








1. 手写⼀个简单的Kmeans算法
导入所需要的包
# 导入一些包
import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
%matplotlib inline
from sklearn.datasets import make_blobs
模拟数据
# 模拟出一些数据集出来
#r = np.random.randint(1,100)
r = 4
#print(r)
k = 3
x , y = make_blobs(n_samples = 300,
cluster_std = [0.3, 0.3, 0.3],
centers = [[0,0],[1,1],[-1,1]]
,random_state = r
)
sim_data = pd.DataFrame(x, columns = ['x1', 'x2'])
sim_data['label'] = y
sim_data.head(5)
datasets = sim_data.copy()
plt.scatter(sim_data['x1'], sim_data['x2'])

因为聚类分析是无监督学习方式,所以在代码中不需要y值,都只有x值就好了。所以drop弹出y
取出最大值与最小值
data_content = datasets.drop('label',axis=1)
range_info =data_content.describe().loc[['min','max'],:]
随机产生3个介于最大值与最小值之间的数(这样写代码更有拓展性,实用性强)
#这样的代码实用性会更强,上面只适用于X1和X2
# 这个代码可以适用于所有数据
l = []
for i in data_content.columns:
l.append(np.random.uniform(range_info[i]['min'],range_info[i]['max'],3))
l
这个作为初始的聚类中心点的位置,介于最大值与最小值之间

转成表格DataFrame
pd.DataFrame(l,index = data_content.columns).T

这3个初始值的聚类中心点就是
(1.796770 ,-0.384921)
(-0.119144, -0.497739)
(1.258498, -0.322896)
因为for循环有对大数据不采用,所以这里教一种减少循环次数的方法
# 列表解析式
[np.random.uniform(range_info[i]['min'],
range_info[i]['max'],3) for i in data_content.columns]
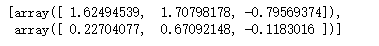
这个是取出k个随机的介于最大值和最小值之间的数
# 从i的最大最小中随机生成k个数
np.random.uniform(range_info[i]['min'],range_info[i]['max'],k)
这个比上一个更有拓展性,可以外部设置K值(聚类点数)
# 使用列表解析式写出一个更加有拓展性的代码
k = 4
k_randoms = [np.random.uniform(range_info[i]['min'],
range_info[i]['max'], k) for i in data_content.columns]
k_randoms
转成表格形式
# 将最后的k_randoms转化成dataframe的格式
centers = pd.DataFrame(k_randoms, index = data_content.columns).T
centers

封装成函数,之后就可以直接用了,datasets是数据集
# 上面的都测试好之后,我们就可以把它写出一个函数
def initial_centers(datasets, k = 3):
data_content = datasets.drop('label', axis = 1)
range_info = data_content.describe().loc[['min', 'max'], :]
k_randoms = [np.random.uniform(range_info[i]['min'],
range_info[i]['max'], k) for i in data_content.columns]
centers = pd.DataFrame(k_randoms, index = data_content.columns).T
return centers
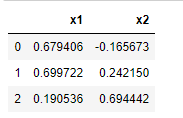
测试一下封装好的包
centers = initial_centers(datasets = datasets, k = 3)
centers
















 798
798











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









