






适用平台:Matlab2021及以上
你肯定见过这些顶级期刊在做论文中的特征可视化工具:t-SNE;出来的图都非常好看,能够给专家及读者留下非常好的印象,这是科研的必备工具!尽快拿下!
t-SNE的作用:当我们处理高维数据时,很难直观地理解数据之间的关系。t-SNE的目标是帮助我们在一个更低维度的空间中(通常是2D或3D)对数据进行可视化,同时保留数据点之间的相似性关系。通过一些数学变换,将原始信息从复杂的高维度(比如100维)变成一个简单的低维度(比如2维或3维)的样本分布图。
计算步骤:
-
t-SNE的核心思想是保持高维空间中数据点之间的相似性关系,尽量在低维空间中保持相似的关系。简单说,如果在高维空间中两个点很相似,它们在降维后的低维空间中仍然要尽量保持相似。
-
这个算法的数学原理涉及到概率分布和距离的概念。它首先计算高维空间中点与点之间的相似性,使用一个概率分布来表示这种相似性。然后,在低维空间中,它再计算点与点之间的相似性,并构建另一个概率分布。
-
t-SNE的目标是最小化这两个概率分布之间的差异,以确保高维空间中相似的点在低维空间中仍然保持相似。这个差异通常通过使用KL散度(Kullback-Leibler divergence)来衡量。
简而言之,t-SNE让我们在一个更容易理解的低维空间中看到数据点,同时尽量保持原始数据点之间的相似性关系。这使得我们可以更好地理解数据的结构和模式,特别是在局部区域内的关系。
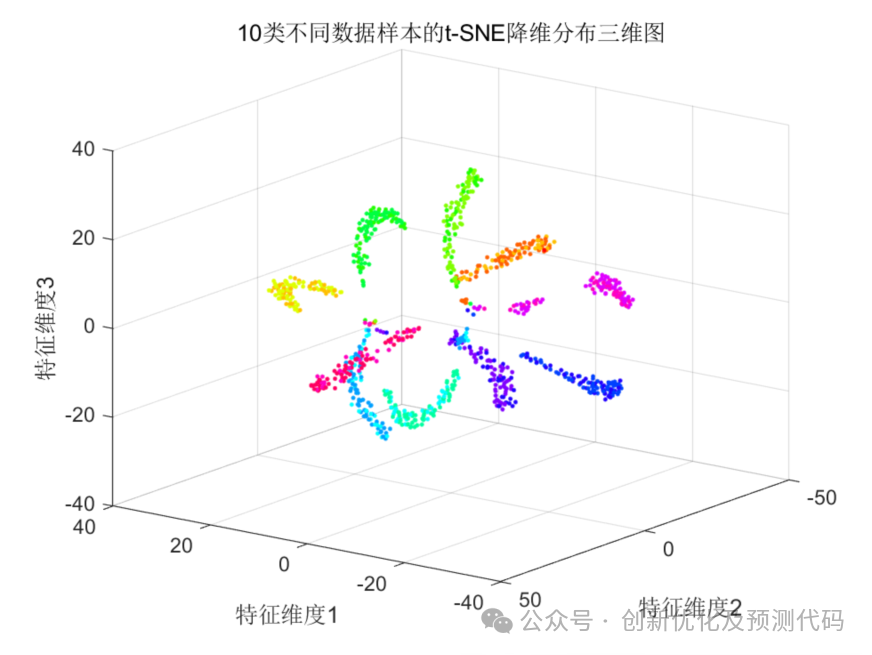
示例1:高维数据进行低维空间可视化
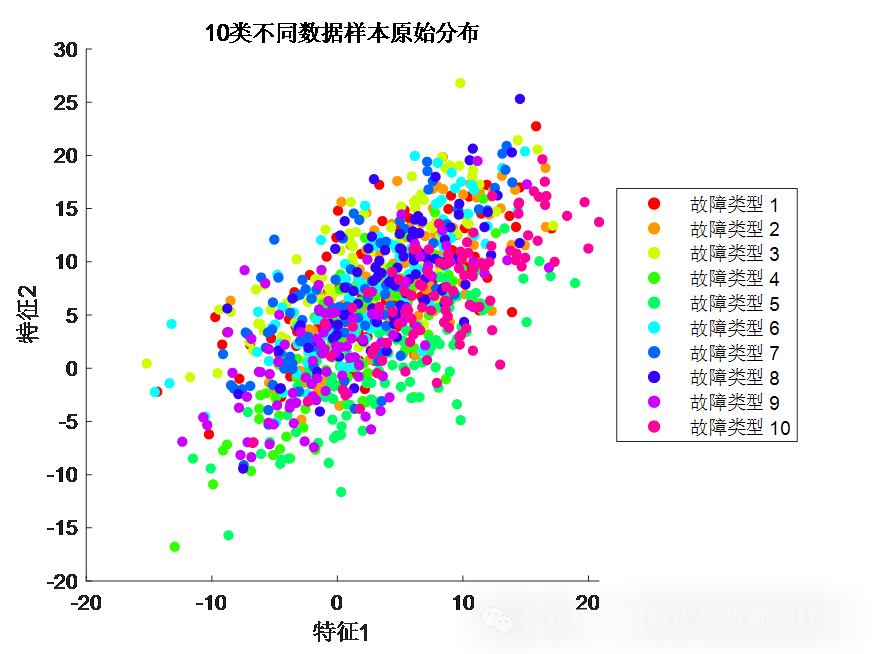
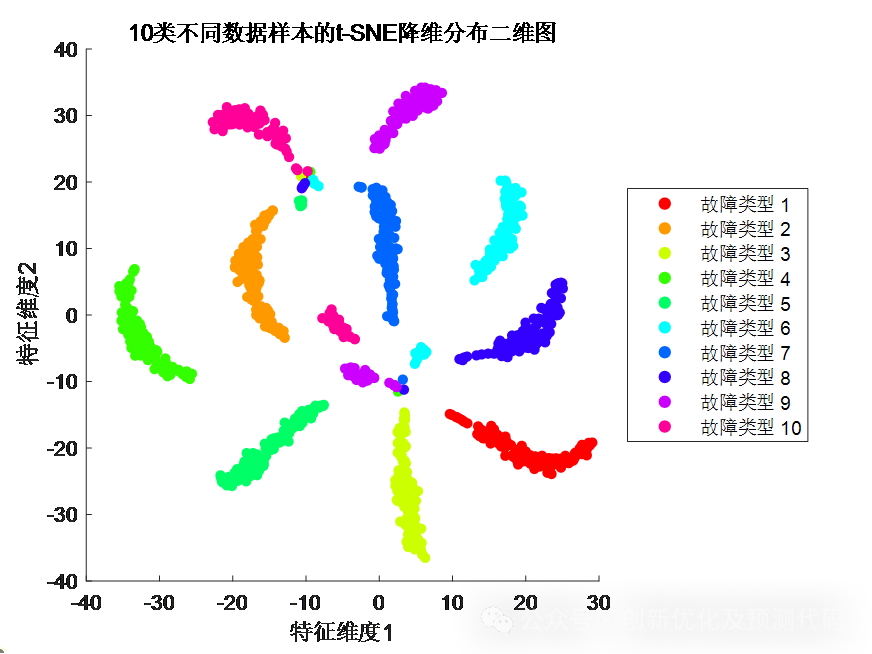
数据的特征(维度)越高,就越难以在低维空间中进行绘制,没有明显的规律性(散乱);用t-SNE降维成二维或者三维较低空间时,数据样本的分布呈现出一定的规律(聚合)。
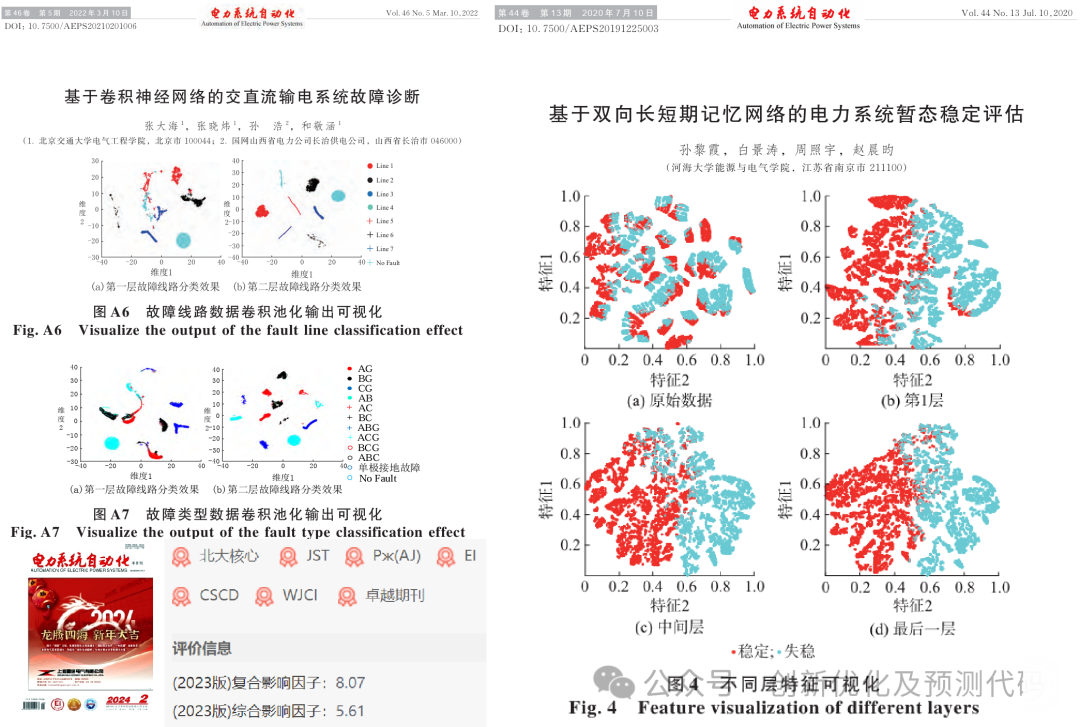
示例2:CNN-SVM卷积-支持向量机神经网络输入与输出的特征对比
观察刚输入的原始故障样本分布和模型提取特征后全连接层的样本特征分布。
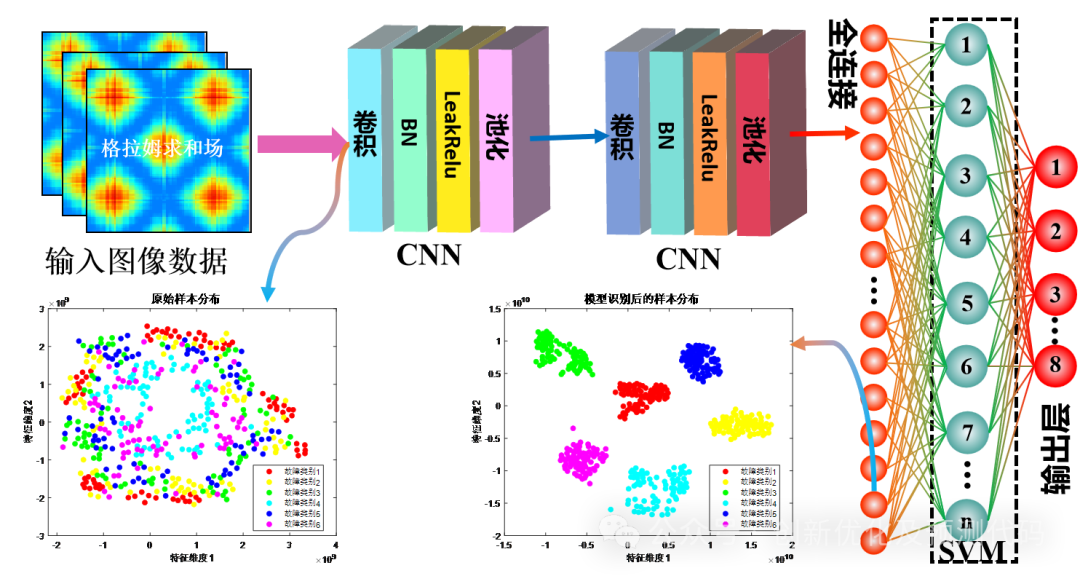
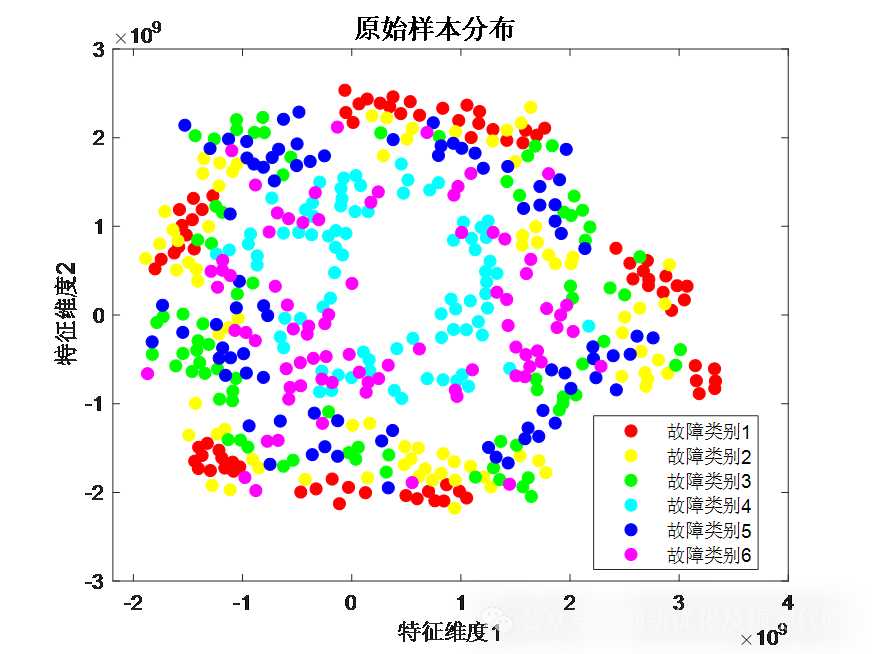
原始样本分布:(样本分散,分布混乱,无明显规律)
模型提取特征后的样本分布:(不同故障样本分离,同类故障样本聚合,特征提取成功)
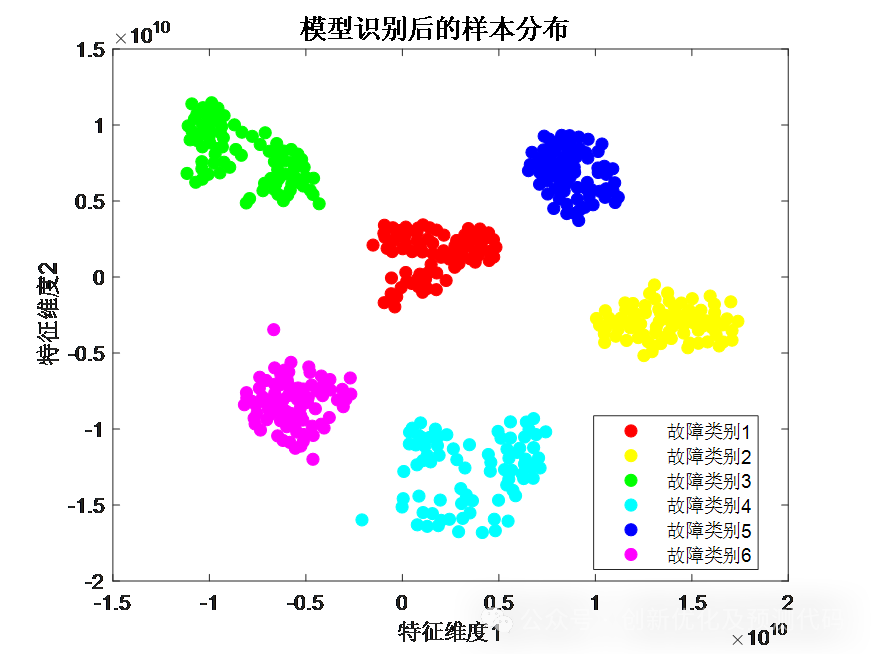
结果分析:与原始样本相比较,经特征提取后数据样本同类聚合明显,说明CNN-SVM网络模型具有很强的特征提取能力,可以实现有效的故障识别。
部分代码:
完整代码:https://mbd.pub/o/bread/ZZqamJls
%% 绘制原始数据分布散点图
figure;
hold on;
colors = hsv(num_classes);
scatter_handles = gobjects(1, num_classes);
for class_idx = 1:num_classes
start_idx = (class_idx-1)*num_samples_per_class+1;
end_idx = class_idx*num_samples_per_class;
scatter_handles(class_idx) = scatter(data(1, start_idx:end_idx), data(2, start_idx:end_idx), 25, colors(class_idx, :), 'filled');
end
hold off;
xlabel('特征1');
ylabel('特征2');
title([num2str(num_classes) '类不同数据样本原始分布']);
% 在右侧显示故障类型
legend_text = cell(1, num_classes);
for class_idx = 1:num_classes
legend_text{class_idx} = sprintf('故障类型 %d', class_idx);
end
legend(scatter_handles, legend_text, 'Location', 'eastoutside');
%% 使用 t-SNE 进行降维
tsne_data = tsne(data');
%% 绘制降维后的分布图和图例
figure;
hold on;
scatter_handles = gobjects(1, num_classes);
for class_idx = 1:num_classes
start_idx = (class_idx-1)*num_samples_per_class+1;
end_idx = class_idx*num_samples_per_class;
scatter_handles(class_idx) = scatter(tsne_data(start_idx:end_idx, 1), tsne_data(start_idx:end_idx, 2), 25, colors(class_idx, :), 'filled');
end
hold off;
xlabel('特征维度1');
ylabel('特征维度2');
title([num2str(num_classes) '类不同数据样本的t-SNE降维分布二维图']);
% 在右侧显示故障类型的图例
legend_text = cell(1, num_classes);
for class_idx = 1:num_classes
legend_text{class_idx} = sprintf('故障类型 %d', class_idx);
end
legend(scatter_handles, legend_text, 'Location', 'eastoutside');欢迎感兴趣的小伙伴通过代码上方链接或联系小编获得完整版代码哦~

















 1324
1324

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









