







机器遗忘先导知识→超链接(编辑中)
目录
摘要
在本文中,我们进行了第一次关于调查机器遗忘引起的意外信息泄露的研究。我们提出了一种新的隶属推理攻击,它利用ML模型的两个版本的不同输出来推断目标样本是否是原始模型的训练集的一部分,但不在相应的未学习模型的训练集之外。
我们的实验表明,所提出的成员推断攻击取得了较强的性能。更重要的是,我们表明,我们的攻击在多种情况下都优于对原始ML模型的经典成员推断攻击,这表明机器学习的遗忘学习可能会对隐私产生适得其反的影响。我们注意到,对于经典成员度推理表现不佳的广义化 ML 模型,隐私降级尤为显着。我们进一步研究了四种机制来减轻新发现的隐私风险,并表明仅发布预测标签、温度标度和差分隐私是有效的。
主要贡献
- 我们迈出了第一步,通过成员资格推理攻击的视角来量化机器学习中的意外隐私风险
- 我们提出了几种实用的方法来聚合两个版本的ML模型返回的信息
- 我们提出了两个新的指标来衡量机器学习导致的隐私退化,并进行了广泛的实验来证明我们攻击的有效性
- 我们提出了四种防御机制来减轻我们的攻击带来的隐私风险,并实证评估其有效性。
被攻击模型
Retraining from Scratch
将需要遗忘的样本从训练数据集中删除,用删除后的训练数据集重新训练获得一个新的模型,该新模型作为遗忘后模型使用。

SISA架构
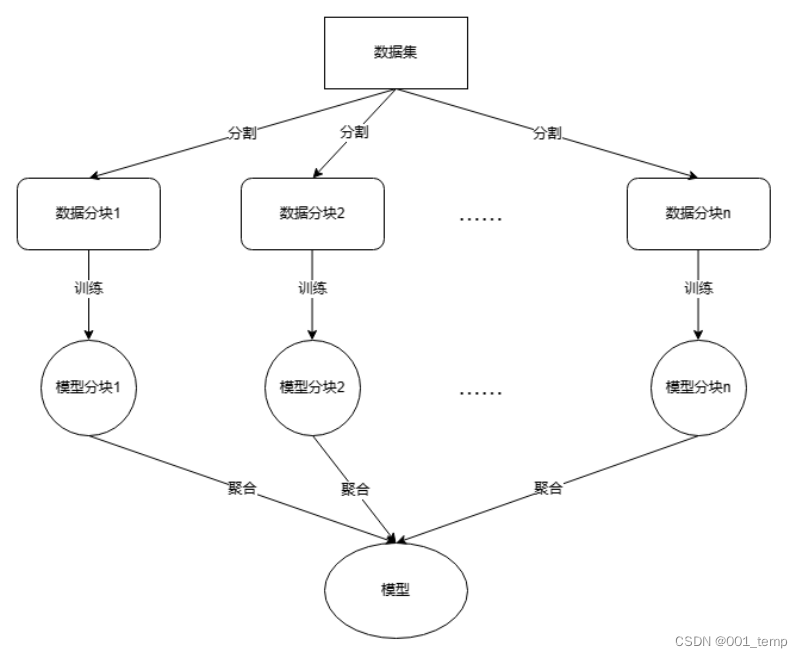
将训练样本划分为不相交的多个样本分片,以分别训练分模型,分模型结果最后简单地进行聚合,作为最终结果。本论文中使用的聚合结果为将分模型对样本预测的标签置信值求平均值。
进行机器遗忘时,将需要遗忘的样本属于的训练数据集分片中的该样本删除,并重新训练分模型。

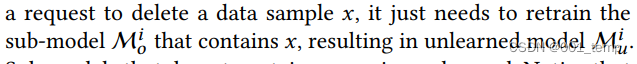
攻击模型
目标:给定一个目标样本 x、一个原始模型及其遗忘的模型,攻击者旨在推断 x 是否从原始模型中遗忘。
敌手的知识:我们假设攻击者可以黑盒访问原始 ML 模型及其遗忘模型。当两个连续查询的目标样本的输出没有变化时,则没有发生遗忘,攻击者也不需要发起攻击。另一方面,当攻击者观察到目标样本输出的变化时,他们知道目标模型已更新。
机器遗忘中的成员推理攻击
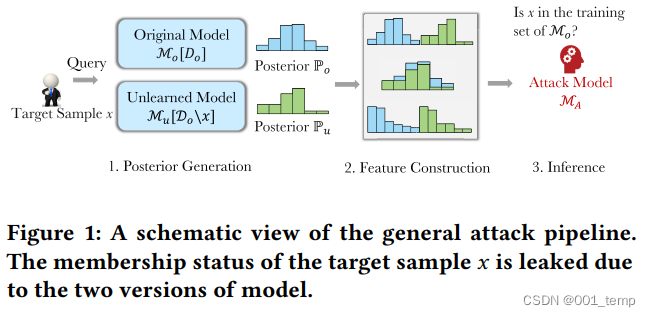
常用技术线如上图。通过构建特征推测样本是否属于原始训练数据集。
攻击方式
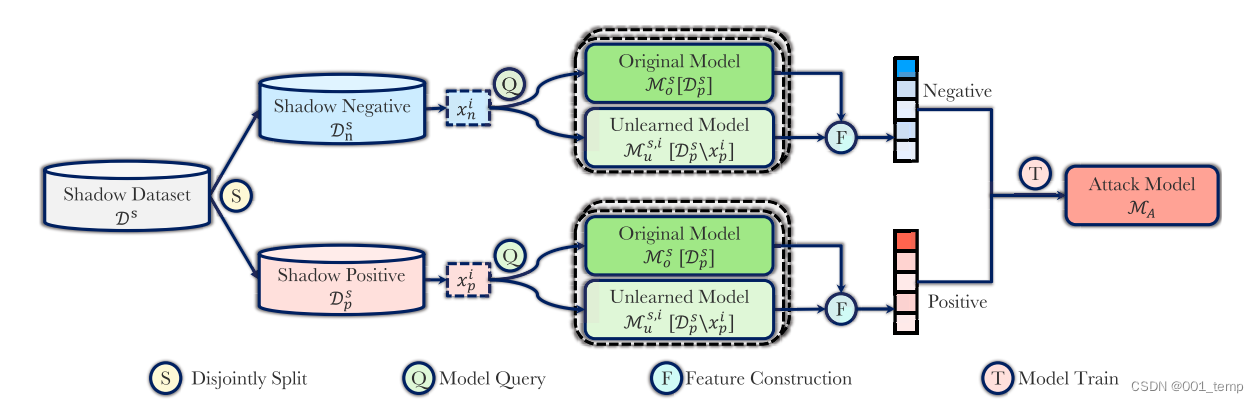
影子模型
假设敌手有能力在本地构建一个和目标攻击模型结构相同的模型,该模型称为影子模型。影子模型用于生成供攻击模型学习的特征数据集。
将数据集(Shadow Dataset)划分为不相交的影子正数据集(Shadow Positive)和影子负数据集(Shadow Negative)。其中,影子正数据集用于训练得到影子模型(Original Model),并选择需要遗忘的样本,以训练得到影子遗忘模型(Unlearned Model)。影子正数据集中用于遗忘的样本、影子负数据集中随机抽取的样本用于放入影子模型和影子遗忘模型中,以获取用于构建特征的数据。
该生成的数据被标签为Positive或Negative,需要进行特征构建,以进一步获取遗忘样本的特征,并去除冗余。
特征构建
对于同一样本,记影子模型对其预测的置信值为Po,影子遗忘模型对其预测的置信值为Pu。此处的置信值之对于该样本的每个分类的预测置信值,所有分类置信值之和应为1。
特征构建方法如下:
- 直接连接
- 排序连接

- 直接作差
- 排序作差
- 欧里几德距离

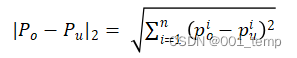
防御手段
只输出标签
隐匿置信值,对于被攻击模型对于样本只输出置信值最高的标签。
top-k
隐匿除最高的前k个置信值其值以及标签以外的置信值。
温度缩放
温度缩放将logits向量除以学习的缩放参数。
温度缩放是一种简单有效的分类校准技术,其原理是通过对神经网络的输出进行缩放,从而调整分类器的置信度。具体做法是通过引入一个温度参数T,对神经网络的最后一层输出进行缩放,以调整预测概率的集中程度。这是一种简单而有效的方法,可以消除神经网络输出后验的过度置信度问题。这种防御减少了单个样本对输出置信值的影响。
差分隐私
差分隐私DP保证数据集中的任何单个数据样本对输出的影响有限。先前的研究表明,DP可以有效防止经典的隶属度推理攻击。为了验证 DP 是否可以在机器学习取消学习设置中阻止我们的成员资格推理攻击,我们以差分私有方式训练原始模型和未学习模型。
评估
给定 n 个目标样本 x 1 到 x n,将 p i u 定义为将 x i 分类为成员的攻击的置信度,将 p i m 定义为经典隶属度推理的置信度。设 b i 是 x i 的真实状态,即如果 x i 是成员,则 b i = 1,否则 b i = 0。
DegCount
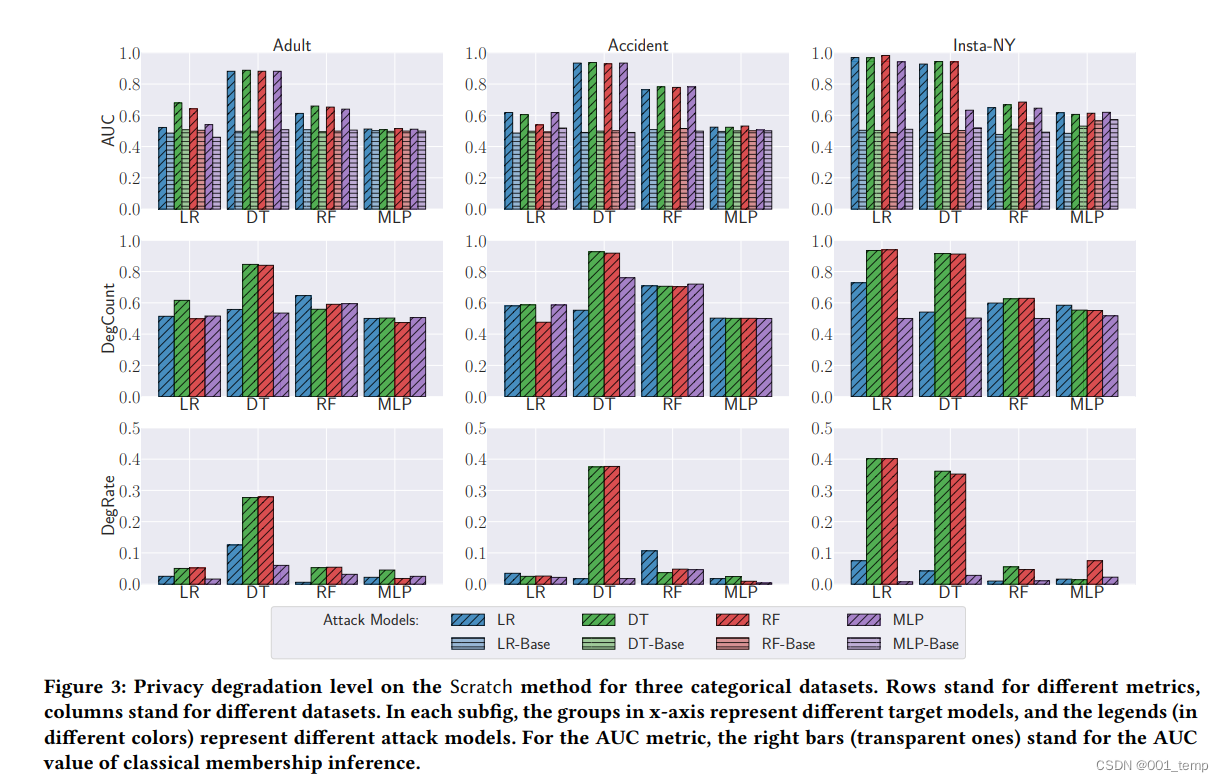
DegCount 代表 退化计数。它计算目标样本的比例,这些目标样本的真实隶属状态通过我们的攻击以比经典隶属度推理更高的置信度预测。其中 1P 是指标函数,如果 P 为真,则等于 1,否则为 0。更高的 DegCount 意味着更高的隐私降级。
简而言之,DegCount 是攻击模型推断出的结果的置信值相比起经典成员推理攻击的置信值更高的数量与所有的样本输出的数量的比值。
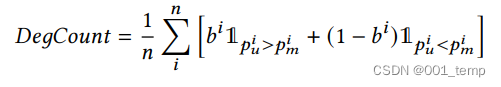
DegRate
DegRate 代表 退化率。它计算了我们攻击中正确预测了成员标签的部分的的平均置信度与经典成员推断相比的提高率。更高的 DegRate 意味着更高的隐私降级。
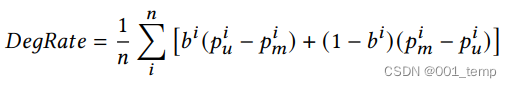
AUC
它是一种广泛使用的指标,用于衡量二元分类在一系列阈值中的性能。
实验结果
配置
样本集:
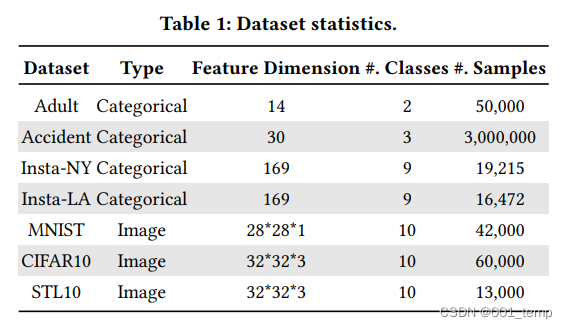
实验结果
对于Adult、Accident、Insta-NY数据集训练的模型,LR、DT、RF、MLP四个攻击模型的攻击表现。
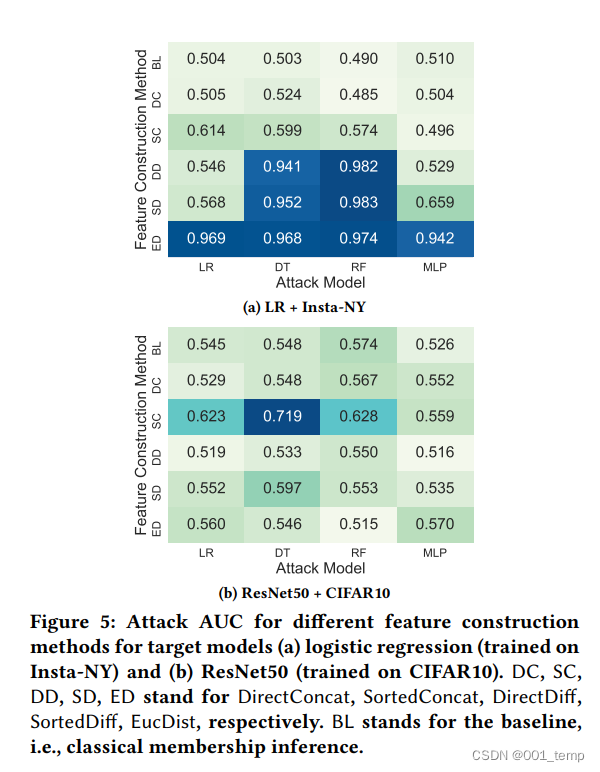
寻找最佳特征
对于其他数据集训练的模型的攻击结果:

不同特征构建方法的攻击结果对比。不同的行表示不同的特征构建方法。
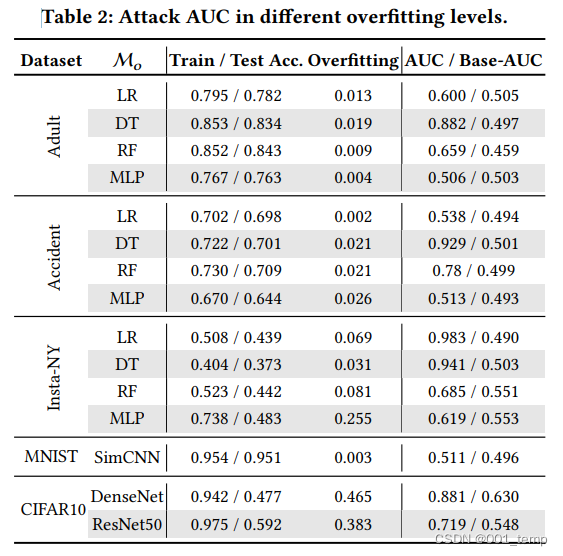
过拟合的影响
不同过拟合水平进行攻击的结果:
其他实验
不同参数攻击结果对比:(a)影子原始模型的数量;(b)训练样本的数量;(c)每个影子原始模型中的遗忘样本数量

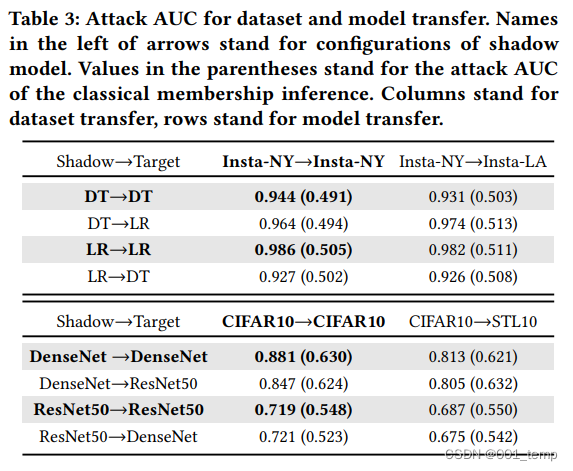
攻击可转移性
对于不同模型之间转换的攻击对比(不同的数据集,不同的影子模型和目标模型):
SISA
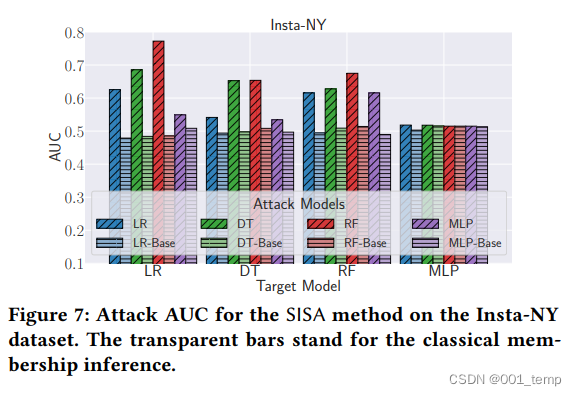
SISA模型中的攻击表现:
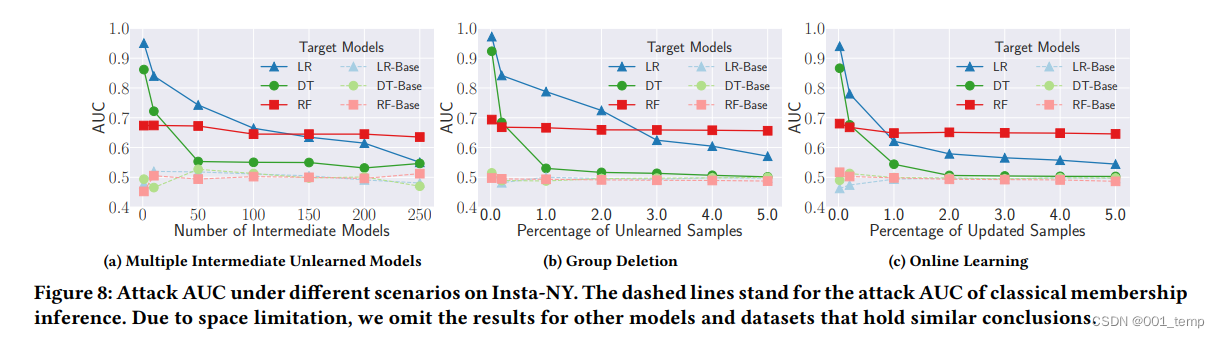
不同场景下的攻击
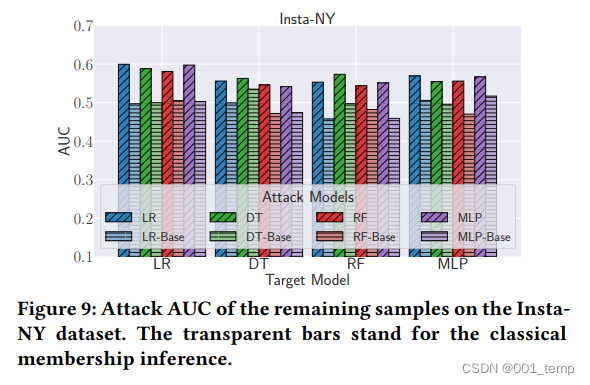
残余样本的影响
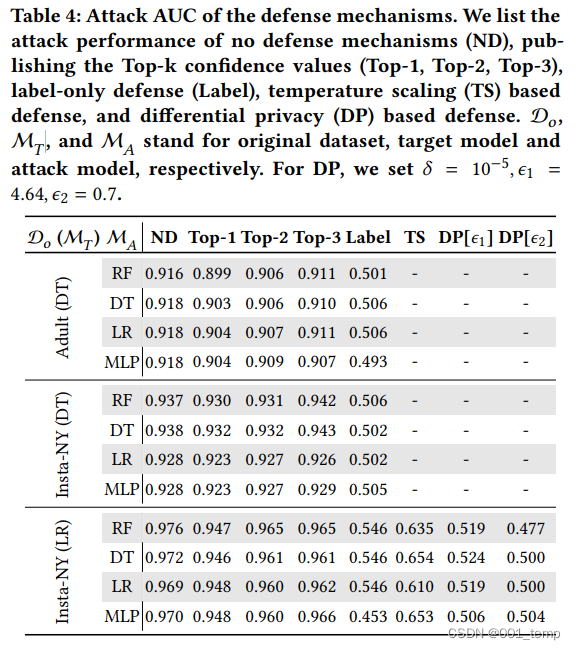
不同防御机制下的攻击结果















 8161
8161

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









