






说话人匿名(Speaker Anonymization)旨在隐藏说话人的身份,同时保留原始语音的自然性和独特性。说话人匿名作为一种有效的隐私保护解决方案,当前的主流匿名方案使用预训练自动说话人验证(ASV)模型中的话语级向量来表示说话人身份,然后对其进行平均或修改以实现说话人匿名。然而,匿名后语音的自然度、说话人独特性方面有所下降,并且在应对强大攻击者时存在严重的隐私泄漏问题。
近期,西工大音频语音与语言处理研究组(ASLP@NPU)的论文 “Distinctive and Natural Speaker Anonymization via Singular Value Transformation-assisted Matrix” 在语音研究领域顶级期刊IEEE/ACM Transactions on Audio, Speech and Language Processing (TASLP)上发表,该论文针对说话人匿名问题开展了深入研究。论文提出了一种新颖的说话人匿名方法。该方法通过建模与说话人身份相关的矩阵,并将其转换为匿名奇异值变换辅助矩阵,从而隐藏原始说话人身份。该方法首先从预训练的ASV模型中提取帧级说话人向量,并使用注意力机制创建说话人得分矩阵和与说话人相关的标记。值得注意的是,说话人得分矩阵作为与之对应的说话人相关标记的权重,代表了说话人的身份。通过奇异值分解(SVD)重新组合分解后的正交特征向量矩阵和非线性变换的奇异值,生成奇异值变换辅助矩阵。这一过程防止了引入其他说话人身份信息而导致的说话人独特性下降。通过将奇异值变换辅助矩阵与说话人相关标记相乘,我们生成了匿名的说话人身份表示,从而产生既自然又独特的匿名语音。论文在VoicePrivacy竞赛官方数据集上进行了实验验证,证明了所提方法在所有攻击场景下都能有效保护说话人隐私,同时保持语音的自然性和独特性。

论文题目:Distinctive and Natural Speaker Anonymization via Singular Value Transformation-assisted Matrix
作者列表:姚继珣,王晴,郭鹏程,宁子谦,谢磊
发表期刊:IEEE/ACM Transactions on Audio, Speech and Language Processing
预印版:https://arxiv.org/pdf/2405.10786

发表论文截图

扫码直接看论文
背景动机
随着社交媒体的广泛应用,互联网上的语音数据呈指数级增长。诸如语音支付和语音助手等应用将语音数据存储在集中服务器上,使其容易被恶意攻击者窃取。语音数据包含丰富的个人敏感信息,如年龄、健康状况、宗教信仰等,这些信息可以通过说话人识别系统或其他类型的语音属性识别系统进行识别攻击,导致个人隐私泄露。说话人匿名能够在用户分享语音数据之前对用户隐私进行保护,是一种主动的隐私保护解决方案。
说话人匿名技术的相关研究仍处于起步阶段,现有研究在定义和评估标准方面缺乏一致性。为了解决这个问题并便于比较说话人匿名系统,语音社区引入了VoicePrivacy Challenge (VPC),并在2020年和2022年举行了比赛。VPC明确定义了说话人匿名任务、基准、评估标准和数据集,以推动专注于保护语音数据隐私的技术发展和创新。实验室在2022VPC竞赛提交的系统,在官方四个条件(condition)指标上均取得了第一名的优异成绩 [1]。
竞赛获奖系统解读:VPC2022语音隐私保护赛NWPU-ASLP说话人匿名化系统
说话人匿名的主要挑战在于如何选择适当的说话人身份表示,并有效地抑制原始说话人信息。之前的研究提出了直接使用从预训练的ASV模型中提取的说话人向量[2]或查找表(LUT)作为说话人身份表示[1]。这些表示可以通过诸如平均[2]、缩放[3]或添加对抗噪声[4]等技术进一步修改。然而,直接在语音转换模型中使用从预训练的ASV模型中提取的说话人向量存在局限性,因为预训练的ASV模型和语音转换模型通常没有使用转换优化函数联合训练。因此,在面对更强大的攻击者时,说话人匿名的性能显著下降。此外,从ASV模型中提取的表示是一个全局向量,可能保留了残余的说话人无关的全局信息,如风格和韵律。当直接对该表示进行平均或缩放时,匿名语音的独特性和自然性会明显下降,主要是由于引入了其他说话人的身份信息以及ASV模型与语音转换模型之间的不匹配所致。
本文提出了一种新颖的说话人匿名方法,将说话人身份建模为矩阵形式,称为奇异值变换辅助矩阵。奇异值变换辅助矩阵表示与说话人身份信息对应的权重,通过修改矩阵值可以有效地隐藏说话人身份,同时保持语音的自然性和独特性。为了避免传统方法中预训练的ASV模型与声学模型之间的不匹配问题,我们从预训练的ASV模型中提取帧级说话人表示,并利用自监督学习(SSL)生成说话人相关的标记和说话人得分矩阵,以获得更适合的话语级说话人身份表示。SSL模块与转换模型联合优化,这显著提高了转换后语音的自然性,并能有效捕捉说话人身份的独特属性。另一方面,说话人相关标记类似于软说话人身份标签,而说话人得分矩阵则是标记的权重,因此我们可以通过修改说话人得分矩阵来匿名原始说话人身份。我们采用奇异值分解(SVD)来分解说话人得分矩阵,生成表示相关性的奇异矩阵,用于生成最终的说话人表示权重。通过变换奇异矩阵,我们可以修改原始说话人矩阵的权重,实现匿名过程。提出的匿名过程无需额外的说话人向量池,降低了复杂性。SVD过程防止了因引入其他说话人身份信息而导致的说话人独特性下降。
解决方案
整体框架
图1 展示了我们提出说话人匿名系统的框架,该框架由三个模块组成:特征提取器、说话人身份建模模块和重构模块。在训练阶段,特征提取器会提取三种特征:韵律表示、软内容表示和帧级说话人向量。特征提取器包括两个预训练模型:基于HuBERT的软内容提取器、ECAPA-TDNN说话人提取器和一个韵律提取器。预训练模型在训练期间是冻结的。软内容提取器通过微调预训练的HuBERT-Base模型获得,特别关注从离散单元中获取细粒度连续上下文表示。从该模型提取的语言内容特征可以有效减少的误读与变调,并增加匿名语音的整体自然性。另一方面,ECAPA-TDNN负责提取与说话人特征相关的帧级表示。对于韵律提取,使用YAAPT算法从输入的语音信号中提取能量和F0作为韵律特征。
为了建模说话人身份表征,我们利用说话人身份建模模块来提取一个全局时变表征。该模块通过注意力机制将从预训练的ECAPA-TDNN中提取的帧级说话人向量转换为话语级的说话人表征。对于语言内容和韵律建模,提取的软内容和韵律特征作为软内容编码器和韵律编码器的输入,得到隐藏的语言内容表示和韵律表示。随后,解码器使用隐藏的语言内容、韵律和说话人表示来预测梅尔频谱图。最后,预训练的声码器从预测的梅尔频谱图重构语音波形。
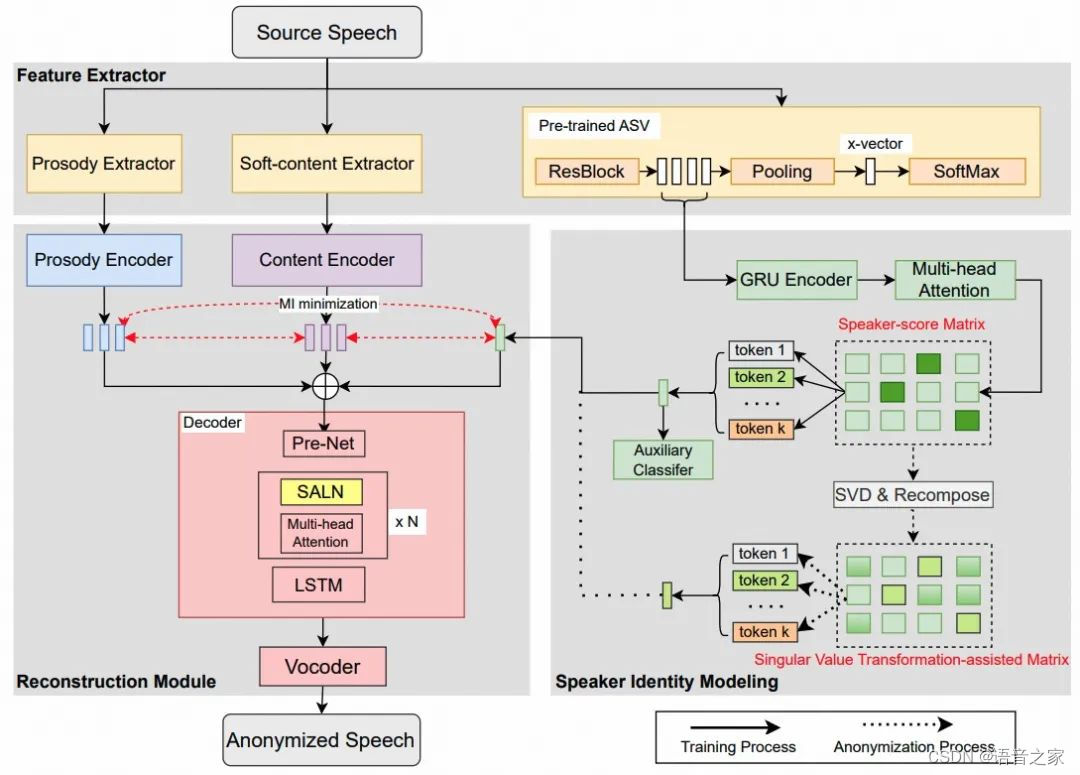
图 1. 提出的说话人匿名系统框架
内容编码器和韵律编码器的详细结构如图2所示。内容编码器由一个一维卷积网络和四个Conformer块组成。韵律编码器由一个两层的一维卷积网络(每层带有ReLU激活函数),每层后面跟一个dropout层,以及一个额外的线性层组成,用于将提取的F0和能量投射到隐藏表示中。两个编码器都将软内容特征和韵律编码为与说话人身份表示相同的维度,旨在最小化不同表示之间的互信息,并实现表示之间的相互补充。
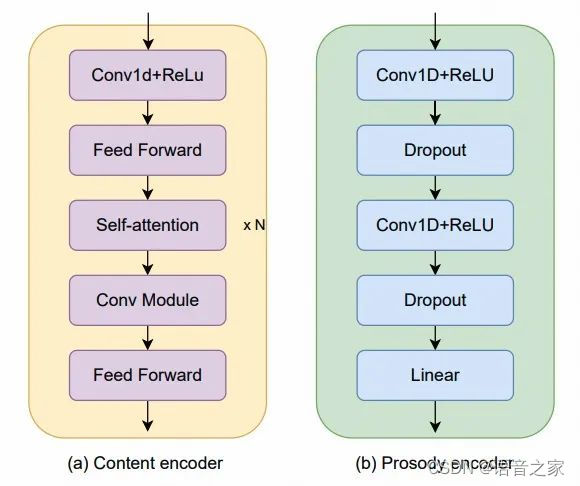
图 2. 内容编码器与韵律编码器结构图
说话人身份表示建模
说话人身份表示在说话人匿名中的作用具有至关重要的作用。其重要性可分为两个方面:获得说话人身份的最佳表示;其次,隐藏说话人的身份。理想的匿名说话人表示应具备以下特点:1) 取消原始说话人身份信息,2) 保留独特的说话人身份以维持匿名说话人的多样性,3) 排除任何残留的与说话人无关的信息。传统上,普遍的方法将说话人身份视为一个全局表示,并直接提取话语级别的说话人向量,通常称为 x-vector。不幸的是,这些方法忽视了说话人身份中其他宝贵的时变信息。
为了避免丢失说话人身份信息并减少残留的与说话人无关的信息,我们将说话人身份表示建模为三个步骤:
(i). 我们从预训练的ASV模型中提取帧级别的说话人向量,而不是传统的话语级别向量。如图1所示,预训练的ASV模型由几个ResNet块、一个池化层和一个全连接层组成。我们提取最后一个ResNet块的输出作为与说话人相关的向量,这些向量保留了时间维度。
(ii). 帧级别的说话人向量作为GRU编码器的输入,该编码器旨在捕获既有时不变又有其他时变的说话人身份信息,我们利用GRU层的输出作为注意力查询。
(iii). 使用注意力机制来捕获说话人表示和说话人相关标记之间的相关性,同时生成说话人分数矩阵。
这种配置使注意力层能够捕获突出的特征,并在说话人身份表示中对最相关的信息进行对齐。一旦我们获得了说话人得分矩阵,我们可以以多头方式生成一个固定维度的说话人向量。
匿名策略
在前面的部分,我们介绍了通过说话人得分矩阵和说话人相关标记之间的乘法生成的说话人身份表示。说话人相关标记类似于软说话人标签,不同的说话人得分矩阵明显对应于不同的说话人。因此,奇异值变换辅助矩阵是通过使用SVD进行矩阵变换生成的。图3显示了奇异值变换辅助矩阵的生成过程,具体的算法流程可以参考算法1。
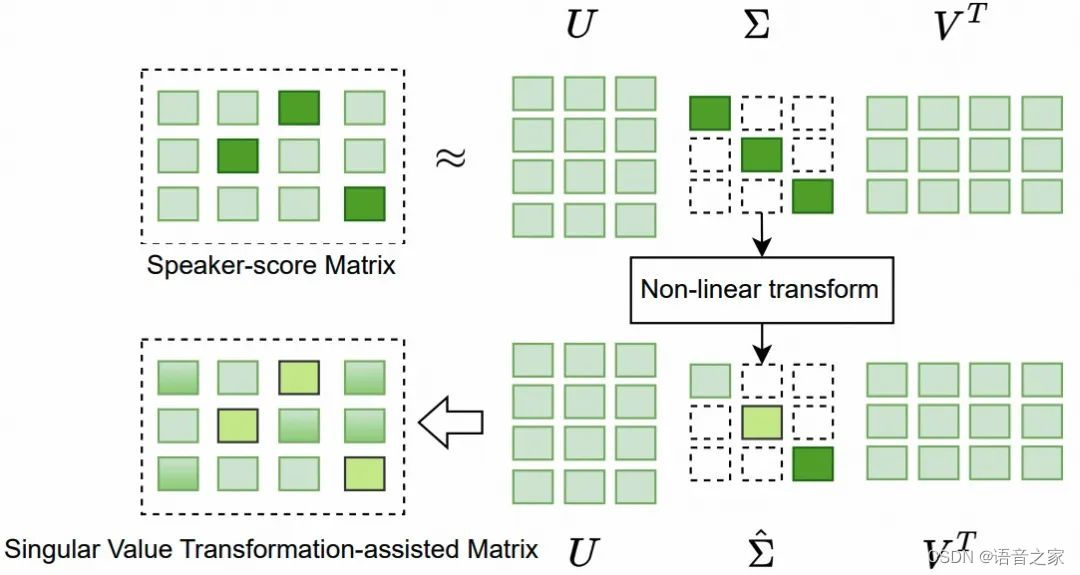
图 3. 基于奇异值分解的匿名流程图
算法1. 基于奇异值分解的说话人匿名算法流程

实验验证
实验设置
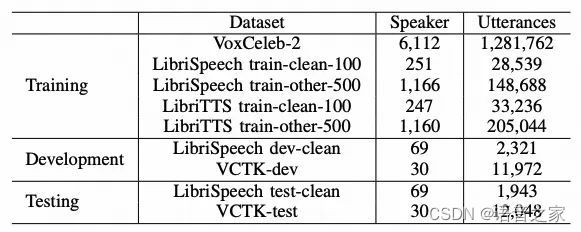
为了评估我们提出的匿名系统在所有攻击场景下的性能,即Ignore、lazy-informed、semi-informed,我们遵循了VPC竞赛的官方评估方案,并在官方数据集上进行了实验,数据集详情如表1所示。
表1. 实验所用数据集
隐私保护实验结果
根据VPC评估计划的配置,我们首先研究了我们提出的匿名系统在各种攻击场景下的隐私保护性能。如表2所示,对于无知情景,开发和测试数据集中的平均EER结果都高于50%,表明我们提出的匿名系统在这种情况下能够有效保护个人隐私。对于另外两个更具挑战性的攻击情景,攻击者对匿名系统的了解水平高于无知情景,我们提出的系统的EER结果只有轻微差距。尽管如此,我们的匿名系统仍然实现了合理的隐私保护性能。这些结果表明,我们提出的匿名系统即使在更具挑战性的攻击下也能最大程度地减少说话人隐私泄漏。
关于语调和独特性性能,F0指标表明音调相关性分别在开发和测试数据集中达到了0.83和0.84。这些分数显著高于VPC要求的最低平均音调相关性0.3。此外,我们提出的系统的独特性结果接近于0,这表明在匿名说话人中有效保留了原始的独特性。
表2. 提出的匿名系统在不同场景下隐私保护的结果
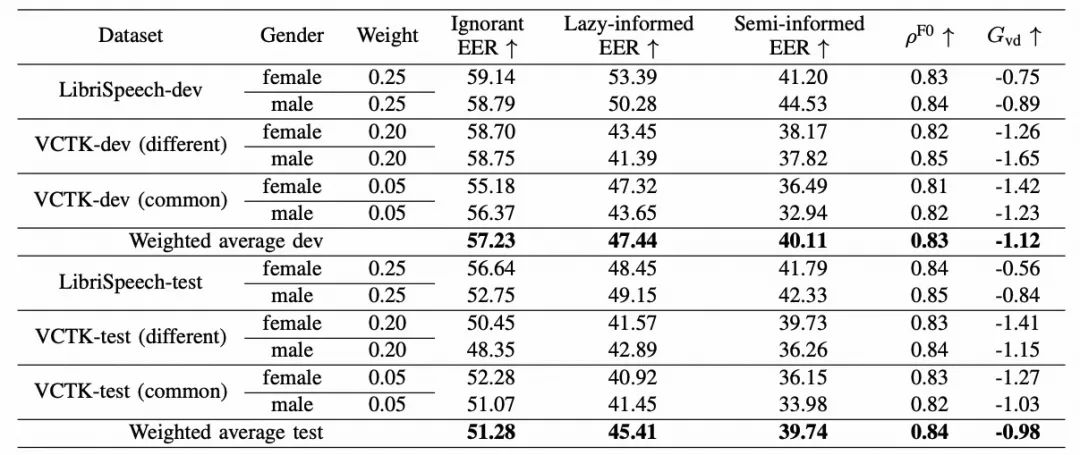
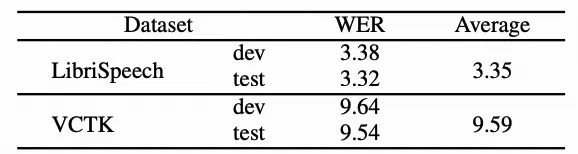
表3展示了我们提出的系统的可理解性性能。我们观察到LibriSpeech数据集和VCTK数据集之间的WER结果存在差距,尽管VCTK数据集的WER结果已经较低。这种差异可能归因于LibriSpeech数据集属于与软内容提取器的训练数据集相同的领域。平均WER结果分别为LibriSpeech数据集和VCTK数据集为3.35%和9.59%。这些结果表明,匿名语音可以有效保留语言信息并保持更好的可理解性。
表3. 音频匿名后的WER结果
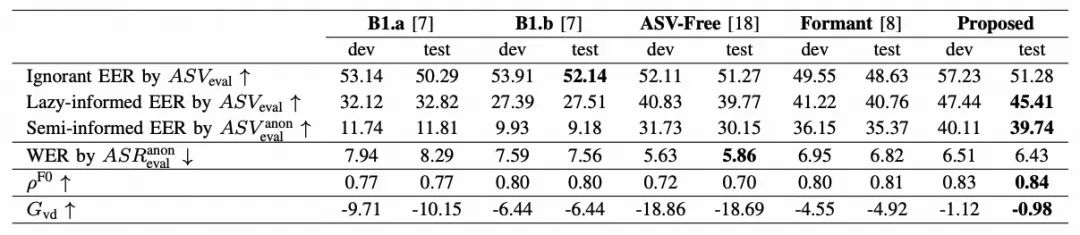
基线系统对比结果
为了进一步展示我们提出的系统的有效性,我们在主观和客观指标上将我们的系统与基线系统进行了比较。客观结果如表4所示。在半知情场景中,B1.a和B1.b系统的隐私保护性能显著下降,与无知或懒惰知情场景相比差距更大。这表明,当攻击者了解匿名系统时,VPC基线系统在保护个人隐私方面效果不佳。相反,我们提出的匿名系统在四个匿名系统中在半知情场景中实现了最高的EER结果,展示了其在面对更强大攻击者时保护说话人隐私的卓越能力。关于WER结果,我们提出的系统显著低于B1.a、B1.b和Formant系统,仅略高于ASV-Free系统。然而,考虑到说话人可区分性指标,ASV-Free系统是不可取的,因为它无论原始说话人如何都产生相似的声音。此外,音调和独特性结果清楚地表明,使用我们提出的系统匿名的语音具有比基线系统更高的音调相关性和更大的多样性。这表明,我们提出的匿名系统在保留说话人原始语调和独特性方面表现出色。
表4. 提出的说话人匿名系统与基线系统的对比结果
除了客观的独特性指标外,我们还采用了计算匿名语音独特性指标的相似性矩阵的可视化,如图4所示。相似性矩阵由VPC官方工具包在LibriSpeech和VCTK测试数据集上计算得到。在图中矩阵明显的主对角线反映了更高的声音独特性,当说话人不同的时候,主对角线消失。对于B1.a、B1.b和Formant系统,矩阵中主对角线不清晰,表明在匿名过程中声音独特性有所下降。对于ASV-Free系统,矩阵中的主对角线消失,使得说话人难以区分。相比之下,我们提出的匿名系统的矩阵显示了明显的主对角线,这表明在匿名后成功保留了声音的独特性。

图4. 说话人相似度矩阵可视化。O代表原始音频,A代表匿名音频
为了进一步分析我们提出的系统的自然性,我们进行了主观测试,并比较了我们系统和基线系统在自然性方面的MOS评分。图5显示了MOS结果的小提琴图。VPC基线系统的主观得分相似,B1.b的自然性得分高于B1.a。此外,ASV-Free和Formant的自然性得分均高于B1.b。然而,我们提出的匿名系统的匿名语音自然性进一步提高,超越了所有基线系统的自然性。这表明,在主观评价中,我们的匿名系统在匿名语音的自然性方面表现得更好。
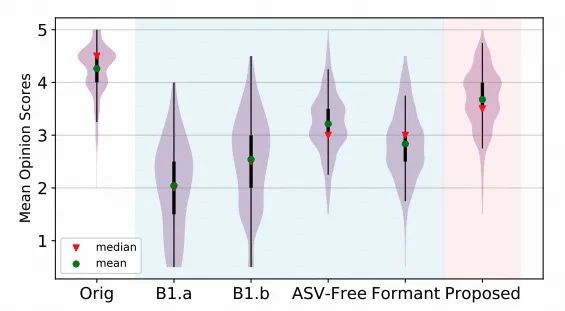
图5. 主观MOS测评结果
参考文献
[1] J. Yao, Q. Wang, L. Zhang, P. Guo, Y. Liang, and L. Xie, “NWPU-ASLP system for the VoicePrivacy 2022 challenge,” arXiv preprint arXiv:2209.11969, 2022
[2] B. M. L. Srivastava, M. Maouche, M. Sahidullah, E. Vincent, A. Bellet, M. Tommasi, N. Tomashenko, X. Wang, and J. Yamagishi, “Privacy and utility of x-vector based speaker anonymization,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 30, pp. 2383–2395, 2022
[3] J. Yao, Q. Wang, Y. Lei, P. Guo, L. Xie, N. Wang, and J. Liu, “Distinguishable speaker anonymization based on formant and fundamental frequency scaling,” in ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2023.
[4] C. Huang, Y. Y. Lin, H. Lee, and L. Lee, “Defending your voice: Adversarial attack on voice conversion,” in IEEE Spoken Language Technology Workshop, SLT, 2021, pp. 552–559.
[5] Miao X, Wang X, Cooper E, et al. Speaker anonymization using orthogonal householder neural network. in IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2023.

















 8060
8060

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









