







错误标签方法
来自论文:Machine Unlearning:A Survey中总结的方法。通过给遗忘样本提供随机的错误标签,混淆模型对样本的理解,从而无法在模型中保留任何正确的信息,以达到机器遗忘的目的。
这里总结了以下论文中的方法:
[1] Laura Graves, Vineel Nagisetty, and Vijay Ganesh. Amnesiac machine learning. In Thirty-Fifth AAAI Conference on Artificial Intelligence, AAAI 2021, Thirty-Third Conference on Innovative Applications of Artificial Intelligence, IAAI 2021, The Eleventh Symposium on Educational Advances in Artificial Intelligence, EAAI 2021, Virtual Event, February 2-9, 2021, pages 11516–11524. AAAI Press, 2021.
[2] Daniel L. Felps, Amelia D. Schwickerath, Joyce D. Williams, Trung N. Vuong, Alan Briggs, Matthew Hunt, Evan Sakmar, David D. Saranchak, and Tyler Shumaker. Class clown: Data redaction in machine unlearning at enterprise scale. In Greg H. Parlier, Federico Liberatore, and Marc Demange, editors, Proceedings of the 10th International Conference on Operations Research and Enterprise Systems, ICORES 2021, Online Streaming, February 4-6, 2021, pages 7–14. SCITEPRESS, 2021.
Amnesiac machine learning.
论文主要探讨了在遵守欧盟通用数据保护条例(General Data Protection Regulation, GDPR)的“被遗忘的权利”(Right to be Forgotten)的背景下,如何从已训练的机器学习模型中安全有效地删除个人数据,同时确保模型不受到模型反演攻击(model inversion attacks)和成员推理攻击(membership inference attacks)的威胁。
论文内容概括:
-
背景介绍:GDPR要求数据持有者在欧盟居民请求时删除其个人数据,包括用于训练机器学习模型的训练记录。然而,深度神经网络(DNN)容易受到信息泄露攻击,如模型反演攻击和成员资格推断攻击,这可能会泄露原本应该被删除的私人信息。
-
问题陈述:研究者们提出了一个问题:如何在不损害网络性能的情况下,从训练好的神经网络中安全高效地移除学习到的数据,并且使其不易受到当前数据泄露攻击的威胁。
-
方法介绍:论文提出了两种数据移除方法——“Unlearning”(常规遗忘)和“Amnesiac Unlearning”(健忘遗忘)。常规遗忘通过重新标记敏感数据为随机选择的错误标签,然后对修改后的数据集进行少量迭代训练来混淆模型对敏感数据的理解。而健忘遗忘则是通过选择性地撤销涉及敏感数据的学习步骤,具体是在训练过程中记录哪些示例出现在哪些批次中,以及每个批次的参数更新,然后在数据移除请求到来时,仅撤销包含敏感数据的批次的参数更新。
-
实验评估:研究者们通过实证分析来展示这些方法的有效性、安全性和对敏感数据的遗忘效果,同时保持模型效能。
-
相关工作:论文回顾了有关机器学习模型信息泄露的研究,包括成员资格推断攻击和模型反演攻击,并讨论了差分隐私等技术。
-
实验步骤和方法:
- 实验环境:使用Python 3.7和PyTorch深度学习库,在Amazon Sagemaker平台上进行。
- 数据集:使用了MNIST手写数字数据集和CIFAR100数据集。
- 神经网络模型:使用了Resnet18卷积神经网络。
- 攻击算法:包括修改版的模型反演攻击和成员推理攻击。
- 实验过程:首先评估了在应用数据移除方法前后模型的准确性,然后进行了模型反演攻击和成员推理攻击,以展示数据移除方法对抗数据泄露的有效性。
-
结论:论文最后得出结论,提出的数据移除方法能够有效地保护目标(敏感)数据的隐私,同时不会显著影响模型在非目标数据上的性能。
健忘遗忘方法
Unlearning(常规遗忘)
目标:常规遗忘的目标是混淆模型对敏感数据的理解,使其无法保留有关该数据的任何有意义信息。
方法:为了实现这一点,研究者们提出重新标记敏感数据为随机选择的错误标签,然后在修改后的数据集上对网络进行一些迭代训练。具体来说:
- 对于整个类别的遗忘,将该类别中每个样本的标签替换为随机选择的错误标签。
- 对于选定样本集的遗忘,通过移除这些样本并在数据集中插入少量副本,每个副本带有随机选择的错误标签。
优点:这种重新标记过程在计算上成本较低,并且研究表明,只需要在修改后的数据集上进行少量训练迭代,这种方法就能有效。
风险:数据持有者在常规遗忘过程中必须保留敏感数据的副本,这可能具有法律意义。然而,GDPR给予数据持有者最多一个月的时间来删除数据,这使得这种方法在允许的范围内。
Amnesiac Unlearning(健忘遗忘)
目标:健忘遗忘涉及选择性地撤销涉及敏感数据的学习步骤,以实现对数据的精确移除。
方法:在训练过程中,模型所有者保留一个列表,记录哪些示例出现在哪些批次中,以及每个批次的参数更新。当收到数据移除请求时,模型所有者将仅撤销包含敏感数据的批次的参数更新。具体步骤如下:
- 保持一个包含敏感数据批次索引的列表 SB。
- 维护每个包含敏感数据的批次的模型参数更新 Δθsb。
- 完成训练后,通过从学习到的模型参数 θM 中移除 SB 中的参数更新,生成受保护的模型 M′。
公式表示:
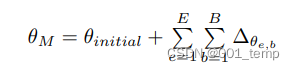
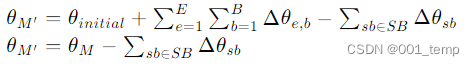
优点:
- 能够非常有效地从单个样本中移除学习内容,对模型其余部分的影响很小。
- 时间效率高,只要需要移除的数据量小,模型的有效性就不会受损。
缺点:
- 需要较大的存储空间来保存每个批次的参数更新值,尤其是对于大型模型。
实验具体步骤和方法:
-
数据集选择:选择了MNIST和CIFAR100两个广泛使用的数据集进行实验。
-
模型选择:使用了Resnet18作为实验的神经网络模型。
-
攻击方法实现:
- 模型反演攻击:对原始模型反演攻击进行了修改,使其能够生成更清晰的图像,并在复杂卷积网络如Resnet18上有效。
- 成员推理攻击:根据先前的研究实现了成员推理攻击,并使用多个影子模型来提高攻击的准确性。
-
数据移除方法评估:
- 对比了“naive retraining”(简单重新训练)、“unlearning”和“amnesiac unlearning”三种方法。
- 评估了这些方法在移除数据后对模型准确性的影响。
- 通过模型反演攻击和成员资格推断攻击来评估这些方法在防止数据泄露方面的有效性。
-
结果分析:分析了不同方法在保护数据隐私和保持模型性能方面的效果,并讨论了它们的优势和局限性。
-
结论:论文总结了数据移除方法的有效性,并指出了未来研究的方向,如开发更全面的数据保留评估方法。
Class clown
论文由Daniel L. Felps等人撰写,主要探讨了在遵守数据隐私法规(如GDPR和加州消费者隐私法案)的情况下,如何在不完全重新训练模型的前提下,删除深度神经网络(DNN)中的特定数据点。文章提出了一种新的数据擦除机制,称为“Class Clown”,利用成员资格推断攻击(Membership Inference Attack)和数据投毒攻击(Data Poisoning Attack)来实现。
概括内容:
- 背景:随着数据隐私法规的实施,个人可以要求企业删除其个人信息,这给使用大量消费者数据集训练高精度DNN的公司带来了技术和财务上的挑战。
- 机器遗忘:提出了一种无需完全重新训练即可让机器学习系统“忘记”数据的方法。该方法通过更新与数据相关的特征来实现,而不是重新训练整个模型。
- Class Clown技术:介绍了一种新的数据擦除技术,通过在增量模型更新中故意错误地分配标签来实现,同时使用成员资格推断攻击模型作为合规工具。
- 实验配置:使用CIFAR10数据集和卷积神经网络(CNN)架构进行实验,评估成员资格推断攻击的效果,并比较不同的数据擦除策略。
- 实验结果:Class Clown技术成功地在5个或更少的重训练周期内实现了数据擦除,对任务精度的影响很小(5%或更少)。
- 结论:Class Clown技术可以用于遵守新兴的数据隐私法规,同时在操作空间中满足性能指标。
Class Clown技术
Class Clown技术的核心思想:
-
成员推理攻击(Membership Inference Attack, MIA):这是一种隐私攻击,攻击者可以预测一个数据记录是否属于模型的训练集。Class Clown技术利用MIA作为一种合规工具,通过量化训练数据点的隐私风险,来确定哪些数据点需要被擦除。
-
数据投毒攻击(Data Poisoning Attack):在模型更新过程中,通过故意错误地分配标签来实现数据点的擦除。这种方法不需要使用原始训练数据集。
Class Clown技术的具体实施步骤:
-
确定要擦除的数据点:使用MIA来识别训练集中需要被擦除的数据点。
-
增量模型更新:从现有的部署模型开始,通过增量的方式对模型进行更新。这涉及到对特定的数据点进行标签投毒,即故意将这些数据点的标签错误地分配给其他类别。
-
标签投毒:在重训练周期中,将需要擦除的数据点的标签故意错误地分配给随机选择的其他类别。这样做会降低模型对正确类别的信心,并改变擦除点附近的决策边界。
-
平衡投毒梯度:在重训练过程中,需要平衡投毒数据点的影响和真实数据点的影响。如果投毒梯度过大,可能会显著影响模型的全局决策边界和准确性;如果使用的真实数据点太多,则投毒点的影响可能不足以改变局部损失空间。
-
重训练和评估:使用MIA模型来评估重训练后的模型是否成功地使擦除点的置信度降低到期望的水平。如果攻击置信度降至零以下,则停止重训练。
-
精度恢复:如果擦除后模型的任务精度低于操作要求,可以选择使用新的或原始训练数据进行少量的训练周期,以恢复精度。
-
顺序擦除:在实际应用中,数据擦除请求可能是无序的,Class Clown技术可以顺序处理这些请求,并通过模拟擦除请求队列来跟踪任务精度。
实验步骤和方法:
- 数据集和模型架构:使用CIFAR10数据集,构建具有0.27M可训练参数的CNN模型。
- 训练配置:使用Adam优化器,批量大小为128,训练25个周期,不使用数据增强。
- 成员推理攻击模型:独立训练的攻击模型,使用基于类的逻辑回归方法。
- 数据擦除:通过在重训练周期中故意错误地分配要擦除数据点的标签来实现。
- 重训练和评估:在重训练过程中,使用攻击模型确定擦除数据点的预测置信度,并与原始攻击置信度进行比较。如果攻击置信度降至零以下,则停止重训练。
- 效果评估:构建100个新的攻击模型,用于评估目标模型、移除模型和擦除模型。记录每个攻击的输出置信度,并比较不同擦除策略的效果。
- 连续擦除:模拟企业操作中数据擦除请求的无序到达,使用Class Clown技术顺序处理每个请求,并跟踪任务精度。
- 未来研究方向:包括优化数据点的选择策略、同时擦除多个数据点的方法、顺序擦除的最优策略,以及将技术扩展到其他数据集和模型架构。
论文通过实验验证了Class Clown技术的有效性,并提出了一种新的DNN模型生命周期维护流程,以处理数据擦除请求,同时最小化完全重新训练模型的需求。















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









