






AI视野·今日CS.Robotics 机器人学论文速览
Tue, 28 Sep 2021
Totally 48 papers
👉上期速览✈更多精彩请移步主页
Interesting:
📚SLAM系统发展综述,Robust SLAM Systems (from 英国曼大,intel中国实验室,北航)

***📚WiFi-Sensor-for-Robotics, 基于wif的机器人定位工具包。(from 哈佛 cmu)
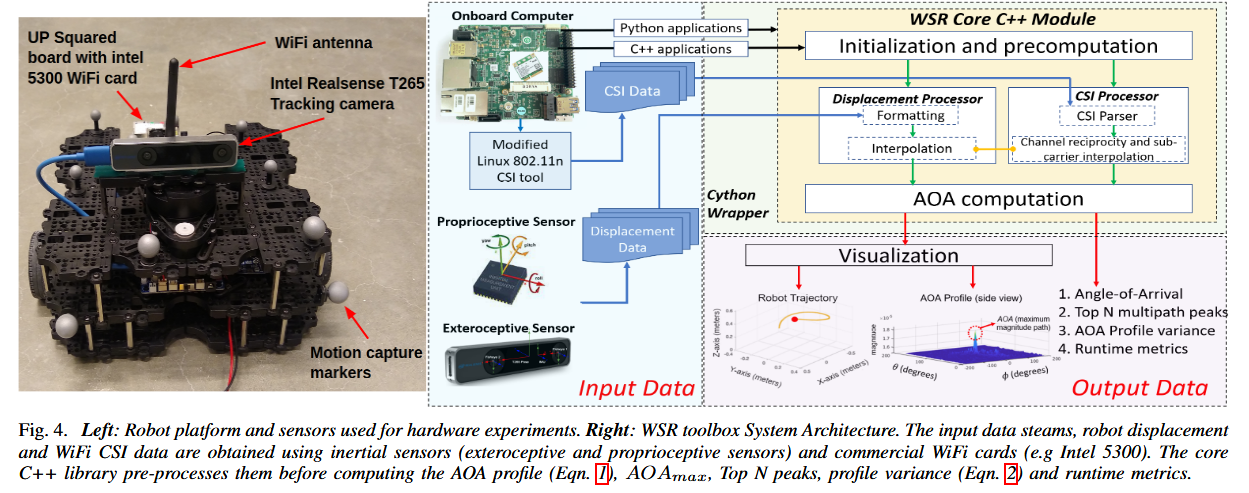
code: https://github.com/Harvard-REACT/WSR-Toolbox
📚月球上的采矿小车, (from 阿德莱德大学)
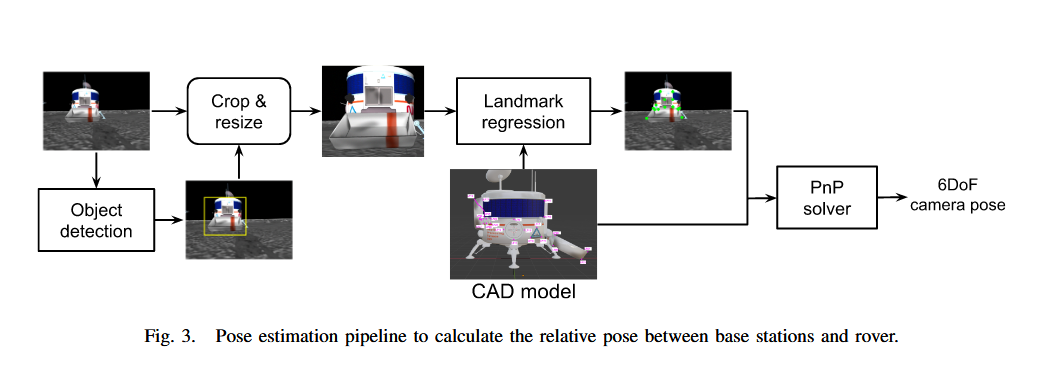
NASA Space Robotics Challeng
Daily Robotics Papers
| A 3-DOF Robotic Platform for the Rehabilitation of Reaction Time and Balance Skills of MS Patients Authors Tugce Ersoy, Elif Hocaoglu 我们介绍了用于治疗 MS 患者平衡障碍的 3 DOF 机器人平台的设计、实施和实验评估。机器人平台的设计允许脚踝基于空间中的拟人自由度进行角运动。话虽如此,这样的机器人通过在三个方向上改变平台的角度位置来迫使患者保持平衡。任务的难度级别是根据从负责患者对意外扰动的反应时间的上下平台收集的数据确定的。上平台即时提供每只脚的压力分布,而下平台同时共享患者的重心。在这项研究中,成功实现了 3 DOF 并联机械手的运动学和动力学分析和仿真。概念设计验证的控制是通过PID控制进行的。 |
| G-VOM: A GPU Accelerated Voxel Off-Road Mapping System Authors Timothy Overbye, Srikanth Saripalli 我们提出了一个用于越野路径规划和导航的局部 3D 体素映射框架。我们的方法提供硬和软正障碍检测、负障碍检测、坡度估计和粗糙度估计。通过使用 3D 数组查找表数据结构并利用 GPU,它可以提供在线性能。然后,我们演示了该系统在三辆车上工作,即 Clearpath Robotics Warthog、Moose 和 Polaris Ranger,并与一组预先记录的航点进行比较。这是在自主操作中以 4.5 毫秒完成,在手动操作中以 12 毫秒完成,地图更新率为 10 赫兹。 |
| Precision fruit tree pruning using a learned hybrid vision/interaction controller Authors Alexander You, Hannah Kolano, Nidhi Parayil, Cindy Grimm, Joseph R. Davidson 机器人修剪树木需要高度精确的机械手控制,以便以正确的角度将切割工具与所需的修剪点准确对齐。同时,机器人必须避免对环境的刚性部分(例如树木、支柱和电线)施加过大的力。在本文中,我们提出了一种混合控制系统,该系统使用基于学习视觉的控制器来初始将刀具与所需的修剪点对齐,获取环境图像并输出控制动作。该控制器完全在模拟中训练,但可以通过神经网络轻松转移到真实的树上,该网络将原始图像转换为简化的分段表示。一旦建立接触,系统就会将控制权移交给一个交互控制器,该控制器将刀具枢轴点引导到分支,同时最小化交互力。 |
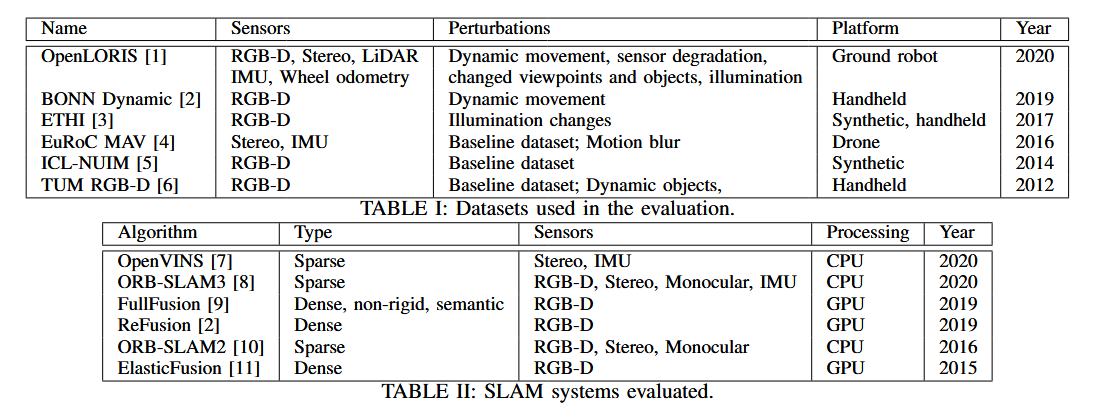
| Robust SLAM Systems: Are We There Yet? Authors Mihai Bujanca, Xuesong Shi, Matthew Spear, Pengpeng Zhao, Barry Lennox, Mikel Lujan 过去十年的进步带来了 SLAM 系统准确性和速度的显着改进,拓宽了它们的映射能力。 |
| Dynamic Allocation of Visual Attention for Vision-based Autonomous Navigation under Data Rate Constraints Authors Ali Reza Pedram, Riku Funada, Takashi Tanaka 本文考虑了任务相关的自上而下注意力分配问题,用于使用已知地标的基于视觉的自主导航。与将地标选择表述为组合优化问题的现有范式不同,我们将其建模为资源分配问题,其中决策者 DM 被授予额外的自由来控制对每个地标的关注程度。 DM 可用的总资源用输入信息流的容量限制表示,它由从环境状态到 DM 观察的定向信息量化。我们考虑线性二次高斯 LQG 机制中这种受控传感方案的后退水平实现。凸凹过程应用于每个时间步长,如果使用乘法器的交替方向方法 ADMM,则其时间复杂度在水平长度上呈线性。 |
| Non-prehensile Planar Manipulation via Trajectory Optimization with Complementarity Constraints Authors Jo o Moura, Theodoros Stouraitis, Sethu Vijayakumar 接触适应是操纵物体时的一项基本能力。非抓握操作的两种关键接触方式是粘着和滑动。本文提出了一种轨迹优化 TO 方法,该方法制定为具有互补约束 MPCC 的数学程序,它能够在这两种模式之间切换。我们表明该公式可适用于平面操作任务的规划和模型预测控制 MPC。我们在数值上将我们的规划器与混合整数替代方案进行了比较,表明 MPCC 平面器收敛速度更快,在时间范围方面的扩展性更好,并且可以处理有障碍物的环境 ii 我们的控制器与最先进的混合整数方法相比,表明MPCC 控制器实现了更好的跟踪和更一致的计算时间。 |
| Trajectory-based Reinforcement Learning of Non-prehensile Manipulation Skills for Semi-Autonomous Teleoperation Authors Sangbeom Park, Yoonbyung Chai, Sunghyun Park, Jeongeun Park, Kyungjae Lee, Sungjoon Choi 在本文中,我们提出了一个使用 RGB D 传感器的拾放任务的半自主遥操作框架。特别地,我们假设目标对象位于杂乱的环境中,在该环境中,抓握和非抓握操作结合起来以实现有效的遥操作。基于轨迹的强化学习用于学习非抓握操作以重新排列对象以实现直接抓取。从杂乱环境的深度图像和目标物体的位置,学习到的策略可以为人类操作员提供多种非抓握操作的选择。我们为重排任务精心设计了一个奖励函数,其中在模拟环境中训练策略。 |
| Validating human driver models for interaction-aware automated vehicle controllers: A human factors approach Authors Olger Siebinga, Arkady Zgonnikov, David Abbink 自动驾驶汽车面临的一个主要挑战是与其他交通参与者安全顺畅地互动。处理此类交通交互的一种有前途的方法是为自动驾驶汽车配备交互感知控制器 IAC。这些控制器基于驾驶员模型预测周围的人类驾驶员将如何响应自动驾驶汽车的动作。然而,IAC 中使用的驱动程序模型的预测有效性很少得到验证,这可能会限制 IAC 在演示它们的简单模拟环境之外的交互能力。在本文中,我们认为除了评估 IAC 的交互能力外,还应根据自然的人类驾驶行为验证其底层驱动程序模型。我们为此验证提出了一个工作流程,其中包括基于场景的数据提取和基于人为因素文献的两阶段战术操作评估程序。我们在从现有 IAC 复制的基于逆向强化学习的驱动程序模型的案例研究中演示了此工作流程。该模型仅在 40 个预测中显示了正确的战术行为。该模型的操作行为与观察到的人类行为不一致。案例研究表明,有原则的评估工作流程是有用的,也是必要的。 |
| Learning of Parameters in Behavior Trees for Movement Skills Authors Matthias Mayr, Konstantinos Chatzilygeroudis, Faseeh Ahmad, Luigi Nardi, Volker Krueger 强化学习 RL 是一个强大的数学框架,它允许机器人通过反复试验来学习复杂的技能。尽管在许多应用中取得了无数成功,但 RL 算法仍然需要数千次试验才能收敛到高性能策略,在学习时可能会产生危险行为,并且通常建模为神经网络的优化策略在无法执行任务时给出的解释几乎为零。由于这些原因,在工业环境中采用 RL 并不常见。另一方面,行为树 BTs 可以提供一种策略表示,a 支持模块化和可组合技能,b 允许轻松解释机器人动作,c 提供有利的低维参数空间。在本文中,我们提出了一种新算法,该算法可以在模拟中学习 BT 策略的参数,然后在没有任何额外训练的情况下推广到物理机器人。我们利用带有工作站数字孪生的物理模拟器,并使用黑盒优化器优化相关参数。 |
| GPU Accelerated Batch Multi-Convex Trajectory Optimization for a Rectangular Holonomic Mobile Robot Authors Fatemeh Rastgar, Houman Masnavi, Karl Kruusam e, Alvo Aabloo, Arun Kumar Singh 我们提出了一个批处理轨迹优化器,可以同时实时解决数百个不同的问题实例。我们考虑完整机器人,但放宽了圆形底座足迹的假设。我们的主要算法贡献在于提高了底层非凸问题的计算易处理性,以及利用批量计算来缓解初始化瓶颈并提高解决方案质量。我们通过推导出运动学和碰撞避免约束的多凸重构来实现这两个目标。我们通过交替最小化方法利用这些结构,并表明由此产生的批处理操作减少到只计算矩阵向量乘积,这些乘积可以在 GPU 上进行微不足道的加速。我们在三个方面改进了最先进的技术。首先,与依赖于在每个控制回路计算单个局部最优轨迹的基线方法相比,我们提高了导航成功率、跟踪的质量。其次,我们表明,当使用来自高斯分布的轨迹样本进行初始化时,我们的批量优化器在解决方案质量方面优于最先进的交叉熵方法。最后,我们的批处理优化器比在并行 CPU 线程中运行不同优化实例的概念上更简单的替代方案快几个数量级。 |
| CT-ICP: Real-time Elastic LiDAR Odometry with Loop Closure Authors Pierre Dellenbach, Jean Emmanuel Deschaud, Bastien Jacquet, Fran ois Goulette 多光束 LiDAR 传感器越来越多地用于机器人技术,特别是用于定位和感知任务的自动驾驶汽车。然而,感知与定位任务和机器人构建其环境精细地图的能力密切相关。为此,我们提出了一种新的实时 LiDAR 里程计方法,称为 CT ICP,以及具有闭环的完整 SLAM。 CT ICP 的原理是使用轨迹的弹性公式,具有扫描内姿势的连续性和扫描之间的不连续性,以便对传感器运动中的高频更加鲁棒。配准是基于扫描映射到密集点云作为以稀疏体素结构化的实时操作的映射。同时,使用高程图像和通过图形优化姿态的快速回环检测方法允许纯粹在 LiDAR 上获得完整的 SLAM。为了展示该方法的稳健性,我们在驾驶和高频运动场景中在七个数据集 KITTI、KITTI raw、KITTI 360、KITTI CARLA、ParisLuco、Newer College 和 NCLT 上对其进行了测试。 CT ICP 里程计是用 C 语言实现的,可在线获取。循环检测和姿态图优化位于 Python 框架 pyLiDAR SLAM 中,也可在线获取。 |
| A Biologically Inspired Global Localization System for Mobile Robots Using LiDAR Sensor Authors Genghang Zhuang, Carlo Cagnetta, Zhenshan Bing, Kai Huang, Alois Knoll 环境中的定位是动物和移动机器人必不可少的导航能力。在室内环境中,使用概率方法完美解决全局定位问题仍然具有挑战性。然而,动物能够以更少的努力本能地定位自己。因此,从动物身上寻找生物学灵感是一件有趣而有希望的事情。在本文中,我们提出了一个使用 LiDAR 传感器的生物学启发的全局定位系统,该传感器利用海马模型和基于地标的重新定位方法。 |
| A Biologically Inspired Simultaneous Localization and Mapping System Based on LiDAR Sensor Authors Genghang Zhuang, Zhenshan Bing, Jiaxi Zhao, Ning Li, Yuhong Huang, Kai Huang, Alois Knoll 同时定位和映射 SLAM 是机器人用于执行自主导航任务的基本技术和功能之一。受啮齿动物海马体的启发,本文提出了一种基于 LiDAR 传感器的受生物学启发的 SLAM 系统,使用海马体模型构建认知地图并估计室内环境中的机器人姿态。基于生物启发模型,使用来自 LiDAR 传感器的点云数据的 SLAM 系统能够利用来自 LiDAR 里程计的自运动线索和来自 LiDAR 局部视图单元的局部视图线索来构建认知地图并估计机器人姿势。 |
| Nonlinear MPC for Quadrotor Fault-Tolerant Control Authors Fang Nan, Sihao Sun, Philipp Foehn, Davide Scaramuzza 四旋翼飞行器的机械简单性、悬停能力和高度敏捷性使该行业能够快速适应检查、探索和城市空中机动性。另一方面,四旋翼飞行器的不稳定和欠驱动动力学使它们非常容易受到系统故障的影响,尤其是转子故障。在这项工作中,我们提出了一种容错控制器,使用非线性模型预测控制 NMPC 来稳定和控制遭受单个转子完全故障的四旋翼飞行器。与依赖线性假设或采用忽略外环输入约束的级联结构的现有工作不同,我们的方法利用损坏的四旋翼的完全非线性动力学并考虑每个转子的推力约束。因此,这种方法可以从标称飞行到转子故障飞行无缝过渡,并有效地从极端初始条件下执行加厚恢复。 |
| Introspective Robot Perception using Smoothed Predictions from Bayesian Neural Networks Authors Jianxiang Feng, Maximilian Durner, Zoltan Csaba Marton, Ferenc Balint Benczedi, Rudolph Triebel 这项工作的重点是改进 RGB 图像对象分类领域的不确定性估计,并展示了其在两个机器人应用中的优势。我们采用 BNN 并评估两种实用的推理技术以获得更好的不确定性估计,即 Concrete Dropout CDP 和 Kronecker 分解拉普拉斯近似 LAP 。我们展示了使用更可靠的不确定性估计作为条件随机场 CRF 中的一元潜力的性能提升,该 CRF 也能够合并上下文信息。此外,利用获得的不确定性以半监督的方式实现域适应,这在注释数据时需要较少的人工工作。 |
| Anti-collision Technologies for Unmanned Aerial Vehicles: Recent Advances and Future Trends Authors Zhiqing Wei, Zeyang Meng, Meichen Lai, Huici Wu, Jiarong Han, Zhiyong Feng 无人机 无人机广泛应用于救灾、农业、货运等民用领域。随着无人机飞行活动的海量,旨在避免无人机与其他物体碰撞的防撞技术备受关注。 .防撞技术对于保障无人机的生存性和安全性至关重要。在本文中,对无人机防撞技术进行了全面调查。我们首先在政策层面引入了无人机安全方面的法律法规,防止碰撞。然后,从障碍物感知、碰撞预测和碰撞避免三个方面回顾了防碰撞技术的发展过程。我们对各个方面的方法进行了详细的调查和比较,并分析了它们的优缺点。此外,从快速障碍物感知和快速无线组网的角度介绍了无人机防撞技术的未来发展趋势。 |
| Emotional Speech Synthesis for Companion Robot to Imitate Professional Caregiver Speech Authors Takeshi Homma, Qinghua Sun, Takuya Fujioka, Ryuta Takawaki, Eriko Ankyu, Kenji Nagamatsu, Daichi Sugawara, Etsuko T. Harada 当人们试图影响他人做某事时,他们会下意识地调整自己的言语以包含适当的情感信息。为了让机器人以同样的方式影响人,机器人应该能够模仿人类说话时的情绪范围。为此,我们提出了一种模仿人类语音中情绪状态的语音合成方法。与以前的方法相比,我们方法的优点是它需要较少的人工来调整合成语音的情绪。我们的合成器接收一个情感向量来表征合成语音的情感。该向量是通过使用语音情感识别器从人类话语中自动获得的。我们在机器人试图通过使用适当的情绪状态与老人交谈来调节老人的昼夜节律的场景中评估了我们的方法。为了模仿目标语音,我们收集了专业护理人员在一天中的不同时间与老年人交谈时的话语。然后我们进行了主观评估,老年参与者听了我们的方法生成的语音样本。结果表明,聆听样本让参与者在清晨感觉更活跃,在半夜更平静。 |
| Markerless Suture Needle 6D Pose Tracking with Robust Uncertainty Estimation for Autonomous Minimally Invasive Robotic Surgery Authors Zih Yun Chiu, Albert Z Liao, Florian Richter, Bjorn Johnson, Michael C. Yip 缝合针定位对自主缝合起着至关重要的作用。为了稳健地跟踪缝合针的 6D 姿态,以前的方法通常在针上添加标记或执行复杂的特征提取操作,使得这些方法难以适用于现实世界环境。因此,在这项工作中,我们提出了一种使用贝叶斯滤波器进行无标记缝合针姿势跟踪的新方法。训练数据高效的特征点检测器以提取针上的特征点。然后基于这些检测,我们提出了一种新的观察模型,该模型测量检测与针的预期投影之间的重叠,可以有效地计算。此外,对于所提出的方法,我们推导出了观测噪声协方差的近似值,使该模型对检测中的不确定性更具鲁棒性。仿真实验结果表明,所提出的观测模型实现了约1.5mm的空间位置和1度方向的低跟踪误差。我们还展示了我们训练的无标记特征检测器与现实世界环境中提出的观察模型相结合的定性结果。 |
| On the Feasibility of Learning Finger-gaiting In-hand Manipulation with Intrinsic Sensing Authors Gagan Khandate, Maxmillian Haas Heger, Matei Ciocarlie 手指步态操作是实现物体大角度重新定向的重要技能。然而,由于任务的不稳定性质,在手的任意方向上实现这些步态是具有挑战性的。在这项工作中,我们使用无模型强化学习 RL 仅通过精确抓取来学习手指步态,并演示手指步态围绕轴旋转,完全使用机载本体感受和触觉反馈。为了解决精确抓取固有的不稳定性,我们建议使用初始状态分布来有效探索状态空间。我们的方法可以学习手指步态,与现有技术相比,样本复杂度显着提高。 |
| Finite State Machine Policies Modulating Trajectory Generator Authors Ren Liu, Nitish Sontakke, Sehoon Ha 深度强化学习深度 RL 已成为开发腿式机器人控制器的有效工具。然而,简单的神经网络表示以其较差的外推能力而闻名,这使得学习行为容易受到看不见的扰动或具有挑战性的地形的影响。因此,研究人员研究了一种新颖的架构,即 Policies Modulating Trajectory Generators PMTG,它结合了轨迹发生器 TG 和反馈控制信号,以实现更稳健的行为。在这项工作中,我们建议通过用异步有限状态机 Async FSM 替换简单的 TG 来扩展具有有限状态机 PMTG 的 PMTG 框架。本发明为协商意外扰动的策略提供了明确的接触事件概念。我们证明了所提出的架构可以在模拟和真实机器人上的各种场景中实现更稳健的行为,例如具有挑战性的地形或外部扰动。 |
| VP-GO: a "light" action-conditioned visual prediction model Authors Anji Ma, Yoann Fleytoux, Jean Bapstiste Mouret, Serena Ivaldi 视觉预测模型是基于视觉的机器人抓取杂乱的未知软物体的有前途的解决方案。以前的文献模型在计算上是贪婪的,这限制了可重复性,尽管有些人考虑了预测模型中的随机性,但往往太弱,无法捕捉涉及抓取此类物体的机器人实验的现实。此外,之前的工作侧重于在更复杂的语义动作方面无法有效推理的基本动作。为了解决这些限制,我们提出了 VP GO,一种轻随机动作条件视觉预测模型。我们建议将语义抓取和操作动作分层分解为基本的末端执行器运动,以确保与现有模型和数据集的兼容性,用于机器人动作的视觉预测,例如 RoboNet。我们还记录并发布了一个新的开放数据集,用于物体抓取的视觉预测,称为 PandaGrasp。我们的模型可以在 RoboNet 上进行预训练并在 PandaGrasp 上进行微调,并且在信号预测指标方面的表现与更复杂的模型类似。 |
| Linear Policies are Sufficient to Realize Robust Bipedal Walking on Challenging Terrains Authors Lokesh Krishna, Guillermo A. Castillo, Utkarsh A. Mishra, Ayonga Hereid, Shishir Kolathaya 在这项工作中,我们仅通过学习一个线性策略就证明了双足机器人 Digit 在不平坦地形上的稳健行走。特别是,我们提出了一种新的控制管道,其中高级轨迹调制器塑造末端足椭圆形轨迹,而低级步态控制器调节躯干和脚踝方向。足部轨迹调制器使用线性策略,调节器使用线性 PD 控制律。与基于神经网络的策略相反,所提出的线性策略只有 13 个可学习参数,从而不仅保证了样本有效学习,而且还实现了策略的简单性和可解释性。这是在斜坡、楼梯和户外景观等具有挑战性的地形上实现的,不会损失性能。我们首先在自定义模拟环境 MuJoCo 中演示鲁棒行走,然后直接转移到硬件而不修改控制管道。 |
| Embedded Hardware Appropriate Fast 3D Trajectory Optimization for Fixed Wing Aerial Vehicles by Leveraging Hidden Convex Structures Authors Vivek Kantilal Adajania, Houman Masnavi, Fatemeh Rastgar, Karl Kruusamae, Arun Kumar Singh 大多数商用固定翼飞行器 FWV 只能携带小型、轻便的计算硬件,例如 Jetson TX2。即使仅考虑运动学运动模型,在这些计算资源上解决非线性轨迹优化在计算上也具有挑战性。最重要的是,随着环境变得更加混乱,计算时间会急剧增加。在本文中,我们朝着克服这一瓶颈迈出了一步,并提出了一种轨迹优化器,可在典型的城市环境设置中同时在传统笔记本电脑台式机和 Jetson TX2 上实现在线性能。我们的优化器建立在新的见解之上,即 FWV 的看似非线性的轨迹优化问题具有隐式多凸结构。我们的优化器通过将交替最小化、布雷格曼迭代和乘法器交替方向方法中的不同概念结合在一起来利用这些计算结构。 |
| Anytime Game-Theoretic Planning with Active Reasoning About Humans' Latent States for Human-Centered Robots Authors Ran Tian, Liting Sun, Masayoshi Tomizuka, David Isele 以人为中心的机器人需要对其人类伙伴的认知限制和潜在的非理性进行推理,以实现无缝交互。本文提出了一种随时博弈论规划器,该规划器集成了迭代推理模型、部分可观察马尔可夫决策过程和机会约束蒙特卡罗信念树搜索,用于机器人行为规划。我们的规划器使机器人能够安全、主动地实时推理其人类伙伴的潜在认知状态、有限的智能和非理性,以更好地最大化其效用。我们在自动驾驶领域验证了我们的方法,其中我们的行为规划器和低级运动控制器分层控制自动驾驶汽车以协商交通合并。 |
| Singularities of serial robots: Identification and distance computation using geometric algebra Authors Isiah Zaplana, Hugo Hadfield, Joan Lasenby 串行机器人机械手的奇异性是机器人失去向至少一个方向移动的能力的那些配置。因此,它们的识别对于提高当前控制和运动规划策略的性能至关重要。虽然经典方法需要计算 n 自由度串行机器人的 6x n 或 nxn 矩阵的行列式,但这项工作提出了一种新颖的奇点识别方法,该方法基于将机器人关节轴定义的扭曲建模为六维和三维几何代数。特别是,它包括确定哪些配置导致这些扭曲的外部产品消失。此外,由于转子在几何代数中表示旋转,一旦确定了这些奇异点,在配置空间 C 中定义了一个距离函数,使得它对奇异配置集 S 的限制允许我们计算任何配置到一个的距离给定的奇异性。 |
| Efficient Force Estimation for Continuum Robot Authors Qingyu Xiao, Yue Chen 外部接触力是机器人建模、控制外部物体并与外部物体安全交互的最重要信息之一。对于连续体机器人,可以根据机器人配置的测量来估计接触力,这解决了在具有严格尺寸约束的机器人身上实现力传感器反馈的困难。在本文中,我们使用从光纤布拉格光栅传感器 FBGS 测量的局部曲率来估计单个或多个外部接触力的大小和位置。简化的力学模型源自 Cosserat 杆理论,用于计算连续体机器人曲率。最小二乘优化用于通过最小化计算曲率和测量曲率之间的误差来估计力。结果表明,该方法能够准确估计接触力大小误差 5.25 12.87 和位置误差 1.02 2.19 。在MATLAB中验证了该方法的计算速度。结果表明,我们的方法比传统方法快 29.0 101.6 倍。 |
| Improved Soft Duplicate Detection in Search-Based Motion Planning Authors Nader Maray, Anirudh Vemula, Maxim Likhachev 基于搜索的技术通过离散化状态空间和预计算运动原语,在机器人导航等运动规划问题中取得了巨大成功。然而,在具有复杂动态约束的领域中,在离散状态空间中构建运动原语并非易事。这需要在连续空间中运行,这对于基于搜索的规划器来说可能具有挑战性,因为他们可能会陷入局部最小值区域。先前在连续空间中进行规划的工作引入了软重复检测,这需要搜索来计算状态相对于先前看到的状态的重复性,以避免探索可能重复的状态,尤其是在局部极小值区域。他们提出了一个简单的度量,利用状态之间的欧几里德距离和与障碍物的接近度来计算重复性。在本文中,我们通过在两个状态之间引入运动动力学知情度量、子树重叠来改进该度量,作为它们的后继者之间的相似性,可以使用运动动力学运动原语在固定时间范围内达到。 |
| Closed-form solutions for the inverse kinematics of serial robots using conformal geometric algebra Authors Isiah Zaplana, Hugo Hadfield, Joan Lasenby 这项工作解决了使用共形几何代数的串行机器人的逆运动学问题。经典方法包括使用齐次矩阵,这需要高计算成本和执行时间,或者开发不能推广到任意串行机器人的特定几何策略。在这项工作中,我们提出了一种基于共形几何代数的紧凑、优雅和直观的机器人运动学公式,该公式为具有球形手腕的机械手的逆运动学问题的封闭形式解析提供了合适的框架。对于此类串行机器人,逆运动学问题可以分为位置和方向问题两个子问题。后者是通过将定义目标方向的转子适当地拆分为三个更简单的转子来解决的,而前者是通过为构成机器人位置部分的棱柱关节和旋转关节的每个组合开发几何策略来解决的。 |
| A Multi-Agent System for Autonomous Mobile Robot Coordination Authors Norberto Sousa, Nuno Oliveira, Isabel Pra a 内部物流和库存相关任务的自动化是现代制造企业面临的主要挑战之一,因为它可以更有效地应用人力资源。如今,自主移动机器人 AMR 是此类应用的最先进技术,因为它们在动态环境中具有很强的适应性,取代了更传统的解决方案,例如自动导引车 AGV,这些解决方案在灵活性方面非常有限,并且需要对其进行昂贵的设施更新。安装。应用人工智能 AI 来提高 AMR 的能力,一直为开发更复杂、更高效的机器人做出贡献。尽管如此,解决复杂任务的多机器人协调与合作仍然是一个越来越受关注的热门研究方向。这项工作提出了一个多代理系统,用于在与制造生态系统相关的任务中协调多个 TIAGo 机器人,例如原材料、成品和工具的运输和调度。 |
| Beyond Robustness: A Taxonomy of Approaches towards Resilient Multi-Robot Systems Authors Amanda Prorok, Matthew Malencia, Luca Carlone, Gaurav S. Sukhatme, Brian M. Sadler, Vijay Kumar 稳健性是整个工程、自动化和科学的关键。然而,健壮性的特性通常由成本高昂的要求支撑,例如过度配置、已知的不确定性和预测模型以及已知的对手。这些条件是理想化的,而且往往无法满足。另一方面,韧性是承受意外中断、从负面事件中迅速恢复并恢复正常的能力。在这篇调查文章中,我们分析了如何通过利用系统范围内的互补性、多样性和冗余性来克服逆境的代理和多机器人系统网络中实现弹性,这些系统通常涉及重新配置机器人能力,以提供一些不具备的关键能力。先验地存在于系统中。随着社会越来越依赖连接的自动化系统来提供关键的基础设施服务,例如物流、运输和精准农业,提供实现弹性多机器人系统的方法至关重要。通过列举非弹性脆弱系统的后果,我们认为弹性必须成为一个核心的工程设计考虑因素。为实现这一目标,社区需要明确如何定义、衡量和维护它。我们在基础机器人领域解决这些问题,涵盖感知、控制、规划和学习。我们的主要贡献之一是正式的方法分类法,这也有助于我们讨论弹性系统的定义因素和压力源。最后,这篇调查文章提供了有关如何实现弹性的见解。 |
| A Fast Computational Optimization for Optimal Control and Trajectory Planning for Obstacle Avoidance between Polytopes Authors Akshay Thirugnanam, Jun Zeng, Koushil Sreenath 多胞体之间的避障对于基于最优控制和优化的轨迹规划问题来说是一个具有挑战性的话题。现有的工作要么通过混合整数优化解决这个问题,依赖于系统动力学的简化,要么通过使用距离约束的双变量模型预测控制,需要长视野避障。在任何一种情况下,该解决方案都只能用作离线规划算法。在本文中,我们通过使用离散时间控制障碍函数 DCBF 约束来利用较小的地平线足以避障的特性,并且我们提出了一种基于 DCBF 的具有双变量的新优化公式,以生成无碰撞的动态可行轨迹。与现有工作相比,所提出的优化公式具有较低的计算复杂度,可用作一般非线性动力系统控制和规划的快速在线算法。 |
| Fully Differentiable and Interpretable Model for VIO with 4 Trainable Parameters Authors Zexi Chen, Haozhe Du, Yiyi Liao, Yue Wang, Rong Xiong 单目视觉惯性里程计 VIO 是机器人和自动驾驶中的一个关键问题。传统方法基于过滤或优化来解决这个问题。虽然完全可解释,但它们依赖于人工干预和经验参数调整。另一方面,基于学习的方法允许端到端的训练,但需要大量的训练数据来学习数百万个参数。然而,不可解释和沉重的模型阻碍了泛化能力。在本文中,我们提出了一个完全可微、可解释且轻量级的单目 VIO 模型,该模型仅包含 4 个可训练参数。具体来说,我们首先采用 Unscented Kalman Filter 作为可微层来预测俯仰和滚转,其中学习噪声的协方差矩阵来滤除 IMU 原始数据的噪声。其次,采用精细的俯仰和滚转来使用可微的相机投影来检索每帧的重力对齐的 BEV 图像。最后,利用可微的姿态估计器来估计 BEV 帧之间剩余的 4 个 DoF 姿态。我们的方法允许学习由姿态估计损失监督的端到端协方差矩阵,表现出优于经验基线的性能。 |
| Low Cost Bin Picking Solution for E-Commerce Warehouse Fulfillment Centers Authors Avnish Gupta, Akash Jadhav, Pradyot VN Korupolu 近年来,电子商务履行仓库的吞吐量需求急剧增加。这导致为物品拣选和移动开发了各种自动化解决方案。在本文中,我们解决了机械手挑选随机放置在垃圾箱中的异类物品的问题。传统的解决方案要求物品被拣选并有序地放置在垃圾箱中,并且需要事先知道物品的确切尺寸。这样的解决方案在现实世界中表现不佳,因为垃圾箱中的物品很少有序放置,电子商务供应商几乎每天都会添加新产品。我们提出了一种具有成本效益的解决方案,可以应对上述挑战。我们的解决方案包括一个双传感器系统,其中包括一个普通的 RGB 摄像头和一个 3D ToF 深度传感器。我们提出了一种新算法,该算法融合来自这两个传感器的数据以改进对象分割,同时保持姿势估计的准确性,尤其是在被遮挡的环境和紧密包装的垃圾箱中。我们通过使用 ABB IRB 1200 机器人拣选箱子来实验验证我们系统的性能。我们还表明,我们的系统在姿态估计方面保持了高水平的准确性,这与框的尺寸、纹理、遮挡或方向无关。我们进一步表明,我们的系统在计算上更便宜,并保持 1 秒的一致检测时间。 |
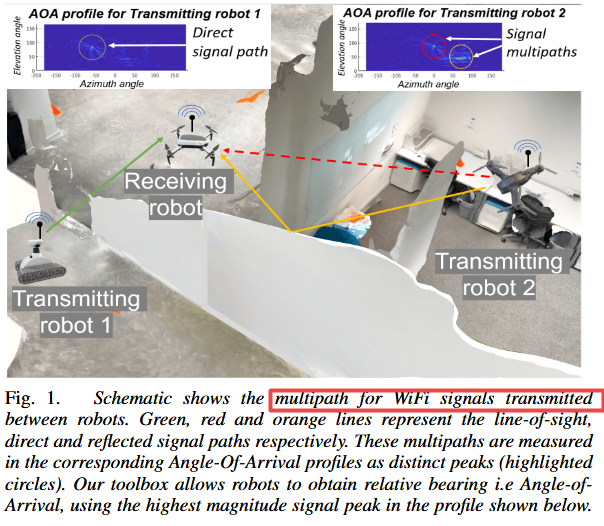
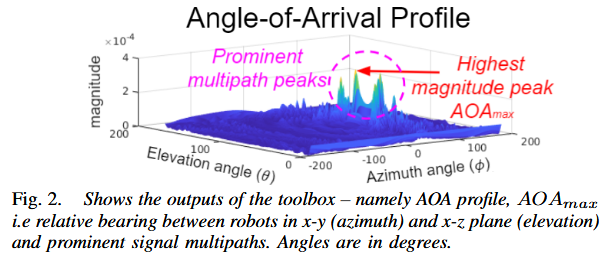
| Toolbox Release: A WiFi-Based Relative Bearing Sensor for Robotics Authors Ninad Jadhav, Weiying Wang, Diana Zhang, Swarun Kumar, Stephanie Gil 本文介绍了机器人 WSR 工具箱的 WiFi 传感器,这是一个开源 C 框架。它使团队中的机器人能够获得彼此的相对方位,即使在非视线 NLOS 设置中也是机器人技术中非常具有挑战性的问题。它通过在机器人穿越环境时分析其通信的 WiFi 信号的相位来实现。此功能基于我们之前工作中开发的理论,首次作为开源工具提供。它的动机是缺乏易于部署的解决方案,这些解决方案使用机器人本地资源,例如 WiFi 在 NLOS 中进行传感。这对多机器人团队的本地化、临时机器人网络和安全性等都有影响。该工具箱专为使用商品硬件和板载传感器在机器人平台上进行分布式和在线部署而设计。我们还发布了数据集,展示了其在多机器人定位用例的 NLOS 和视线 LOS 设置中的性能。实证结果表明,我们工具箱中的方位估计实现了 5.10 度的平均精度。 |
| From Bench to Bedside: The First Live Robotic Surgery on the dVRK to Enable Remote Telesurgery with Motion Scaling Authors Florian Richter, Emily K. Funk, Won Seo Park, Ryan K. Orosco, Michael C. Yip 由于实验室和现场环境之间的显着差异,手术机器人研究的创新很少转化为现场手术。实时环境需要考虑在研究的早期阶段经常被忽视的因素,例如外科工作人员、外科手术以及使用活组织的挑战。一个这样的例子是达芬奇研究套件 dVRK,它被 40 多个机器人研究小组使用,代表了达芬奇手术系统的开源版本。尽管 dVRK 已经使用了近十年,并且是将研究转化为实践的理想候选者,用于世界各地医院使用的 5,000 多台达芬奇系统,但还没有使用它进行过一次现场手术。在本文中,我们解决了将手术机器人研究从工作台转移到床边的挑战、考虑因素和解决方案。这是从远程远程手术场景的角度解释的,之前在实验室环境中试验的运动缩放解决方案被转化为活猪手术。 |
| Learning-based Initialization Strategy for Safety of Multi-Vehicle Systems Authors Jennifer C. Shih, Akshara Rai, Laurent El Ghaoui 由于近年来将自动驾驶汽车引入现实世界的兴趣日益高涨,多车碰撞避免是一个非常关键的问题。这些车辆在完成其目标时的安全性至关重要。 Hamilton Jacobi HJ 可达性是保证低维系统安全的有前途的工具。然而,由于其计算时间呈指数级复杂性,没有基于可达性的方法能够在非结构化场景中成功保证超过三辆车的安全。对于拥有四辆或更多车辆的系统,我们只能凭经验验证它们的安全性能。虽然基于可达性的安全方法享有灵活的最小限制控制策略,但在线推理长期轨迹具有挑战性,因为任何给定状态下的安全性都是通过观察来确定的在一个预先计算的表中提高其安全值,该表没有表现出连续函数具有的有利特性。这引发了在给定任何限制最少的安全意识碰撞避免算法同时避免在线轨迹优化的情况下无法保证安全性时提高非结构化多车辆系统的安全性能的问题。在本文中,我们提出了一种使用监督学习的新方法,通过在车辆原始初始状态的非常接近的邻域中提出新的初始状态来提高车辆的安全性。 |
| Improving Model Predictive Path Integral using Covariance Steering Authors Ji Yin, Zhiyuan Zhang, Evangelos Theodorou, Panagiotis Tsiotras 本文提出了一种用于在不确定性下运行的自主系统的新型控制方法。我们将模型预测路径积分 MPPI 控制与协方差转向 CS 理论相结合,以获得适用于一般非线性系统的鲁棒控制器。所提出的协方差控制模型预测路径积分 CC MPPI 控制器解决了在某些 MPPI 实现中观察到的由于意外干扰和不确定性而导致的性能下降。也就是说,如果环境变化太快或 MPPI 推出期间的模拟动态没有捕捉到实际动态中的噪声和不确定性,则基线 MPPI 实施可能会导致分歧。所提出的 CC MPPI 控制器通过控制在预测范围结束时推出轨迹的分散来避免发散。此外,CC MPPI 具有可调整的轨迹采样分布,可以根据环境进行更改以实现高效采样。 |
| A 4-DoF Parallel Origami Haptic Device for Normal, Shear, and Torsion Feedback Authors Sophia R. Williams, Jacob M. Suchoski, Zonghe Chua, Allison M. Okamura 我们展示了一个中尺度手指安装的 4 自由度 DoF 触觉设备,它是使用折纸制造技术创建的。 4 DoF 设备是一种平行运动机构,能够向指尖提供法向、剪切和扭转触觉反馈。传统的机器人制造方法不太适合设计小型机器人设备,因为制造小型低摩擦关节具有挑战性且成本高昂。我们的设备使用折纸制造原理来降低复杂性和设备占用空间。我们表征了设备的带宽、工作空间和力输出。在虚拟现实场景中展示了扭转自由度的能力。我们的结果表明,该设备可以在 4 个自由度中提供触觉反馈,有效操作工作空间为 0.64cm 3,每个位置以 pm 30 圆周旋转。 |
| Robotic Vision for Space Mining Authors Ragav Sachdeva, Ravi Hammond, James Bockman, Alec Arthur, Brandon Smart, Dustin Craggs, Anh Dzung Doan, Thomas Rowntree, Elijah Schutz, Adrian Orenstein, Andy Yu, Tat Jun Chin, Ian Reid 未来的月球基地可能会使用从月球表面开采的资源建造。在月球上维持人类劳动力的困难以及与地球的通信滞后意味着需要使用具有高度自主性的协作机器人进行采矿。在本文中,我们探讨了机器人视觉在解决缺乏卫星定位系统的月球环境中自主采矿、危险地形导航和精细机器人交互的几个主要挑战方面的效用。具体来说,我们描述并报告了我们为 NASA 太空机器人挑战赛第二阶段开发的机器人视觉算法的结果,该挑战赛是在自主协作机器人在月球上采矿的背景下构建的。比赛提供了一个模拟的月球环境,展示了上面提到的复杂性。我们展示了机器学习支持的视觉如何帮助缓解月球环境带来的挑战。 |
| Efficiently Training On-Policy Actor-Critic Networks in Robotic Deep Reinforcement Learning with Demonstration-like Sampled Exploration Authors Zhaorun Chen, Binhao Chen, Shenghan Xie, Liang Gong, Chengliang Liu, Zhengfeng Zhang, Junping Zhang 在高维的复杂环境中,从头开始训练强化学习 RL 模型通常会遇到冗长乏味的代理环境交互集合。相反,利用专家演示来指导 RL 代理可以提高样本效率并改善最终收敛。为了更好地将专家先验与策略 RL 模型相结合,我们提出了一个基于演员评论算法的从演示 LfD 中学习的通用框架。从技术上讲,我们首先使用 K 均值聚类来评估采样探索与演示数据的相似性。然后我们通过修改梯度更新策略以利用演示来增加类似帧中动作的可能性。我们在 Mujoco 中的 4 个标准基准环境和 2 个自行设计的机器人环境中进行实验。结果表明,在一定条件下,我们的算法可以将样本效率提高20 40 。 |
| A User-Centred Framework for Explainable Artificial Intelligence in Human-Robot Interaction Authors Marco Matarese, Francesco Rea, Alessandra Sciutti 最先进的人工智能 AI 技术已经达到了令人印象深刻的复杂性。因此,研究人员正在发现越来越多的方法来在现实世界的应用中使用它们。然而,此类系统的复杂性需要引入使这些对人类用户透明的方法。 AI 社区正试图通过引入可解释的 AI XAI 领域来解决这个问题,该领域是尝试性地降低 AI 算法的不透明性。然而,近年来,越来越清楚的是,XAI 不仅仅是一个计算机科学问题,因为它是关于通信的,XAI 也是一个人类代理交互问题。此外,人工智能从实验室出来,用于现实生活。这意味着需要为非专家用户量身定制 XAI 解决方案。因此,我们为 XAI 提出了一个以用户为中心的框架,该框架侧重于从认知和社会科学理论和发现中汲取灵感的社交互动方面。 |
| Bayesian deep learning of affordances from RGB images Authors Lorenzo Mur Labadia, Ruben Martinez Cantin 自主代理,例如机器人或智能设备,需要了解如何与对象及其环境进行交互。可供性被定义为代理、对象和环境中可能的未来动作之间的关系。在本文中,我们提出了一种贝叶斯深度学习方法来直接从 RGB 图像预测环境中可用的可供性。基于之前关于社会接受的可供性的工作,我们的模型基于多尺度 CNN,它结合了来自对象和完整图像的局部和全局信息。然而,之前的工作假设了一个确定性模型,但不确定性量化是稳健检测、基于可供性的推理、持续学习等的基础。我们的贝叶斯模型能够捕捉场景中的任意不确定性和与模型相关的认知不确定性,之前的学习过程。为了进行比较,我们使用两种最先进的技术 Monte Carlo dropout 和 deep ensemble 来估计不确定性。我们还比较了不同类型的 CNN 编码器进行特征提取。我们已经在一个关于社会可接受行为的可供性数据库上进行了几次实验,与以前的工作相比,我们已经显示出改进的性能。此外,不确定性估计与对象和场景的类型一致。 |
| An Adaptive PID Autotuner for Multicopters with Experimental Results Authors John Spencer, Joonghyun Lee, Juan Augusto Paredes, Ankit Goel, Dennis Bernstein 本文开发了一种用于多旋翼飞行器的自适应 PID 自动调谐器,并给出了仿真和实验结果。自动调谐器由基于在 PX4 飞行堆栈中实施的追溯成本自适应控制的自适应数字控制法则组成。学习轨迹用于在单次飞行期间优化自动驾驶仪。然后通过飞行使用二阶希尔伯特曲线构建的测试轨迹,将自动调谐的自动驾驶仪与默认的 PX4 自动驾驶仪进行比较。为了研究自动调谐器对四轴飞行器动力学的敏感性,改变了四轴飞行器的质量,并比较了自动调谐和默认自动驾驶仪的性能。 |
| Graph-Based Spatial-Temporal Convolutional Network for Vehicle Trajectory Prediction in Autonomous Driving Authors Zihao Sheng, Yunwen Xu, Shibei Xue, Dewei Li 预测相邻车辆的轨迹是自动驾驶汽车决策和运动规划的关键步骤。本文提出了一种基于图的时空卷积网络 GSTCN,以使用过去的轨迹预测所有相邻车辆的未来轨迹分布。该网络使用图卷积网络 GCN 处理空间交互,并使用卷积神经网络 CNN 捕获时间特征。空间时间特征由门控循环单元 GRU 网络编码和解码,以生成未来的轨迹分布。此外,我们提出了一个加权邻接矩阵来描述车辆之间相互影响的强度,消融研究证明了我们提出的方案的有效性。我们的网络在下一代模拟 NGSIM 中的两个真实世界高速公路轨迹数据集 I 80 和 US 101 上进行了评估。 三个方面的比较,包括预测误差、模型大小和推理速度,表明我们的网络可以达到最先进的性能 |
| Learning Multimodal Rewards from Rankings Authors Vivek Myers, Erdem B y k, Nima Anari, Dorsa Sadigh 从人类反馈中学习已被证明是获取机器人奖励功能的有用方法。然而,专家反馈通常被认为是从潜在的单峰奖励函数中提取的。这种假设并不总是适用于多个专家提供数据的设置,或者当单个专家为不同的任务提供数据时,我们因此超越了学习单模态奖励并专注于学习多模态奖励函数。我们将多模态奖励学习表述为一个混合学习问题,并开发了一种新的基于排序的学习方法,其中专家只需要对一组给定的轨迹进行排序。此外,由于在机器人技术中访问交互数据通常很昂贵,因此我们开发了一种主动查询方法来加速学习过程。我们使用 OpenAI 的 LunarLander 的多任务变体和真正的 Fetch 机器人进行实验和用户研究,我们从具有不同偏好的多个用户那里收集数据。 |
| MetaDrive: Composing Diverse Driving Scenarios for Generalizable Reinforcement Learning Authors Quanyi Li, Zhenghao Peng, Zhenghai Xue, Qihang Zhang, Bolei Zhou 安全驾驶需要人类和智能代理的多种能力,例如对未知环境的通用性、复杂的多代理设置中的决策以及对周围交通的安全意识。尽管强化学习取得了巨大成功,但由于缺乏集成的交互环境,大多数 RL 研究都是单独研究每种能力的。在这项工作中,我们开发了一个名为 MetaDrive 的新驾驶模拟平台,用于研究可推广的强化学习算法。 MetaDrive 是高度组合的,它可以从程序生成和真实交通数据重放中生成无数不同的驾驶场景。基于 MetaDrive,我们在单代理和多代理设置中构建了各种 RL 任务和基线,包括对未知场景的泛化性进行基准测试、安全探索和学习多代理流量。 |
| Prioritized Experience-based Reinforcement Learning with Human Guidance: Methdology and Application to Autonomous Driving Authors Jingda Wu, Zhiyu Huang, Wenhui Huang, Chen Lv 强化学习需要熟练的定义和出色的计算工作来解决优化和控制问题,这可能会损害其前景。将人类指导引入强化学习是提高学习性能的一种很有前途的方法。在本文中,建立了一个综合的基于人类指导的强化学习框架。提出了一种在强化学习过程中适应人类指导的新型优先体验重放机制,以提高强化学习算法的效率和性能。为了减轻人类参与者的繁重工作量,基于增量在线学习方法建立行为模型来模仿人类行为。我们设计了两个具有挑战性的自动驾驶任务来评估所提出的算法。进行实验以访问所提出算法的训练和测试性能以及学习机制。 |
| Channel State Information Based Localization with Deep Learning Authors Kutay B lat 定位是机器人和无线通信等各个领域中最重要的问题之一。例如,无人驾驶飞行器 UAV 需要精确的位置信息,以便制定适当的控制策略。使用用于户外应用的集成 GPS 单元可以非常有效地处理这个问题。然而,由于 GPS 信号不可用,室内应用需要特殊处理。移动机器人(例如 UAV)的另一个方面是移动机器人和计算单元之间存在持续的无线通信。这种通信主要用于直接获取遥测信息或控制动作的计算。负责这种传输的集成单元是商用无线通信芯片组。接收端的这些单元负责用各种数学技术消除通信信道的各种影响。这些技术主要需要当前信道的信道状态信息CSI来补偿信道本身。补偿后,芯片组与CSI无关。然而,发送器和接收器的位置对 CSI 有直接影响。尽管 CSI 包含如此丰富的环境信息,但商业无线芯片组阻止了这些数据的可访问性,因为它们被制造为仅向用户提供处理过的信息数据位。但是,根据 IEEE 802.11n 标准化,某些芯片组提供对 CSI 的访问。因此,CSI 数据变得可处理并可集成到本地化方案中。在这个项目中,为本地化任务构建了一个测试环境。两个具有适当芯片组的路由器被指定为发送器和接收器。它们用于 CSI 数据收集。 |
| Chinese Abs From Machine Translation |















 557
557











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









