






 本文介绍了如何使用pip和conda进行OpenAIGym的最小安装和完整安装,以及如何查看已安装的环境。文章详细讲解了Gym环境命名规则、基本函数接口,如make()、reset()、step()等,并提供了一个随机策略的完整示例。此外,还展示了如何与环境进行交互,包括环境的初始化、状态更新和奖励机制。
本文介绍了如何使用pip和conda进行OpenAIGym的最小安装和完整安装,以及如何查看已安装的环境。文章详细讲解了Gym环境命名规则、基本函数接口,如make()、reset()、step()等,并提供了一个随机策略的完整示例。此外,还展示了如何与环境进行交互,包括环境的初始化、状态更新和奖励机制。
1.1 最小安装
执行以下命令就可以完成最小安装(conda install也可以吧。当然,通常在安装之前先upgrade pip和conda是一个良好的习惯)
更新pip版本(windows cmd terminal,当然其它类型的命令行终端也应该可以。第一条语句和第三条语句是用于查看更新前后的pip的版本):
pip --version
python -m pip install --upgrade pip
pip --version更新conda版本:
conda update conda 用pip安装gym(注意,在Anaconda环境中也同样可以用pip进行安装):
pip install gym1.2 完整安装
Gym库的一些内置的扩展库并不包括在最小安装中,比如说gym[atari]、gym[box2d]、gym[mujoco]、gym[robotics]等等。以gym[atari]为例,如果要安装最小环境加上atari环境、或者在已经安装了最小环境然后要追加atari安装时可以执行以下命令:
pip install --upgrade gym[atari]也可以用下面命令安装:
pip install --upgrade gym[all](可能会有错误)
1.3 查看gym所有安装的环境
import gym
from gym import envs
# 更新到0.26.2之后更换为 env_list = envs.registry.keys()
env_list = envs.registry.all()
env_ids = [env_item.id for env_item in env_list]
print('There are {0} envs in gym'.format(len(env_ids)))
print(env_ids)
1.4 Gym环境命名规则
(1) 如果环境ID的“v”后面有数字,就代表着当前环境的版本。
(2) 环境ID有“ram”的时候,根据环境返回的“状态”是Atari游戏中使用的“ram”(Random Access Memory) “随机存取存储器”的内容。
(3) 当环境ID有“deterministic”时,agent传递给环境的动作会被重复执行4帧,然后返回“状态”。
(4) 环境ID有“NoFrameskip”的时候,agent传递给环境的动作被执行1帧,然后马上(没有跳过帧) 返回“状态”。
(5) 默认情况下,在环境ID中不包含“deterministic”、“NoFrameskip”的情况下,“动作”重复执行n帧。n从{2,3,4}均匀采样。
1.5 gym基本函数接口
使用gym环境,首先第一件事情就是通过调用gym.make()来创建环境对象。
然后,智能体通过调用env类的方法来与环境进行交互,常用的env类方法有:reset(), close(), render(), step(),等等。以下分别介绍。
① make() 生成环境对象
'''
env = gym.make(id)
说明:生成环境
参数:Id(str类型) 环境ID
返回值:env(Env类型) 环境
环境ID是OpenAI Gym提供的环境的ID,可以通过上一节所述方式进行查看有哪些可用的环境
例如,如果是“CartPole”环境,则ID可以用“CartPole-v1”。返回“Env”对象作为返回值
'''通过make()创建完环境对象后,可以查看环境的属性和当前状态,代码示例如下:
import gym
env = gym.make('CartPole-v1')
print('观测空间 = {}'.format(env.observation_space))
print('动作空间 = {}'.format(env.action_space))
print('动作数 = {}'.format(env.action_space.n))
print('观测范围 = {} - {}'.format(env.observation_space.low, env.observation_space.high))
print('动作数 = {}'.format(env.action_space.n))
1.6 reset()函数
reset()为环境复位初始化函数。将环境的状态恢复到初始状态。
init_state = env.reset()
print('初始状态 = {}'.format(init_state))
print('初始状态 = {}'.format(env.state))
'''
初始状态 = [-0.01415594 0.00287111 0.03600921 -0.01799398]
初始状态 = [-0.01415594 0.00287111 0.03600921 -0.01799397]
'''在一次任务的开始时必须调用reset(),哪怕是make()生成对象后的第一次任务。这是因为,make()生成对象后并没有顺便做一下初始化。在2.1的代码中查看env.state我们得到的是None。这里调用了reset()后才确定了初始状态。以上语句也表明,reset()所返回的init_state与调用reset后的env.state的确是相同的。
1.7 env.step():单步执行
当然这里说的单步不是指软件程序调试中所指的运行一行代码之类的,而是指智能体与环境之间的一次交互,即智能体在当前状态s下执行一次动作a,环境相应地更新至状态s',并向智能体反馈及时奖励r。
函数接口说明如下:
import gym
env = gym.make('CartPole-v1')
env.reset()
for k in range(5):
action = env.action_space.sample()
state, reward, done, info = env.step(action)
print('动作 = {0}: 当前状态 = {1}, 奖励 = {2}, 结束标志 = {3}, 日志信息 = {4}'.format(action, state, reward, done, info))
'''
动作 = 0: 当前状态 = [-0.04947745 -0.21806296 -0.02542098 0.30381304], 奖励 = 1.0, 结束标志 = False, 日志信息 = {}
动作 = 1: 当前状态 = [-0.05383871 -0.02258812 -0.01934472 0.00322255], 奖励 = 1.0, 结束标志 = False, 日志信息 = {}
动作 = 1: 当前状态 = [-0.05429048 0.17280584 -0.01928027 -0.29550055], 奖励 = 1.0, 结束标志 = False, 日志信息 = {}
动作 = 0: 当前状态 = [-0.05083436 -0.02203602 -0.02519028 -0.00896013], 奖励 = 1.0, 结束标志 = False, 日志信息 = {}
动作 = 1: 当前状态 = [-0.05127508 0.17343797 -0.02536948 -0.30948325], 奖励 = 1.0, 结束标志 = False, 日志信息 = {}
'''1.8 env.render():环境显示
以图形化的方式显示环境当前状态,在智能体与环境的持续交互过程中,该图形化显示也是相应地持续更新的。 env.render()所生成的图形窗口是以另外的独立的窗口出现。
1.9 env.seed():指定随机种子
'''
env.seed(seed=None)
说明:指定随机数种子
参数:seed(int 类型) 随机种子
返回值:seeds(list 类型) 在环境中使用的随机数种子列表
用env.seed()指定环境的随机数种子。如果想要训练的再现性,或者想要根据不同的环境使用不同的随机数种子,就可以使用该方法
'''1.10 一个随机策略的完整示例
import gym
import time
# 生成环境
env = gym.make('CartPole-v1')
# 环境初始化
state = env.reset()
# 循环交互
while True:
# 渲染画面
env.render()
# 从动作空间随机获取一个动作
action = env.action_space.sample()
# agent与环境进行一步交互
state, reward, done, info = env.step(action)
print('state = {0}; reward = {1}'.format(state, reward))
# 判断当前episode 是否完成
if done:
print('done')
break
time.sleep(1)
# 环境结束
env.close()2 Gym环境
这是一个让某种小游戏运行的简单例子。 这将运行 CartPole-v0 环境实例 1000 个时间步,在每次迭代的时候都会将环境初始化(env.render)。运行之后你将会看到一个经典的推车杆问题:
import gym
env = gym.make('CartPole-v0')
#生成环境
env.reset()
#重置环境,让环境回到起点
for _ in range(100):
env.render()
#提供环境(把游戏中发生的显示到屏幕上)
env.step(env.action_space.sample())
#env.action_space.sample() 会在动作空间中随机选择一个
#env.step会顺着这个动作进入下一个状态
env.close()2.1 动作是如何和环境交互的
与环境交互过程中,每一步环境都会返回四个值
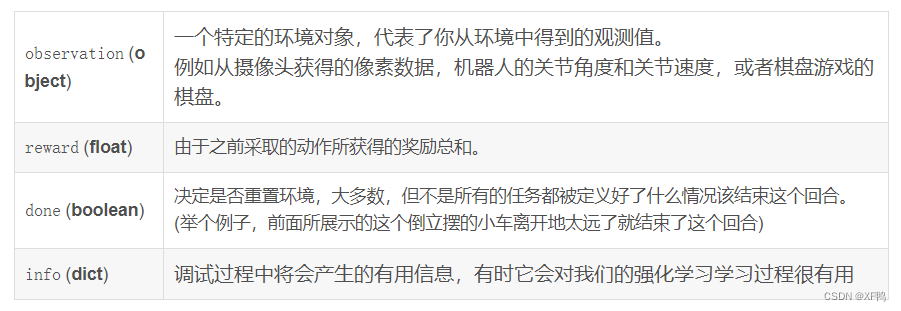
程序的开始被叫做reset(),它会返回一个初始的观测值,因此像比于前面的代码,一个改良版的方式编写代码如下所示:
import gym
env = gym.make('CartPole-v1')
for i_episode in range(2):
observation = env.reset()
#初始话环境
for t in range(100):
env.render()
#提供环境
action = env.action_space.sample()
#在可行的动作空间中随机选择一个
observation, reward, done, info = env.step(action)
#顺着这个动作进入下一个状态
print(observation, reward, done, info)
if done:
print("Episode finished after {} timesteps".format(t+1))
break
env.close()
'''
[-0.02344513 -0.17659043 0.0043245 0.27116755] 1.0 False {}
[-0.02697694 -0.37177384 0.00974786 0.5652113 ] 1.0 False {}
[-0.03441242 -0.56703115 0.02105208 0.8609492 ] 1.0 False {}
[-0.04575304 -0.7624334 0.03827107 1.1601765 ] 1.0 False {}
[-0.06100171 -0.9580325 0.0614746 1.4646091 ] 1.0 False {}
[-0.08016236 -1.1538512 0.09076678 1.7758446 ] 1.0 False {}
[-0.10323939 -0.9598616 0.12628368 1.5127068 ] 1.0 False {}
[-0.12243662 -1.1562663 0.1565378 1.8419967 ] 1.0 False {}
[-0.14556195 -0.9631801 0.19337773 1.6017431 ] 1.0 False {}
[-0.16482554 -0.7708017 0.2254126 1.3750535 ] 1.0 True {}
Episode finished after 10 timesteps
'''
'''
# 查看当前Gym库注册的那些环境
from gym import envs
env_specs = envs.registry.all()
envs_ids = [env_spec.id for env_spec in env_specs]
print(envs_ids)
'''
import gym
# MountainCar-V0例子
import gym
env = gym.make('MountainCar-v0')
print('观测空间 = {}'.format(env.observation_space))
print('动作空间 = {}'.format(env.action_space))
print('观测范围 = {} - {}'.format(env.observation_space.low, env.observation_space.high))
print('动作数 = {}'.format(env.action_space.n))
class BespokeAgent():
def __init__(self,env):
pass
def decide(self,observation): # 决策
position, velocity = observation
lb = min(-0.09 * (position + 0.25) ** 2 + 0.03, 0.3 * (position + 0.9) ** 4 - 0.08)
ub = -0.07 * (position + 0.38) ** 2 + 0.07
if lb < velocity < ub:
action = 2
else:
action = 0
return action
def learn(self, *args): # 学习
pass
agent = BespokeAgent(env)
def play_montecarlo(env, agent, render = False, train =False):
episode_reward = 0 # 记录回合总奖励,初始化0
observation = env.reset() #重置游戏环境,开始新的回合
while True:
if render:
env.render() # 显示图形界面
action = agent.decide(observation)
next_observation, reward, done, _ = env.step(action) # 执行动作
episode_reward += reward # 收集回合奖励
if train:
agent.learn(observation, action, reward, done) # 学习
if done:
break
observation = next_observation
return episode_reward # 返回回合总奖励
env.seed(0) # 设置随机数种子,只是为了让结果可以精确复现,一般情况下可删去
# episode_reward = [play_montecarlo(env,agent) for _ in range(100)]
episode_reward = play_montecarlo(env, agent, render=True)
print('回合奖励 = {}'.format(episode_reward))
env.close()

















 1337
1337

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











