






针对大场景点云来说,如果采用点卷积那样的算法(PointConv,PointCNN,KPConv等)或者PointNet++等,他们都是利用FPS(最远点采样)的方法,虽然这种采样方法可以使用比较少量的点并且极大地保留的点云的结构,但是他们采样的时间非常的慢,就像我之前有篇博客介绍一样,它没有RS采样的速度,所以对大场景点云来说,目前只有随机采样(RS)才够快。今天介绍的这篇文章是DLA-Net,它是针对大场景建筑点云学习的双重局部注意特征,其实它的网络结构和RandLA-Net很像,都是先进行局部特征编码,只不过他们学习的特征不一样,DLA-Net还在学习的特征上加上了一个自注意力权重,这个方式比较类似于Point Transformer的思想,之后的特征也像RandLA-Net一样进行了一个自注意力池化,用来聚合特征,只不过DLA-Net的自注意力池的输入还添加了一个局部特征编码的特征输入。以下是我对它三个模块和结构的分析。
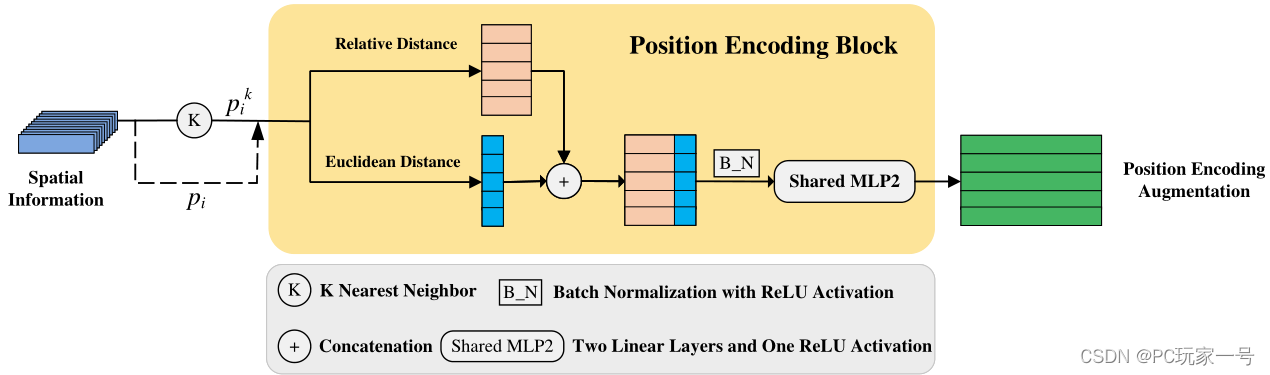
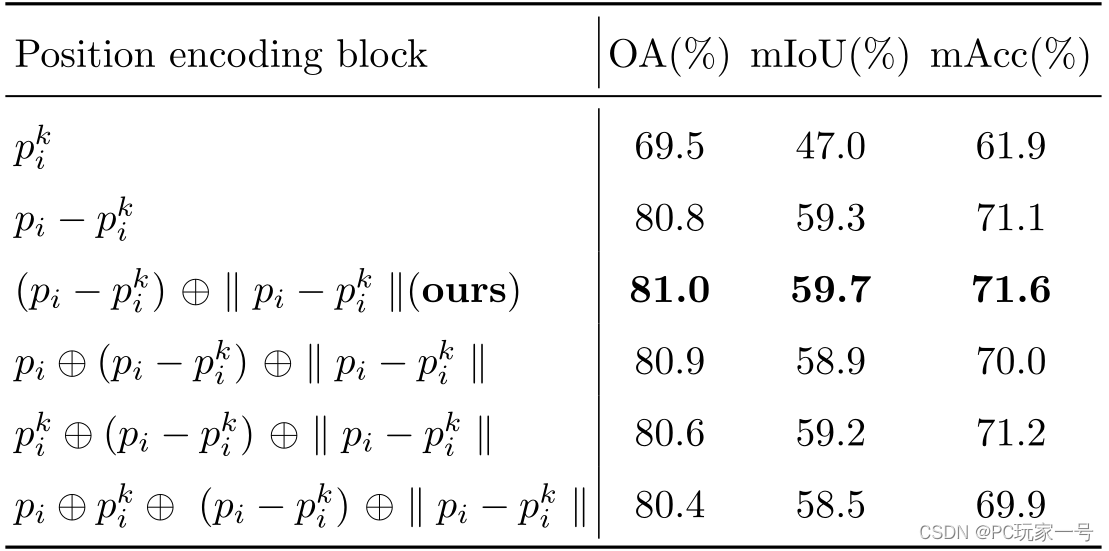
对于局部特征编码模块,它首先选取一个中心点,然后利用KNN进行邻域搜索,之后利用相对位置坐标和它们之间欧氏距离进行连接,之后送入MLP(2个线性层和一个ReLU激活函数)中学习到一个位置编码特征,这个特征就是学习邻域的特征,之前文章有介绍过,很多网络都是在PointNet的基础上去构造不同的方法去学习邻域特征。它后面的消融实验也从不同的学习方法(输入为邻域点、邻域点+中心点等)进行测试,发现相对位置坐标和它们之间欧氏距离这种输入使得最后的Miou是最好的。 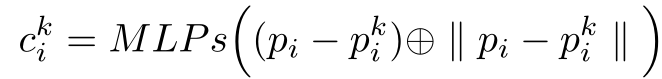
对于自注意力模块,它采用的方法类似于Point Transformer中的想法,利用中心点和邻域点特征之间的减法,在加上局部特征编码得到特征构成自注意力权重,对其特征和局部编码得到的邻域特征进行点乘学习,完成自注意力加权。它做的消融实验是只添加特征映射函数、只添加变化特征和什么也不加,发现还是它们设计的效果最好。
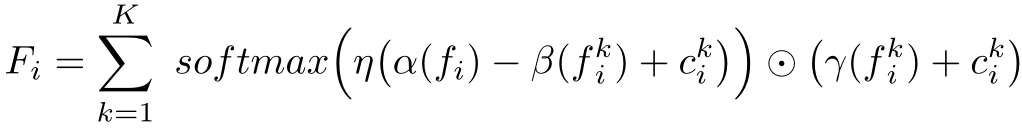
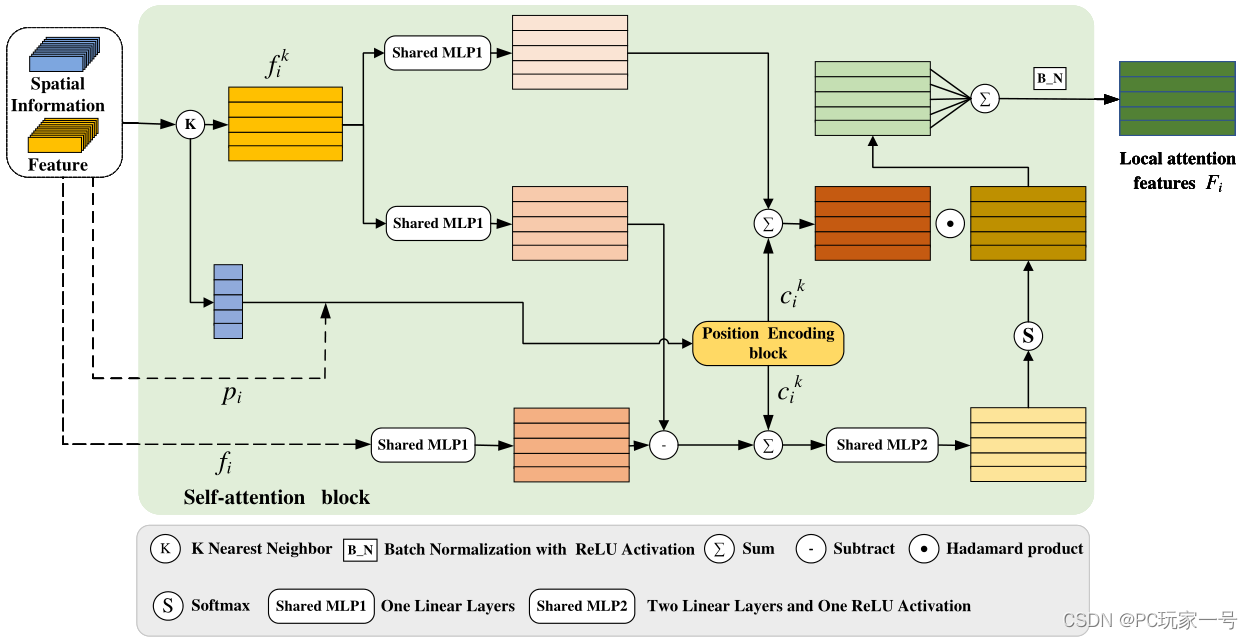
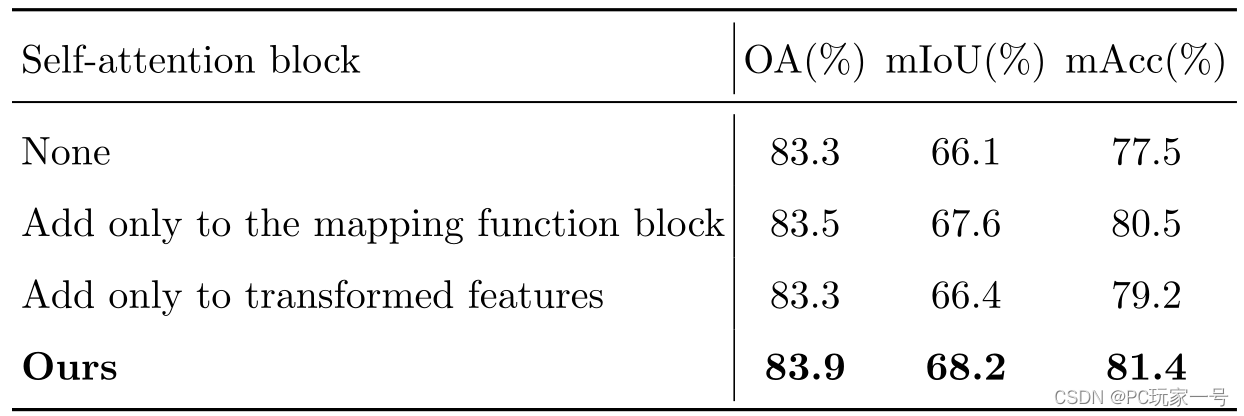
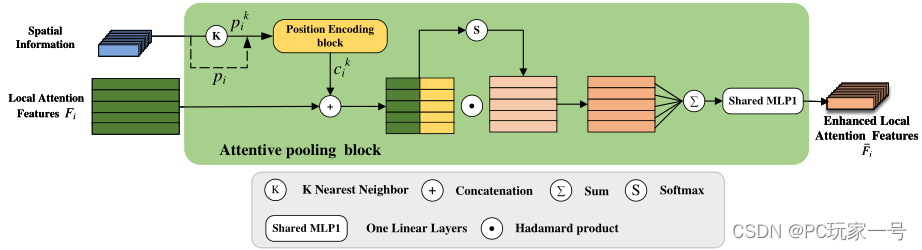
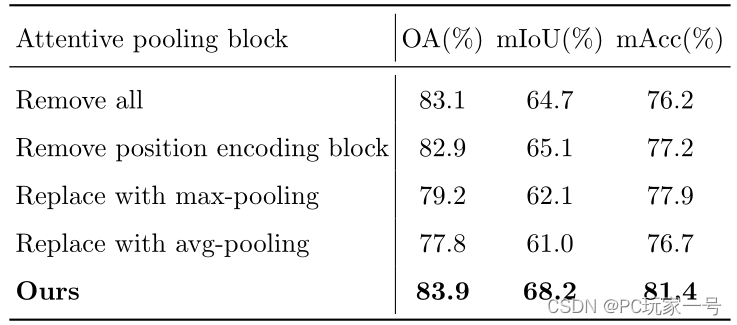
对于自注意力池模块,它主要用于特征的聚合,它设计的和RandLA-Net很像,只不过他的输入不仅仅是自注意力权重提取到的输出特征,而是添加了局部特征编码模块的特征,消融实验也证明了添加过后效果更好,并且它对比了最大池化和平均池化,还是自注意力池化模块最好。
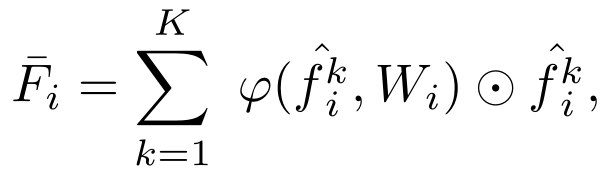
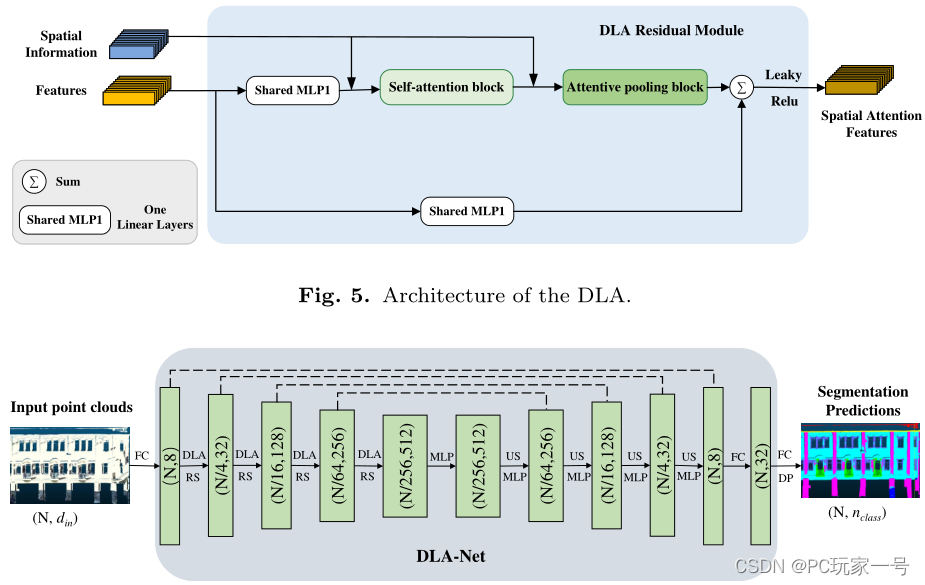
对于DLA-Net的结构而言,它和RandLA-Net的结构一样,都是利用RS进行采样,之后利用DLA模块,然后先聚合特征,点的数目变化为N→N/4→N/16→N/64→N/256,聚合特征就是降低点云的尺度,但是为了防止丢失信息,所以提升了网络的维度(通道数)。聚合完特征之后,利用紧邻插值的方法进行上采样还原到初始点,完成分割任务。
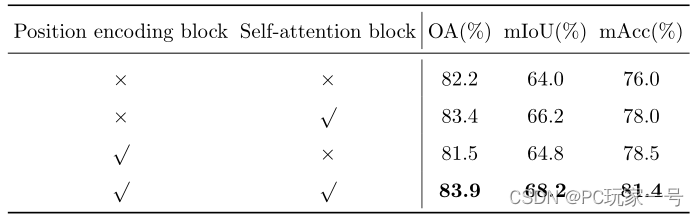
对于该网络的设计,在建筑大场景点云的语义分割中效果还是比RandLA-Net和其他网络要好点的,并且它还针对局部特征编码模块和自注意力模块进行了消融实验,实验证明这两个模块的设计是非常必要的。
对于点云分割来说,不管是点卷积的文章还是逐点MLP的文章而言,都有它们各自的优势,但是它们解决的问题我感觉都是一样的,都是子PointNet的基础之上,去学习邻域的特征,只不过它们学习的方式不一样,还有一点非常重要,就是要解决点云的无序性。以上是本人对这篇文章的理解,详细代码和内容请看论文。















 4048
4048











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











