







所谓公共方法指的是我们之前学到过的容器类型如列表、元组、字符串等都可以使用的一些公共函数,这里只列举了6个比较常用的方法,如len()、del、max()、min()、range()、enumerate()。
一、公共方法
| 函数 | 描述 |
| len() | 统计容器中数据个数 |
| del或del() | 删除 |
| max() | 返回容器中元素最大值 |
| min() | 返回容器中元素最小值 |
| range(start, end, step) | 生成从start到end的数字,步长为step,供for循环使用 |
| enumerate() | 函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在for循环当中 |
二、len()
含义:统计容器中数据个数
语法:len(序列)
代码体验:
# 字符串
str1 = 'abcd'
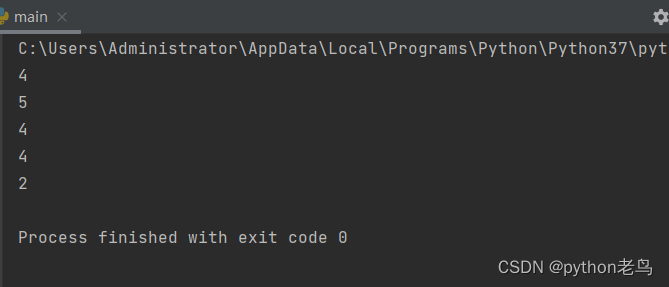
print(len(str1)) # 4
# 列表
list1 = [1, 2, 3, 4, 5]
print(len(list1)) # 5
# 元组
tuple1 = (10, 20, 30, 40)
print(len(tuple1)) # 4
# 集合
set1 = {10, 20, 30, 40}
print(len(set1)) # 4
# 字典
dict1 = {'name': 'Python自学网', 'age': 30}
print(len(dict1)) # 2执行结果如图:
三、del或del()
含义:删除整个目标或删除某个数据
语法: del 目标 或 del(目标)
代码体验:
# 字符串
str1 = 'abcd'
# 列表
list1 = [1, 2, 3, 4, 5]
# 元组
tuple1 = (10, 20, 30, 40)
# 集合
set1 = {10, 20, 30, 40}
# 字典
dict1 = {'name': 'Python自学网', 'age': 30}
# 删除整个目标
# del str1
print(str1) # NameError: name 'str1' is not defined
# del(list1)
print(list1) # NameError: name 'list1' is not defined
# del(set1)
print(set1) # NameError: name 'set1' is not defined
# 删除某个数据
del(list1[2])
print(list1) # [1, 2, 4, 5]
del dict1['name']
print(dict1) # {'age': 30}四、最大值和最小值
max():返回容器中元素最大值
min():返回容器中元素最小值
语法: max(目标) 、 min(目标)
代码体验:
str1 = 'abcd'
list1 = [1, 2, 3, 4, 5]
# max(): 最大值
print(max(str1)) # d
print(max(list1)) # 5
# min():最小值
print(min(str1)) # a
print(min(list1)) # 1五、range()
含义:生成从start到end的数字,步长为step的可迭代对象,供for循环使用
语法:range(start, end, step)
注意:
- 1、range()生产的序列不含包end数字,也就是不包含结束位
- 2、step步长可以省略,代表步长默认为1
- 3、开始start可以省略,代表从0开始
代码体验:
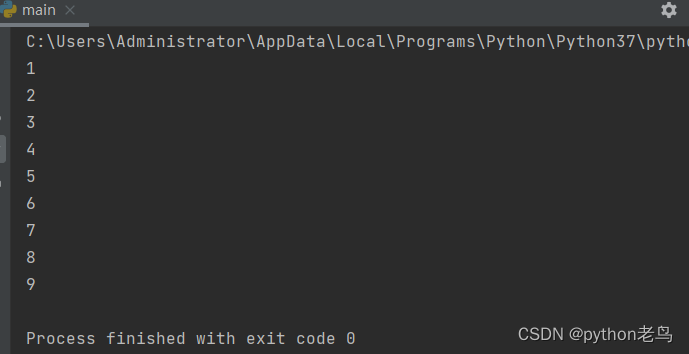
for i in range(1, 10, 1):
print(i)
# 1 2 3 4 5 6 7 8 9
for i range(1, 10):
print(i)
# 1 2 3 4 5 6 7 8 9执行结果如图:
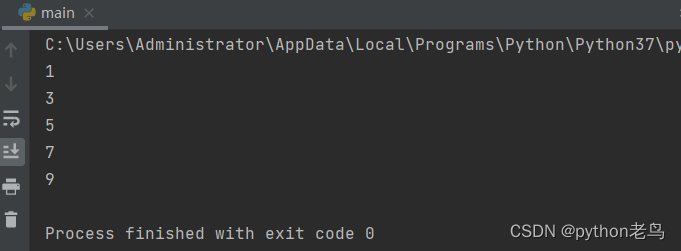
代码体验:
for i in range(1, 10, 2):
print(i)
# 1 3 5 7 9执行结果如图:
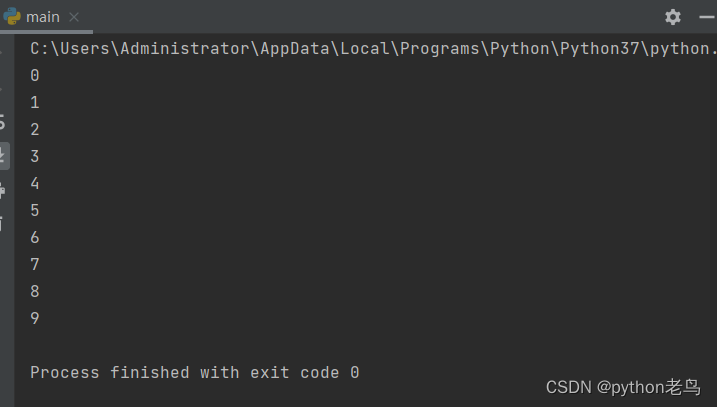
代码体验:
for i in range(10):
print(i)
# 0 1 2 3 4 5 6 7 8 9执行结果如图:
六、enumerate()
含义:函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在for循环当中
语法:enumerate(可遍历对象, start=0)
注意:
- 1、strat参数用来设置遍历数据的下标的起始值,默认为0
- 2、返回结果是元组,元组第一个数据是原迭代对象的数据对应的下标,元组第二个数据是原迭代对象的数据
代码体验:
for i in enumerate(list1):
print(i)
# 返回结果是元组,元组第一个数据是原迭代对象的数据对应的下标,元组第二个数据是原迭代对象的数据执行结果如图:
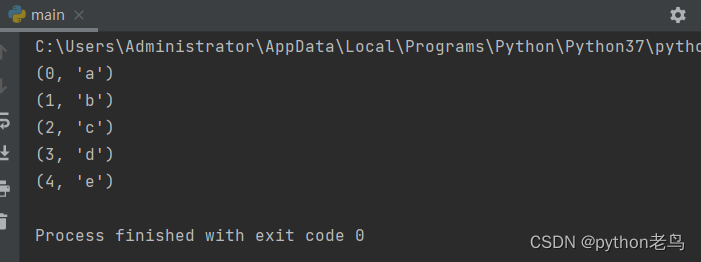
代码体验:
for i in enumerate(list1, start=1):
print(i)执行结果如图:
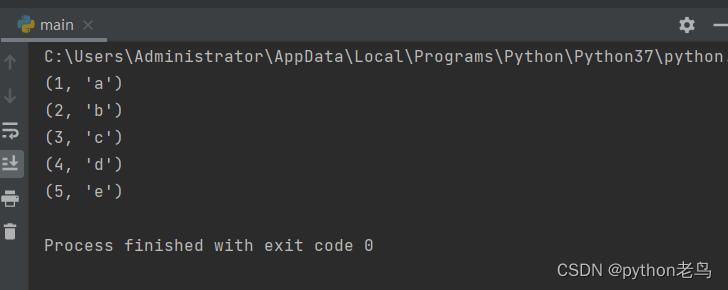
文章借鉴来源:Python自学网
















 1055
1055











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











