





最近又看了一些点云分割的文章,近两年点云分割的文章是真的少,不知道是不是点云分割算法接近了末端。这篇文章主要提出了一个基于查询方法的统一范式,它解决了一些不仅仅是点云分割的问题,还解决了三维点云分类和三维目标检测的问题。
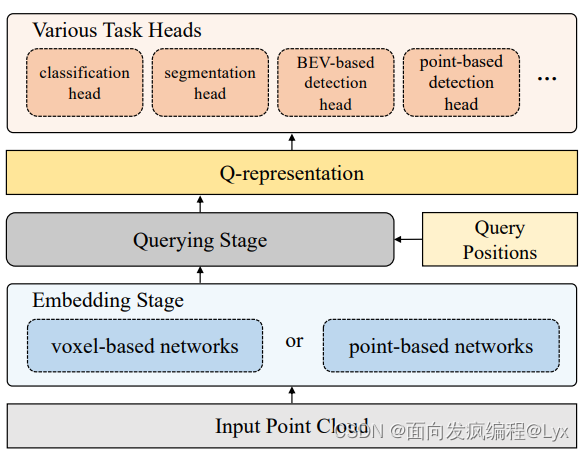
文章整体结构如上图,可以大体将EQ-Net分为三个部分,第一部分成为嵌入部分(Embedding Staget),该部分主要嵌入输入点云,它的一个优势是它不仅仅可以嵌入基于点的网络还能嵌入基于体素的网络,大大提高了其泛化性。通过该部分,网络可以得到下采样的支持点S和支持点特征Fs。第二部分是查询阶段,该部分的输入有两部分,一部分是支持点,另一部分是查询点,该部分主要是通过查询原始数据集,点云分割的话基本上就是将整个点云数据集输入到网络中。该阶段主要经过Q-Net网络,得到一个支持点特征FQ。如下图。
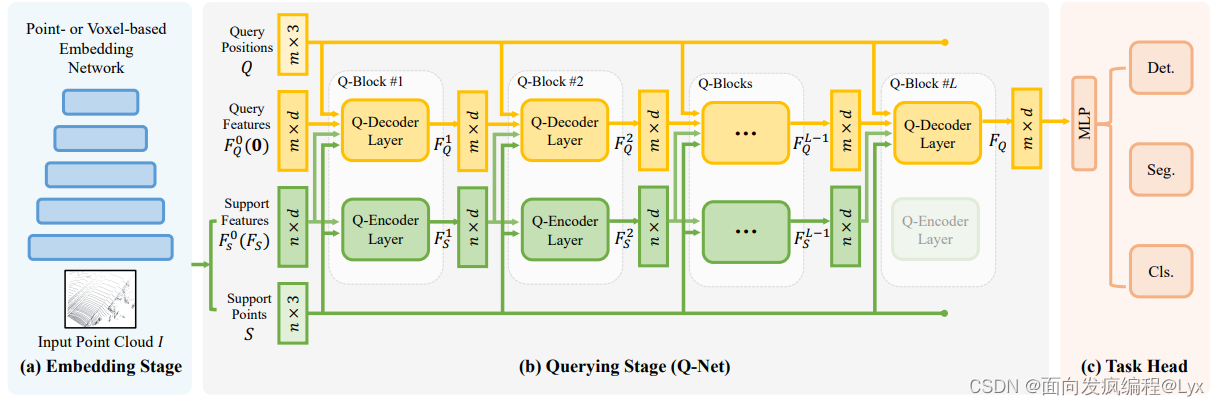
上图可以解析成两部分,黄色代表的是Q-Decoder块,绿色代表的是Q-Encoder块,他们具体层数可以通过消融实验确定。黄色部分主要是利用的Transformer中的交叉注意力,因为它的输入不仅仅有支持点,还有查询点。绿色部分主要是自注意力,它的输入只有支持点,通过几层注意力层后送入不同的任务头(Task Head)完成相应的三维任务。
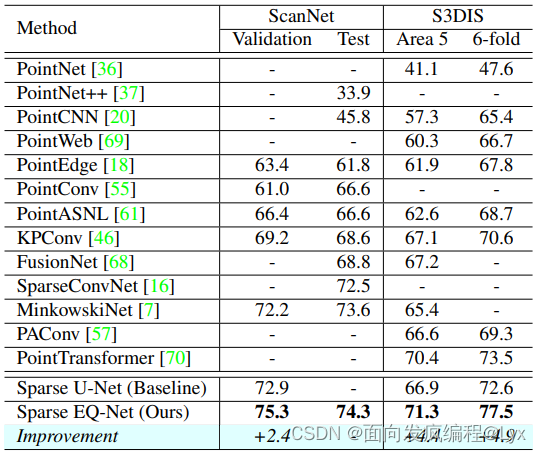
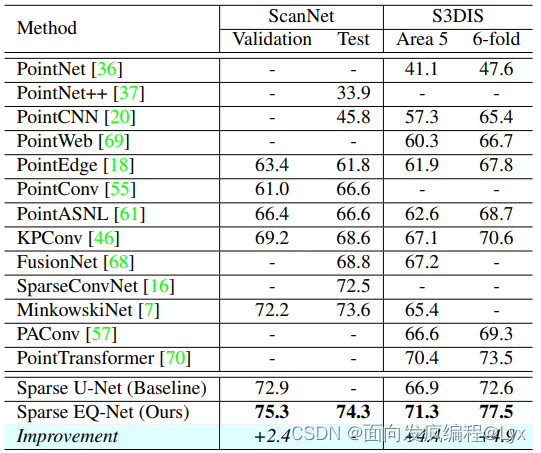
该网络在S3DIS的6-fold上达到了77.5的一个水平,可以说是非常的高了,而且EQ-Net可以嵌入不同的一个网络得到一个支持点的特征,所以该部分设计还是比较好的。
论文地址:https://arxiv.org/pdf/2203.01252v3.pdf
【计算机视觉】简述对EQ-Net的理解
最新推荐文章于 2024-05-30 18:21:20 发布
















 1084
1084











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











