







spark核心编程
-
查缺:
java中 .flush() 这个方法是清除缓存
在传对象到另一个电脑的时候要序列化 只需要类继承Serializable即可
Scala中 option表示防止空指针异常,这个数据可有可无
项目中的相对路径是以该项目根目录文件为标准,即为文件总目录
slices 切片 切片数量
-
单词补漏
- socket: 插座,发送端,可以理解为需求的客户端,发送请求
- NotSerializableExcenption 序列化异常
- excutor 执行端 可以理解为服务器
io操作和rdd原理之间关系—>装饰者设计模式
-
io操作图解
-
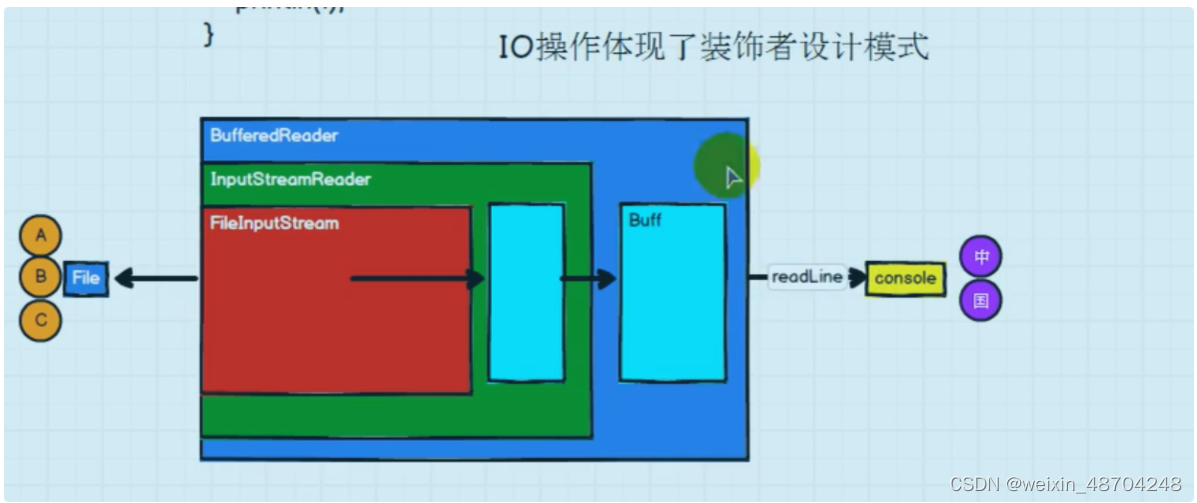
以sparkrdd wordcount 案例为对比
什么是RDD
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是 Spark 中最基本的数据处理模型。代码中是一个抽象类,它代表一个弹性的、不可变、可分区、里面的元素可并行计算的集合。
-
RDD操作图解
-
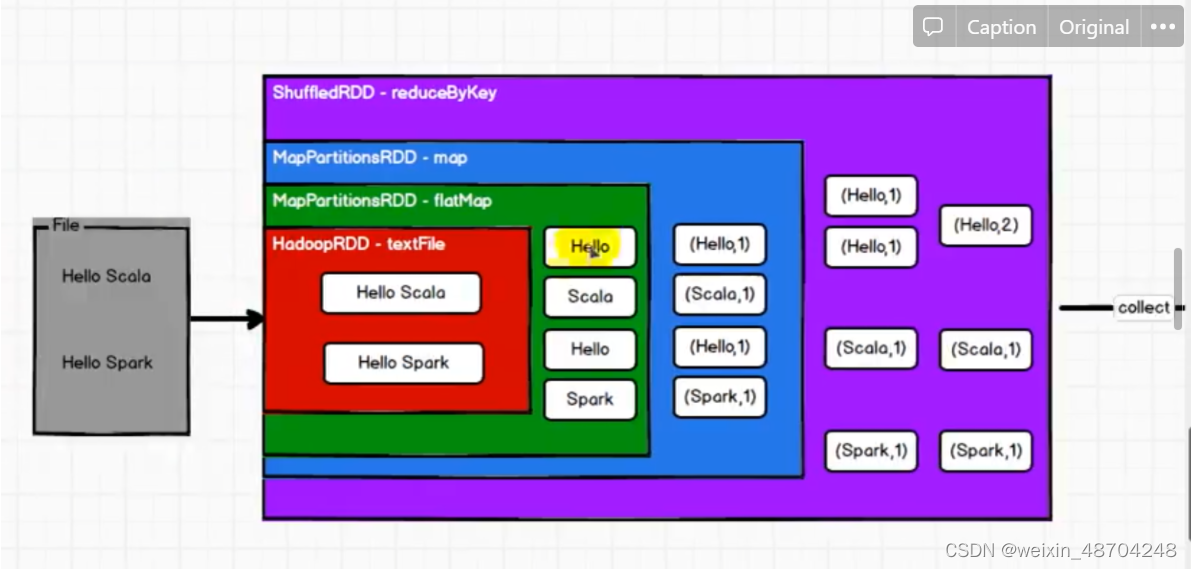
RDD 数据处理方式类似于io流,也有装饰者设计模式
RDD的数据只有在collect方法时,才会真正的执行逻辑操作
RDD是不保存数据的,保存的是数据逻辑,而io保存部分数据
-
RDD核心属性
-
分区列

-
-
RDD创建
-
RDD内存创建,和分区规则,数值的去向
-
ps: seq为需要计算的数据
// 将内存中数据放入创建RDD对象框架中,这两个方法是一样的,makeRDD底层调用context.parallelize(seq)方法 val value1:RDD[Int] = context.parallelize(seq) val value: RDD[Int] = context.makeRDD(seq) -
RDD内存创建分区规则,数值的去向
// RDD的并行度 & 分区 // makeRDD方法可以传递第二个参数,这个参数表示分区的数量 // 第二个参数可以不传递的,那么makeRDD方法会使用默认值 : defaultParallelism(默认并行度) // scheduler.conf.getInt("spark.default.parallelism", totalCores) // spark在默认情况下,从配置对象中获取配置参数:spark.default.parallelism // 如果获取不到,那么使用totalCores属性,这个属性取值为当前运行环境的最大可用核数 //val rdd = sc.makeRDD(List(1,2,3,4),2)
-
-
文件创建,和分区规则,数值的去向
-
文件创建
// 在文件中创建,相对路径就是从项目文件开始 // 既可以指向一个目录名字则计算一个目录下的多个文件,又可以计算单个文件 // 也可以用通配符 如1*.txt 条件下的文件 val value: RDD[String] = context.textFile("data") // 可以显示路径和数据两个值 // textFile : 以行为单位来读取数据,读取的数据都是字符串 // wholeTextFiles : 以文件为单位读取数据 // 读取的结果表示为元组,第一个元素表示文件路径,第二个元素表示文件内容 val rdd = sc.wholeTextFiles("datas") -
分区规则
//TODO创建RDD // textFile可以将文件作为数据处理的数据源,默认也可以设定分区。 // minPartitions : 最小分区数量 // math.min(defaultParallelism, 2) //val rdd = sc.textFile("datas/1.txt") // 如果不想使用默认的分区数量,可以通过第二个参数指定分区数 // Spark读取文件,底层其实使用的就是Hadoop的读取方式 // 分区数量的计算方式: 7是字节 字节也包括回车符号 2是分区数 // totalSize = 7 // 求一行字节数 // goalSize = 7 / 2 = 3(byte) // 7 / 3 = 2...1 (1.1) + 1 = 3(分区) // val rdd = sc.textFile("datas/1.txt", 2) -
分区后数值的分配
//TODO创建RDD //TODO数据分区的分配 // 1. 数据以行为单位进行读取 // spark读取文件,采用的是hadoop的方式读取,所以一行一行读取,和字节数没有关系 // 2. 数据读取时以偏移量为单位,偏移量不会被重复读取 @@表示回车符,一行三个字节! // ps :以第一行为多少字节为偏移量范围单位 如一行三个字节则 分区0 为 [0,3]范围的字节 /* 1@@ => 012 2@@ => 345 3 => 6 */ // 3. 数据分区的偏移量范围的计算 从0开始,范围都是闭合 // 0 => [0, 3] => 12 // 1 => [3, 6] => 3 // 2 => [6, 7] => // 【1,2】,【3】,【】 val rdd = sc.textFile("datas/1.txt", 2) -
简单案例
//总数为14个字节 // 14byte / 2 = 7byte // 14 / 7 = 2(分区) /* 1234567@@ => 012345678 89@@ => 9101112 0 => 13 [0, 7] => 1234567 [7, 14] => 890 */ // 如果数据源为多个文件,那么计算分区时以文件为单位进行分区 val rdd = sc.textFile("datas/word.txt", 2)
-
-
-
RDD算子
-
rdd的计算,在一个分区内,map算子顺序是计算一个数据完后再计算下一个数据,分区内数据的执行是有序的,例如map
-
不同分区之间的执行是无序的
-
mapPartitions() 以分区为一个缓存区,即有一个分区执行一次而不是map算子每个数据执行一次,mapPartitions()里面参数是迭代器
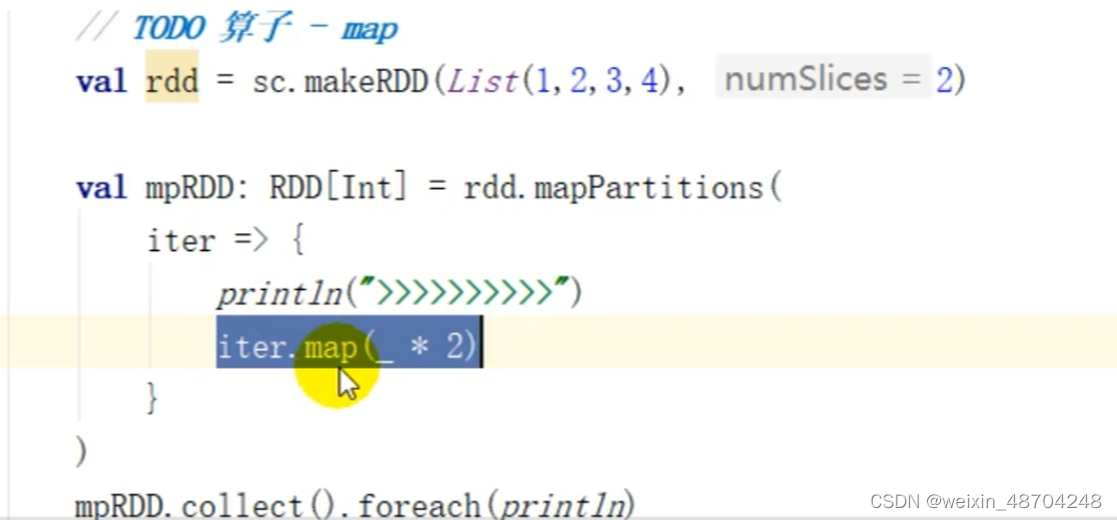
<aside> 💡 但是这个mapPartitions()算子完成后是不会释放内存的,所以在内存小,数据较大的情况下,很容易内存溢出
</aside>
-
mapPartitionsWithIndex(),这里有两个参数,第一个为分区下标,第二个为迭代器Nil.interactor这个Nil是空值的意思,有许多扩展TraversableOnce[U]这个为课迭代集合 -
glom()将RDD个体组成数组,变为数组后就有许多的方法例如就最大值 max//TODO算子 - glom val rdd : RDD[Int] = sc.makeRDD(List(1,2,3,4), 2) val glomRDD: RDD[Array[Int]] = rdd.glom() glomRDD.collect().foreach(data=> println(data.mkString(","))) -
groupBy()参数是一个判断函数,此参数函数需要参数是根据需求填类型,返回值是分组判断,记得常用的是匿名参数Ps : 分组和分区之间没有必要关系
// groupBy会将数据源中的每一个数据进行分组判断,根据返回的分组key进行分组 // 相同的key值的数据会放置在一个组中 def groupFunction(num:Int) = { num % 2 } val groupRDD: RDD[(Int, Iterable[Int])] = rdd.groupBy(groupFunction) map算子也能大括号运用 timeRDD.map{ case ( hour, iter ) => { (hour, iter.size) } }.collect.foreach(println)<aside> 💡
groupBy()会将数据打乱,重新组合,这和操作被称为shuffle</aside>
-
filter()算子,过滤内容参数是一个判断函数,如果是真则返回,是假就不返回rdd.filter( line => { val datas = line.split(" ") val time = datas(3) time.startsWith("17/05/2015") } ).collect().foreach(println) -
simple()算子,英文名是样品,算子有三个参数-
代码例子
// sample算子需要传递三个参数 // 1. 第一个参数表示,抽取数据后是否将数据返回 true(放回),false(丢弃) // 2. 第二个参数表示, // 如果抽取不放回的场合:数据源中每条数据被抽取的概率!!,基准值的概念 // 如果抽取放回的场合:表示数据源中的每条数据被抽取的可能次数 // 可能大于这个次数也可能小于这个次数 // 3. 第三个参数表示,抽取数据时随机算法的种子,ps:就是随即一次后会产生一个种子数,如果使用了当前种子数,那随机数将不变 // 如果不传递第三个参数,那么使用的是当前系统时间 // println(rdd.sample( // false, // 0.4 // //1 // ).collect().mkString(",")) println(rdd.sample( true, 2 //1 ).collect().mkString(","))
-
-
distinct()去重算子算子去重原理和小案例
val rdd = sc.makeRDD(List(1,2,3,4,1,2,3,4)) // map(x => (x, null)).reduceByKey((x, _) => x, numPartitions).map(_._1) // (1, null),(2, null),(3, null),(4, null),(1, null),(2, null),(3, null),(4, null) // (1, null)(1, null)(1, null) // (null, null) => null // (1, null) => 1 val rdd1: RDD[Int] = rdd.distinct() rdd1.collect().foreach(println) -
coalesce:缩减分区 ,repartition()增加分区//coalesce val rdd = sc.makeRDD(List(1,2,3,4,5,6), 3) // coalesce方法默认情况下不会将分区的数据打乱重新组合 // 这种情况下的缩减分区可能会导致数据不均衡,出现数据倾斜 // 如果想要让数据均衡,可以进行shuffle处理,参数第二个为是否要shuffle //val newRDD: RDD[Int] = rdd.coalesce(2) val newRDD: RDD[Int] = rdd.coalesce(2,true) //repartition val rdd = sc.makeRDD(List(1,2,3,4,5,6), 2) // coalesce算子可以扩大分区的,但是如果不进行shuffle操作,是没有意义,不起作用。 // 所以如果想要实现扩大分区的效果,需要使用shuffle操作 // spark提供了一个简化的操作 // 缩减分区:coalesce,如果想要数据均衡,可以采用shuffle // 扩大分区:repartition, 底层代码调用的就是coalesce,而且肯定采用shuffle //val newRDD: RDD[Int] = rdd.coalesce(3, true) val newRDD: RDD[Int] = rdd.repartition(3) -
sortBy()排序,第一个参数为函数,第二个参数可以改变排序的方式,默认为升序//TODO算子 - sortBy val rdd = sc.makeRDD(List(("1", 1), ("11", 2), ("2", 3)), 2) // sortBy方法可以根据指定的规则对数据源中的数据进行排序,默认为升序,第二个参数可以改变排序的方式 // sortBy默认情况下,不会改变分区。但是中间存在shuffle操作 val newRDD = rdd.sortBy(t=>t._1.toInt, false) newRDD.collect().foreach(println) -
TODO 算子 - 双Value类型,interection()交集,union()并集,subtract()差集,zip()拉链-
双Value类型// 交集,并集和差集要求两个数据源数据类型保持一致 // 拉链操作两个数据源的类型可以不一致 val rdd1 = sc.makeRDD(List(1,2,3,4)) val rdd2 = sc.makeRDD(List(3,4,5,6)) val rdd7 = sc.makeRDD(List("3","4","5","6")) // 交集 : 【3,4】 val rdd3: RDD[Int] = rdd1.intersection(rdd2) //val rdd8 = rdd1.intersection(rdd7) println(rdd3.collect().mkString(",")) // 并集 : 【1,2,3,4,3,4,5,6】 val rdd4: RDD[Int] = rdd1.union(rdd2) println(rdd4.collect().mkString(",")) // 差集 : 【1,2】 val rdd5: RDD[Int] = rdd1.subtract(rdd2) println(rdd5.collect().mkString(",")) // 拉链 : 【1-3,2-4,3-5,4-6】 val rdd6: RDD[(Int, Int)] = rdd1.zip(rdd2) val rdd8 = rdd1.zip(rdd7) println(rdd6.collect().mkString(","))<aside> 💡 拉链zip注意事项
// Can't zip RDDs with unequal numbers of partitions: List(2, 4) // 两个数据源要求分区数量要保持一致 // Can only zip RDDs with same number of elements in each partition // 两个数据源要求分区中数据数量保持一致 val rdd1 = sc.makeRDD(List(1,2,3,4,5,6),2) val rdd2 = sc.makeRDD(List(3,4,5,6),2) val rdd6: RDD[(Int, Int)] = rdd1.zip(rdd2) println(rdd6.collect().mkString(","))</aside>
-
-
partitionBy根据指定的分区规则对数据进行重分区//TODO算子 - (Key - Value类型) val rdd = sc.makeRDD(List(1,2,3,4),2) val mapRDD:RDD[(Int, Int)] = rdd.map((_,1)) // RDD => PairRDDFunctions // 隐式转换(二次编译) // partitionBy根据指定的分区规则对数据进行重分区,首先判断是否是同个方法,然后判断分区数量 val newRDD = mapRDD.partitionBy(new HashPartitioner(2)) newRDD.partitionBy(new HashPartitioner(2)) -
reduceByKey : 相同的key的数据进行value数据的聚合操作// scala语言中一般的聚合操作都是两两聚合,spark基于scala开发的,所以它的聚合也是两两聚合 // 【1,2,3】 // 【3,3】 // 【6】 // reduceByKey中如果key的数据只有一个,是不会参与运算的。 val rdd = sc.makeRDD(List( ("a", 1), ("a", 2), ("a", 3), ("b", 4) )) val reduceRDD: RDD[(String, Int)] = rdd.reduceByKey( (x:Int, y:Int) => { println(s"x =${x}, y =${y}") x + y } ) -
groupByKey : 将数据源中的数据,相同key的数据分在一个组中,形成一个对偶元组val rdd = sc.makeRDD(List( ("a", 1), ("a", 2), ("a", 3), ("b", 4) )) // groupByKey : 将数据源中的数据,相同key的数据分在一个组中,形成一个对偶元组 // 元组中的第一个元素就是key, // 元组中的第二个元素就是相同key的value的集合 val groupRDD: RDD[(String, Iterable[Int])] = rdd.groupByKey() groupRDD.collect().foreach(println) // groupBy : 将数据源中的数据,相同key的数据分在一个组中,形成一个key,迭代器(key+value)形式 // 元组中的第一个元素就是key, // 元组中的第二个元素就是相同key的迭代器(key+value)形式 //参数一是根据元素什么值来作为key val groupRDD1: RDD[(String, Iterable[(String, Int)])] = rdd.groupBy(_._1)
-
RDD总结
- RDD特点
-
rdd是最小的执行计算单元和最小数据处理模型,有读取和分区(分开计算)操作
-
rdd计算逻辑是不可变的
-
可分区,并行计算
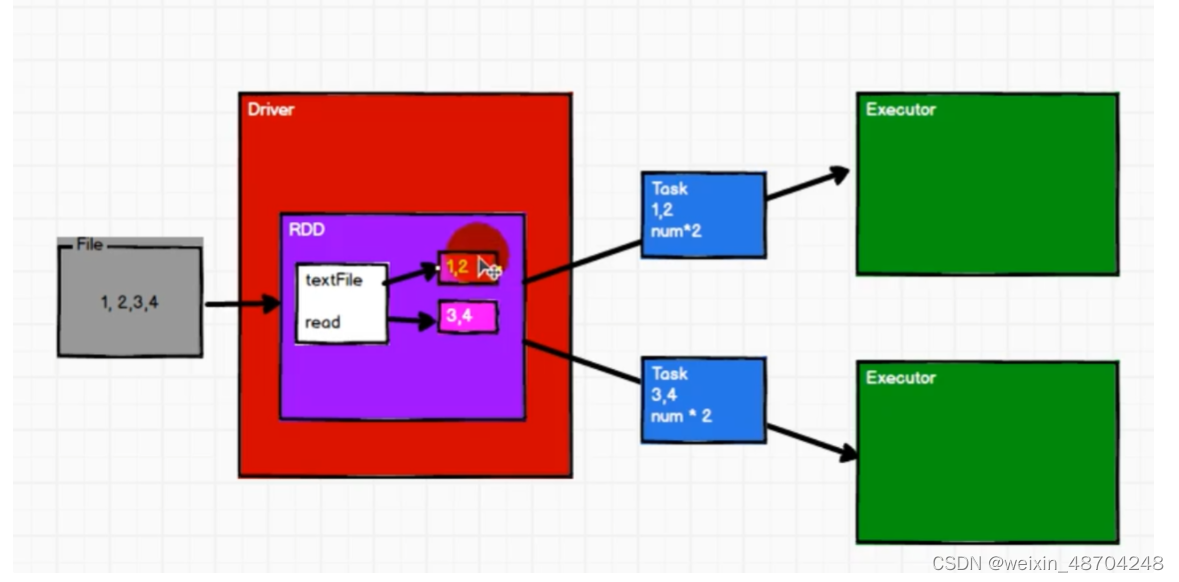
-
RDD核心属性
- 属性有以下

- 分区列表
RDD 数据结构中存在分区列表,用于执行任务时并行计算,是实现分布式计算的重要属性。

- 分区计算函数
Spark 在计算时,是使用分区函数对每一个分区进行计算

ps:就是将计算逻辑到每个分区中计算,而不是计算数据到每个分区中计算

- RDD 之间的依赖关系
RDD 是计算模型的封装,当需求中需要将多个计算模型进行组合时,就需要将多个 RDD 建立依赖关系
ps:每个分区都有就算,计算逻辑一样

- 分区器(可选)
当数据为 KV 类型数据时,可以通过设定分区器自定义数据的分区

• 首选位置(可选)计算数据时,可以根据计算节点的状态选择不同的节点位置进行计算
ps: 也就是装饰者模式,当要再加一个逻辑计算的时候,是嵌套方法
- 属性有以下
-















 249
249











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









