






 本文介绍了如何在Python环境下使用TensorFlow2.x实现深度强化学习,特别是DQN算法,应用于微能源网的能源管理与优化。作者探讨了提升DQN性能的技术如经验回放和冻结参数,并展示了其在解决可再生能源管理问题上的创新性。对比实验显示了深度强化学习的优越性及其泛化能力。
本文介绍了如何在Python环境下使用TensorFlow2.x实现深度强化学习,特别是DQN算法,应用于微能源网的能源管理与优化。作者探讨了提升DQN性能的技术如经验回放和冻结参数,并展示了其在解决可再生能源管理问题上的创新性。对比实验显示了深度强化学习的优越性及其泛化能力。
适用平台:python环境tensorflow 2.x
程序深入阐述强化学习的框架、Q学习算法和深度Q网络(DQN)算法的基础理论的基础上,分析了提升DQN性能的经验回放机制与冻结参数机制,并以经济性为目标完成了微能源网能量管理与优化。程序算例丰富、注释清晰、干货满满,可扩展性和创新性很高!下面对文章和程序做简要介绍!

程序创新点:
程序提出一种基于深度强化学习(deep reinforcement learning,DRL)的微能源网能量管理与优化方法。该方法使用深度Q网络(deep Q network,DQN)对预测负荷、风/光等可再生能源功率输出和分时电价等环境信息进行学习,通过习得的策略集对微能源网进行能量管理,是一种模型无关基于价值的智能算法。
主要工作:
程序以微能源网为对象,建立了基于能源总线模型的微能源网系统,提出利用深度强化学习算法对微能源网进行能量管理与优化策略研究。面向微能源网系统,采用经历回放机制和冻结网络参数机制提升深度强化学习算法的性能,并通过深度神经网络储存策略集解决传统强化学习的维数灾难,实现对微能源网的能量管理与优化,有效解决了具有随机性和间歇性的面向可再生能源的微能源网运行优化所面临的建模困难、传统算法运行收敛较慢难以满足实时优化要求以及系统开放性等问题。更进一步,在验证继承已训练策略集的强化学习算法的优越性的基础上,对比了在离线数据集上训练完成的深度强化学习算法与启发式算法(以遗传算法为例)对同一新负荷场景的优化结果与计算时间,证明了深度强化学习的可行性与优越性。对比证明了深度强化学习不仅可以实现对单一场景进行能量管理与策略优化,具备优秀的泛化能力,实现对新场景能量管理的快速收敛并获得趋优解。
深度强化学习简介
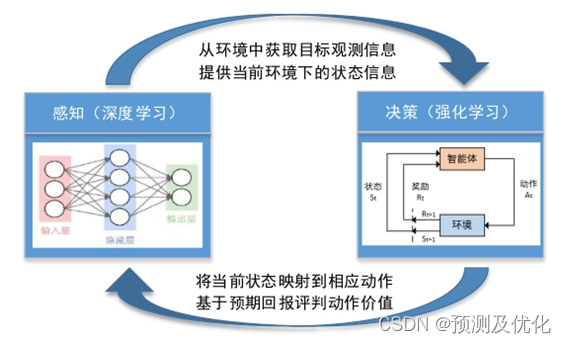
深度强化学习(Deep Reinforcement Learning,DRL)是强化学习(Reinforcement Learning,RL)与深度学习技术的结合,旨在通过深度神经网络来解决复杂的决策问题。强化学习是一种机器学习范式,其中智能体通过与环境的交互学习,以达到最大化累积奖励的目标。
以下是深度强化学习的一些关键概念和方法:
神经网络:DRL使用深度神经网络来表示值函数、策略或模型。这些网络可以是卷积神经网络(CNN)用于处理图像输入,也可以是循环神经网络(RNN)用于处理序列数据。
值函数:值函数衡量在给定状态下采取特定动作的累积奖励的期望值。深度强化学习中常使用深度Q网络(DQN)来学习值函数。
策略梯度:策略梯度方法直接学习策略,即从状态到动作的映射。这些方法使用梯度上升来最大化预期奖励。
Actor-Critic:Actor-Critic算法结合了值函数估计(Critic)和策略改进(Actor),通过使用值函数来指导策略的训练。这样可以加速学习过程。
深度确定性策略梯度(DDPG):DDPG是一种用于连续动作空间的深度强化学习方法,结合了策略梯度和值函数的思想。
Proximal Policy Optimization(PPO):PPO是一种常用的策略优化算法,通过在每次更新中保持策略的相对不变性来提高训练的稳定性。
强化学习环境:OpenAI Gym等强化学习环境提供了标准化的测试基准,让研究者和开发者能够在各种任务上评估他们的强化学习算法。
深度Q网络:
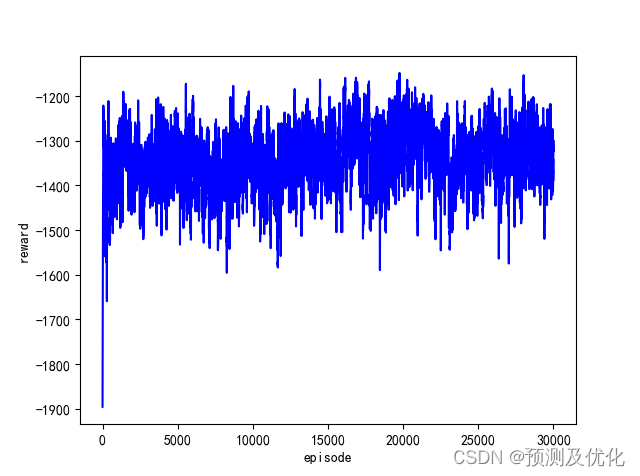
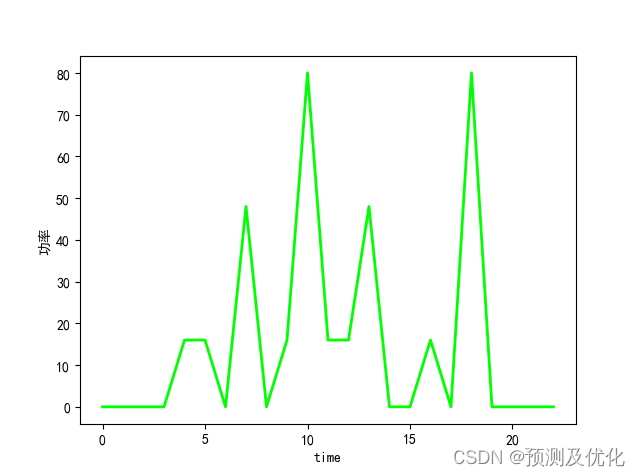
程序结果:
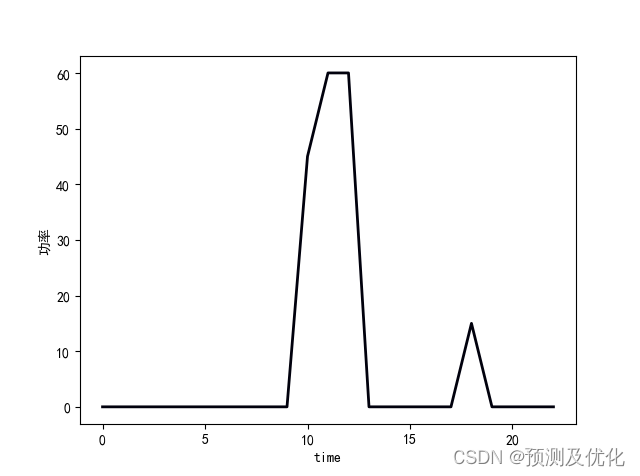
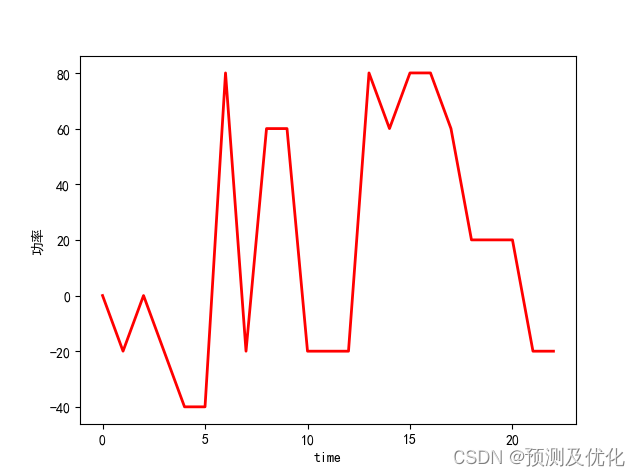
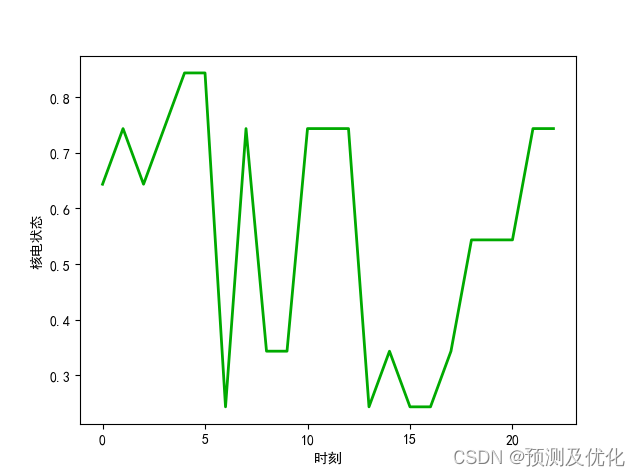
部分程序:
def policy_train(env, agent, episode_num):
reward_sum_line = []
running_reward = 0
flag = True
P_MT_action_list = []
P_g_action_list = []
P_B_action_list = []
H_D_state_list = []
for i in range(episode_num):
observation = env.reset(np.random.uniform(0.2, 0.9))
reward_episode = []
while True:
action = agent.choose_action(np.array(observation))
observation_, reward, done = env.step(action)
agent.store_transition(observation, action, reward, observation_)
reward_episode.append(reward)
observation = observation_
if i == episode_num - 1:
action = env.action_space[action]
P_MT_action_list.append(env.P_MT_action[action[0]])
P_g_action_list.append(env.P_g_action[action[1]])
P_B_action_list.append(env.P_B_action[action[2]])
H_D_state_list.append(observation[6])
部分内容源自网络,侵权联系删除!
欢迎感兴趣的小伙伴关注并获取完整版代码,小编会不定期更新高质量的学习资料、文章和程序代码,为您的科研加油助力!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









