






之前讲述的都是基于逐点MLP和点卷积的文章,对于逐点MLP的文章来说(PointNet和PointNet++)都是采用了对称函数(maxpooling)的做法,这样做的目的是为了解决点云的无序性,但是最大的不足就是他们只提取了全局特征(global feature),丢失了很多信息,虽然PointNet++设计了set abstraction层,用于提取周围点特征,但是提取的效果不好,而且计算量比较差,对于点卷积的文章,他们利用Kernel对领域点进行聚合,然后提取特征并且进行分割和分类,这样做的好处就是解决了丢失信息的问题,并且想办法解决点云的无序性问题,例如KPConv是在空间中对特征进行加权求和,PointCNN就是利用相对位置用MLP进行学习一个变换矩阵,学习空间点云的形状。他们这些方法采样的话大都是用的FPS(最远点采样),这样的好处是可以尽可能保留点云空间的特征,但是坏处就是计算大场景的点云(成千上万个点)的计算速度比较慢,下面讲述一下我对RandLA-Net应用于大场景点云的理解。
一、对于采样来说,因为是大场景点云,虽然随机采样会丢失一些稀疏点的信息,但是相比于FPS和IDIS来说的话,应用在大场景点云上非常合适,采样时间比较快,是它们的几百倍。
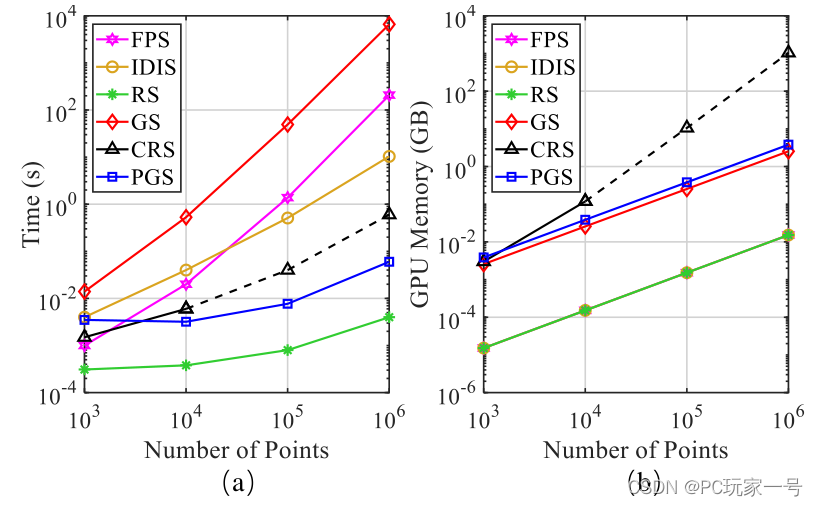
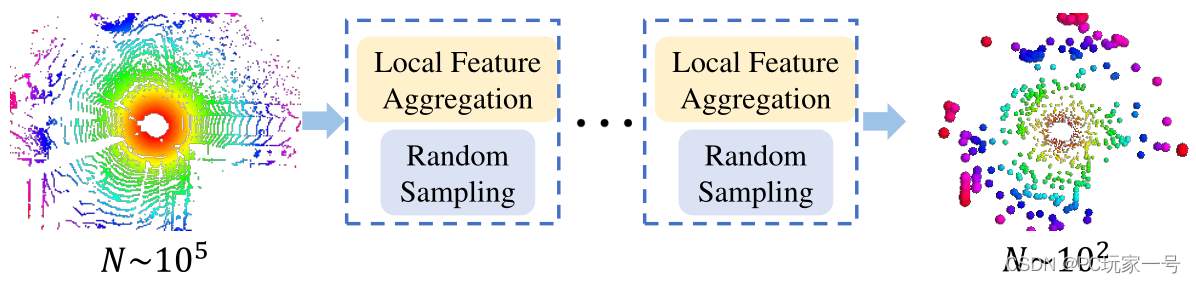
二、由于RandLA-Net采用的是RS采样方式,它的优势很明显,处理大场景点云速度快,但是会丢失一些稀疏关键点的信息,所以它设计了一个LFA的结构,简单点说就是局部特征的聚合,增大网络的感受野来保存复杂的网络结构。
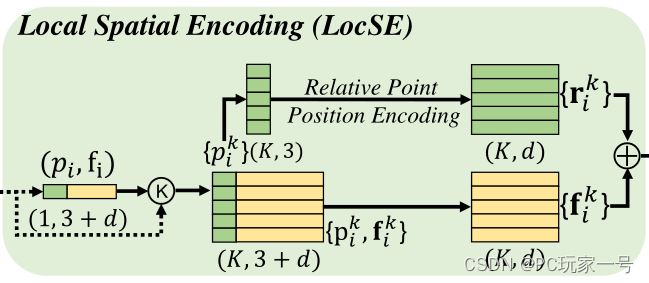
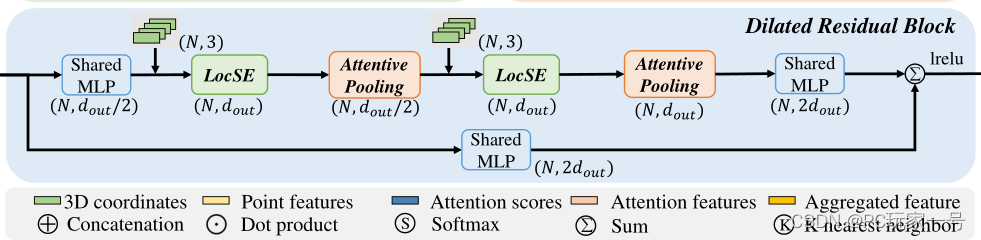
三、LFA主要聚合局部的特征,它由三部分组成,第一部分是LocSE,这部分是局部空间编码的部分,这部分主要通过利用KNN的方法寻找领域点,然后通过特征去学习领域点的一个相对位置关系,与原有的特诊进行一个Concat,这里面通过相对位置学习的一个算是特征吧,这部分将领域和中心点的位置关系进行学习,会提高网络识别点云空间的网络结构,提高一个分割效率。
这里利用MLP输入的主要是中心点、领域点、相对位置、欧氏距离。
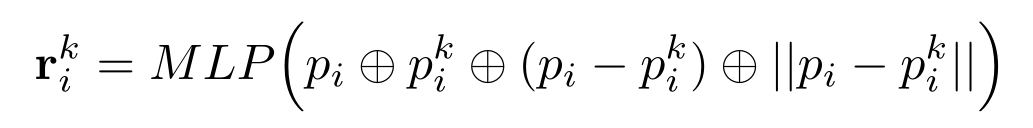
第二部分是Attentive pool(注意力池)部分,这部分主要是利用自己的特征去自学习一个权重,简单点理解就是将自己认为特征比较重要的部分进行一个注意力加权,然后将特征聚合,并且解决点云的无序性问题。
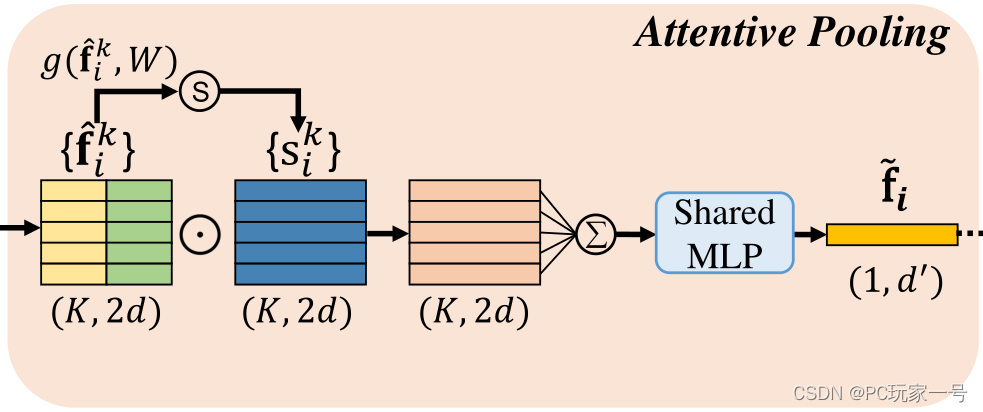
第三部分是扩展残差部分,这部分作用简单来说就是一个领域经过一次LocSE和Attentive pool之后,一个点可以映射K个点,经过两次之后,可以映射K平方个点,意思就是扩大网络的感受野,RandLA-Net堆叠了两组LocSE和注意池就可以达到令人满意的平衡。
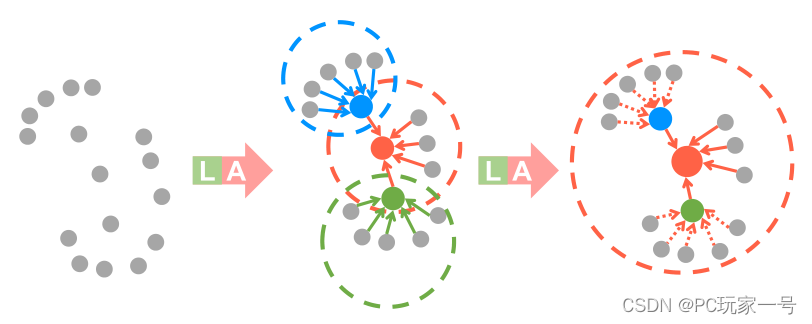
上图的意思就是经过一个LA,蓝色点聚合了上面5个点的特征,红色点聚合了3个点的特征,绿色点聚合了下面5个点的特征,然后再经过一个LA,红色点聚合了那一个领域点的特征,感受野变大了很多。
四、RandLA-Net的网络结构相比其他网络的结构类似,也是先提升网络的维度,对点进行提特征,然后在进行点的还原,并且融合上下文的信息。点云的输入的话是一个尺寸为N×din的大场景点云,然后下采样部分是4个编码层,每一层点云的数量减少(聚合)成原来的25%,然后利用增加空间通道数(维数)的方法保留更多的信息,然后上采样部分是4个解码层,利用KNN搜索的每个点的紧邻点的索引,用最近插值的方法将点的尺度放大,然后利用MLP将上文相同维度的特征信息进行融合,最后利用3个FC层对其进行输出,输出结果为N×nclass,nclass是每一类别的数量。

五、实验部分的话,因为RandLA-Net是解决大场景点云分割问题,并且它的采样时间比较短,所在在分类和分割(Semantic3D和SemanticKITTI)数据集上都优先于之前的算法,着重说一下它做的消融实验。


这个消融实验说明了当移除LocSE模块时,它的效果会大大下降,说明学习一种邻域特征关系对结果非常重要,而且后续有消融实验证明,学习邻域关系的输入对其结果影响也是很大的,利用一些基本池化代替自注意力模块对其分割结果影响不是很大,而且简化残差模块对Miou影响也比较大。

作者做得该消融实验也证明了2个LocSE和Attentive Pool模块连接是最好的分割效果,以上是本人自己对RandLA-Net的一个理解,如有不对,请多多指正!!!
论文网址:https://arxiv.org/abs/1911.11236


















 7776
7776

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











