0 1 2 3 4
- 遍历字符串
- range
range 可以生成数字供 for 循环遍历,它可以传递三个参数,分别表示 起始、结束和步长
- if 判断语句
-
数据类型高级
- 字符串高级
函数 说明 len len函数可以获取字符串的长度 find 查找指定内容在字符串中是否存在,如果存在就返回该内容在字符串中第一次出现的开始位置索引值,如果不存在,则返回-1 startswith/endswith 判断字符串是不是以谁谁谁开头/结尾 count 返回 str在start和end之间 在 mystr里面出现的次数 replace 替换字符串中指定的内容,如果指定次数count,则替换不会超过count次 split 通过参数的内容切割字符串 upper/lower 将字符串中的大小写互换 strip 去空格 join 字符串拼接 - 列表高级
添加元素- append 会把新元素添加到列表末尾
A = ['xiaoWang','xiaoZhang','xiaoHua'] # A=['xiaoWang', 'xiaoZhang', 'xiaoHua'] print("A=%s" % A) temp = '添加的元素' A.append(temp) # A=['xiaoWang', 'xiaoZhang', 'xiaoHua', '添加的元素'] print("A=%s" % A) - insert(index, object) 在指定位置 index 前插入元素 object
strs = ['a','b','m','s'] strs.insert(3,'h') print(strs) # ['a', 'b', 'm', 'h', 's'] - 通过 extend 可以将另一个列表中的元素逐一添加到列表中
a = ['a','b','c'] b = ['d','e','f'] a.extend(b) print(a) # ['a', 'b', 'c', 'd', 'e', 'f'] 将 b 添加到 a 里 print(b) # ['d','e','f'] b的内容不变
- del:根据下标进行删除
movieName = ['加勒比海盗','骇客帝国','第一滴血','指环王','霍比特人','速度与激情'] # movieName=['加勒比海盗', '骇客帝国', '第一滴血', '指环王', '霍比特人', '速度与激情'] print('movieName=%s' % movieName) del movieName[2] # movieName=['加勒比海盗', '骇客帝国', '指环王', '霍比特人', '速度与激情'] print('movieName=%s' % movieName) - pop:删除最后一个元素
movieName = ['加勒比海盗','骇客帝国','第一滴血','指环王','霍比特人','速度与激情'] # movieName=['加勒比海盗', '骇客帝国', '第一滴血', '指环王', '霍比特人', '速度与激情'] print('movieName=%s' % movieName) movieName.pop() # movieName=['加勒比海盗', '骇客帝国', '第一滴血', '指环王', '霍比特人'] print('movieName=%s' % movieName) - remove:根据元素的值进行删除
movieName = ['加勒比海盗','骇客帝国','第一滴血','指环王','霍比特人','速度与激情'] # movieName=['加勒比海盗', '骇客帝国', '第一滴血', '指环王', '霍比特人', '速度与激情'] print('movieName=%s' % movieName) movieName.remove('指环王') # movieName=['加勒比海盗', '骇客帝国', '第一滴血', '霍比特人', '速度与激情'] print('movieName=%s' % movieName)
- 我们是通过指定下标来访问列表元素,因此修改元素的时候,为指定的列表下标赋值即可
A = ['xiaoWang','xiaoZhang','xiaoHua'] # A=['xiaoWang', 'xiaoZhang', 'xiaoHua'] print("A=%s" % A) A[1] = 'xiaoLu' # A=['xiaoWang', 'xiaoLu', 'xiaoHua'] print("A=%s" % A)
所谓的查找,就是看看指定的元素是否存在,主要包含以下 2 个方法- in(存在),如果存在那么结果为 true ,否则为 false
- not in(不存在),如果不存在那么结果为 true,否则 false
nameList = ['xiaoWang','xiaoZhang','xiaoHua'] findName = input('请输入要查找的姓名:') if findName in nameList: print('在列表中找到了相同的名字') else: print('没有找到')
- append 会把新元素添加到列表末尾
- 元组高级
Python 的元组与列表类似,不同之处在于元组的元素不能修改。元组使用小括号,列表使用方括号- 访问元组
tuple=('hello',12,30) print(tuple[0]) # hello - 修改元组
tuple=('hello',12,30) tuple[0]='world' ''' Traceback (most recent call last): File "D:\我的下载2 代码和电路有关的\python\pyCharm\code\01.HelloWord\com\xc\HelloWord.py", line 2, in <module> tuple[0]='world' ~~~~~^^^ TypeError: 'tuple' object does not support item assignment ''' - python中不允许修改元组的数据,包括不能删除其中的元素
- 定义只有一个元素的元组,需要在唯一的元素后写一个逗号
- 访问元组
- 切片
- 切片是指对操作的对象截取其中一部分的操作。字符串、列表、元组都支持切片操作
- 切片的语法:[起始:结束:步长],也可以简化使用 [起始:结束]
- 注意:选取的区间从"起始"位开始,到"结束"位的前一位结束(不包含结束位本身),步长表示选取间隔
# 索引是通过下标取某一个元素 # 切片是通过下标去某一段元素 s = 'Hello World!' print(s) print(s[4]) # o 字符串里的第4个元素 print(s[3:7]) # lo W 包含下标 3,不含下标 7 print(s[1:]) # ello World! 从下标为1开始,取出 后面所有的元素(没有结束位) print(s[:4]) # Hell 从起始位置开始,取到 下标为4的前一个元素(不包括结束位本身) print(s[1:5:2]) # el 从下标为1开始,取到下标为5的前一个元素,步长为2(不包括结束位本身) - 字典高级
查看元素- 除了使用 key 查找数据,还可以使用 get 来获取数据
info = {'name':'班长','age':18} print(info['age']) # 获取年龄 18 # print(info['sex']) # 获取不存在的key,会发生异常 print(info.get('sex')) # 获取不存在的key,获取到空的内容,不会出现异常,None print(info.get('sex', '男')) # 获取不存在的key, 可以提供一个默认值,返回 男
- 字典的每个元素中的数据是可以修改的,只要通过 key 找到,即可修改
info = {'name':'班长', 'id':100} print('修改之前的字典为 %s:' % info) info['id'] = 200 # 为已存在的键赋值就是修改 print('修改之后的字典为 %s:' % info) # 修改之后的字典为 {'name': '班长', 'id': 200}:
- 如果在使用 变量名[‘键’] = 数据 时,这个“键”在字典中,不存在,那么就会新增这个元素
info = {'name':'班长'} print('添加之前的字典为:%s' % info) info['id'] = 100 # 为不存在的键赋值就是添加元素 print('添加之后的字典为:%s' % info) # 添加之后的字典为:{'name': '班长', 'id': 100}
- del 删除指定的元素
info = {'name':'班长', 'id':100} print('删除前,%s' % info) del info['name'] # del 可以通过键删除字典里的指定元素 print('删除后,%s' % info) # 删除后,{'id': 100} - del 删除整个字典
info = {'name':'monitor', 'id':100} print('删除前,%s'%info) del info # del 也可以直接删除变量 # 这句打印直接报错 print('删除后,%s'%info) - clear 清空整个字典
info = {'name':'monitor', 'id':100} print('清空前,%s'%info) info.clear() print('清空后,%s'%info) # 清空后,{}
- 遍历字典的 key(键)
dict={'name':'Mike','age':18} for key in dict.keys(): print(key) - 遍历字典的 value(值)
dict={'name':'Mike','age':18} for key in dict.values(): print(key) - 遍历字典的项(元素)
dict={'name':'Mike','age':18} for item in dict.items(): print(item) - 遍历字典的 key-value(键值对)
dict={'name':'Mike','age':18} for key,value in dict.items(): print(key,value)
- 除了使用 key 查找数据,还可以使用 get 来获取数据
- 字符串高级
-
函数
- 定义函数
def 函数名(): 代码 - 调用函数
# 定义完函数后,函数是不会自动执行的,需要调用它才可以 f1() - 函数参数
def test(a,b): print(a,b) test(1,2) # 位置参数 1 2 test(b=1,a=2) # 关键字参数 2 1 - 函数返回值
def add2num(a, b): c = a+b return c # return 后可以写变量名、计算表达式 - 局部变量
- 局部变量,就是在函数内部定义的变量
- 其作用范围是这个函数内部,即只能在这个函数中使用,在函数的外部是不能使用的
- 全局变量
- 如果一个变量,既能在一个函数中使用,也能在其他的函数中使用,这样的变量就是全局变量
- 在函数外边定义的变量叫做 全局变量
- 全局变量能够在所有的函数中进行访问
- 定义函数
-
文件
-
文件的打开与关闭
打开文件/创建文件- 在python,使用open函数,可以打开一个已经存在的文件,或者创建一个新文件
- open(文件路径,访问模式)
f = open('test.txt', 'w') - 绝对路径:指的是绝对位置,完整地描述了目标的所在地,所有目录层级关系是一目了然的
- 相对路径:是从当前文件所在的文件夹开始的路径
- test.txt ,是在当前文件夹查找 test.txt 文件
- ./test.txt ,也是在当前文件夹里查找 test.txt 文件, ./ 表示的是当前文件夹
- …/test.txt ,从当前文件夹的上一级文件夹里查找 test.txt 文件。 …/ 表示的是上一级文件夹
- demo/test.txt ,在当前文件夹里查找 demo 这个文件夹,并在这个文件夹里查找 test.txt 文件
- 访问模式
访问模式 说明 r 以只读方式打开文件。文件的指针将会放在文件的开头。如果文件不存在,则报错。这是默认模式 w 打开一个文件只用于写入。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件 a 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入 r+ 打开一个文件用于读写。文件指针将会放在文件的开头 w+ 打开一个文件用于读写。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件 a+ 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写 rb 以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头 wb 以二进制格式打开一个文件只用于写入。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件 ab 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入 rb+ 以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头 wb+ 以二进制格式打开一个文件用于读写。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件 ab+ 以二进制格式打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写
关闭文件
# 新建一个文件,文件名为:test.txt f = open('test.txt', 'w') # 关闭这个文件 f.close() -
文件的读写
写数据(write)- 如果文件不存在,那么创建;如果存在那么就先清空,然后写入数据
f = open('test.txt', 'w') f.write('hello world, i am here!\n' * 5) f.close()
读数据(read)
- 使用 read(num) 可以从文件中读取数据,num 表示要从文件中读取的数据的长度(单位是字节),如果没有传入 num ,那么就表示读取文件中所有的数据
f = open('test.txt', 'r') content = f.read(5) # 最多读取5个数据 print(content) print("‐"*30) # 分割线,用来测试 content = f.read() # 从上次读取的位置继续读取剩下的所有的数据 print(content) f.close() - 如果用 open 打开文件时,如果使用的"r",那么可以省略 open(‘test.txt’)
读数据(readline)
- readline 只用来读取一行数据
读数据(readlines)
- readlines可以按照行的方式把整个文件中的内容进行一次性读取,并且返回的是一个列表,其中每一行为列表的一个元素。
- 如果文件不存在,那么创建;如果存在那么就先清空,然后写入数据
-
序列化和反序列化
- 通过文件操作,我们可以将字符串写入到一个本地文件。但是,如果是一个对象(例如列表、字典、元组等),就无法直接写入到一个文件里,需要对这个对象进行序列化,然后才能写入到文件里
- 设计一套协议,按照某种规则,把内存中的数据转换为字节序列,保存到文件,这就是序列化,反之,从文件的字节序列恢复到内存中,就是反序列化
- 对象—>字节序列 === 序列化
- 字节序列–>对象 ===反序列化
- JSON 模块
- JSON提供了 dump 和 dumps 方法,将一个对象进行序列化
- dumps 方法的作用是把对象转换成为字符串,它本身不具备将数据写入到文件的功能
import json file = open('names.txt', 'w') names = ['zhangsan', 'lisi', 'wangwu', 'jerry', 'henry', 'merry', 'chris'] # file.write(names) 出错,不能直接将列表写入到文件里 # 可以调用 json的dumps方法,传入一个对象参数 result = json.dumps(names) # dumps 方法得到的结果是一个字符串 print(type(result)) # <class 'str'> # 可以将字符串写入到文件里 file.write(result) file.close() - dump 方法可以在将对象转换成为字符串的同时,指定一个文件对象,把转换后的字符串写入到这个文件里
import json file = open('names.txt', 'w') names = ['zhangsan', 'lisi', 'wangwu', 'jerry', 'henry', 'merry', 'chris'] # dump方法可以接收一个文件参数,在将对象转换成为字符串的同时写入到文件里 json.dump(names, file) file.close() - 使用 JSON 实现反序列化
- 使用 loads 和 load 方法,可以将一个 JSON 字符串反序列化成为一个 Python 对象
- loads 方法需要一个字符串参数,用来将一个字符串加载成为 Python 对象
import json # 调用 loads 方法,传入一个字符串,可以将这个字符串加载成为 Python 对象 result = json.loads('["zhangsan", "lisi", "wangwu", "jerry", "henry", "merry", "chris"]') print(type(result)) # <class 'list'> - load 方法可以传入一个文件对象,用来将一个文件对象里的数据加载成为 Python 对象
import json # 以可读方式打开一个文件 file = open('names.txt', 'r') # 调用 load 方法,将文件里的内容加载成为一个 Python 对象 result = json.load(file) print(result) file.close()
-
-
异常
程序在运行过程中,由于我们的编码不规范,或者其他原因一些客观原因, 导致我们的程序无法继续运行,此时,程序就会出现异常。 如果我们不对异常进行处理,程序可能会由于异常直接中断掉。 为了保证程序的健壮性,我们在程序设计里提出了异常处理这个概念- 读取文件异常
- 在读取一个文件时,如果这个文件不存在,则会报出 FileNotFoundError 错误
- try…except 语句
- try…except 语句可以对代码运行过程中可能出现的异常进行处理
try: 可能会出现异常的代码块 except 异常的类型: 出现异常以后的处理语句try: f = open('test.txt', 'r') print(f.read()) except FileNotFoundError: print('文件没有找到,请检查文件名称是否正确')
- try…except 语句可以对代码运行过程中可能出现的异常进行处理
- 读取文件异常
二 Urllib
1.Urllib 介绍
-
什么是互联网爬虫
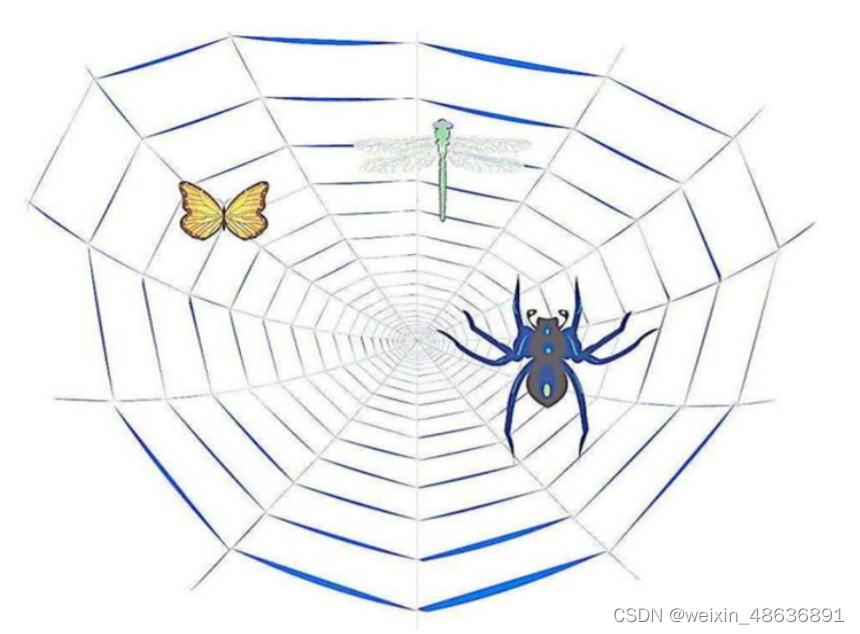
- 如果我们把互联网比作一张大的蜘蛛网,那一台计算机上的数据便是蜘蛛网上的一个猎物,而爬虫程序就是一只小蜘蛛,沿着蜘蛛网抓取自己想要的数据
-
爬虫核心
- 爬取网页:爬取整个网页 包含了网页中所有得内容
- 解析数据:将网页中你得到的数据 进行解析
- 难点:爬虫和反爬虫之间的博弈
-
爬虫的用途
- 数据分析 / 人工数据集
- 社交软件冷启动
- 舆情监控
- 竞争对手监控
-
爬虫分类
通用爬虫: 实例 百度、360、google、sougou 等搜索引擎‐‐‐伯乐在线 功能 访问网页‐>抓取数据‐>数据存储‐>数据处理‐>提供检索服务 robots协议 一个约定俗成的协议,添加 robots.txt 文件,来说明本网站哪些内容不可以被抓取,起不到限制作用 自己写的爬虫无需遵守 网站排名(SEO) 1. 根据 pagerank 算法值进行排名(参考个网站流量、点击率等指标) 2. 百度竞价排名 缺点 1. 抓取的数据大多是无用的 2.不能根据用户的需求来精准获取数据 聚焦爬虫: 功能 根据需求,实现爬虫程序,抓取需要的数据 设计思路 1.确定要爬取的 url 如何获取 Url 2.模拟浏览器通过 http 协议访问 url ,获取服务器返回的 html 代码 如何访问 3.解析 html 字符串(根据一定规则提取需要的数据) 如何解析 -
反爬手段
- User‐Agent
- User Agent中文名为用户代理,简称 UA,它是一个特殊字符串头,使得服务器能够识别客户使用的操作系统及版本、CPU 类型、浏览器及版本、浏览器渲染引擎、浏览器语言、浏览器插件等
- 代理 IP
- 西次代理 and 快代理
- 什么是高匿名、匿名和透明代理?它们有什么区别
- 使用透明代理,对方服务器可以知道你使用了代理,并且也知道你的真实 IP
- 使用匿名代理,对方服务器可以知道你使用了代理,但不知道你的真实 IP
- 使用高匿名代理,对方服务器不知道你使用了代理,更不知道你的真实 IP
- .验证码访问
- 打码平台:云打码平台
- 动态加载网页
- 网站返回的是js数据 并不是网页的真实数据
- selenium 驱动真实的浏览器发送请求
- 数据加密
- 分析 js 代码
- User‐Agent
2.Urllib 库使用以及请求对象的定制
-
Urllib 库使用
urllib.request.urlopen() 模拟浏览器向服务器发送请求 response 服务器返回的数据 response的数据类型是 HttpResponse 字节‐‐>字符串 解码 decode 字符串‐‐>字节 编码 encode read() 字节形式读取二进制 扩展:rede(5) 返回前几个字节 readline() 读取一行 readlines() 一行一行读取 直至结束 getcode() 获取状态码 geturl() 获取 url getheaders() 获取 headers urllib.request.urlretrieve() 请求网页 请求图片 请求视频 -
请求对象的定制
- UA 介绍:User Agent 中文名为用户代理,简称 UA,它是一个特殊字符串头,使得服务器能够识别客户使用的操作系统及版本、CPU 类型、浏览器及版本。浏览器内核、浏览器渲染引擎、浏览器语言、浏览器插件等
- 语法:request = urllib.request.Request()
3.编解码
- 介绍:由于计算机是美国人发明的,因此,最早只有 127 个字符被编码到计算机里,也就是大小写英文字母、数字和一些符号,这个编码表被称为ASCII编码,比如大写字母A的编码是 65,小写字母z的编码是 122。但是要处理中文显然一个字节是不够的,至少需要两个字节,而且还不能和 ASCII 编码冲突,所以,中国制定了 GB2312 编码,用来把中文编进去。你可以想得到的是,全世界有上百种语言,日本把日文编到 Shift_JIS 里,韩国把韩文编到 Euc‐kr 里,各国有各国的标准,就会不可避免地出现冲突,结果就是,在多语言混合的文本中,显示出来会有乱码。因此,Unicode 应运而生。Unicode 把所有语言都统一到一套编码里,这样就不会再有乱码问题了。Unicode 标准也在不断发展,但最常用的是用两个字节表示一个字符(如果要用到非常偏僻的字符,就需要 4 个字节)。现代操作系统和大多数编程语言都直接支持 Unicode
- get 请求方式:urllib.parse.quote()
import urllib.request import urllib.parse url = 'https://www.baidu.com/s?wd=' headers = { 'User‐Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, likeGecko) Chrome/74.0.3729.169 Safari/537.36' } url = url + urllib.parse.quote('小野') request = urllib.request.Request(url=url,headers=headers) response = urllib.request.urlopen(request) content=response.read().decode('utf‐8') print(content) - get 请求方式:urllib.parse.urlencode()
import urllib.request import urllib.parse url = 'http://www.baidu.com/s?' data = { 'name':'小刚', 'sex':'男', } data = urllib.parse.urlencode(data) url = url + data print(url) headers = { 'User‐Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, likeGecko) Chrome/74.0.3729.169 Safari/537.36' } request = urllib.request.Request(url=url,headers=headers) response = urllib.request.urlopen(request) content=response.read().decode('utf‐8') print(content) - post 请求方式
import urllib.request import urllib.parse url = 'https://fanyi.baidu.com/sug' headers = { 'user‐agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, likeGecko) Chrome/74.0.3729.169 Safari/537.36' } keyword = input('请输入您要查询的单词') data = { 'kw':keyword } data = urllib.parse.urlencode(data).encode('utf‐8') request = urllib.request.Request(url=url,headers=headers,data=data) response = urllib.request.urlopen(request) content=response.read().decode('utf‐8') print(content) - post 和 get 区别
- get 请求方式的参数必须编码,参数是拼接到 url 后面,编码之后不需要调用 encode 方法
- post请求方式的参数必须编码,参数是放在请求对象定制的方法中,编码之后需要调用 encode 方法
- 案例1:百度详细翻译
import urllib.request import urllib.parse url = 'https://fanyi.baidu.com/v2transapi' headers = { # ':authority': 'fanyi.baidu.com', # ':method': 'POST', # ':path': '/v2transapi', # ':scheme': 'https', # 'accept': '*/*', # 'accept‐encoding': 'gzip, deflate, br', # 'accept‐language': 'zh‐CN,zh;q=0.9', # 'content‐length': '119', # 'content‐type': 'application/x‐www‐form‐urlencoded; charset=UTF‐8', 'cookie':'REALTIME_TRANS_SWITCH=1;FANYI_WORD_SWITCH=1;HISTORY_SWITCH=1;SOUND_SPD_SWITCH=1;SOUND_PREFER_SWITCH=1;PSTM=1537097513;BIDUPSID=D96F9A49A8630C54630DD60CE082A55C;BAIDUID=0814C35D13AE23F5EAFA8E0B24D9B436:FG=1;to_lang_often=%5B%7B%22value%22%3A%22en%22%2C%22text%22%3A%22%u82F1%u8BED%22%7D%2C%7B%22value%22%3A%22zh%22%2C%22text%22%3A%22%u4E2D%u6587%22%7D%5D;from_lang_often=%5B%7B%22value%22%3A%22zh%22%2C%22text%22%3A%22%u4E2D%u6587%22%7D%2C%7B%22value%22%3A%22en%22%2C%22text%22%3A%22%u82F1%u8BED%22%7D%5D;BDORZ=B490B5EBF6F3CD402E515D22BCDA1598;delPer=0;H_PS_PSSID=1424_21115_29522_29519_29099_29568_28835_29220_26350;PSINO=2;locale=zh;Hm_lvt_64ecd82404c51e03dc91cb9e8c025574=1563000604,1563334706,1565592510;Hm_lpvt_64ecd82404c51e03dc91cb9e8c025574=1565592510;yjs_js_security_passport=2379b52646498f3b5d216e6b21c6f1c7bf00f062_1565592544_js', # 'origin': 'https://fanyi.baidu.com', # 'referer': 'https://fanyi.baidu.com/translate?aldtype=16047&query=&keyfrom=baidu&smartresult=dict&lang=auto2zh', # 'sec‐fetch‐mode': 'cors', # 'sec‐fetch‐site': 'same‐origin', # 'user‐agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, likeGecko) Chrome/76.0.3809.100 Safari/537.36', # 'x‐requested‐with': 'XMLHttpRequest', } data = { 'from': 'en', 'to': 'zh', 'query': 'you', 'transtype': 'realtime', 'simple_means_flag': '3', 'sign': '269482.65435', 'token': '2e0f1cb44414248f3a2b49fbad28bbd5', } #参数的编码 data = urllib.parse.urlencode(data).encode('utf‐8') # 请求对象的定制 request = urllib.request.Request(url=url,headers=headers,data=data) response = urllib.request.urlopen(request) # 请求之后返回的所有的数据 content = response.read().decode('utf‐8') import json # loads将字符串转换为python对象 obj = json.loads(content) # python对象转换为json字符串 ensure_ascii=False 忽略字符集编码 s = json.dumps(obj,ensure_ascii=False) print(s) - 案例2:豆瓣电影(ajax 的 get 请求)
# 爬取豆瓣电影前10页数据 # https://movie.douban.com/j/chart/top_list?type=20&interval_id=100%3A90&action=&start=0&limit=20 # https://movie.douban.com/j/chart/top_list?type=20&interval_id=100%3A90&action=&start=20&limit=20 # https://movie.douban.com/j/chart/top_list?type=20&interval_id=100%3A90&action=&start=40&limit=20 import urllib.request import urllib.parse # 下载前10页数据 # 下载的步骤:1.请求对象的定制 2.获取响应的数据 3.下载 # 每执行一次返回一个request对象 def create_request(page): base_url = 'https://movie.douban.com/j/chart/top_list?type=20&interval_id=100%3A90&action=&' headers = { 'User‐Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML,like Gecko) Chrome/76.0.3809.100 Safari/537.36' } data={ # 1 2 3 4 # 0 20 40 60 'start':(page‐1)*20, 'limit':20 } # data编码 data = urllib.parse.urlencode(data) url = base_url + data request = urllib.request.Request(url=url,headers=headers) return request # 获取网页源码 def get_content(request): response = urllib.request.urlopen(request) content = response.read().decode('utf‐8') return content def down_load(page,content): # with open(文件的名字,模式,编码)as fp: # fp.write(内容) with open('douban_'+str(page)+'.json','w',encoding='utf‐8')as fp: fp.write(content) if __name__ == '__main__': start_page = int(input('请输入起始页码')) end_page = int(input('请输入结束页码')) for page in range(start_page,end_page+1): request = create_request(page) content = get_content(request) down_load(page,content)
4.URLError \ HTTPError
- 简介
- .HTTPError 类是 URLError 类的子类
- .导入的包 urllib.error.HTTPError / urllib.error.URLError
- .http 错误:http 错误是针对浏览器无法连接到服务器而增加出来的错误提示。引导并告诉浏览者该页是哪里出了问题
- 通过 urllib 发送请求的时候,有可能会发送失败,这个时候如果想让你的代码更加的健壮,可以通过 try‐except 进行捕获异常,异常有两类,URLError \ HTTPError
- 示例
import urllib.request import urllib.error url = 'https://blog.csdn.net/ityard/article/details/102646738' # url = 'http://www.goudan11111.com' headers = { #'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed‐exchange;v=b3', # 'Accept‐Encoding': 'gzip, deflate, br', # 'Accept‐Language': 'zh‐CN,zh;q=0.9', # 'Cache‐Control': 'max‐age=0', # 'Connection': 'keep‐alive', 'Cookie': 'uuid_tt_dd=10_19284691370‐1530006813444‐566189;smidV2=2018091619443662be2b30145de89bbb07f3f93a3167b80002b53e7acc61420;_ga=GA1.2.1823123463.1543288103;dc_session_id=10_1550457613466.265727;acw_tc=2760821d15710446036596250e10a1a7c89c3593e79928b22b3e3e2bc98b89;Hm_lvt_e5ef47b9f471504959267fd614d579cd=1571329184;Hm_ct_e5ef47b9f471504959267fd614d579cd=6525*1*10_19284691370‐1530006813444‐566189;__yadk_uid=r0LSXrcNYgymXooFiLaCGt1ahSCSxMCb;Hm_lvt_6bcd52f51e9b3dce32bec4a3997715ac=1571329199,1571329223,1571713144,1571799968;acw_sc__v2=5dafc3b3bc5fad549cbdea513e330fbbbee00e25; firstDie=1; SESSION=396bc85c‐556b‐42bd‐890c‐c20adaaa1e47;UserName=weixin_42565646;UserInfo=d34ab5352bfa4f21b1eb68cdacd74768;UserToken=d34ab5352bfa4f21b1eb68cdacd74768; UserNick=weixin_42565646; AU=7A5;UN=weixin_42565646; BT=1571800370777; p_uid=U000000; dc_tos=pzt4xf;Hm_lpvt_6bcd52f51e9b3dce32bec4a3997715ac=1571800372;Hm_ct_6bcd52f51e9b3dce32bec4a3997715ac=1788*1*PC_VC!6525*1*10_19284691370‐1530006813444‐566189!5744*1*weixin_42565646;announcement=%257B%2522isLogin%2522%253Atrue%252C%2522announcementUrl%2522%253A%2522https%253A%252F%252Fblogdev.blog.csdn.net%252Farticle%252Fdetails%252F102605809%2522%252C%2522announcementCount%2522%253A0%252C%2522announcementExpire%2522%253A3600000%257D', # 'Host': 'blog.csdn.net', # 'Referer': 'https://passport.csdn.net/login?code=public', # 'Sec‐Fetch‐Mode': 'navigate', # 'Sec‐Fetch‐Site': 'same‐site', # 'Sec‐Fetch‐User': '?1', # 'Upgrade‐Insecure‐Requests': '1', 'User‐Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, likeGecko) Chrome/77.0.3865.120 Safari/537.36', } try: request = urllib.request.Request(url=url,headers=headers) response = urllib.request.urlopen(request) content = response.read().decode('utf‐8') print(content) except urllib.error.HTTPError: print(1111) except urllib.error.URLError: print(2222) - .cookie 登录
5.Handler 处理器与代理服务器
- 为什么要学习 handler
- urllib.request.urlopen(url):不能定制请求头
- urllib.request.Request(url,headers,data):可以定制请求头
- Handler:定制更高级的请求头,随着业务逻辑的复杂 请求对象的定制已经满足不了我们的需求(动态cookie和代理不能使用请求对象的定制)
- handler 示例
import urllib.request url = 'http://www.baidu.com' headers = { 'User ‐ Agent': 'Mozilla / 5.0(Windows NT 10.0;Win64;x64) AppleWebKit / 537.36(KHTML,likeGecko) Chrome / 74.0.3729.169Safari / 537.36' } request = urllib.request.Request(url=url,headers=headers) handler = urllib.request.HTTPHandler() opener = urllib.request.build_opener(handler) response = opener.open(request) content=response.read().decode('utf‐8') print(content) - 代理的常用功能
- 突破自身IP访问限制,访问国外站点
- 访问一些单位或团体内部资源
- 扩展:某大学FTP(前提是该代理地址在该资源的允许访问范围之内),使用教育网内地址段免费代理服务器,就可以用于对教育网开放的各类 FTP 下载上传,以及各类资料查询共享等服务)
- 提高访问速度
- 扩展:通常代理服务器都设置一个较大的硬盘缓冲区,当有外界的信息通过时,同时也将其保存到缓冲区中,当其他用户再访问相同的信息时, 则直接由缓冲区中取出信息,传给用户,以提高访问速度
- 隐藏真实 IP
- 扩展:上网者也可以通过这种方法隐藏自己的 IP,免受攻击
- 代码配置代理
- 创建 Reuqest 对象
- 创建 ProxyHandler 对象
- 用 handler 对象创建 opener 对象
- 使用 opener.open 函数发送请求
- 代理示例
import urllib.request url = 'http://www.baidu.com/s?wd=ip' headers = { 'User ‐ Agent': 'Mozilla / 5.0(Windows NT 10.0;Win64;x64) AppleWebKit / 537.36(KHTML,likeGecko) Chrome / 74.0.3729.169Safari / 537.36' } request = urllib.request.Request(url=url,headers=headers) proxies = {'http':'117.141.155.244:53281'} handler = urllib.request.ProxyHandler(proxies=proxies) opener = urllib.request.build_opener(handler) response = opener.open(request) content = response.read().decode('utf‐8') with open('daili.html','w',encoding='utf‐8')as fp: fp.write(content) - 扩展
- 代理池
- 快代理
三 解析
1.XPath
- xpath 使用
- 注意:提前安装xpath插件
①打开 chrome 浏览器 --> ②点击右上角小圆点 --> ③更多工具 --> ④扩展程序 --> ⑤拖拽 xpath 插件到扩展程序中 --> ⑥如果 crx 文件失效,需要将后缀修改 zip --> ⑦再次拖拽 --> ⑧关闭浏览器重新打开 --> ⑨ctrl + shift + x --> ⑩出现小黑框
- 安装 lxml 库
pip install lxml ‐i https://pypi.douban.com/simple - .导入 lxml.etree
from lxml import etree - etree.parse() 解析本地文件
html_tree = etree.parse('XX.html') - etree.HTML() 服务器响应文件
html_tree = etree.HTML(response.read().decode('utf‐8') - html_tree.xpath(xpath路径)
- 注意:提前安装xpath插件
- xpath 基本语法
- 路径查询
- //:查找所有子孙节点,不考虑层级关系
- / :找直接子节点
- .谓词查询
- //div[@id]
- //div[@id=“maincontent”]
- 属性查询
- //@class
- 模糊查询
- //div[contains(@id, “he”)]
- //div[starts‐with(@id, “he”)]
- .内容查询
- //div/h1/text()
- 逻辑运算
- //div[@id=“head” and @class=“s_down”]
- //title | //price
- 路径查询
2.JsonPath
| 资料 |
|---|
| 简单入门 |
-
pip 安装
pip install jsonpath -
jsonpath 的使用
obj = json.load(open('json文件', 'r', encoding='utf‐8')) ret = jsonpath.jsonpath(obj, 'jsonpath语法')
3.BeautifulSoup
-
基本简介
- BeautifulSoup 简称:bs4
- 什么是 BeatifulSoup:BeautifulSoup,和 lxml 一样,是一个 html 的解析器,主要功能也是解析和提取数据
- 优缺点
- 缺点:效率没有lxml的效率高
- 优点:接口设计人性化,使用方便
-
安装以及创建
- 安装
pip install bs4 - 导入
from bs4 import BeautifulSoup - 创建对象
- 服务器响应的文件生成对象
soup = BeautifulSoup(response.read().decode(), 'lxml') - 本地文件生成对象
# 注意:默认打开文件的编码格式gbk所以需要指定打开编码格式 soup = BeautifulSoup(open('1.html'), 'lxml')
- 服务器响应的文件生成对象
- 安装
-
节点定位
1.根据标签名查找节点 soup.a 【注】只能找到第一个a soup.a.name soup.a.attrs 2.函数 (1).find(返回一个对象) find('a'):只找到第一个a标签 find('a', title='名字') find('a', class_='名字') (2).find_all(返回一个列表) find_all('a') 查找到所有的a find_all(['a', 'span']) 返回所有的a和span find_all('a', limit=2) 只找前两个a (3).select(根据选择器得到节点对象)【推荐】 1.element eg:p 2..class eg:.firstname 3.#id eg:#firstname 4.属性选择器 [attribute] eg:li = soup.select('li[class]') [attribute=value] eg:li = soup.select('li[class="hengheng1"]') 5.层级选择器 element element div p element>element div>p element,element div,p eg:soup = soup.select('a,span') -
节点信息
- 获取节点内容:适用于标签中嵌套标签的结构
- obj.string
- obj.get_text()【推荐】
- 节点的属性
- tag.name:获取标签名
tag = find('li) print(tag.name) - tag.attrs:将属性值作为一个字典返回
- tag.name:获取标签名
- 获取节点属性
- obj.attrs.get(‘title’)【常用】
- obj.get(‘title’)
- obj[‘title’]
- 获取节点内容:适用于标签中嵌套标签的结构
四 真实浏览器交互
1.Selenium
-
什么是 Selenium
- Selenium 是一个用于 Web 应用程序测试的工具
- Selenium 测试直接运行在浏览器中,就像真正的用户在操作一样
- 支持通过各种 driver(FirfoxDriver,IternetExplorerDriver,OperaDriver,ChromeDriver)驱动真实浏览器完成测试
- Selenium 也是支持无界面浏览器操作的
-
为什么使用 Selenium
- 模拟浏览器功能,自动执行网页中的 js 代码,实现动态加载
-
如何安装 Selenium
- 操作谷歌浏览器驱动下载
- 谷歌驱动和谷歌浏览器版本之间的映射表:映射表
- 查看谷歌浏览器版本
- 谷歌浏览器右上角 --> 帮助 --> 关于
- pip install selenium
-
Selenium 的使用步骤
- 导入
from selenium import webdriver from selenium.webdriver.chrome.service import Service - 创建谷歌浏览器操作对象
ser=Service('谷歌浏览器驱动文件路径') browser=webdriver.Chrome(service=ser) - 访问网址
url = 要访问的网址 browser.get(url)
- 导入
-
Selenium 的元素定位
元素定位:自动化要做的就是模拟鼠标和键盘来操作来操作这些元素,点击、输入等等。操作这些元素前首先要找到它们,WebDriver 提供很多定位元素的方法,最新方法方法(以下方法都被弃用) 示例 find_element_by_id button = browser.find_element_by_id(‘su’) find_elements_by_name name = browser.find_element_by_name(‘wd’) find_elements_by_xpath xpath1 = browser.find_elements_by_xpath(‘//input[@id=“su”]’) find_elements_by_tag_name names = browser.find_elements_by_tag_name(‘input’) find_elements_by_css_selector my_input = browser.find_elements_by_css_selector(‘#kw’)[0] find_elements_by_link_text browser.find_element_by_link_text(“新闻”) -
访问元素信息
方法 作用 .get_attribute(‘class’) 获取元素属性 .text 获取元素文本 .tag_name 获取标签名 -
交互
方法 作用 click() 点击 send_keys() 输入 browser.back() 后退操作 browser.forword() 前进操作 js=‘document.documentElement.scrollTop=100000’(此方法无效) 模拟JS滚动 browser.execute_script(js代码) 执行js代码 page_source 获取网页代码 browser.quit() 退出
2.Phantomjs
- 什么是 Phantomjs
- 是一个无界面的浏览器
- 支持页面元素查找,js 的执行等
- 由于不进行 css 和 gui 渲染,运行效率要比真实的浏览器要快很多
- 由于合伙人问题,Phantomjs 已经停止更新
- 如何使用 Phantomjs
- 获取 PhantomJS.exe 文件路径 path
- browser = webdriver.PhantomJS(path)
- browser.get(url)
- 扩展:保存屏幕快照:browser.save_screenshot(‘baidu.png’)
3.Chrome handless
- Chrome-headless 模式, Google 针对 Chrome 浏览器 59版 新增加的一种模式,可以让你不打开 UI 界面的情况下使用 Chrome 浏览器,所以运行效果与 Chrome 保持完美一致
- 系统要求
- Chrome
- Unix\Linux 系统需要 chrome >= 59
- Windows 系统需要 chrome >= 60
- Python3.6
- Selenium==3.4.*
- ChromeDriver==2.31
- Chrome
- 配置
from selenium import webdriver from selenium.webdriver.chrome.options import Options chrome_options = Options() chrome_options.add_argument('--headless') chrome_options.add_argument('--disable‐gpu') path = r'C:\Program Files (x86)\Google\Chrome\Application\chrome.exe' chrome_options.binary_location = path browser = webdriver.Chrome(options=chrome_options) browser.get('http://www.baidu.com/') - 配置封装
from selenium import webdriver #这个是浏览器自带的 不需要我们再做额外的操作 from selenium.webdriver.chrome.options import Options def share_browser(): #初始化 chrome_options = Options() chrome_options.add_argument('‐‐headless') chrome_options.add_argument('‐‐disable‐gpu') #浏览器的安装路径 打开文件位置 #这个路径是你谷歌浏览器的路径 path = r'C:\Program Files (x86)\Google\Chrome\Application\chrome.exe' chrome_options.binary_location = path browser = webdriver.Chrome(chrome_options=chrome_options) return browser # 封装调用 from handless import share_browser browser = share_browser() browser.get('http://www.baidu.com/') browser.save_screenshot('handless1.png')
五 requests
1.基本使用
- 文档
- 安装
pip install requests - response 的属性以及类型
- 类型:models.Response
- 属性
属性 说明 r.text 获取网站源码 r.encoding 访问或定制编码方式 r.url 获取请求的 url r.content 响应的字节类型 r.status_code 响应的状态码 r.headers 响应的头信息
2.get 请求
- requests.get()
import requests url = 'http://www.baidu.com/s?' headers = { 'User‐Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML,like Gecko) Chrome/65.0.3325.181 Safari/537.36' } data = { 'wd':'北京' } response = requests.get(url,params=data,headers=headers) - 定制参数
- 参数使用 params 传递
- 参数无需 urlencode 编码
- 不需要请求对象的定制
- 请求资源路径中 ? 可加可不加
3.post请求
- requests.post()
# 百度翻译 import requests post_url = 'http://fanyi.baidu.com/sug' headers={ 'User‐Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36(KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36' } data = { 'kw': 'eye' } r = requests.post(url = post_url,headers=headers,data=data) - get 和 post 区别
- get 请求的参数名字是 params ,post 请求的参数的名字是 data
- 请求资源路径后面可以不加 ?
- 不需要手动编解码
- 不需要做请求对象的定制
4.代理
- proxy 定制
在请求中设置 proxies 参数
参数类型是一个字典类型import requests url = 'http://www.baidu.com/s?' headers = { 'user‐agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML,like Gecko) Chrome/65.0.3325.181 Safari/537.36' } data = { 'wd':'ip' } proxy = { 'http':'219.149.59.250:9797' } r = requests.get(url=url,params=data,headers=headers,proxies=proxy) with open('proxy.html','w',encoding='utf‐8') as fp: fp.write(r.text)
5.cookie 定制
- 应用案例
- 古诗文网(需要验证)
- 云打码平台
- 用户登陆 actionuser action
- 开发者登陆 actioncode action
六 scrapy
1.scrapy
①scrapy 介绍
-
scrapy 是什么
- Scrapy 是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中
-
安装
安装 scrapy: pip install scrapy 安装过程中出错: 如果安装有错误!!!! pip install Scrapy building 'twisted.test.raiser' extension error: Microsoft Visual C++ 14.0 is required. Get it with "Microsoft Visual C++ Build Tools": http://landinghub.visualstudio.com/visual‐cpp‐build‐tools 解决方案: http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted 下载twisted对应版本的 whl 文件(如我的 Twisted‐17.5.0‐cp36‐cp36m‐win_amd64.whl),cp 后面是 python 版本,amd64 代表 64 位,运行命令: pip install C:\Users\...\Twisted‐17.5.0‐cp36‐cp36m‐win_amd64.whl pip install Scrapy 如果再报错 python ‐m pip install ‐‐upgrade pip 如果再报错 win32 解决方法: pip install pypiwin32 再报错:使用 anaconda 使用步骤: 打开 anaconda 点击 environments 点击 not installed 输入 scrapy apply 在 pycharm 中选择 anaconda 的环境
②scrapy 项目的创建以及运行
- 创建 scrapy 项目
- 终端输入:scrapy startproject 项目名称
- 项目组成
- spiders
- __init__.py
- 自定义的爬虫文件.py --> 由我们自己创建,是实现爬虫核心功能的文件
- __init__.py
- items.py --> 定义数据结构的地方,是一个继承自 scrapy.Item 的类
- middlewares.py --> 中间件 代理
- pipelines.py --> 管道文件,里面只有一个类,用于处理下载数据的后续处理。默认是 300 优先级,值越小优先级越高(1‐1000)
- settings.py --> 配置文件 比如:是否遵守 robots 协议,User‐Agent 定义等
- spiders
- 创建爬虫文件
- 跳转到 spiders 文件夹:cd 目录名字/目录名字/spiders
- scrapy genspider 爬虫名字 网页的域名
- 爬虫文件的基本组成
继承 scrapy.Spider 类- name = ‘baidu’ --> 运行爬虫文件时使用的名字
- allowed_domains --> 爬虫允许的域名,在爬取的时候,如果不是此域名之下的
url ,会被过滤掉 - start_urls --> 声明了爬虫的起始地址,可以写多个 url ,一般是一个
- parse(self, response) --> 解析数据的回调函数
- response.text --> 响应的是字符串
- response.body --> 响应的是二进制文件
- response.xpath() --> xpath 方法的返回值类型是 selector 列表
- extract() --> 提取的是 selector 对象的是 data
- extract_first() --> 提取的是 selector 列表中的第一个数据
- 运行爬虫文件
- scrapy crawl 爬虫名称
- 注意:应在spiders文件夹内执行
③scrapy 架构组成
- 引擎
- 自动运行,无需关注,会自动组织所有的请求对象,分发给下载器
- 下载器
- 从引擎处获取到请求对象后,请求数据
- spiders
- Spider 类定义了如何爬取某个(或某些)网站。包括了爬取的动作(例如:是否跟进链接)以及如何从网页的内容中提取结构化数据(爬取 item )。 换句话说,Spider 就是您定义爬取的动作及分析某个网页(或者是有些网页)的地方
- 调度器
- 有自己的调度规则,无需关注
- 管道(Item pipeline)
- 最终处理数据的管道,会预留接口供我们处理数据
- 当 Item 在 Spider 中被收集之后,它将会被传递到 Item Pipeline ,一些组件会按照一定的顺序执行对 Item 的处理。每个 item pipeline 组件(有时称之为“Item Pipeline”)是实现了简单方法的 Python 类。他们接收到 Item 并通过它执行一些行为,同时也决定此 Item 是否继续通过 pipeline,或是被丢弃而不再进行处理
- 以下是 item pipeline 的一些典型应用
- 清理 HTML 数据
- 验证爬取的数据(检查 item 包含某些字段)
- 查重(并丢弃)
- 将爬取结果保存到数据库中
④scrapy 工作原理
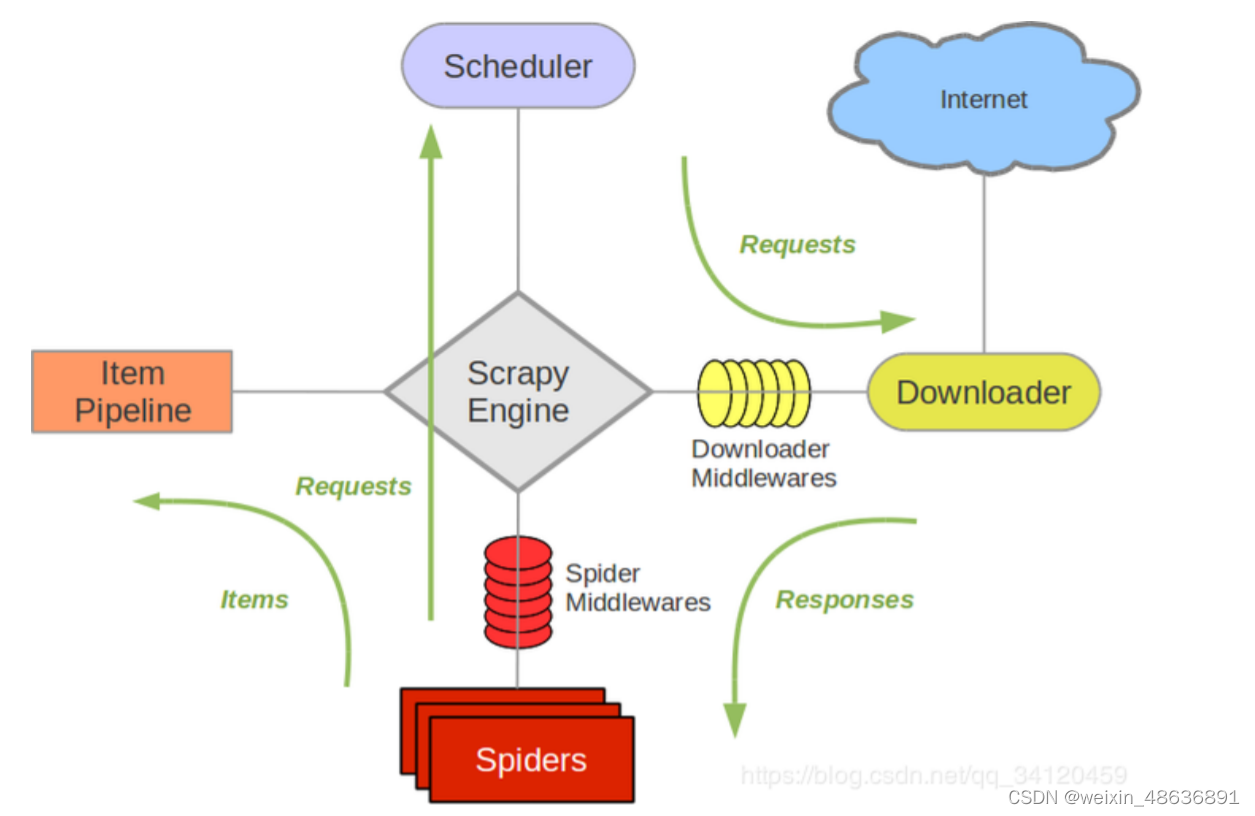
- 简图
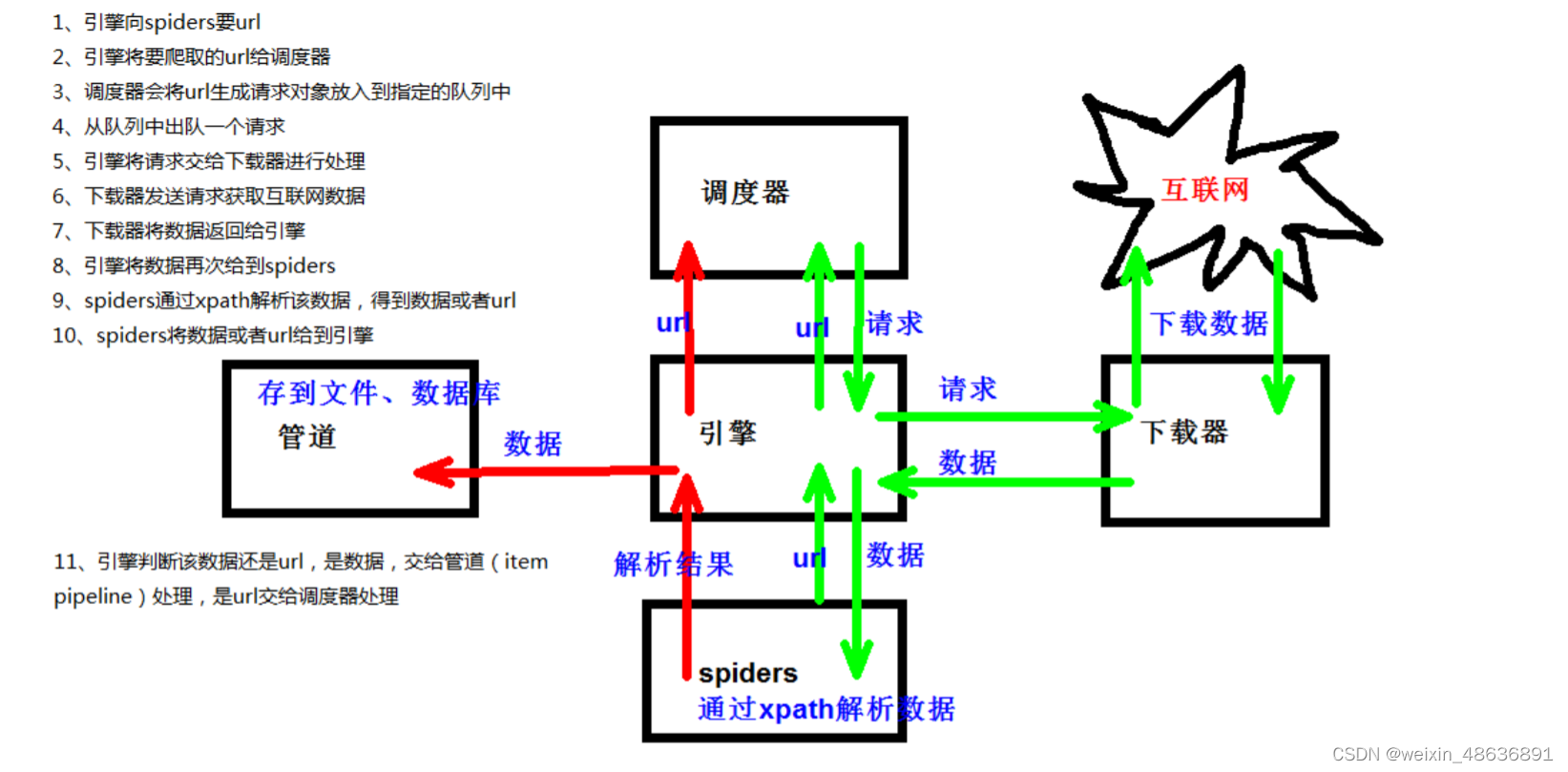
- 详细图
- 案例
- 汽车之家
2.scrapy shell
- 什么是 scrapy shell
- Scrapy 终端,是一个交互终端,供您在未启动 spider 的情况下尝试及调试您的爬取代码。 其本意是用来测试提取数据的代码,不过您可以将其作为正常的 Python 终端,在上面测试任何的 Python 代码
- 该终端是用来测试 XPath 或 CSS 表达式,查看他们的工作方式及从爬取的网页中提取的数据。 在编写您的 spider 时,该终端提供了交互性测试您的表达式代码的功能,免去了每次修改后运行 spider 的麻烦
- 一旦熟悉了 Scrapy 终端后,您会发现其在开发和调试 spider 时发挥的巨大作用
- 安装 ipython
- 安装:pip install ipython
- 简介:如果您安装了 IPython ,Scrapy 终端将使用 IPython (替代标准 Python 终端)。 IPython 终端与其他相比更为强大,提供智能的自动补全,高亮输出,及其他特性
- 应用
- scrapy shell www.baidu.com
- scrapy shell http://www.baidu.com
- scrapy shell “http://www.baidu.com”
- scrapy shell “www.baidu.com”
- 语法
- response 对象
- response.body
- response.text
- response.url
- response.status
- response 的解析
- response.xpath()【常用】 --> 使用 xpath 路径查询特定元素,返回一个 selector 列表对象
- response.css() --> 使用 css_selector 查询元素,返回一个 selector 列表对象
- 获取内容 :response.css(‘#su::text’).extract_first()
- 获取属性 :response.css(‘#su::attr(“value”)’).extract_first()
- selector对象 --> 通过 xpath 方法调用返回的是 seletor 列表
- extract()
- 提取 selector 对象的值
- 如果提取不到值 那么会报错
- 使用 xpath 请求到的对象是一个 selector 对象,需要进一步使用 extract() 方法拆包,转换为 unicode 字符串
- extract_first()
- 提取 seletor 列表中的第一个值
- 如果提取不到值 会返回一个空值
- 返回第一个解析到的值,如果列表为空,此种方法也不会报错,会返回一个空值
- 注意:每一个 selector 对象可以再次的去使用 xpath 或者 css 方法
- xpath()
- css()
- extract()
- response 对象
3.yield
- 带有 yield 的函数不再是一个普通函数,而是一个生成器 generator ,可用于迭代
- yield 是一个类似 return 的关键字,迭代一次遇到 yield 时就返回 yield 后面(右边)的值。重点是:下一次迭代时,从上一次迭代遇到的 yield 后面的代码(下一行)开始执行
- 简要理解:yield 就是 return 返回一个值,并且记住这个返回的位置,下次迭代就从这个位置后(下一行)开始
- 案例
- 当当网
- ①yield --> ②管道封装 --> ③多条管道下载 --> ④多页数据下载
- 电影天堂
- 一个 item 包含多级页面的数据
- 当当网
4.pymysql 与 CrawlSpider
-
Mysql
-
pymysql 的使用步骤
pip install pymysql pymysql.connect(host,port,user,password,db,charset) conn.cursor() cursor.execute() -
CrawlSpider
1.继承自 scrapy.Spider 2.独门秘笈 CrawlSpider 可以定义规则,再解析 html 内容的时候,可以根据链接规则提取出指定的链接,然后再向这些链接发送请求 所以,如果有需要跟进链接的需求,意思就是爬取了网页之后,需要提取链接再次爬取,使用 CrawlSpider 是非常合适的 3.提取链接 链接提取器,在这里就可以写规则提取指定链接 scrapy.linkextractors.LinkExtractor( allow = (), # 正则表达式 提取符合正则的链接 deny = (), # (不用)正则表达式 不提取符合正则的链接 allow_domains = (), # (不用)允许的域名 deny_domains = (), # (不用)不允许的域名 restrict_xpaths = (), # xpath,提取符合 xpath 规则的链接 restrict_css = () # 提取符合选择器规则的链接 ) 4.模拟使用 正则用法:links1 = LinkExtractor(allow=r'list_23_\d+\.html') xpath用法:links2 = LinkExtractor(restrict_xpaths=r'//div[@class="x"]') css用法:links3 = LinkExtractor(restrict_css='.x') 5.提取连接 link.extract_links(response) 6.注意事项 【注1】callback只能写函数名字符串, callback='parse_item' 【注2】在基本的spider中,如果重新发送请求,那里的callback写的是 callback=self.parse_item 【注‐ ‐稍后看】follow=true 是否跟进 就是按照提取连接规则进行提取 -
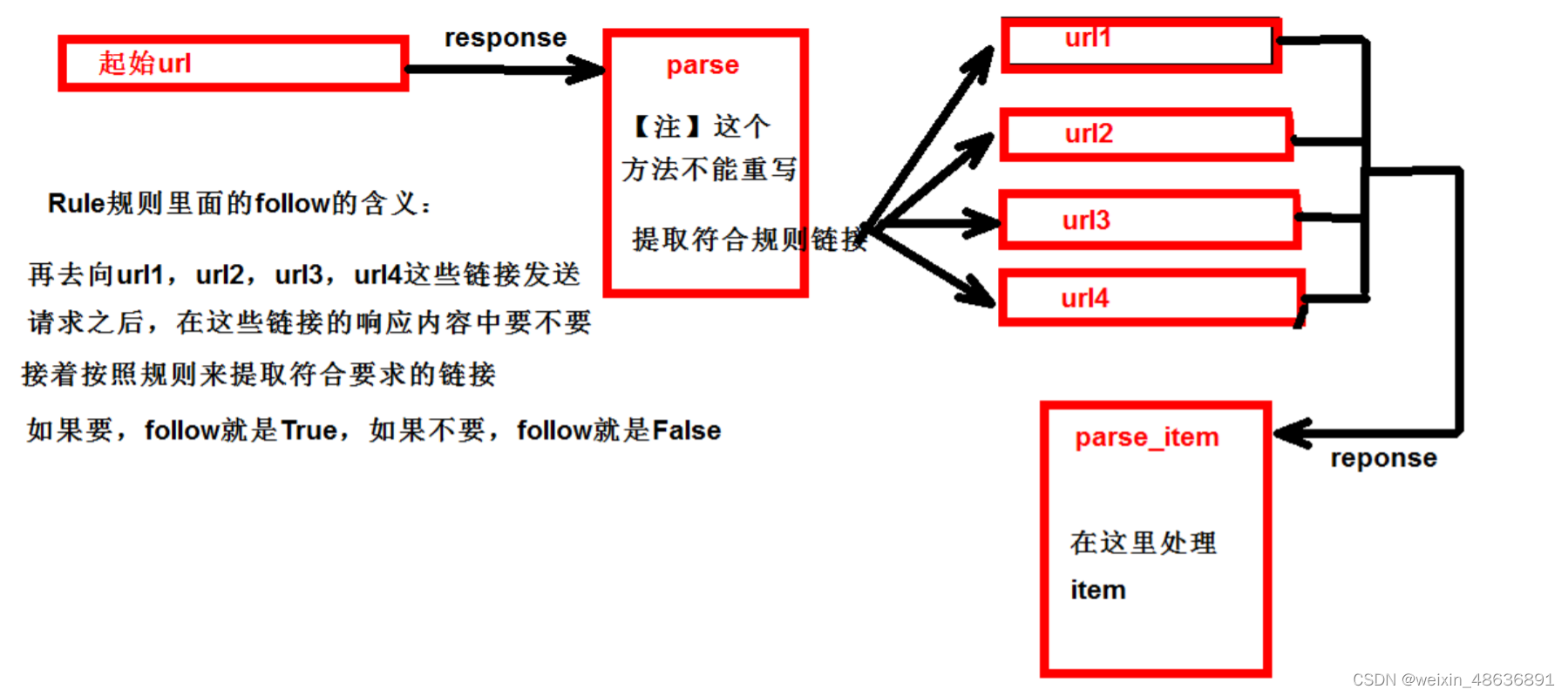
CrawlSpider 运行原理
-
CrawlSpider 案例
-
需求:读书网数据入库
-
步骤
创建项目:scrapy startproject dushuproject 跳转到spiders路径 cd\dushuproject\dushuproject\spiders 创建爬虫类:scrapy genspider ‐t crawl read www.dushu.com items spiders settings pipelines 数据保存到本地 数据保存到 mysql 数据库
-
-
数据入库
# settings 配置参数 DB_HOST = '192.168.231.128' DB_PORT = 3306 DB_USER = 'root' DB_PASSWORD = '1234' DB_NAME = 'test' DB_CHARSET = 'utf8' # 管道配置 from scrapy.utils.project import get_project_settings import pymysql class MysqlPipeline(object): #__init__方法和open_spider的作用是一样的 #init是获取settings中的连接参数 def __init__(self): settings = get_project_settings() self.host = settings['DB_HOST'] self.port = settings['DB_PORT'] self.user = settings['DB_USER'] self.pwd = settings['DB_PWD'] self.name = settings['DB_NAME'] self.charset = settings['DB_CHARSET'] self.connect() # 连接数据库并且获取cursor对象 def connect(self): self.conn = pymysql.connect(host=self.host, port=self.port, user=self.user, password=self.pwd, db=self.name, charset=self.charset) self.cursor = self.conn.cursor() def process_item(self, item, spider): sql = 'insert into book(image_url, book_name, author, info) values("%s","%s", "%s", "%s")' % (item['image_url'], item['book_name'], item['author'], item['info']) sql = 'insert into book(image_url,book_name,author,info) values("{}","{}","{}","{}")'.format(item['image_url'], item['book_name'], item['author'],item['info']) # 执行sql语句 self.cursor.execute(sql) self.conn.commit() return item def close_spider(self, spider): self.conn.close() self.cursor.close()
5.日志信息和日志等级
- 日志级别
- CRITICAL:严重错误
- ERROR: 一般错误
- WARNING: 警告
- INFO: 一般信息
- DEBUG: 调试信息
- cmd 打印日志的原因
- 默认的日志等级是 DEBUG
- 只要出现了 DEBUG 或者 DEBUG 以上等级的日志
- 那么这些日志将会打印
- settings.py 文件设置
- 默认的级别为 DEBUG ,会显示上面所有的信息
- 在配置文件中 settings.py
- LOG_FILE :将屏幕显示的信息全部记录到文件中,屏幕不再显示,注意文件后缀一定是 .log
- LOG_LEVEL :设置日志显示的等级,就是显示哪些,不显示哪些
6.scrapy 的 post 请求与代理
-
scrapy 的 post 请求
(1)重写start_requests方法: def start_requests(self) (2)start_requests的返回值: scrapy.FormRequest(url=url, headers=headers, callback=self.parse_item, formdata=data) url: 要发送的post地址 headers:可以定制头信息 callback: 回调函数 formdata: post所携带的数据,这是一个字典 -
代理
(1)到settings.py中,打开一个选项 DOWNLOADER_MIDDLEWARES = { 'postproject.middlewares.Proxy': 543, } (2)到middlewares.py中写代码 def process_request(self, request, spider): request.meta['proxy'] = 'https://113.68.202.10:9999' return None















 1358
1358











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









