







1、原理
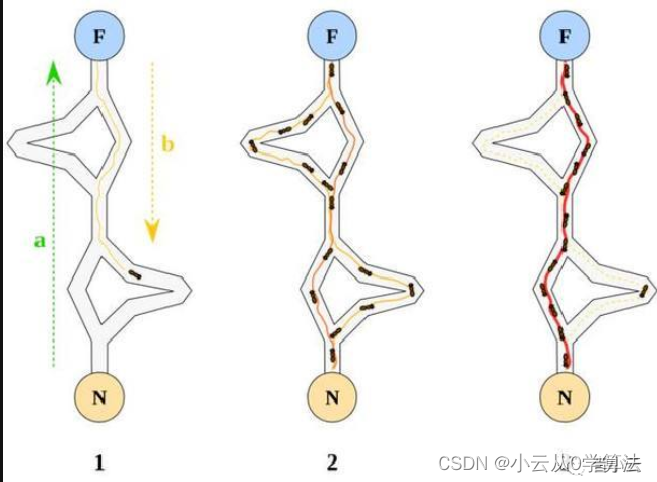
蚁群算法是由自然界中蚂蚁觅食的行为而启发的。最初设计就是解决其中一大类组合优化问题在自然界中,蚂蚁觅食过程中,蚁群总能够寻找到一条从蚁巢到食物源的最优路径。信息素是蚂蚁之间交流的工具之一,当有蚂蚁走过时,它将会在它行进的路上释放出信息素,并且这种信息素会议一定的速率散发掉。
一开始路上没有前面蚂蚁留下的信息素,蚂蚁朝着两个方向行进的概率是相等的;当有蚂蚁走过,它后面的蚂蚁通过路上信息素的浓度,做出决策,往左还是往右;
很明显,沿着短边的的路径上信息素将会越来越浓,从而吸引了越来越多的蚂蚁沿着这条路径行驶;
2、算法流程
2.1基本流程
1、初始化信息素和蚂蚁位置。初始化蚂蚁数量、可行路段、每条路段距离、每条路段的初始信息素大小等信息;设定蚂蚁的起点、终点;
2. 计算每只蚂蚁的选择概率。每只蚂蚁在选择路径时,会考虑当前信息素浓度和距离等因素,计算出每条路径的选择概率。蚂蚁从起点出发根据信息素浓度,有一定的概率性选择路段,浓度越高,概率越大,逐步回到终点;
3. 计算每只蚂蚁的路径和适应度。根据选择概率,每只蚂蚁会沿着选择的路径前进,并计算出其路径长度或适应度值。
4. 更新信息素。蚂蚁在路径上释放信息素,并根据路径长度更新信息素浓度。信息素还会因为挥发效应而逐渐降低。
5.判断是否达到终止条件。可以设置迭代次数或判断蚂蚁的最优路径是否发生变化等终止条件。
6.输出最优解。当达到终止条件后,输出最优解即可。
2.2 参数含义
蚂蚁数量:
在蚁群算法的每一代循环中,每只蚂蚁都会独立地完成自己的TSP。代表同时进行搜索的蚂蚁数量。
max_iter:
最大迭代次数,指定蚁群算法的运行轮数。
alpha和 beta: 表示信息素和启发式信息在路径选择中的重要程度。
信息素浓度较高的路径会被认为是更好的路径
rho:
参数rho控制信息素的挥发速率,即信息素的持久性。设置这个参数的目的是为了平衡蚂蚁算法中的全局搜索和局部搜索的能力。
在蚁群算法中,蚂蚁通过释放信息素来引导其他蚂蚁选择路径。信息素浓度较高的路径有更大的概率被其他蚂蚁选择,因此具有较高的信息素浓度的路径可能会被探索得更加彻底。
然而,如果信息素的持久性过高,会导致较好的路径上的信息素积累过多,从而使得所有蚂蚁倾向于只选择这条路径,陷入局部最优解。这就会降低算法的全局搜索能力。
相反,如果信息素的持久性过低,信息素的增量会迅速被挥发掉,蚂蚁无法对已经探索过的路径保持有效记忆,导致搜索过程失去方向性,无法形成良好的合作连接。这样也会降低算法的局部搜索能力。
因此,通过调节参数rho,可以控制信息素的持久性。适当地设置rho的值可以维持全局搜索和局部搜索的动态平衡,使蚁群算法能够在搜索空间中兼顾全局和局部搜索,更好地寻找到较优的解。一般情况下,参数rho在0~1之间取值,可以根据问题的特性进行调整。
3、优缺点
优点:
- 能够在多维度的搜索空间中进行搜索,并能够找到比较优的解;
- 没有要求搜索空间连续,可以在非连续的区域进行搜索;
- 对于多目标优化问题,可以比较好地处理;
- 能够通过增加信息素挥发速度和更新信息素浓度等措施来避免局部最优解。
缺点:
- 依赖于信息素的初值设定,选择不合适的初值可能会得到不太好的结果;
- 对于大型问题,需要寻找合适的参数并花费较多的计算资源;
- 算法结果可能受到启发式策略的影响,因此需要合适的策略设计。
4、代码实现
以下借助TSP问题(旅行商问题)实例,来详细描述蚁群算法的原理和和实现步骤。
(1)在蚁群算法的每一代循环中,每只蚂蚁都会独立地完成自己的TSP。 蚂蚁完成TSP的过程中,不会选择已经访问过的城市,并且依赖状态转移概率选择下一个城市j。 状态转移概率的定义为: 设第k只蚂蚁当前所在的城市为i,则从该城市移动到j城市的状态转移概率为



此外,算法中还引入了信息素会发机制。 设信息素的保持系数为
,则在完成一次完整循环后,信息素的值变为:

(3)判断是否达到退出条件,如果满足,则退出,否则便进入下一代循环。
import math
import time
import numpy as np
import pandas as pd
from pyecharts import options as opts
from pyecharts.charts import Geo
from pyecharts.datasets import register_url
from pyecharts.globals import ChartType, SymbolType
def tsp_by_aco(D):
# 城市数量
city_cnt = D.shape[0]
# 蚂蚁数量
ant_cnt = 100
# 迭代次数
max_iter = 200
# 信息素权重系数
alpha = 1
# 启发信息权重系数
beta = 2
# 信息素挥发速度
rho = 0.1
# 城市间球面距离
distance = np.zeros((city_cnt, city_cnt))
for i in range(city_cnt):
for j in range(city_cnt):
if i == j:
# 相同城市不允许访问
distance[i][j] = 1000000
else:
# 单位:km
distance[i][j] = 6378.14 * math.acos(
math.cos(D[i][1]) * math.cos(D[j][1]) * math.cos(D[i][0] - D[j][0]) +
math.sin(D[i][1]) * math.sin(D[j][1]))
# 启发信息,距离倒数
eta = 1 / distance
# 信息素矩阵
tau = np.ones((city_cnt, city_cnt))
# 每一代最优解
generation_best_y = []
generation_best_x = []
# 种群
population = np.zeros((ant_cnt, city_cnt)).astype(int)
# 循环迭代
for i in range(max_iter):
"""
在蚁群算法中,城市转移概率用于指导蚂蚁在路径选择时的决策。在代码中,通过以下方式计算城市转移概率:
其中,`tau` 表示信息素矩阵,`eta` 表示启发式信息矩阵,`alpha` 是信息素的重要程度系数,`beta` 是启发式信息的重要程度系数。
这行代码实际上是一个计算公式,将信息素矩阵和启发式信息矩阵按照不同权重进行组合,得到城市转移概率矩阵 `prob_matrix`。
解释这行代码,可以分为两个部分理解:
1. `(tau ** alpha)`:
- 这部分表示信息素矩阵 `tau` 的作用。使用 `**` 符号表示求幂操作。
- `tau ** alpha` 即将信息素矩阵中的每个元素都按照 `alpha` 的权重进行幂运算。
- 较大的信息素值会被放大,因为 `alpha` 表示信息素的重要程度。
2. `(eta ** beta)`:
- 这部分表示启发式信息矩阵 `eta` 的作用。使用 `**` 符号表示求幂操作。
- `eta ** beta` 即将启发式信息矩阵中的每个元素都按照 `beta` 的权重进行幂运算。
- 启发式信息也会被放大,因为 `beta` 表示启发式信息的重要程度。
通过以上两个部分的乘法运算,信息素矩阵和启发式信息矩阵的值根据其对应的权重被放大或缩小,综合起来形成城市转移概率矩阵 `prob_matrix`。
最终,蚂蚁在路径选择时,会基于城市转移概率矩阵中的数值来进行选择,概率较高的城市将有更大的机会被选择。这样能够在搜索空间中引导蚂蚁更有可能选择好的路径,逐步寻找到较优解。
"""
# 城市转移概率
prob_matrix = (tau ** alpha) * (eta ** beta)
# TSP距离
y = np.zeros((ant_cnt, 1))
# 依次遍历每只蚂蚁
for j in range(ant_cnt):
# 设置TSP初始点为0
population[j, 0] = 0
# 选择后续城市
for k in range(city_cnt - 1):
# 已访问城市
visit = set(population[j, :k + 1])
# 未访问城市
un_visit = list(set(range(city_cnt)) - visit)
# 未访问城市转移概率归一化
prob = prob_matrix[population[j, k], un_visit]
prob = prob / prob.sum()
# 轮盘赌策略选择下个城市
next_point = np.random.choice(un_visit, size=1, p=prob)[0]
# 添加被选择的城市
population[j, k + 1] = next_point
# 更新TSP距离
y[j] += distance[population[j, k], population[j, k + 1]]
# 更新TSP距离:最后一个城市->第0个城市
y[j] += distance[population[j, -1], 0]
# 保存当前代最优解
best_index = y.argmin()
generation_best_x.append(population[best_index, :])
generation_best_y.append(y[best_index, :])
# 计算信息素改变量,ACS模型,Q=1
delta_tau = np.zeros((city_cnt, city_cnt))
for j in range(ant_cnt):
for k in range(city_cnt - 1):
delta_tau[population[j, k], population[j, k + 1]] += 1 / y[j]
delta_tau[population[j, city_cnt - 1], population[j, 0]] += 1 / y[j]
# 信息素更新
tau = (1 - rho) * tau + delta_tau
print('iter: {}, best_f: {}'.format(i, generation_best_y[-1]))
# 最优解位置
best_generation_index = np.array(generation_best_y).argmin()
return generation_best_x[best_generation_index], generation_best_y[best_generation_index]
def plot_tsp(cities):
try:
register_url("https://echarts-maps.github.io/echarts-countries-js/")
except Exception:
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
register_url("https://echarts-maps.github.io/echarts-countries-js/")
'''
https://echarts-maps.github.io/echarts-countries-js/preview.html
这个网站上显示的各个国家中文名称, 可以写在下面的maptype里面
'''
title1 = "中国主要城市TSP_by_ACO"
c = (
Geo().add_schema(
maptype='china', # 可以输入国家名字,比如"瑞士"
itemstyle_opts=opts.ItemStyleOpts(color='#323c48', border_color='#111'), ) # 设置地图颜色和边框色
)
for i in range(len(cities)):
c.add(
"城市", # 第一个add数据的标题
[(cities['城市'].iloc[i], i)],
type_=ChartType.EFFECT_SCATTER, # 使用点的样式,并设置点的颜色,点的大小都是一样的!
symbol_size=6, # 设置点的大小
color='red', ) # 点的颜色
for i in range(len(cities) - 1):
c.add(
"tsp路线",
[(cities['城市'].iloc[i], cities['城市'].iloc[i + 1])], # 城市顺序
type_=ChartType.LINES,
effect_opts=opts.EffectOpts(
symbol=SymbolType.ARROW, symbol_size=6, color='yellow'), # 线上的小箭头的颜色
linestyle_opts=opts.LineStyleOpts(curve=0.2)) # 设置两点间线缆的弯曲度
c.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
c.set_global_opts(title_opts=opts.TitleOpts(title=title1),
toolbox_opts=opts.ToolboxOpts())
c.render('tsp_solution_by_aco.html')
if __name__ == '__main__':
# 城市及其经纬度
original_cities = [['西宁', 101.74, 36.56],
['兰州', 103.73, 36.03],
['银川', 106.27, 38.47],
['西安', 108.95, 34.27],
['郑州', 113.65, 34.76],
['济南', 117, 36.65],
['石家庄', 114.48, 38.03],
['太原', 112.53, 37.87],
['呼和浩特', 111.65, 40.82],
['北京', 116.407526, 39.90403],
['天津', 117.200983, 39.084158],
['沈阳', 123.38, 41.8],
['长春', 125.35, 43.88],
['哈尔滨', 126.63, 45.75],
['上海', 121.473701, 31.230416],
['杭州', 120.19, 30.26],
['南京', 118.78, 32.04],
['合肥', 117.27, 31.86],
['武汉', 114.31, 30.52],
['长沙', 113, 28.21],
['南昌', 115.89, 28.68],
['福州', 119.3, 26.08],
['台北', 121.3, 25.03],
['香港', 114.173355, 22.320048],
['澳门', 113.54909, 22.198951],
['广州', 113.23, 23.16],
['海口', 110.35, 20.02],
['南宁', 108.33, 22.84],
['贵阳', 106.71, 26.57],
['重庆', 106.551556, 29.563009],
['成都', 104.06, 30.67],
['昆明', 102.73, 25.04],
['拉萨', 91.11, 29.97],
['乌鲁木齐', 87.68, 43.77]]
original_cities = pd.DataFrame(original_cities, columns=['城市', '经度', '纬度'])
# 使用ACO算法求解TSP
time0 = time.time()
best_x, best_y = tsp_by_aco(original_cities[['经度', '纬度']].values * math.pi / 180)
print('使用ACO求解TSP,耗时: {} s'.format(time.time() - time0))
# 按最优解顺序,生成访问城市次序
original_cities['seq'] = best_x
sort_cities = original_cities.sort_values(by='seq')
sort_cities.loc[len(sort_cities)] = sort_cities.loc[0]
# 绘制TSP路径
plot_tsp(sort_cities)
# 以下是一个简单的蚁群算法python实现示例,用于解决TSP问题:
#
# ```python
import numpy as np
# 参数设置
"""
这些参数是蚁群算法中的关键参数,具体含义如下:
-alpha: 信息素重要程度。用于蚂蚁在选择下一个节点时的信息素浓度的影响权重,alpha越大,蚂蚁更倾向于选择信息素浓度越高的路径。
alpha的取值越大,蚂蚁更加倾向于选择信息素浓度较高的路径,反之则更加依赖启发信息的作用。
- beta: 启发因子重要程度。用于蚂蚁在选择下一个节点时的启发信息的影响权重,beta越大,蚂蚁更倾向于选择启发信息更好的路径。
启发信息是指在蚁群算法中,通过对当前节点与目标节点的距离或者预估值的计算,为每个节点分配一个启发值。启发值代表了当前节点到目标节点的有益信息,能够帮助蚂蚁在路径选择时更好地指导方向。
启发信息的计算方式取决于所解决问题的具体特点。例如,解决旅行商问题时,启发值可以是当前节点与目标节点之间的直线距离,也可以是两点之间的曼哈顿距离。
如果是解决图的最短路径问题,启发值可以是当前节点到目标节点的预估最短距离值(例如使用A*算法)。
在蚁群算法中,启发信息可以有效地帮助蚂蚁在搜索过程中避免深度优先的搜索,从而更快地从历史的经验中学习,并选择一条最佳路径。
- rho: 信息素挥发因子。用于控制信息素浓度的挥发速度,rho越大,信息素挥发速度越快。
- Q: 信息素增量常数。用于控制信息素的更新量大小。
- ant_count: 蚂蚁数量。用于控制每次迭代中蚂蚁的数量,在实际应用中,通常选择适当的蚂蚁数量可以取得更好的效果。
- generation: 迭代次数。用于控制算法的收敛速度,迭代次数越多,算法越容易达到全局最优解,但时间复杂度也会相应增加。
"""
alpha = 1 # 信息素重要程度
beta = 5 # 启发因子重要程度
rho = 0.5 # 信息素挥发因子
Q = 100 # 信息素增量常数
ant_count = 10 # 蚂蚁数量
generation = 100 # 迭代次数
# 初始化城市坐标
distance_graph = np.array([[0, 20, 42, 35],
[20, 0, 30, 34],
[42, 30, 0, 12],
[35, 34, 12, 0]])
# 初始化信息素和启发因子
pheromone = np.ones(distance_graph.shape) / distance_graph
eta = 1 / (distance_graph + np.diag([1e10] * 4))
# 定义函数计算概率
"""
这是一个计算概率的函数,用于蚂蚁算法中选择下一个城市的概率计算。该函数的输入有两个参数:
-current_city`: 当前所在的城市
-allowed_cities`: 在当前情况下可以选择的城市列表
函数将根据指定的 `alpha` 和 `beta` 参数对蚂蚁在选择下一个城市时的信息素浓度和启发式信息进行权衡,计算出每个城市被选择的概率。
具体而言,首先将信息素浓度和启发式信息均使用指定的参数进行幂运算;然后将它们相乘得到所谓的“概率权值”,最后将所有城市的概率权值进行归一化。
函数返回的结果是一个代表每个城市被选择的概率的向量。
"""
def calculate_prob(current_city, allowed_cities):
pheromone_powered = np.power(pheromone[current_city, allowed_cities], alpha)
eta_powered = np.power(eta[current_city, allowed_cities], beta)
probs = pheromone_powered * eta_powered
probs = probs / np.sum(probs)
return probs
# 定义函数选择下一个城市
def choose_next_city(current_city, allowed_cities):
probs = calculate_prob(current_city, allowed_cities)
next_city = np.random.choice(allowed_cities, p=probs)
return next_city
# 定义函数计算路径长度
def calculate_distance(path):
distance = 0
for c in range(len(path) - 1):
distance += distance_graph[path[c], path[c+1]]
return distance
# 迭代搜索
"""
当蚂蚁经过一个城市时,它会释放信息素,如果多只蚂蚁经过同一个城市,那么这个城市上的信息素残留量就会增加,从而影响下一只蚂蚁选择该城市的概率。、
在算法的迭代过程中,信息素会逐渐挥发和更新,从而保持信息素分布的动态平衡。
"""
best_path = []
best_distance = np.inf
for g in range(generation):
ant_paths = np.zeros((ant_count, distance_graph.shape[0]), dtype=int)
for k in range(ant_count):
ant_pos = np.random.randint(0, distance_graph.shape[0])
ant_paths[k, 0] = ant_pos
allowed_cities = list(range(distance_graph.shape[0]))
allowed_cities.remove(ant_pos)
for i in range(1, distance_graph.shape[0]):
next_pos = choose_next_city(ant_pos, allowed_cities)
ant_paths[k, i] = next_pos
allowed_cities.remove(next_pos)
ant_pos = next_pos
distance = calculate_distance(ant_paths[k])
pheromone_increment = np.zeros(distance_graph.shape)
for c in range(distance_graph.shape[0] - 1):
i, j = ant_paths[k, c], ant_paths[k, c+1]
pheromone_increment[i][j] = 1 / distance
pheromone = (1 - rho) * pheromone + rho * pheromone_increment
if distance < best_distance:
best_path = ant_paths[k]
best_distance = distance
print('Generation: {:2d} Shortest Distance: {:.2f}'.format(g, best_distance))
print('Best Path: {}'.format(best_path))
print('Best Distance: {:.2f}'.format(best_distance))
# ```
#
# 在上述示例中,我们使用numpy库处理矩阵数据,并设置了一些常用的蚁群算法参数,包括信息素重要程度、启发因子重要程度、信息素挥发因子、信息素增量常数、蚂蚁数量、迭代次数等。然后初始化城市坐标,并根据距离计算出启发因子。
#
# 接着,我们定义了两个函数:`calculate_prob`用于计算各城市的选择概率,`choose_next_city`用于选择下一个城市。在迭代搜索的过程中,我们首先随机选择一个起始城市,并根据选择概率逐步选择下一个城市,直到搜索完成。在每个迭代过程中,我们根据蚂蚁的选择路径更新信息素,并记录下最优路径和最短距离。最后输出结果。
4.3 mip解决tsp问题代码
import pandas as pd
import math
import numpy as np
import time
from ortools.linear_solver import pywraplp
from pyecharts import options as opts
from pyecharts.charts import Geo
from pyecharts.datasets import register_url
from pyecharts.globals import ChartType, SymbolType
def calc_by_ortools(data):
# 生成ortools求解器,使用SCIP算法
solver = pywraplp.Solver.CreateSolver('SCIP')
# 优化变量
x = {}
u = {}
for i in range(len(data)):
u[i] = solver.NumVar(0, solver.infinity(), 'u[%i]' % i)
for j in range(len(data)):
x[i, j] = solver.IntVar(0, 1, 'x[%i,%i]' % (i, j))
# 目标函数:
# obj_expr = [data[i][j] * x[i, j] for i in range(len(data)) for j in range(len(data))]
obj_expr = []
for i in range(len(data)):
for j in range(len(data)):
obj_expr.append(data[i][j] * x[i, j])
solver.Minimize(solver.Sum(obj_expr))
# 约束条件一: 出度为1
for i in range(len(data)):
constraint_expr = [x[i, j] for j in range(len(data))]
solver.Add(solver.Sum(constraint_expr) == 1)
# 约束条件二: 入度为1
for j in range(len(data)):
constraint_expr = [x[i, j] for i in range(len(data))]
solver.Add(solver.Sum(constraint_expr) == 1)
# 约束条件三: 消除子环
for i in range(1, len(data)):
for j in range(1, len(data)):
if i != j:
solver.Add(u[i] - u[j] + len(data) * x[i, j] <= len(data) - 1)
# 模型求解
status = solver.Solve()
# 模型求解成功, 打印结果
if status == pywraplp.Solver.OPTIMAL:
# 最优目标函数值
print('best_f =', solver.Objective().Value())
# 最优次序
cnt = 0
print(0, end=' ')
k = 0
best_x = [0]
while cnt < len(data):
for j in range(len(data)):
if x[k, j].solution_value() == 0:
continue
print('->', j, end=' ')
k = j
cnt += 1
best_x.append(j)
break
print('\n')
# 打印使用的变量数量
num_vars = sum(x[i, j].solution_value() for i in range(len(data)) for j in range(len(data)))
print("Number of variables used:", num_vars)
return best_x
else:
print('not converge.')
return []
def plot_optimal_routes(cities):
try:
register_url("https://echarts-maps.github.io/echarts-countries-js/")
except Exception:
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
register_url("https://echarts-maps.github.io/echarts-countries-js/")
'''
https://echarts-maps.github.io/echarts-countries-js/preview.html
这个网站上显示的各个国家中文名称, 可以写在下面的maptype里面
'''
title1 = "中国主要城市TSP_by_ortools"
c = (
Geo()
.add_schema(
maptype='china', # 可以输入国家名字,比如"瑞士"
itemstyle_opts=opts.ItemStyleOpts(color='#323c48', border_color='#111'), ) # 设置地图颜色和边框色
)
for i in range(len(cities)):
c.add(
"城市", # 第一个add数据的标题
[(cities['城市'].iloc[i], i)],
type_=ChartType.EFFECT_SCATTER, # 使用点的样式,并设置点的颜色,点的大小都是一样的!
symbol_size=6, # 设置点的大小
color='red', ) # 点的颜色
for i in range(len(cities) - 1):
c.add(
"tsp路线",
[(cities['城市'].iloc[i], cities['城市'].iloc[i + 1])], # 城市顺序
type_=ChartType.LINES,
effect_opts=opts.EffectOpts(
symbol=SymbolType.ARROW, symbol_size=6, color='yellow'), # 线上的小箭头的颜色
linestyle_opts=opts.LineStyleOpts(curve=0.2)) # 设置两点间线缆的弯曲度
c.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
c.set_global_opts(title_opts=opts.TitleOpts(title=title1),
toolbox_opts=opts.ToolboxOpts())
c.render('tsp_solution_by_ortools.html')
if __name__ == '__main__':
# 城市及其经纬度
original_cities = [['西宁', 101.74, 36.56],
['兰州', 103.73, 36.03],
['银川', 106.27, 38.47],
['西安', 108.95, 34.27],
['郑州', 113.65, 34.76],
['济南', 117, 36.65],
['石家庄', 114.48, 38.03],
['太原', 112.53, 37.87],
['呼和浩特', 111.65, 40.82],
['北京', 116.407526, 39.90403],
['天津', 117.200983, 39.084158],
['沈阳', 123.38, 41.8],
['长春', 125.35, 43.88],
['哈尔滨', 126.63, 45.75],
['上海', 121.473701, 31.230416],
['杭州', 120.19, 30.26],
['南京', 118.78, 32.04],
['合肥', 117.27, 31.86],
['武汉', 114.31, 30.52],
['长沙', 113, 28.21],
['南昌', 115.89, 28.68],
['福州', 119.3, 26.08],
['台北', 121.3, 25.03],
['香港', 114.173355, 22.320048],
['澳门', 113.54909, 22.198951],
['广州', 113.23, 23.16],
['海口', 110.35, 20.02],
['南宁', 108.33, 22.84],
['贵阳', 106.71, 26.57],
['重庆', 106.551556, 29.563009],
['成都', 104.06, 30.67],
['昆明', 102.73, 25.04],
['拉萨', 91.11, 29.97],
['乌鲁木齐', 87.68, 43.77]]
original_cities = pd.DataFrame(original_cities, columns=['城市', '经度', '纬度'])
D = original_cities[['经度', '纬度']].values * math.pi / 180
# 城市间球面距离
city_distance = np.zeros((len(original_cities), len(original_cities)))
for i in range(len(original_cities)):
for j in range(len(original_cities)):
if i == j:
city_distance[i][j] = 100000
else:
city_distance[i][j] = 6378.14 * math.acos(
math.cos(D[i][1]) * math.cos(D[j][1]) * math.cos(D[i][0] - D[j][0]) +
math.sin(D[i][1]) * math.sin(D[j][1]))
# 使用整数规划求解TSP
time0 = time.time()
best_x = calc_by_ortools(city_distance)
print('使用ortools求解TSP,耗时: {} s'.format(time.time() - time0))
# 绘制TSP路径
if len(best_x) > 0:
best_routes = []
for i in range(len(best_x)):
best_routes.append(original_cities['城市'].iloc[best_x[i]])
best_routes = pd.DataFrame(best_routes, columns=['城市'])
plot_optimal_routes(best_routes)
参考链接
我在开水团做运筹


















 2195
2195

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









