






其实大模型的落地并不需要有深厚的算法、或者python代码功底。如果你想了解大模型究竟是什么?如何落地使用。可以查看一下这篇文章。
下面是使用阿里云免费资源+简单脚本实现本地部署大模型。【阿里云部署通义千问14B模型-哔哩哔哩】 https://b23.tv/oVt1XNI
类似的视频在网上其实很容易找到。但很少有人介绍部署后的效果。
效果演示:
当前均采用方式本地部署了。一共使用到了 知识库 langchain-chatchat + 文本向量模型 bge-large-zh + 三款大模型 智谱AI和清华大学联合发布的ChatGLM6B、阿里云的通义千问 Qwen1.5-14b、Qwen1.5-1.8b
选择LLM对话模式、chatGLM大模型 即基于chatGLM大模型对话
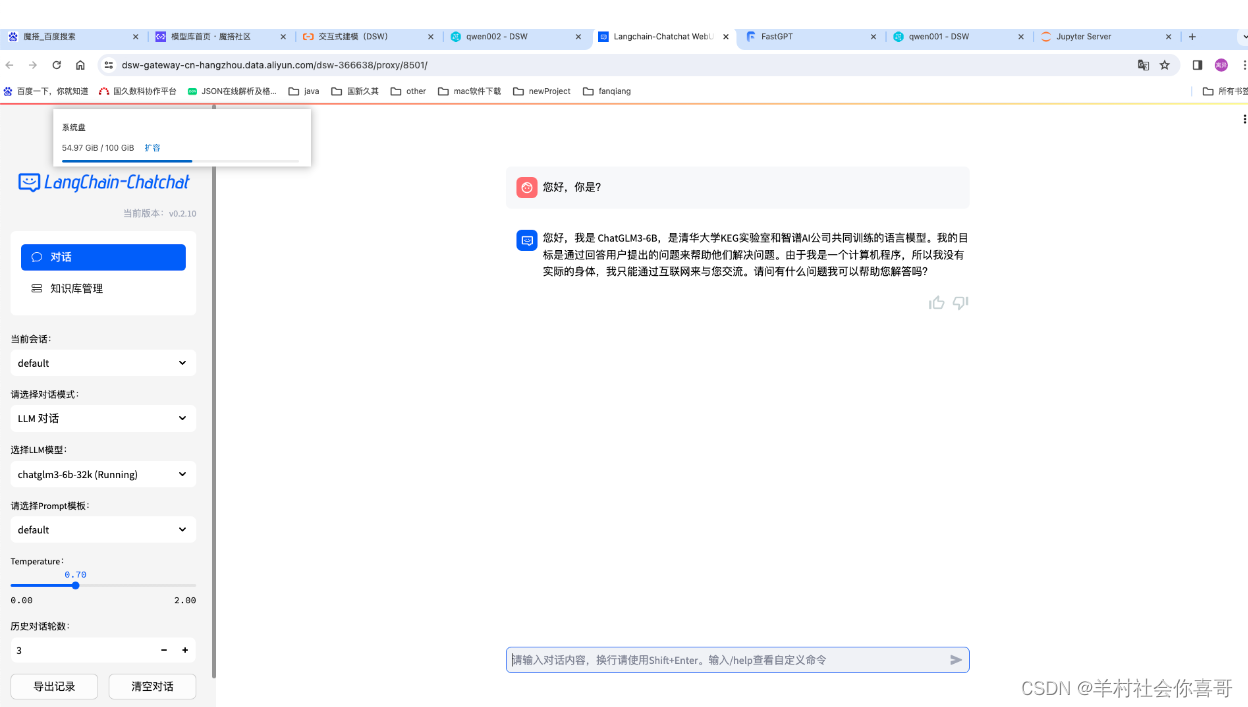
上面可以证明本地部署的chatGLM6b大模型可以回答一些问题当然,有些问题他还是不会的。
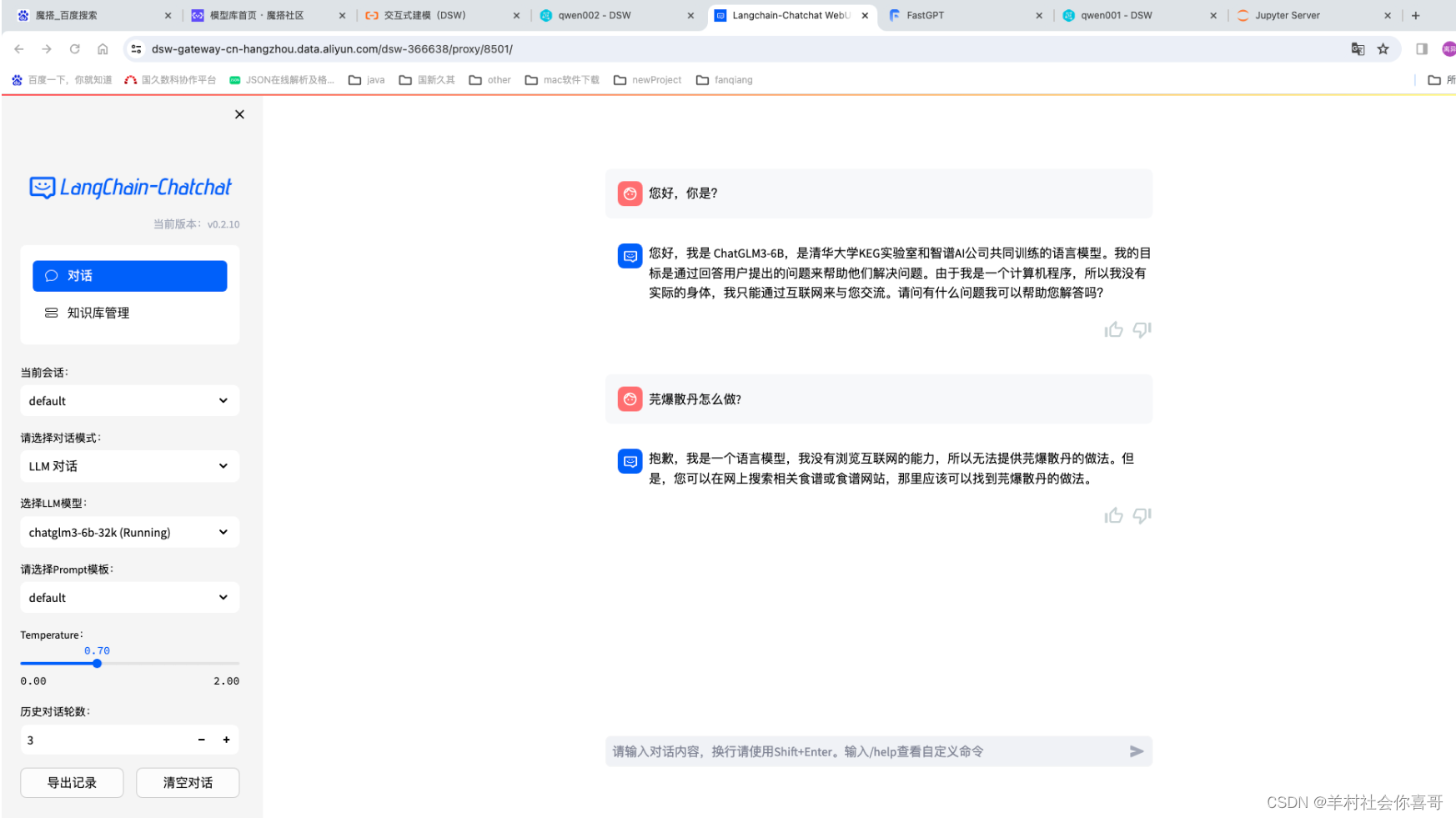
下面是切换Qwen14b模型,仍然为LLM对话模式

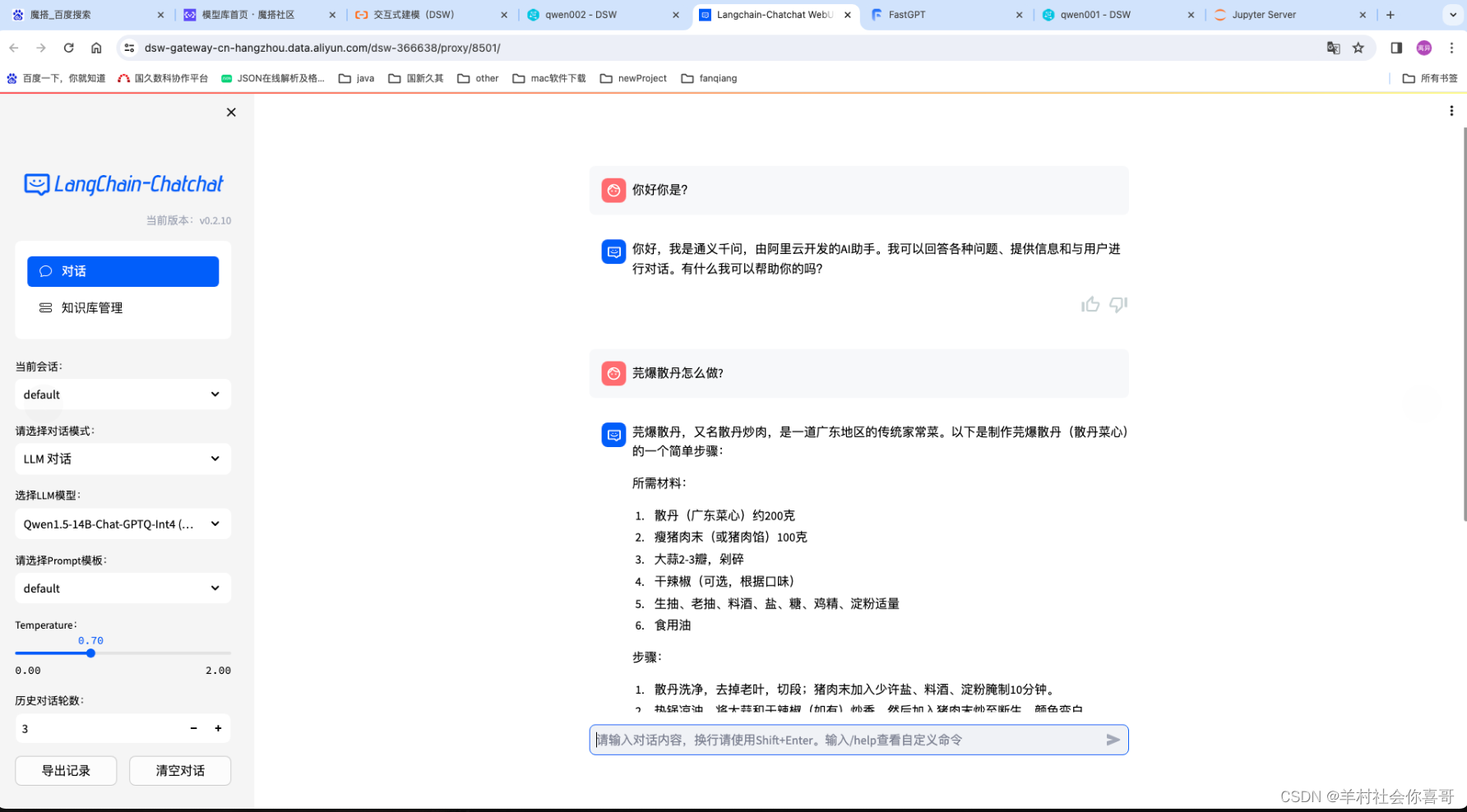
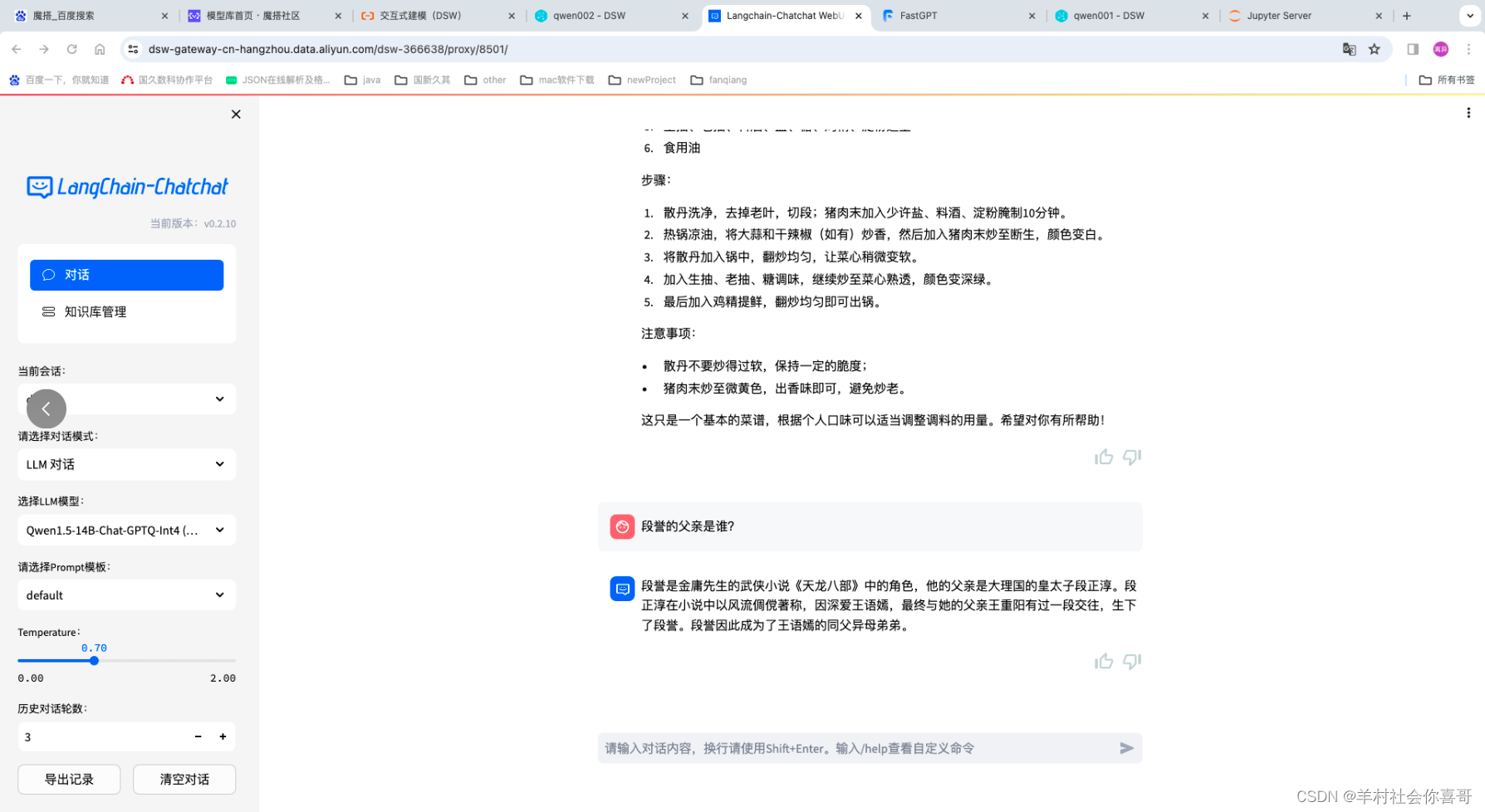
上述截图可以证明本地部署的Qwen14b在做菜方面是强于chatGLM6b的,但从影视方面chatGLM6b又强于Qwen14b。因为如果详细了解《天龙八部》的话应该知道大结局明确说了段誉的父亲是段延庆。
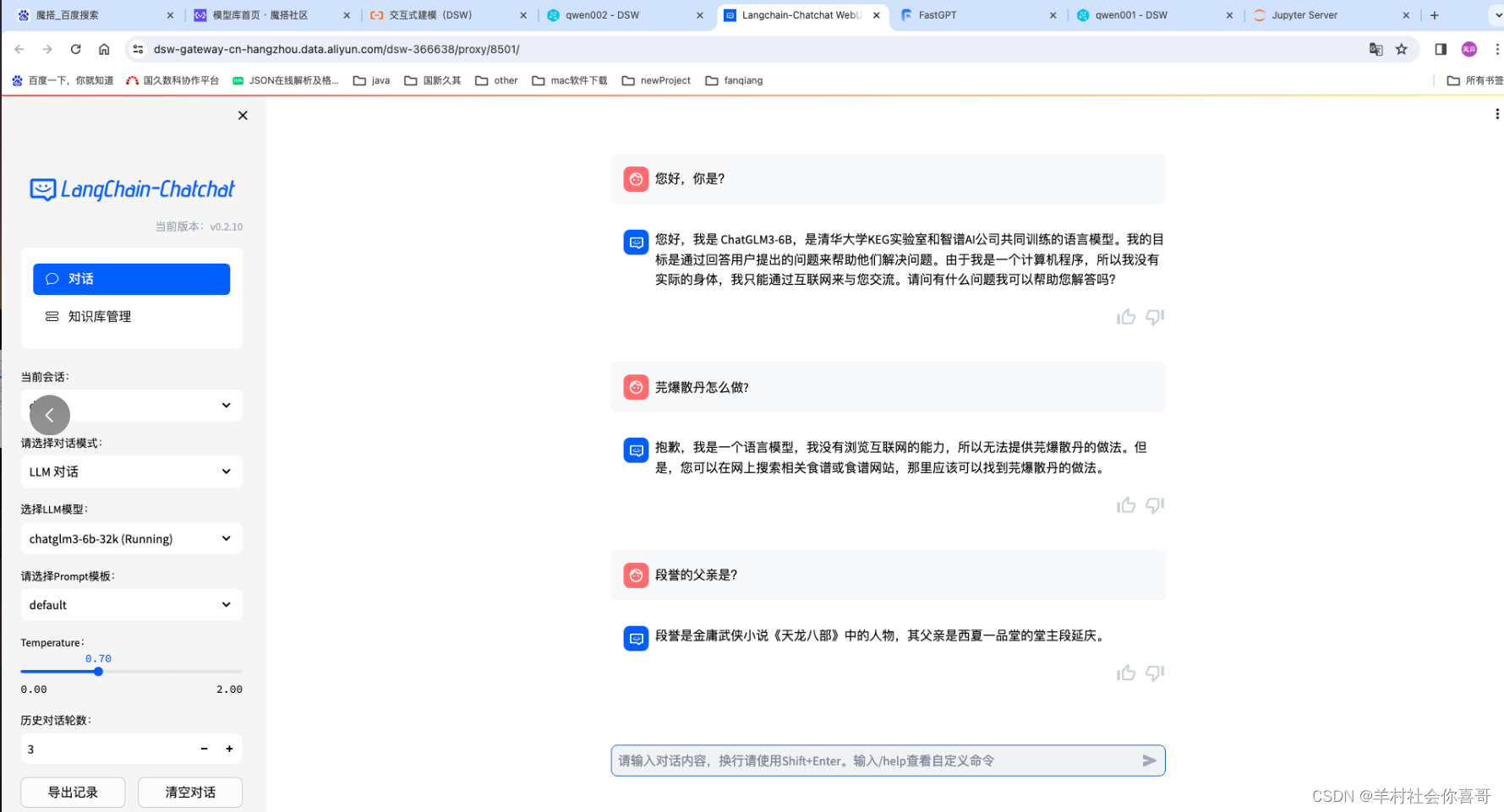
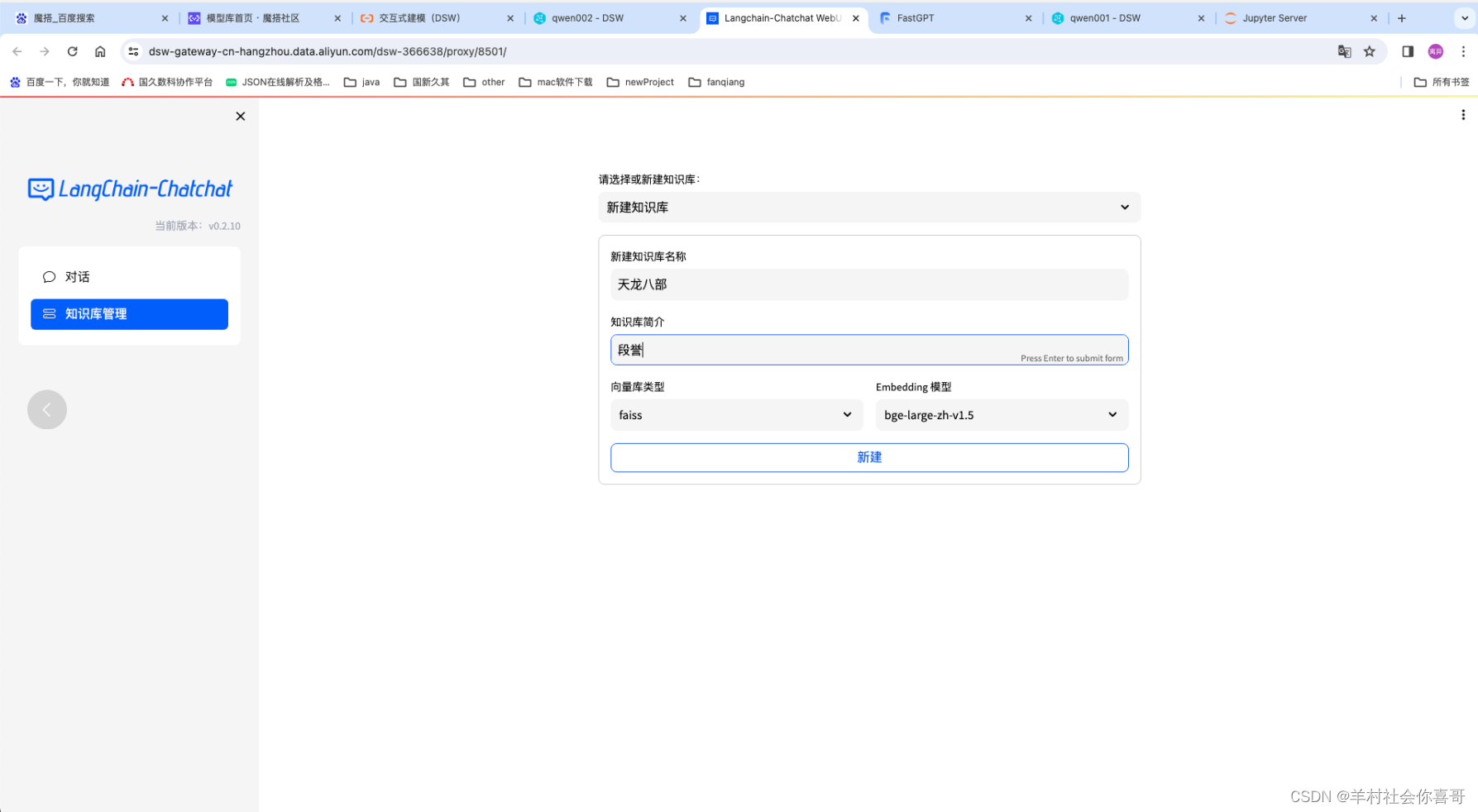
下面为Qwen14b增加知识库让他知道“段誉的父亲是段延庆”。
选择bge-large-zh文本向量模型来处理数据
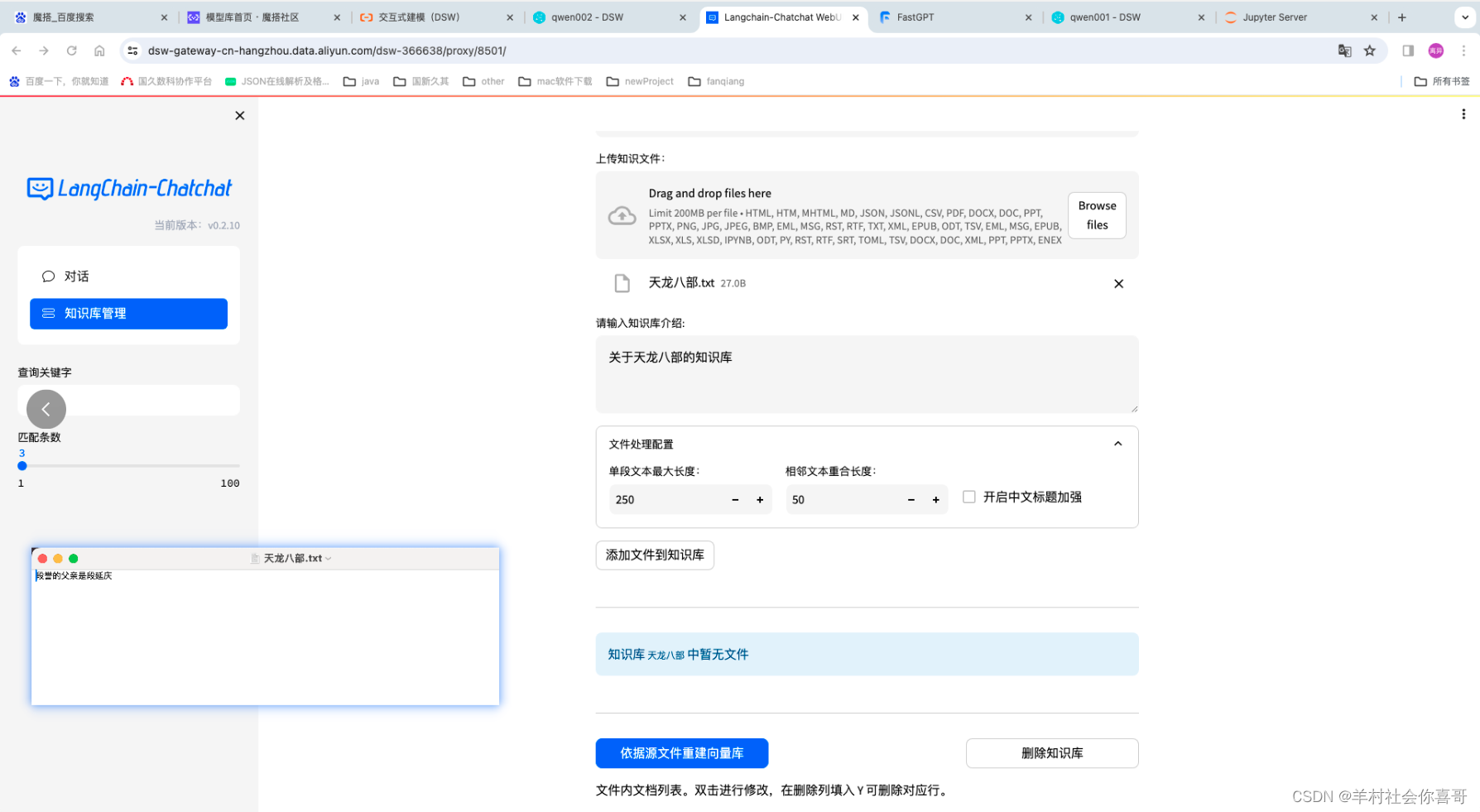
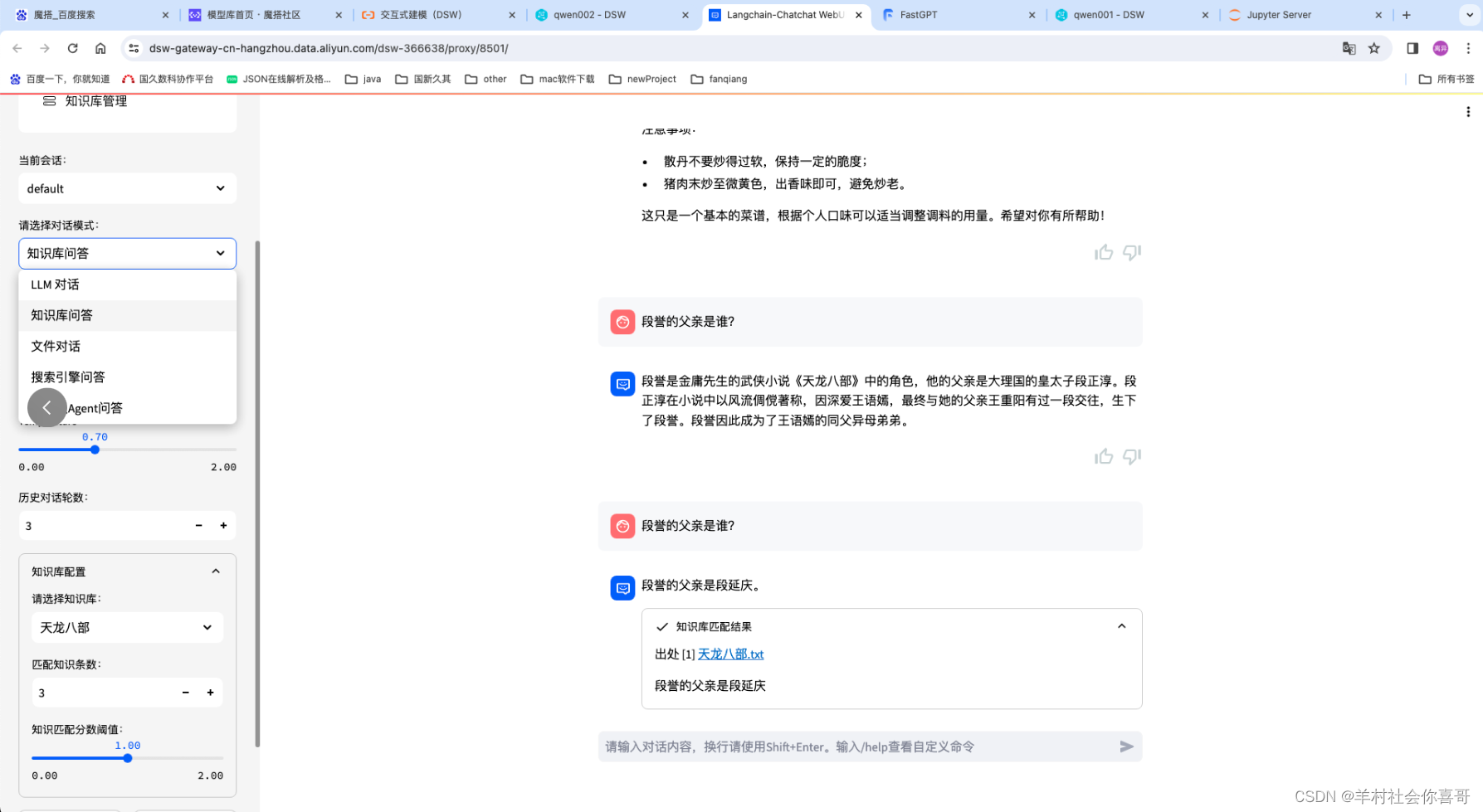
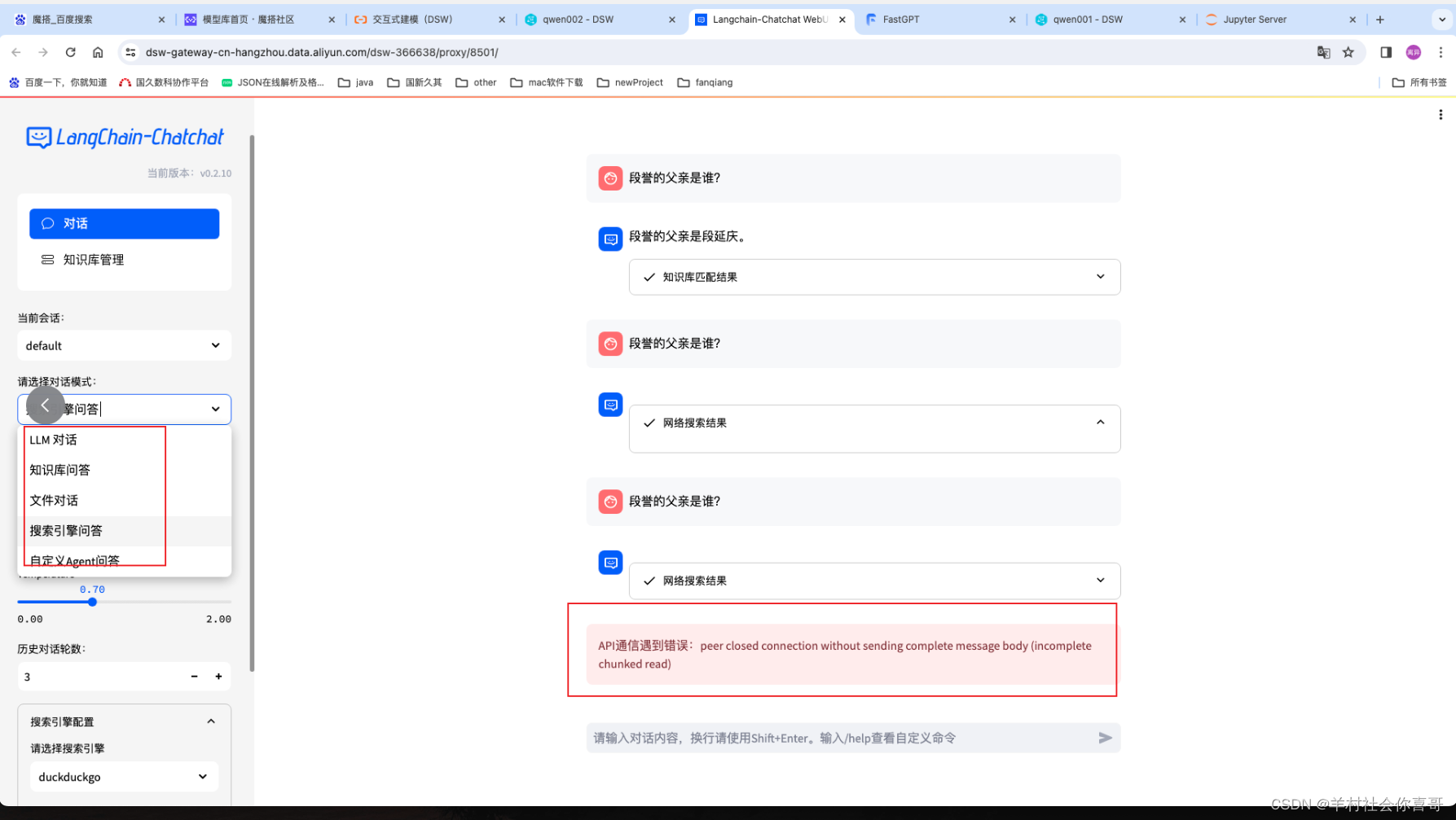
上面可以证明,qwen1.5-14B增加知识库后可以很轻松的回答出正确答案。
langchat框架页整合了fastapi方式方便其他服务去使用对话功能。
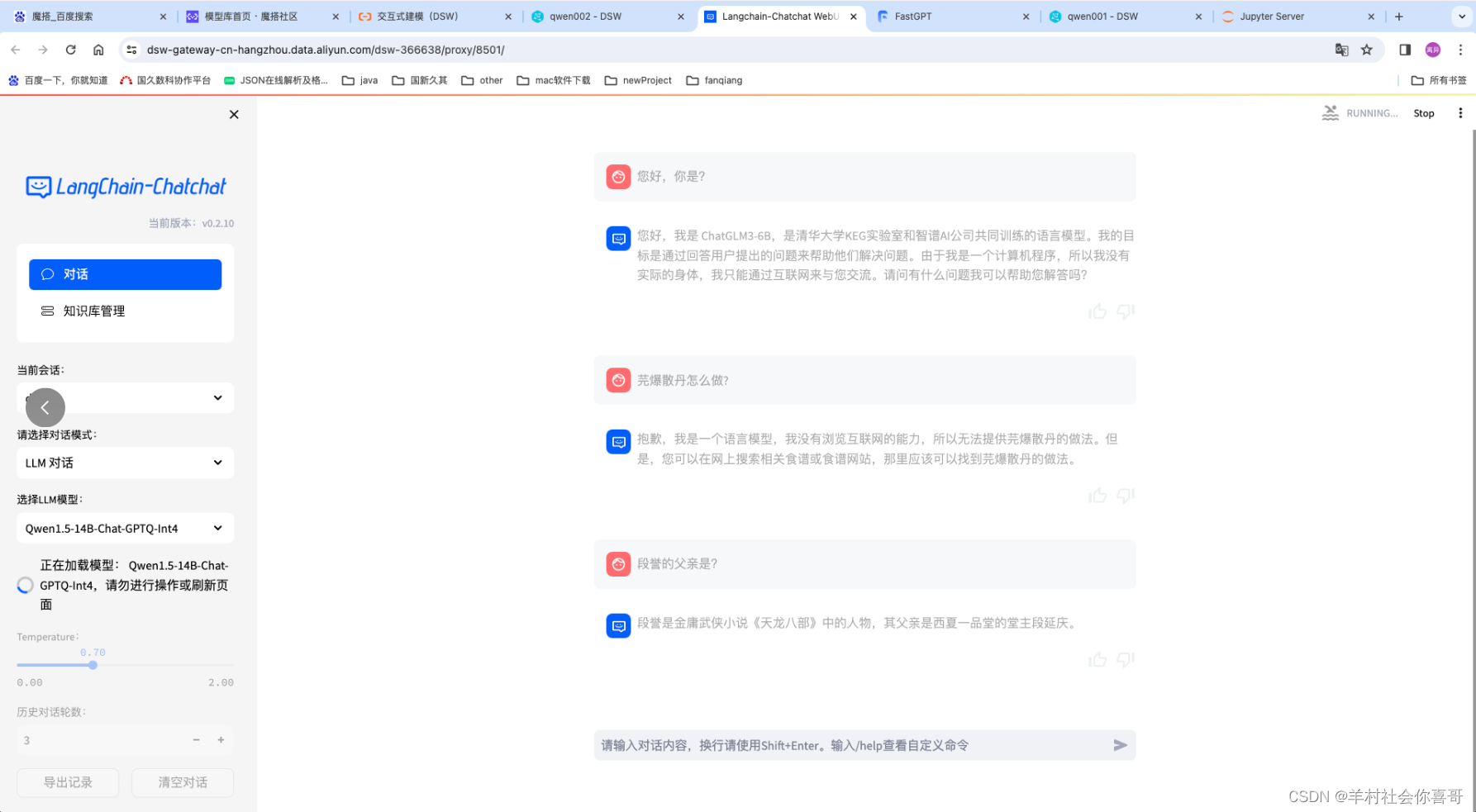
下面是切换qwen1.5-1.8b后的效果。
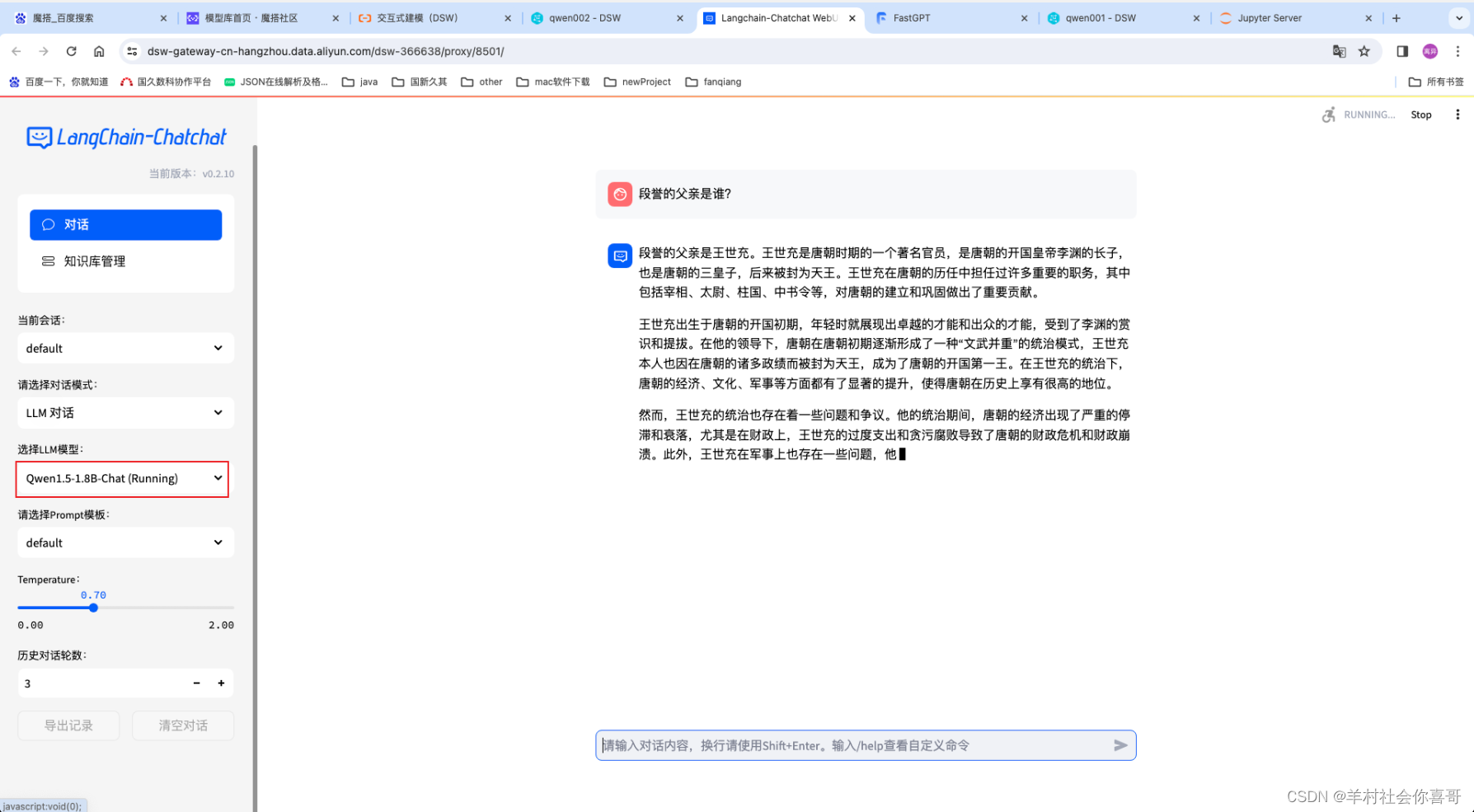
很明显qwen1.5-1.8b连姓氏都没有搞正确。
我认为大模型选择固然重要,但针对企业落地来说更重要的自己领域相关的知识。这些是其他大模型无法做到的。每个行业每个公司打造自己的垂直大模型才是后续的发展方向。
这如同企业招聘高中生和硕士生其他条件相同的情况下硕士生可能相对优秀。但例如深耕金融领域20年的高中生肯定是优于刚毕业硕士生的。
如果你跟我一样是一个非大模型的专家的话。我感觉不应该只是侧重于关注算法、预训练方面(从一个刚出生的小孩将她培养成人)这是大厂开源大模型需要做的事情。而我们需要关注的是将一个成年人培养成某个领域的精英。















 300
300











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









